MiniMax LLM Models
As a premier suite of Large Language Models (LLMs) developed by MiniMax AI, MiniMax is engineered to redefine real-world productivity through cutting-edge artificial intelligence. The ecosystem features MiniMax M2.5, which is purpose-built for high-efficiency professional environments, and MiniMax M2.1, a model that offers significantly enhanced multi-language programming capabilities to master complex, large-scale technical tasks. By achieving SOTA performance in coding, agentic tool use, intelligent search, and office workflow automation, MiniMax empowers users to streamline a wide range of economically valuable operations with unparalleled precision and reliability.
Verken Toonaangevende Modellen
Atlas Cloud biedt u de nieuwste toonaangevende creatieve modellen in de industrie.
Wat MiniMax LLM Models Onderscheidt
Atlas Cloud biedt u de nieuwste toonaangevende creatieve modellen uit de industrie.
Redeneren op frontier-niveau
State-of-the-art taalmodellen gebouwd voor diepgaande redenering, complexe probleemoplossing en planning in meerdere stappen.
Begrip van ultra-lange context
Lightning-stijl attention en een geoptimaliseerde architectuur stellen MiniMax-modellen in staat om lange contexten te verwerken en te behouden,
Kostenefficiënte MoE-prestaties
Mixture-of-Experts-ontwerpen bieden hoge intelligentie, lage latentie en een aanzienlijk betere prijs-prestatieverhouding.
Veelzijdige modelfamilie
Van krachtige modellen voor algemeen gebruik tot varianten die zijn geoptimaliseerd voor coderen en agenten.
Betrouwbaarheid van ondernemingsniveau
Stabiele, schaalbare infrastructuur met monitoring en veiligheid voor productiegebruik.
Open & ontwikkelaarsvriendelijk
Rijke API's, SDK's en open-weight releases geven ontwikkelaars de flexibiliteit om te integreren, te finetunen of zelf te hosten.
Pieksnelheid
Laagste kosten
| Model | Beschrijving |
|---|---|
| MiniMax M2.5 | MiniMax M2.5 is een toonaangevend LLM dat is geoptimaliseerd voor productiviteit in de echte wereld en integreert geavanceerde inferentie-architecturen met uitgebreide contextverwerkingsmogelijkheden van 196,61K; met SOTA-prestaties in kantoorautomatisering en intelligent zoeken, dient het als een uiterst efficiënte engine voor het beheren van economisch waardevolle taken en complexe algemene redeneringen in professionele omgevingen. |
| MiniMax M2.1 | MiniMax M2.1 is een krachtig LLM dat is afgestemd op complexe technische uitdagingen, waarbij aanzienlijk verbeterde meertalige programmering wordt geïntegreerd met een robuuste contextverwerking van 196.61K; met uitzonderlijke precisie in het gebruik van agent-tools dient het als basis voor het bouwen van geavanceerde taakplannings-Agents en het oplossen van ingewikkelde, grootschalige technische problemen. |
| MiniMax M2 | MiniMax M2 is een SOTA general-purpose LLM, die zeer efficiënte redeneermodules integreert met uitgebreide 196.61K contextverwerkingsmogelijkheden; met een competitieve veelzijdigheid in coding, zoekopdrachten en professionele workflows, dient het als een betrouwbare hoeksteen voor dagelijkse bedrijfsactiviteiten die een naadloze integratie van meerstaps taakuitvoering vereisen. |
Nieuwe functies van MiniMax LLM Models + Showcase
De combinatie van geavanceerde modellen met het GPU-versnelde platform van Atlas Cloud biedt ongeëvenaarde snelheid, schaalbaarheid en creatieve controle voor beeld- en videogeneratie.
Geavanceerd programmeren en agent-planning met MiniMax M2.5
MiniMax M2.5 ondersteunt meer dan 10 programmeertalen, waaronder Rust, Go en Python, om uitgebreide full-stack ontwikkeling op web-, mobiele en desktopplatforms te vergemakkelijken. Door diepgaande branchekennis te integreren voor professionele documentopmaak en financiële modellering, maakt het naadloze overgangen mogelijk van systeemarchitectuurontwerp naar uiteindelijke leveringstests. Het is de definitieve oplossing voor complexe software-engineering en workflows voor kantoorproductiviteit met hoge belangen.
