
경직된 ID3 장르 태그가 당신의 로컬 음악 컬렉션을 망치고 있습니다. AudioMuse-AI의 고급 음향 분석 기능과 AtlasCloud의 확장성 높은 API를 결합하면, 정적인 미디어 파일 디렉토리를 감성 중심의 플레이리스트를 자신의 셀프 호스팅 서버로 바로 전달하는 직관적인 시맨틱 탐색 엔진으로 탈바꿈시킬 수 있습니다.
![]()
음악의 온기를 되찾다: AudioMuse-AI로 진정으로 직관적인 로컬 라이브러리 구축하기
늦은 밤 책상에 앉아 있습니다. 강렬한 전자 음악 플레이리스트를 듣고 싶지도 않고, 그렇다고 딱딱하고 차가운 클래식 음악을 들을 기분도 아닙니다. 당신이 원하는 것은 매우 구체적인 분위기입니다. "비 오는 날의 차분한 어쿠스틱 느낌이 가미된, 마음을 차분하게 해주는 조용하고 분위기 있는 인디 포크 음악."
만약 지금 사용 중인 Navidrome이나 Jellyfin의 검색창에 이 문장을 그대로 입력한다면, 결과는 아마 '0'일 것입니다.
수십 년 동안 우리 디지털 음악 수집가들은 ID3 태그를 꼼꼼하게 정리하고, 앨범 아트를 다듬으며, "록", "재즈", "팝"과 같은 경직된 장르 칸에 유동적인 예술 형식을 억지로 끼워 맞추는 데 수많은 시간을 쏟아부었습니다. 하지만 솔직히 말해봅시다. 장르 레이블은 20세기 음반 가게 마케팅의 유물일 뿐입니다. 그것은 음악이 실제로 어떻게 '느껴지는지'를 전혀 이해하지 못합니다.
개인 음악 라이브러리 관리의 미래는 정적인 메타데이터에 있지 않습니다. 바로 시맨틱 오디오 분석에 있습니다. 거대 언어 모델(LLM)은 단순한 채팅 인터페이스 그 이상입니다. 음악에 담긴 측정 불가능한 감정적 무게를 해독하는 궁극적인 열쇠입니다. 오픈 소스인 AudioMuse-AI를 AtlasCloud와 같은 지능형 LLM 라우터와 함께 배포하면, 로컬 파일에 생명을 불어넣고 분위기, 음향적 질감, 가사의 의미를 기반으로 플레이리스트를 생성할 수 있습니다.
AudioMuse-AI란 무엇인가?
AudioMuse-AI는 기존 미디어 설정과 함께 사용할 수 있도록 설계된 셀프 호스팅 오픈 소스 오디오 지능형 엔진입니다. 이 엔진은 Jellyfin, Navidrome, LMS/Lyrion, Emby와 같은 인기 있는 셀프 호스팅 음악 플랫폼에 직접 연결되는 AI 기반 두뇌 역할을 합니다.
AudioMuse-AI는 텍스트 태그를 파싱하는 대신 원본 오디오 파일을 직접 처리합니다. 로컬화된 신경망 모델을 실행하여 (CLAP, Contrastive Language-Audio Pretraining을 사용하여) 복잡한 수학적 음향 벡터를 추출하고 72개 지원 언어 전반에 걸친 가사의 주제를 매핑합니다.
초기 스캔이 완료되면, 기업형 스트리밍 알고리즘을 초라하게 만드는 다음과 같은 기능을 사용할 수 있습니다.
- 음향 클러스터링: 음악 라이브러리를 2D 대화형 "음악 지도"에 시각적으로 배치하여 임의의 장르가 아닌 실제 소리 파형에 따라 트랙을 그룹화합니다.
- 곡 경로 탐색: 신나는 펑크(Funk) 곡을 시작점으로, 우울한 앰비언트 곡을 도착점으로 선택하면, 엔진이 두 곡 사이의 음향적 연결 고리를 자동으로 계산하여 분위기가 자연스럽게 전환되는 플레이리스트를 생성합니다.
