
GPU 커널을 작성할 때, 여러분은 일종의 스펙트럼 상 어딘가에 위치하게 됩니다. 한쪽 끝에는 Triton이 있습니다. 작성이 빠르지만, 컴파일러가 레이아웃과 공유 메모리에 관한 대부분의 결정을 대신 내려줍니다. 다른 쪽 끝에는 CUTLASS / CuTe가 있습니다. 방대한 템플릿 코드라는 대가로 완벽한 제어권을 얻습니다. TileLang은 그 중간에 위치합니다. 여러분은 파이썬 코드를 작성하되, 무엇이 공유 메모리에 저장될지, 파이프라인 단계는 어떻게 구성할지, 워프(warp)가 작업을 어떻게 나눌지를 명시합니다. 그러면 '레이아웃 추론(layout inference)' 단계가 나머지 세부 사항을 채워줍니다.
이 글에서는 TileLang의 멘탈 모델을 다루고, GEMM을 작성해 본 뒤, DeepSeek의 MLA 디코드와 같이 실제로 흥미로운 의사결정이 필요한 실무 수준의 커널을 구축해 보겠습니다. 이 글의 목적은 모든 것을 나열하는 것이 아닙니다. 타일을 어떻게 생각해야 하는지, 그리고 TileLang이 어디서 조용히 어려운 부분들을 처리해 주는지 보여주는 것입니다. 마지막으로는 성능 향상이 아닌, 유연성 덕분에 실무에서 빛을 발했던 일반적인 사례를 소개합니다.
멘탈 모델
핵심 아이디어는 다음 세 가지로 요약됩니다.
- 타일은 일급 객체입니다. 특정 형태의 데이터 덩어리(예: block_M × block_K)는 스레드 블록, 워프 또는 스레드가 소유하고 연산합니다. Triton처럼 스레드 블록 단위로만 생각하거나, CUDA처럼 개별 스레드를 일일이 관리할 필요가 없습니다.
- 메모리 계층 구조에 버퍼를 직접 배치합니다. 무엇이 공유 메모리로 갈지(T.alloc_shared), 무엇이 레지스터로 갈지(T.alloc_fragment), 그리고 무엇이 스레드 로컬일지를 직접 선언합니다. 이는 컴파일러 내부에서 공유 메모리 할당과 스테이징을 숨기는 Triton과의 가장 큰 차이점입니다.
- 컴파일러가 스레드 매핑을 추론합니다. 타일의 위치와 수행할 연산(복사, gemm, reduce)을 정의하면, '레이아웃 추론' 패스가 이를 스레드 전체에 병렬화하고 레지스터 및 공유 메모리 레이아웃을 결정합니다. 필요할 경우 직접 재정의할 수도 있지만, 대부분의 경우 자동으로 해결됩니다. 이 기능은 매우 중요하며, MLA 사례를 보면 왜 그런지 알게 될 것입니다.
Triton을 사용해 보셨다면, 아래 매핑을 참고하세요.
| Triton | TileLang | |
|---|---|---|
| 세분성 | 스레드 블록 + 암시적 벡터화 | 타일 (블록 / 워프 / 스레드) |
| 공유 메모리 | 컴파일러가 관리 | explicit alloc_shared + copy |
| 레이아웃 | 컴파일러가 결정 | 추론 방식 (주석으로 변경 가능) |
| 파이프라이닝 | tl.range + 컴파일러 | explicit T.Pipelined(num_stages=) |
| 텐서 코어 | tl.dot | T.gemm (선택 가능한 워프 정책 포함) |
| 백엔드 | NVIDIA (주력) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, 및 Ascend & MUSA 포크 |
요약하자면, CUTLASS를 직접 작성하지 않고도 블로킹, 파이프라인 깊이, 워프 파티셔닝을 세밀하게 제어하고 싶다면 TileLang이 가장 적합합니다. 간단한 요소별 연산이나 가벼운 융합 연산에는 Triton이 여전히 빠릅니다.
