Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Verken Toonaangevende Modellen
Seedance v1.5 Pro Image-to-Video
Native audio-visual joint generation model by ByteDance. Supports unified multimodal generation with precise audio-visual sync, cinematic camera control, and enhanced narrative coherence.
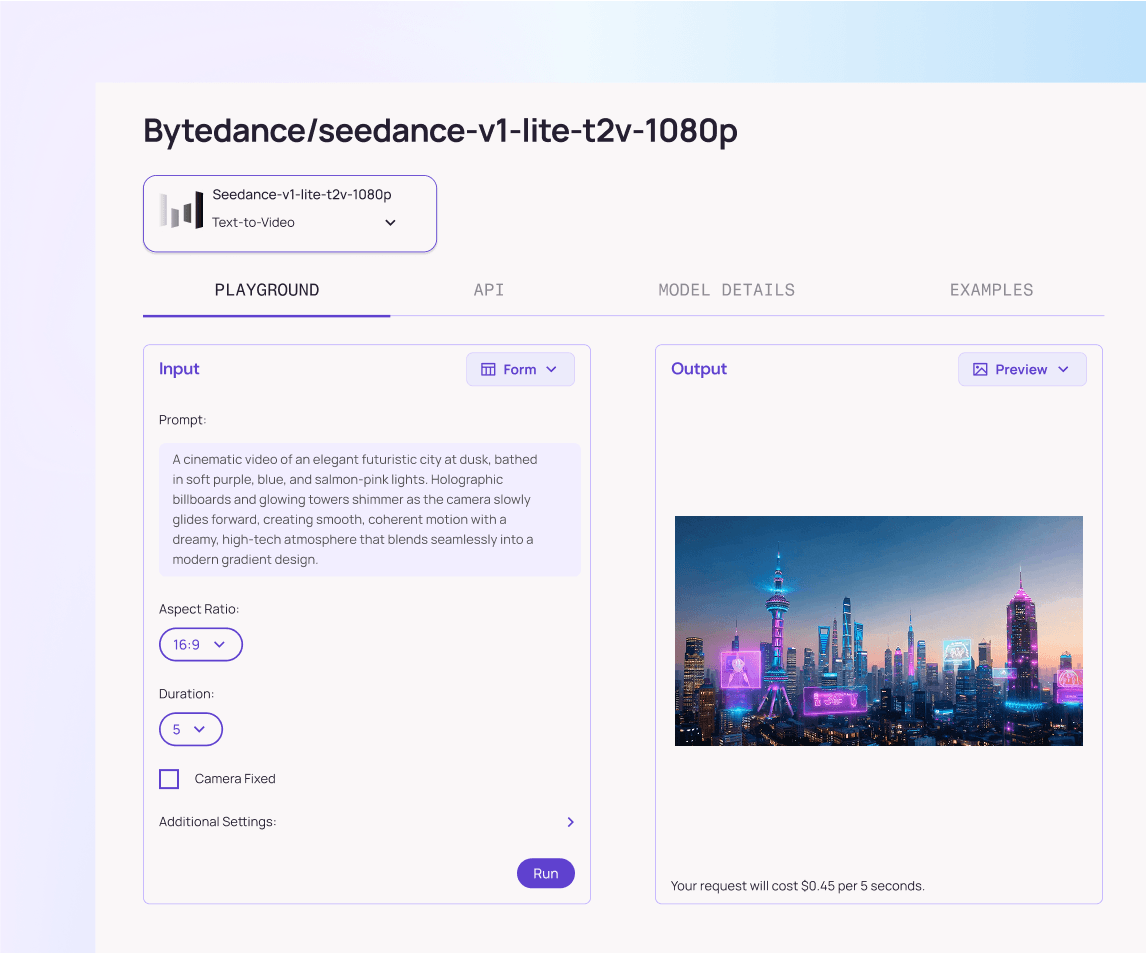
Seedance v1.5 Pro Text-to-Video
Native audio-visual joint generation model by ByteDance. Supports unified multimodal generation with precise audio-visual sync, cinematic camera control, and enhanced narrative coherence.
Wat Opvalt - Seedance 1.5 Video Models

I2V & T2V
Support generating video from text prompts and single images (multi-shot included).

Native Audio Generation
Can generate diverse voices and spatial sound effects that coordinate with the visuals to deliver a smoother storytelling.

Precision Lip-Sync
Support a wide range of languages and dialects with great lip-sync and motion alignment.

Film-Grade Cinematography
Capable of complex camera movement, from close-ups with subtle facial expressions and emotions, to full-shots with cinematic level of details, composition, and atmosphere.