- 시맨틱 가사 검색: 정확한 가사 일치 여부를 찾는 대신, 서사적 주제나 감정적 개념(예: "작은 마을에서의 성장에 관한 노래")으로 라이브러리를 검색합니다.
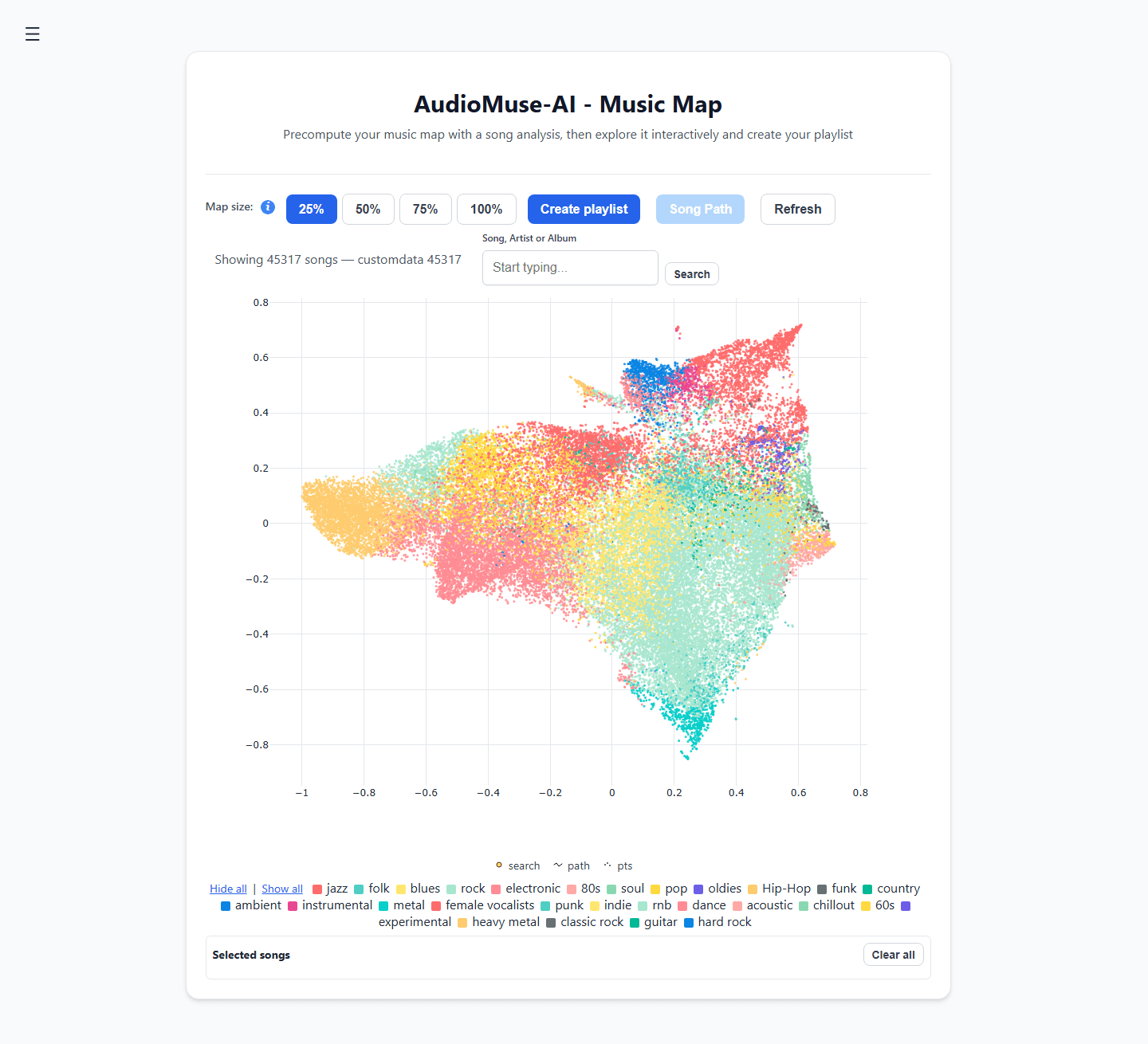
단계별 가이드: 시맨틱 음악 탐색 엔진 구축하기
메타데이터가 전혀 필요 없는 시맨틱 플레이리스트 파이프라인을 설정하는 과정을 살펴보겠습니다.