환경 설정
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # 사전 빌드된 휠, 가장 간편한 경로
컴파일러 패스를 수정해야 한다면 소스에서 직접 빌드하세요(LLVM/CUDA 툴체인이 로컬에 필요합니다):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
GEMM 작성해 보기
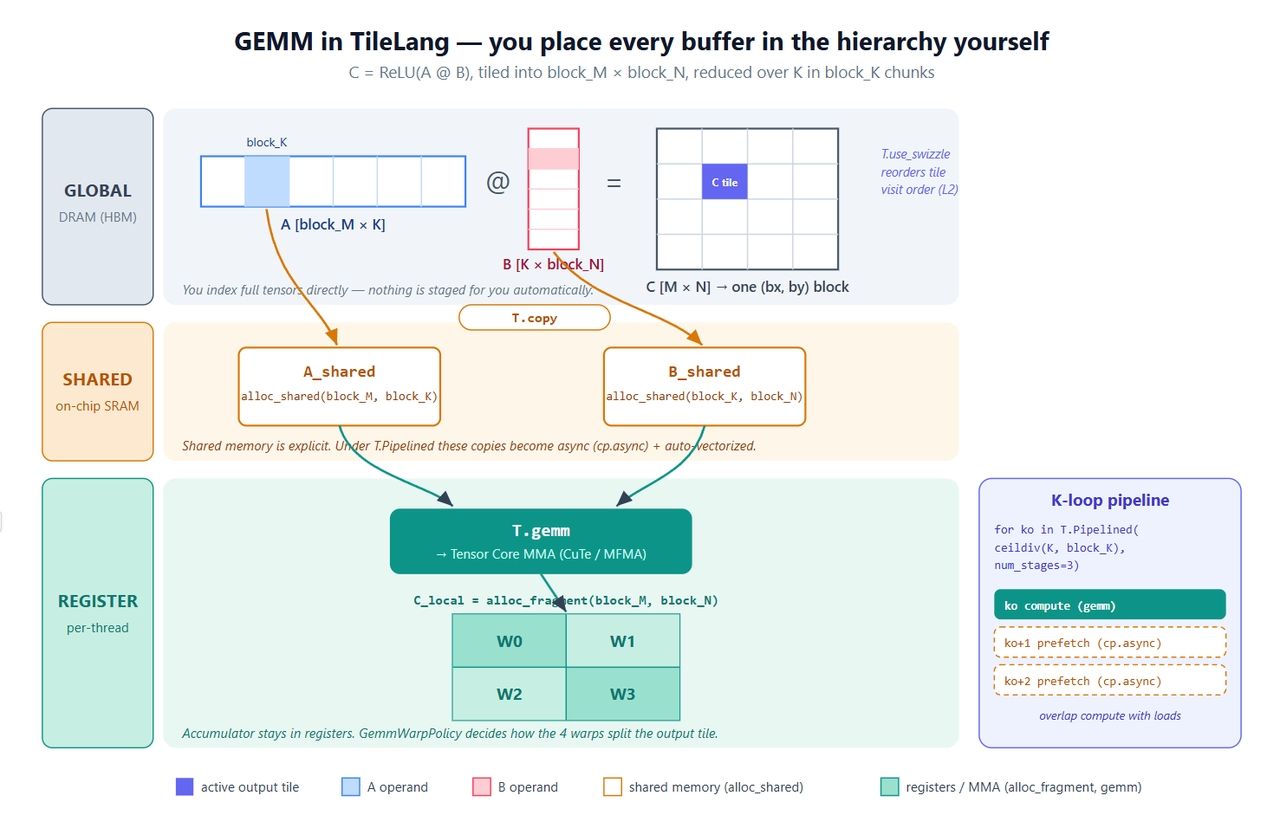
모두가 시작하는 커널인 C = ReLU(A @ B)로 시작해 보겠습니다. 규모는 작지만 명시적 버퍼, 병렬 복사, 소프트웨어 파이프라이닝, 텐서 코어 호출, L2 스위즐(swizzle) 등 중요한 원시 기능들을 모두 포함합니다.
plaintext1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # 그리드 차원: (N방향 블록 수, M방향 블록 수); 블록당 128 스레드 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # 각 타일의 위치를 명시적으로 지정 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # 공유 메모리 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # 레지스터 누산기 23 24 T.use_swizzle(panel_size=4, order="col") # 옵션: 더 나은 L2 재사용성 25 T.clear(C_local) # 누산기 초기화 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # global -> shared 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # 타일 단위 MMA 31 32 for i, j in T.Parallel(block_M, block_N): # 융합된 ReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # 다시 쓰기 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
각 코드의 역할은 다음과 같습니다.