Multi-Resolution
Produce 480p, 720p, or 1080p video to balance quality and performance needs.

Production Ready
Optimized for fast deployment, scaling, and enterprise workloads.
Wat U Kunt Doen - Seedance 1.5 Video Models
Generate 480p, 720p, or 1080p video from text prompts or static images.
Produce explainer videos, ads, and social content at scale.
Refine videos with direct or sequential editing.
Customize workflows with adjustable speed and fidelity.
Strong Storytelling and Emotional Expression.
Waarom Seedance 1.5 Video Models Gebruiken Op Atlas Cloud
De combinatie van Seedance 1.5 Video Models's geavanceerde modellen met het GPU-versnelde platform van Atlas Cloud biedt ongeëvenaarde prestaties, schaalbaarheid en ontwikkelaarservaring.
First-person POV from the front seat of a giant steel roller coalster. The coaster crests the peak and plunges straight down into a dark tunnel. Surrounding scenery (an amusement park at sunset) is slightly blurred, while the wind is represented as whistling air particles.
Prestatie & Flexibiliteit
Lage Latentie:
GPU-geoptimaliseerde inferentie voor realtime reasoning.
Uniforme API:
Voer Seedance 1.5 Video Models, GPT, Gemini en DeepSeek uit met één integratie.
Transparante Prijzen:
Voorspelbare op tokens gebaseerde facturering met serverloze opties.
Onderneming & Schaling
Ontwikkelaarservaring:
SDK's, analytics, fine-tuning tools en sjablonen.
Betrouwbaarheid:
99,99% beschikbaarheid, RBAC en compliance-ready logging.
Beveiliging & Compliance:
SOC 2 Type II, HIPAA-afstemming, gegevenssoevereiniteit in VS.
Verken Meer Families
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.
Z.ai LLM Models
The Z.ai LLM family pairs strong language understanding and reasoning with efficient inference to keep costs low, offering flexible deployment and tooling that make it easy to customize and scale advanced AI across real-world products.
Seedance 1.5 Video Models
Seedance is ByteDance’s family of video generation models, built for speed, realism, and scale. Its AI analyzes motion, setting, and timing to generate matching ambient sounds, then adds creative depth through spatial audio and atmosphere, making each video feel natural, immersive, and story-driven.
Moonshot LLM Models
The Moonshot LLM family delivers cutting-edge performance on real-world tasks, combining strong reasoning with ultra-long context to power complex assistants, coding, and analytical workflows, making advanced AI easier to deploy in production products and services.
Wan2.6 Video Models
Wan 2.6 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. Wan 2.6 will let you create videos of up to 15 seconds, ensuring narrative flow and visual integrity. It is perfect for creating YouTube Shorts, Instagram Reels, Facebook clips, and TikTok videos.
Flux.2 Image Models
The Flux.2 Series is a comprehensive family of AI image generation models. Across the lineup, Flux supports text-to-image, image-to-image, reconstruction, contextual reasoning, and high-speed creative workflows.
Nano Banana Image Models
Nano Banana is a fast, lightweight image generation model for playful, vibrant visuals. Optimized for speed and accessibility, it creates high-quality images with smooth shapes, bold colors, and clear compositions—perfect for mascots, stickers, icons, social posts, and fun branding.
Image and Video Tools
Open, advanced large-scale image generative models that power high-fidelity creation and editing with modular APIs, reproducible training, built-in safety guardrails, and elastic, production-grade inference at scale.
Ltx-2 Video Models
LTX-2 is a complete AI creative engine. Built for real production workflows, it delivers synchronized audio and video generation, 4K video at 48 fps, multiple performance modes, and radical efficiency, all with the openness and accessibility of running on consumer-grade GPUs.
Qwen Image Models
Qwen-Image is Alibaba’s open image generation model family. Built on advanced diffusion and Mixture-of-Experts design, it delivers cinematic quality, controllable styles, and efficient scaling, empowering developers and enterprises to create high-fidelity media with ease.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Hailuo Video Models
MiniMax Hailuo video models deliver text-to-video and image-to-video at native 1080p (Pro) and 768p (Standard), with strong instruction following and realistic, physics-aware motion.
Wan2.5 Video Models
Wan 2.5 is Alibaba’s state-of-the-art multimodal video generation model, capable of producing high-fidelity, audio-synchronized videos from text or images. It delivers realistic motion, natural lighting, and strong prompt alignment across 480p to 1080p outputs—ideal for creative and production-grade workflows.

Alleen bij Atlas Cloud.