1단계: 환경 준비 및 배포
AudioMuse-AI는 macOS, Linux, Windows에서 네이티브로 실행할 수 있지만, 일반적인 홈 서버나 NAS 설정에는 Docker Compose가 가장 깔끔한 방법입니다.
서버에 디렉토리를 만들고 배포 문서에서 공식 docker-compose.yaml 파일을 가져온 뒤, 환경 파일이 올바르게 설정되었는지 확인하세요.
YAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ 하드웨어 주의사항: 기본 AI 모델은 최신 CPU 명령어 세트에 크게 의존합니다. Proxmox와 같은 가상화 환경에서 실행 중이라면, AVX2 지원을 전달하기 위해 CPU 유형을 반드시 **"Host"**로 설정해야 합니다. 일반적인 QEMU 가상 CPU에서 실행하면 부팅 시 컨테이너가 즉시 중단됩니다.
다음 명령어로 실행하세요:
Bash
plaintext1docker compose up -d
2단계: 오디오 프레임워크 스캔 실행
브라우저를 열고 http://YOUR-SERVER-IP:8000으로 이동합니다. 초기 설정 마법사가 나타납니다. 미디어 서버를 연결하세요(예: Navidrome URL 및 개인 API 토큰 입력).
연결이 완료되면 Analysis and Clustering 대시보드로 이동하여 **"Start Analysis"**를 클릭합니다.
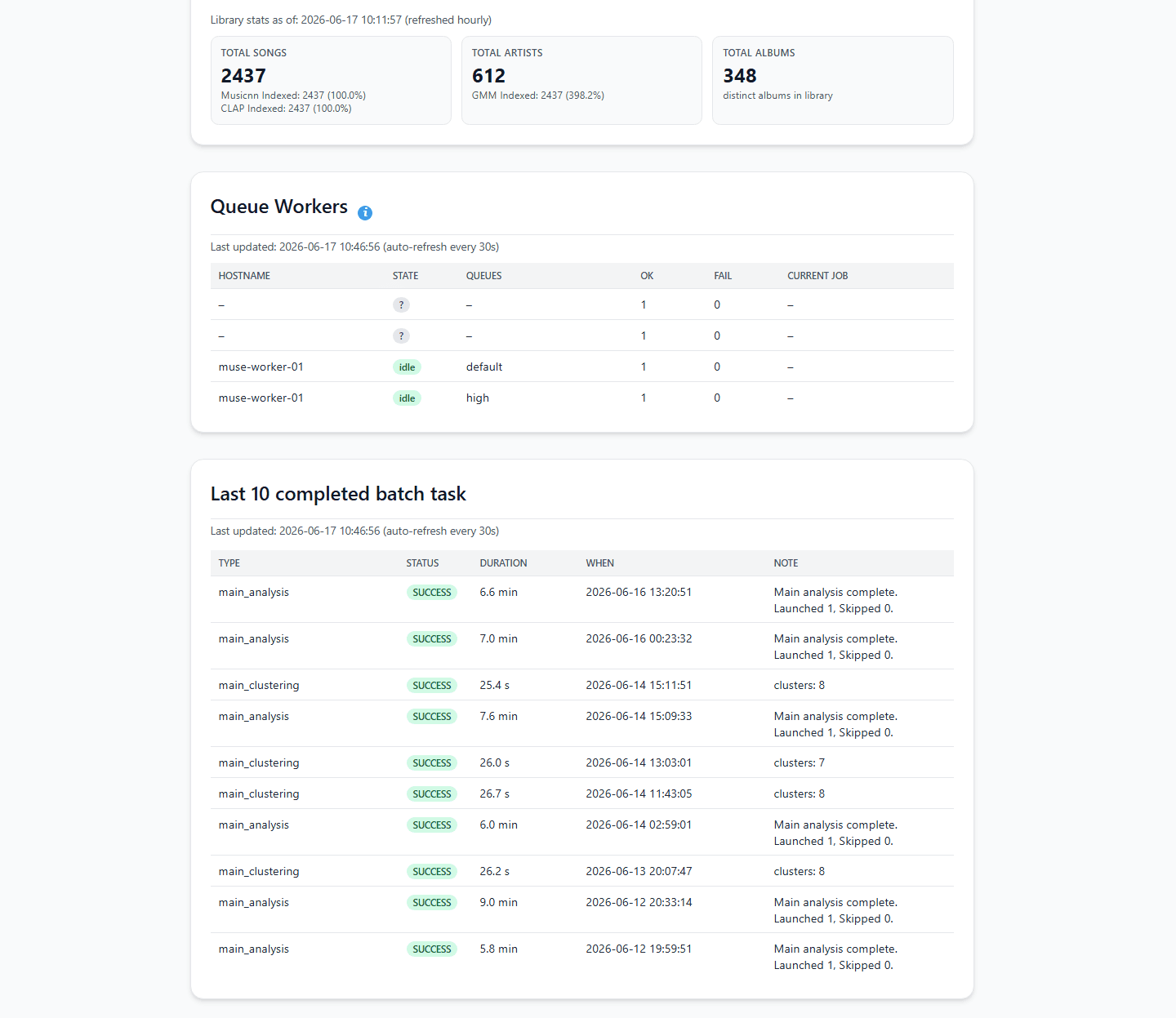
엔진이 음향 지문을 계산하기 시작합니다. 라이브러리 크기와 Intel i5 미니 PC 또는 Raspberry Pi 5와 같은 하드웨어 사양에 따라, 원본 파형을 분석하는 초기 단계는 몇 분에서 몇 시간까지 걸릴 수 있습니다.
3단계: AtlasCloud로 AI 두뇌 구동하기
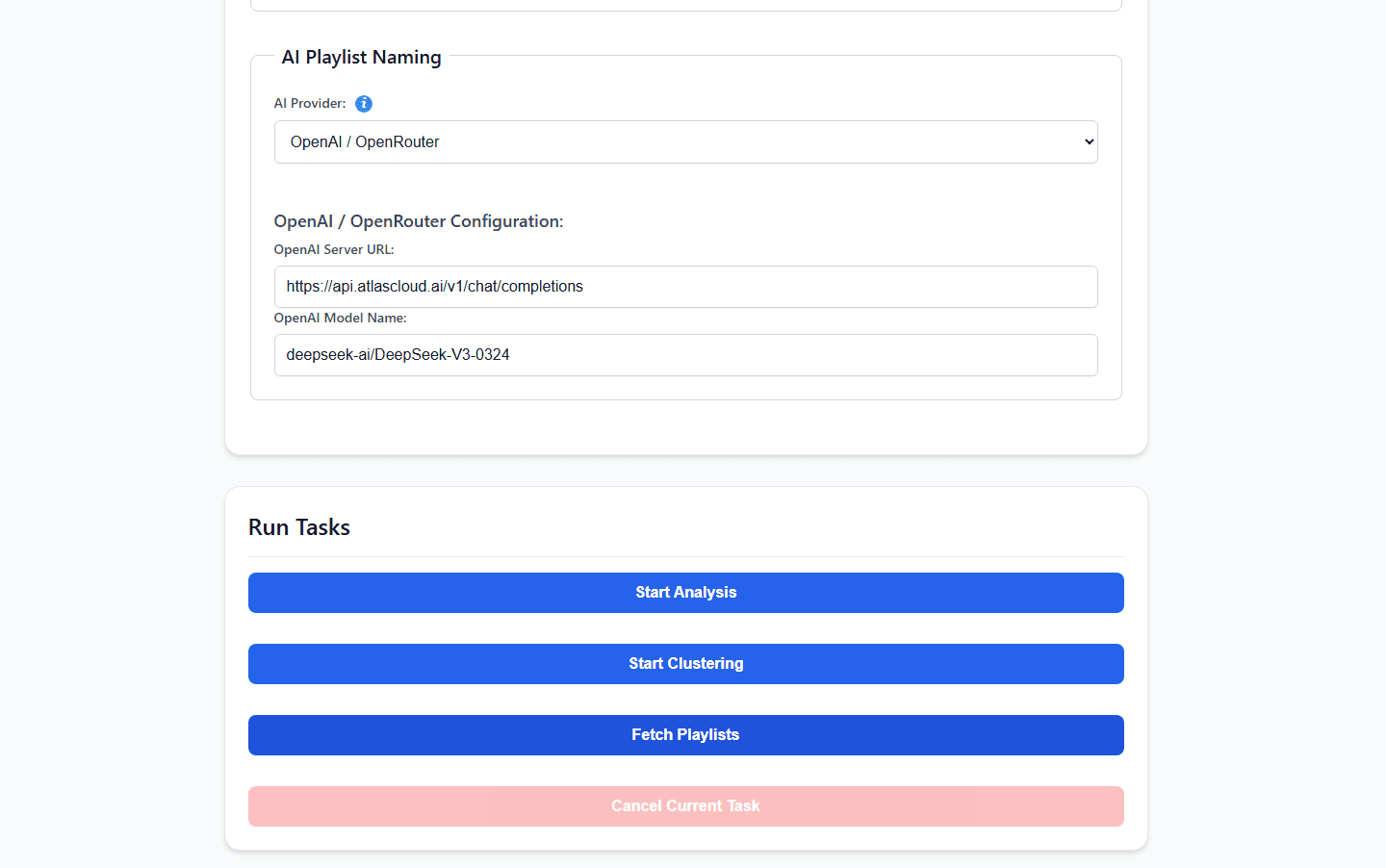
여기서 셀프 호스팅의 고질적인 병목 현상이 발생합니다. AudioMuse-AI는 대화형 플레이리스트 채팅 인터페이스와 심층 가사 임베딩 엔진을 갖추고 있습니다. 이러한 시맨틱 쿼리를 처리하기 위해 거대하고 복잡한 언어 모델을 로컬에서 실행하면 NAS CPU 사용량이 100%에 도달하여 API 타임아웃과 플레이리스트 생성 지연이 발생할 수 있습니다.
로컬 하드웨어를 가볍고 쾌적하게 유지하기 위해, 복잡한 시맨틱 추론을 외부 API로 오프로드할 수 있습니다. 프로젝트의 공식 OpenAI 호환 AI 제공업체 가이드에 따라, 기본 OPENAI 코어 제공업체를 사용하여 AtlasCloud를 통해 요청을 원활하게 라우팅할 수 있습니다.
다음 변수들을 서버의 배포 환경 설정에 추가하세요:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
AtlasCloud를 활용하면 로컬 하드 드라이브에 거대한 모델을 직접 관리할 필요가 없습니다. 단 하나의 키만으로 AudioMuse-AI는 고성능 추론 모델에 즉시 액세스하여 자연어 프롬프트를 즉석에서 분석하며, 1초 미만의 처리 지연 시간으로 결과를 얻을 수 있습니다.