- 세 개의 버퍼, 세 개의 레벨. A_shared와 B_shared는 공유 메모리에, C_local은 레지스터에 존재합니다. 레지스터 누산기와 공유 메모리를 거치는 연산은 GEMM의 표준 레시피이며, 여기서는 사용자가 직접 작성합니다. 이것이 Triton과 다른 점입니다.
- T.copy는 병렬 복사를 위한 문법적 설탕(sugar)입니다. T.Parallel 스타일의 이동으로 확장되며, 컴파일러가 벡터화되고 병합된 global→shared 전송을 유도합니다. T.Pipelined 내부에 있을 경우 자동으로 cp.async로 변환됩니다.
- T.Pipelined(extent, num_stages=N)은 소프트웨어 파이프라인입니다. num_stages=3은 3중 버퍼링을 의미합니다. K-타일 ko를 계산하는 동안, ko+1과 ko+2를 위한 로드가 미리 수행됩니다. Triton에서는 컴파일 플래그인 반면, 여기서는 루프 자체에 정의되어 있어 이해하기 더 쉽습니다.
- T.gemm(A, B, C)는 타일 수준의 행렬 곱셈입니다. NVIDIA 환경에서는 CuTe/MMA로, AMD에서는 해당 내장 함수로 저수준 변환됩니다. 또한 transpose_A / transpose_B 및 warp가 출력 타일을 어떻게 나눌지 제어하는 policy=T.GemmWarpPolicy.* 옵션을 제공합니다. 이 정책 인자는 MLA 커널을 이해하는 핵심입니다.
- T.use_swizzle은 스레드 블록이 스케줄링되는 방식을 재정렬하여 L2 캐시에서 인접한 블록이 시간적으로도 가깝게 실행되도록 합니다. 보통 몇 퍼센트의 대역폭 향상을 가져옵니다.
아래 그림은 이를 하드웨어에 매핑한 모습입니다. 코드와 함께 읽어보세요. 표시된 부분은 Triton이 숨기는 반면 TileLang이 여러분에게 제어권을 돌려주는 정확한 지점입니다.
자주 사용하는 원시 기능들
대부분의 커널은 작은 어휘만으로 작성할 수 있습니다.
- 할당: T.alloc_shared, T.alloc_fragment (레지스터), T.alloc_local.
- 이동 및 초기화: 모든 레벨 간 T.copy(src, dst); T.clear, T.fill.
- 연산: T.gemm(...); 요소별 루프를 위한 T.Parallel(d0, d1, ...) (레이아웃 추론의 진입점); T.reduce_max / T.reduce_sum; T.exp, T.exp2, T.max, T.infinity 같은 스칼라 연산.
- 스케줄: T.Pipelined(extent, num_stages=), T.use_swizzle(...), 특정 레이아웃이 필요할 때 T.annotate_layout(...) (뱅크 충돌 방지, 사용자 정의 스위즐).
- 동적 형태: M = T.dynamic("m") (형태별로 다시 컴파일하지 않음, 일부 버전에서는 T.symbolic).
결과 확인
자주 사용하게 될 두 가지 기능입니다. 컴파일러가 실제로 내보낸 코드를 보려면:
plaintext1print(kernel.get_kernel_source()) # 생성된 CUDA / HIP 코드
성능 측정은 다음과 같습니다:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
T.print(buf)는 커널 내부에서 타일을 출력하며, 저장소의 examples/plot_layout은 메모리 레이아웃을 시각화해 줍니다. 뱅크 충돌을 해결하거나 스위즐을 확인할 때 유용합니다.
실전 사례: MLA 디코드
GEMM은 메커니즘을 보여줍니다. 다음은 그것이 왜 중요한지를 보여줍니다. DeepSeek의 MLA(Multi-Head Latent Attention) 디코드 커널을 살펴보겠습니다. TileLang이 왜 필요한지를 보여주는 가장 깔끔한 예시입니다. TileLang 버전은 FlashMLA의 H100 성능 수준(fp16, 배치 64/128 기준, Triton 및 FlashInfer보다 앞섬)을 약 80줄의 파이썬 코드로 달성합니다. 흥미로운 점은 수학적 복잡성이 아니라 레지스터 압박(register pressure)을 해결하는 과정입니다.
모두가 아는 루프를 다시 보겠습니다. 모든 FlashAttention 계열 커널은 같은 형태를 가집니다. 쿼리 블록별로 키/값 블록을 스트리밍하며 최대값과 분모를 유지하여, 전체 점수 행렬이 메모리에 상주하지 않도록 합니다.
plaintext1# acc_s : [block_M, block_N] 이 KV 블록에 대한 점수 2# acc_o : [block_M, dim] 출력 누산기 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # 이전 출력 재스케일링 9 acc_s = exp(acc_s - scores_max) # 확률 10 acc_o += acc_s @ V[i]
acc_s와 acc_o는 레지스터에 머물러야 합니다. MHA나 GQA에서는 문제없지만, MLA에서는 다릅니다.
어려운 점은 여기서 발생합니다. MLA의 헤드 차원은 매우 큽니다. 쿼리와 키는 576(위치 인코딩이 없는 512 wide "nope" 파트 + 64 wide "rope" 파트), 값은 512입니다. 따라서 acc_o = [block_M, 512]가 되며, 전체 KV 루프 동안 레지스터에 상주해야 합니다.
이제 하드웨어를 고려해 봅시다. Hopper 아키텍처에서 빠른 경로는 wgmma.mma_async입니다. 이는 4개의 워프(128 스레드)를 하나의 워프 그룹으로 묶으며 최소 M값으로 64를 요구합니다. 즉, 하나의 워프 그룹이 소유할 수 있는 최소 M은 64이며, 이는 워프 그룹이 64 × 512 누산기를 보유해야 함을 의미합니다. 이는 단일 워프 그룹의 레지스터 파일에 비해 너무 큽니다. 결과적으로 데이터가 쏟아져 나오며 성능이 급락합니다.
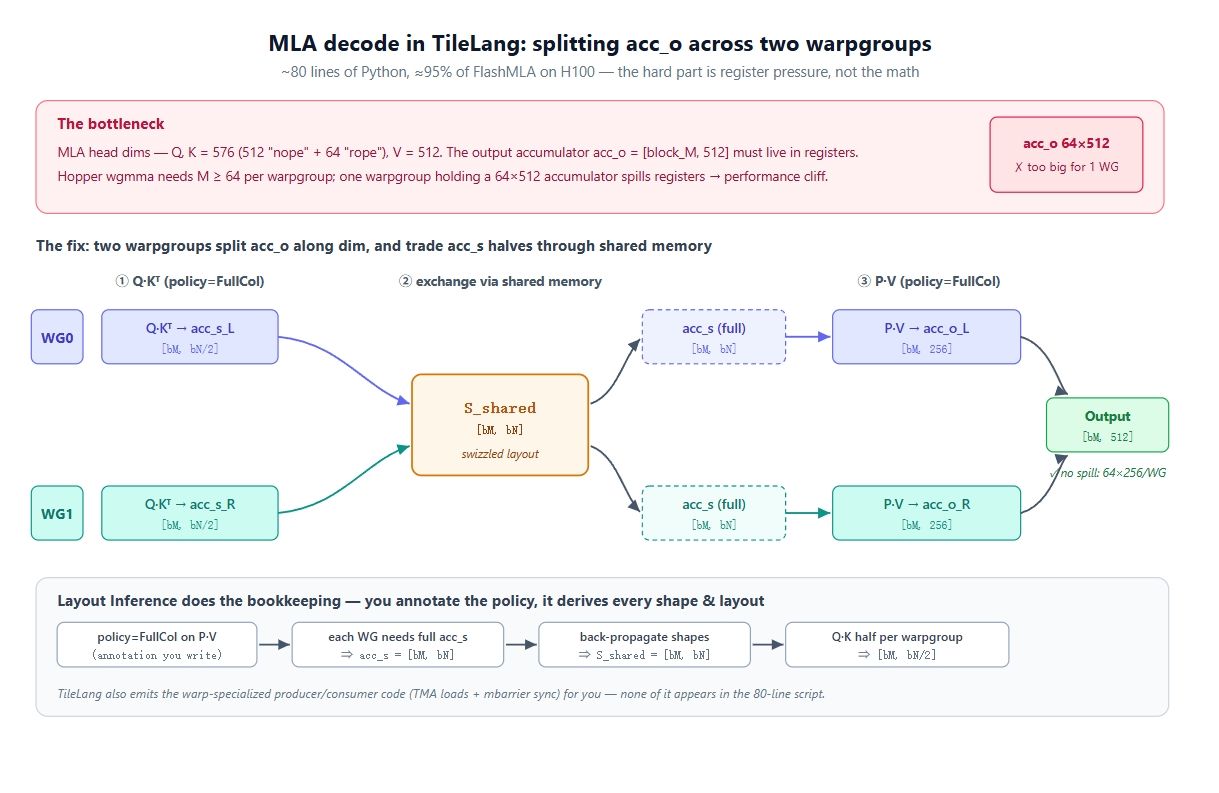
해결책은 출력을 두 워프 그룹으로 분할하는 것입니다. M을 64 이하로 줄일 수 없으므로, 남은 축은 차원(dim)뿐입니다. 두 워프 그룹을 사용합니다. WG0는 acc_o[:, :256]을, WG1은 acc_o[:, 256:]을 소유합니다. 이제 각 그룹은 64 × 256 누산기를 가지며, 이는 레지스터에 적합합니다. 하지만 두 번째 문제가 생깁니다. P @ V 단계(policy=FullCol, 각 워프 그룹이 출력의 한 컬럼 슬랩을 생성)는 전체 acc_s를 필요로 하는데, Q @ K 단계에서는 각 워프 그룹이 절반만 계산했습니다. 해결책은 공유 메모리 스왑입니다. Q @ K 동안 각 워프 그룹은 자신의 절반을 공유 메모리에 쓰고 상대방의 절반을 읽어옵니다. 그 결과 둘 다 전체 acc_s를 갖게 되어 각각 자신의 acc_o 슬랩을 계산할 수 있습니다. 위 그림이 정확히 그 과정입니다.