4단계: 첫 번째 분위기 플레이리스트 생성하기
AtlasCloud가 시맨틱 매핑을 처리하게 한 상태에서 Instant Playlists 탭으로 이동하세요. 시스템의 경계를 넘나드는 능력을 테스트해 보겠습니다. 매우 추상적인 프롬프트를 입력해 보세요:
"늦은 밤 비 오는 날 운전하는 분위기의 곡을 추천해 줘. 처음에는 어쿠스틱하고 느리게 시작해서, 뒤로 갈수록 일렉트로닉한 박동감이 느껴지는 곡으로 자연스럽게 이어줘."
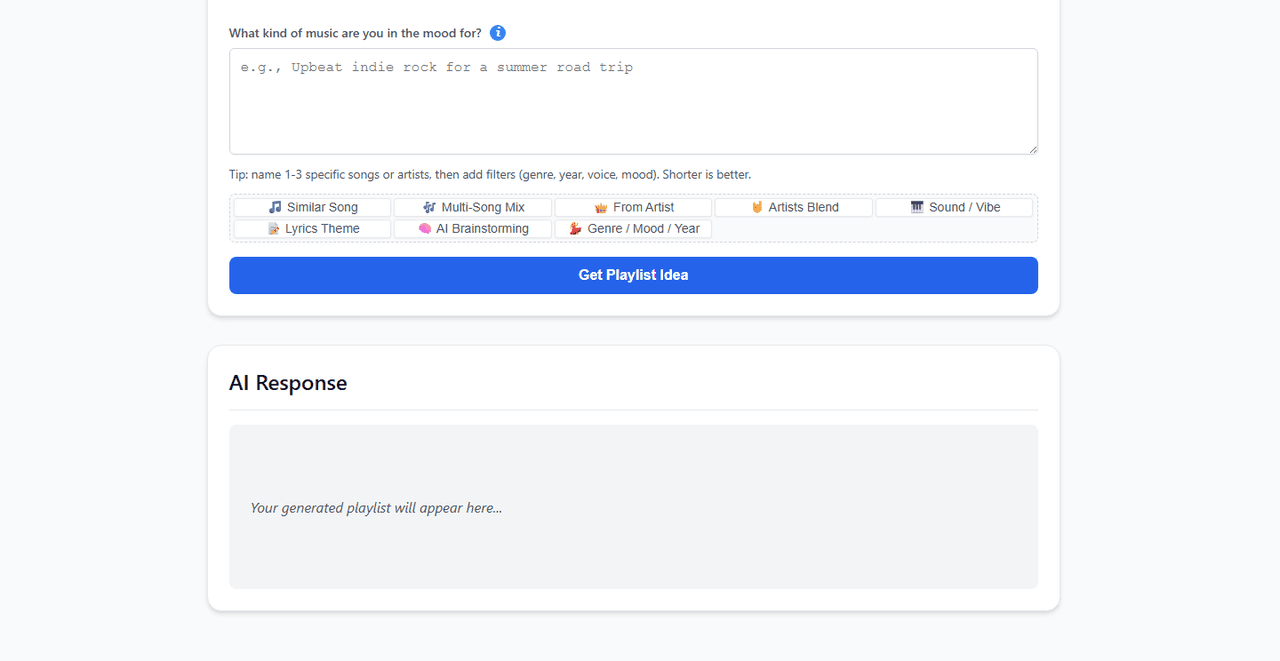
AtlasCloud는 프롬프트의 핵심 감정 의도를 처리하고, 구조적 청사진을 AudioMuse-AI의 로컬 벡터 인덱스로 다시 전달하여 완벽하게 큐레이션된 목록을 즉시 반환합니다. **"Export to Media Server"**를 클릭하면 커스텀 플레이리스트가 Jellyfin이나 Navidrome을 통해 휴대폰 음악 앱으로 즉시 전송됩니다.