CuTe였다면 레이아웃, 스위즐, 텐서 코어 정렬, 생산자/소비자 동기화를 손수 작성해야 했을 것입니다. 여기서 80줄로 끝나는 이유는 레이아웃 추론 덕분입니다.
레이아웃 추론의 역할: T.gemm 호출에 의도를 주석으로 달면, 프로그램 전체에 제약 조건이 전파됩니다.
- P @ V에 policy=FullCol을 지정하면, 각 워프 그룹이 전체 acc_s를 필요로 하게 되어 acc_s = [block_M, block_N]이 됩니다.
- 이는 스테이징 버퍼로 전파되어, T.copy(S_shared, acc_s)의 S_shared도 [block_M, block_N]이 됩니다.
- 또한 Q @ K로 전파되어, FullCol 정책에 따라 각 워프 그룹의 점수 슬랩은 [block_M, block_N/2]가 됩니다.
핵심은 이러한 형태(shape)를 단 한 번도 직접 쓰지 않는다는 것입니다. 워프 정책을 선택하고 수학적 연산을 쓰면, 형태, 스위즐된 레이아웃, 워프 특화된 생산자/소비자 코드가 모두 추론을 통해 나옵니다.
커널의 뼈대. MLA 디코드에서 쿼리는 "nope" 파트(Q, dim 512)와 "rope" 파트(Q_pe, dim 64)로 나뉘며, 압축된 latent가 K와 V 역할을 모두 수행합니다. 그래서 점수는 두 GEMM의 합이고, 출력은 하나가 더해집니다.
plaintext1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# 온라인 소프트맥스 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, scores_scale로 acc_o 재스케일, logsum으로 reduce_sum ... 12 13# acc_o += P @ V (V는 동일한 latent KV) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
두 워프 그룹 간의 S_shared 교환은 FullCol 정책이 적용되면 추론 시스템이 자동으로 삽입하는 부분입니다.
좋은 점: 최적화가 줄 단위로 이루어집니다. 성능 툴킷 전체가 한 줄짜리 명령어로 제공되며, 복잡한 저수준 변환은 대신 처리됩니다.
- L2 재사용을 위한 스레드 블록 스위즐링: T.use_swizzle(panel_size, order="row").
- 뱅크 충돌 방지를 위한 공유 메모리 스위즐링: T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)}).
- 워프 특화: 일반적인 스크립트로 작성하면 생산자(TMA 로드) 워프 그룹과 소비자 워프 그룹으로 나뉘며, 모든 mbarrier 동기화가 생성됩니다.