비교: 로컬 오디오 AI vs 경쟁 서비스
| 기능 | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
| 개인정보 및 제어 | 완벽한 소유권. 데이터는 로컬에 유지되며, LLM 쿼리는 안전하게 프록시됨. | 부분적 개인정보 보호. 전용 계정 및 유료 Plex Pass 필요. | 개인정보 보호 없음. 청취 기록이 광고 추적용으로 수익화됨. |
| 메타데이터 의존도 | 없음. 원본 오디오 파형과 가사 주제를 직접 분석. | 높음. 분석 전 정확한 기본 태그에 크게 의존함. | 절대적. 상업적 레이블 태그와 데이터베이스 ID에 전적으로 의존함. |
| 초기 성능 | 완벽함. 알려지지 않은 로컬 인디 트랙도 즉시 분석 및 매핑 가능. | 낮음. Plex 데이터베이스와 매칭되지 않으면 컨텍스트를 파악하지 못함. | 매우 낮음. 전 세계적으로 수백만 번 재생되지 않은 곡은 알고리즘에서 무시됨. |
| 시맨틱 검색 | 고급. LLM을 통해 복잡한 자연어 프롬프트를 이해함. | 없음. 기본 필터(연도, 장르, 분위기 태그)로 제한됨. | 보통. 텍스트 파싱은 좋지만 카탈로그 항목으로 엄격히 제한됨. |
기술적 주의사항 및 문제 해결
- VNNI 가사 재분석 버그: 최근 컨테이너 스택을 최신 AudioMuse-AI 빌드로 업데이트했다면 CPU 아키텍처에 유의하세요. GTE 다국어 임베딩 모델의 이전 버전은 VNNI 명령어 세트가 없는 구형 CPU(2019년 이전 하드웨어)에서 벡터 매핑 품질이 저하될 수 있습니다. Linux 호스트에서 를 실행했을 때 결과가 없다면, PostgreSQL CLI를 사용하여 기존 데이터베이스 테이블을 삭제하고 가사 스캔을 다시 트리거하여 깨끗하고 정확한 시맨틱 검색 결과를 얻어야 합니다.text
1grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo - 미디어 서버 타임아웃 조정: 500곡 이상의 방대한 플레이리스트를 Navidrome으로 동기화할 때, 초기 동기화 핸드셰이크가 기본 프록시 제한을 초과할 수 있습니다. 로그에서 연결 핸드셰이크 중단이 발생한다면 공식 매개변수 가이드를 확인하여 서버의 타임아웃 플래그를 조정하세요.
자주 묻는 질문 (FAQ)
설정 중에 Jellyfin 연결 테스트가 실패하는 이유는 무엇인가요?
일반적으로 기본 URL 형식이 잘못되었거나 API 토큰 범위가 유효하지 않기 때문입니다. 포트를 포함한 전체 HTTP/HTTPS 주소(예:
1http://192.168.1.50:8096AVX2 명령어 세트가 없는 구형 서버에서 AudioMuse-AI를 실행할 수 있나요?
네, 하지만 표준 Docker 이미지는 사용할 수 없습니다.
1-noavx21neptunehub/audiomuse-ai:latest-noavx2AtlasCloud API가 app_chat.py의 응답 속도를 어떻게 개선하나요?
대화형 플레이리스트 마법사와 상호작용할 때 시스템은 사용자의 대화형 피드백을 구조화된 JSON 스키마로 변환해야 합니다. 이를 로컬 서버의 CPU에서 처리하면 메시지당 10~30초가 소요될 수 있습니다. AtlasCloud와 같은 최적화된 클라우드 파트너를 통해 이러한 특정 요청을 라우팅하면 수 밀리초 내에 답변을 얻을 수 있어, 로컬 서버 메모리를 여유롭게 유지하면서 끊김 없이 고비트레이트 FLAC 파일을 스트리밍할 수 있습니다.