- 파이프라이닝: T.Pipelined(range, num_stages)가 로드와 연산을 오버랩합니다.
- Split-KV (FlashDecoding 스타일): 배치가 작고 SM이 유휴 상태일 때, KV 컨텍스트를 SM 간에 분할하고 병합합니다.
진정으로 어려운 추론 과정(레지스터 예산, 워프 그룹 간 소유권, 공유 메모리 스왑)은 정책 선택과 수학 연산으로 표현합니다. CuTe였다면 수백 줄의 취약한 코드가 되었을 내용들이 추론과 코드 생성으로 해결됩니다.
자체 사례: AtlasCloud의 RMSNorm 커널
마지막 예시는 H100/H200 기반 Wan 비디오 생성 VAE에서 사용한 자체 커널입니다. TileLang의 또 다른 장점을 보여줍니다. 손수 튜닝된 커널이 도달할 수 없는 설정을 깔끔한 드롭인(drop-in) 방식으로 커버합니다.
설정. 이미 최적화된 RMSNorm + SiLU 커널을 운영 중입니다. 특정 모델 구성에 사용하는 은닉 차원 D ∈ {96, 192, 384}에 대해 빠르게 작동합니다. 새로운 설정에는 {160, 256, 320, 512, 640, 1024} 같은 너비가 필요해졌고, 기존 경로는 실행할 수 없었습니다. 그 간극을 메우기 위해 TileLang 드롭인을 작성했습니다.
TileLang 커널. 인터페이스는 동일하고(BTHWC in/out, 동일 수학, 동일 eps), 32의 배수인 모든 C를 지원합니다. 두 번의 패스, 완전 병합, FP32 누산기:
plaintext1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W 행 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # FP32 제곱합 8 # 패스 1: BLOCK_C 단위로 C를 순회, FP32로 제곱합 누적 9 # rinv = rsqrt(ss / C + 1e-5) 10 # 패스 2: X 재로드, y = silu(x * gamma * rinv), 쓰기
얻은 성과. 호출 지점의 변경 없이 기존 디스패치 뒤에 배치되는 진정한 드롭인 방식입니다.
| 구분 | 성과 |
|---|---|
| 기존 미지원 구성 | 0 → 1 — 이제 작동함 |
| 기존 PyTorch Norm 대체 | 42 μs → 20 μs (~2배 빠름) |
| 실무 해상도 VAE End-to-End | ~1.79배 인코드, ~1.78배 디코드 |
TileLang 덕분에 기존에 최적화 경로가 없던 모델 구성까지 지원하게 되었으며, 기존 커널을 전혀 건드리지 않았습니다. 파이썬으로 작성된 이 드롭인 하나가 전체 모델 경로를 정상화했습니다.
TileLang이 빛나는 지점
- CUTLASS/CuTe를 쓰지 않고도 블로킹, 파이프라인, 워프 파티셔닝을 세밀하게 제어할 수 있습니다.
- GEMM 변형, FlashAttention 계열, MLA, 선형 어텐션 등 구조적으로 복잡하고 레이아웃에 민감한 커널에 적합합니다.
- 기존 커널이 도달할 수 없는 구성(은닉 차원 확장, 특이한 레이아웃 등)을 커버하며, eager 모드보다 훨씬 빠릅니다.
- 여러 백엔드(NVIDIA / AMD)를 하나의 커널 코드로 대응할 수 있습니다.
- 최적화 툴킷 전체가 T.use_swizzle, T.annotate_layout, T.Pipelined 등 한 줄 호출로 가능하며 저수준 변환은 알아서 처리됩니다.
결론
TileLang의 멋진 점은 어려운 추론 과정이 보일러플레이트 코드가 아니라 여러분의 머릿속에 머문다는 것입니다. 워프 간 작업 분할, 버퍼 위치, 파이프라인 깊이를 결정하면 레이아웃 추론과 워프 특화 기술이 이를 수백 줄의 CuTe 코드에 버금가는 결과물로 만들어 줍니다. 정책을 선택하고 수학을 작성하세요. 80줄짜리 MLA 커널이 손수 튜닝된 CUTLASS 커널과 나란히 놓일 수 있는 이유입니다.