Snelle respons en efficiëntie in taakbeslissingen met MiniMax M2.5
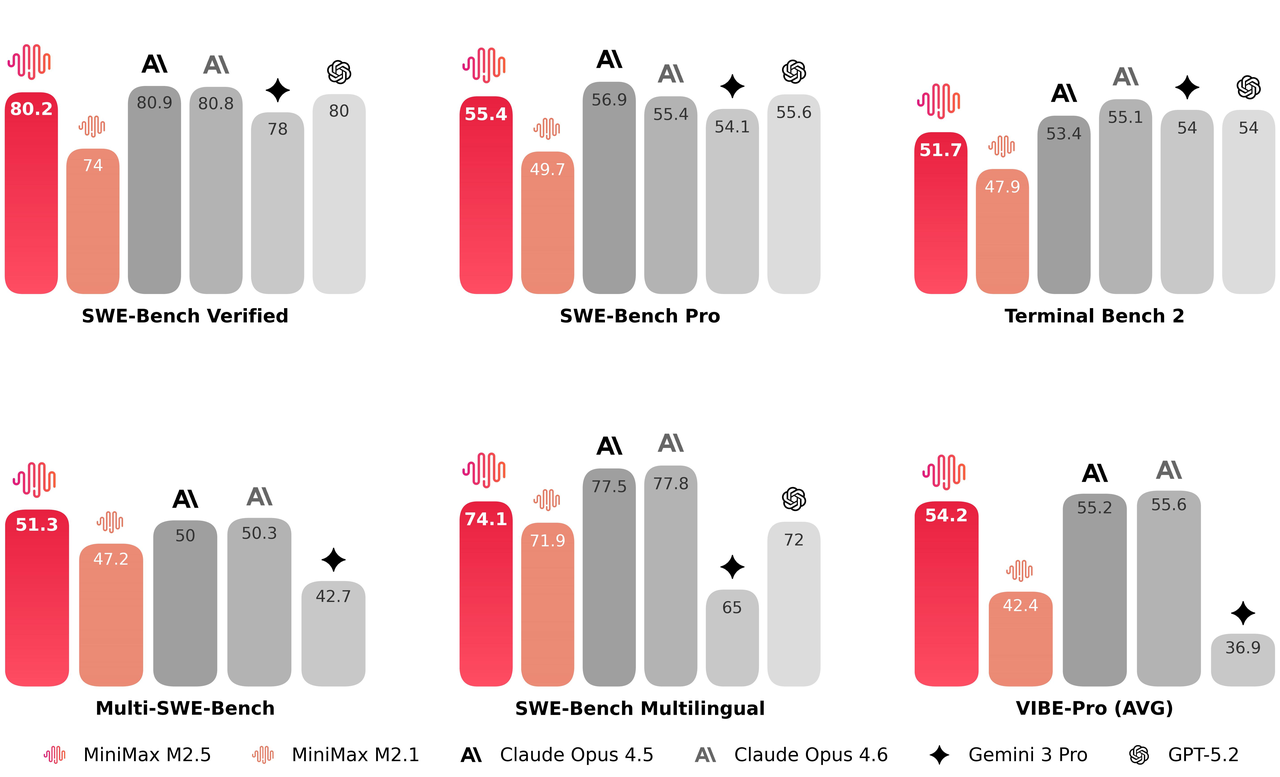
De M2.5-architectuur behaalt een snelheidsverhoging van 37% in end-to-end uitvoering, waardoor de duur van complexe taken op de SWE-bench aanzienlijk wordt teruggebracht van 31,3 naar 22,8 minuten. Door de logica voor taakdecompositie te optimaliseren, heeft het model 20% minder tokens en zoekrondes nodig om doelen te bereiken in benchmarks zoals BrowseComp. Het biedt een gestroomlijnde oplossing voor snelle besluitvorming en elimineert tegelijkertijd redundante rekenkundige overhead.
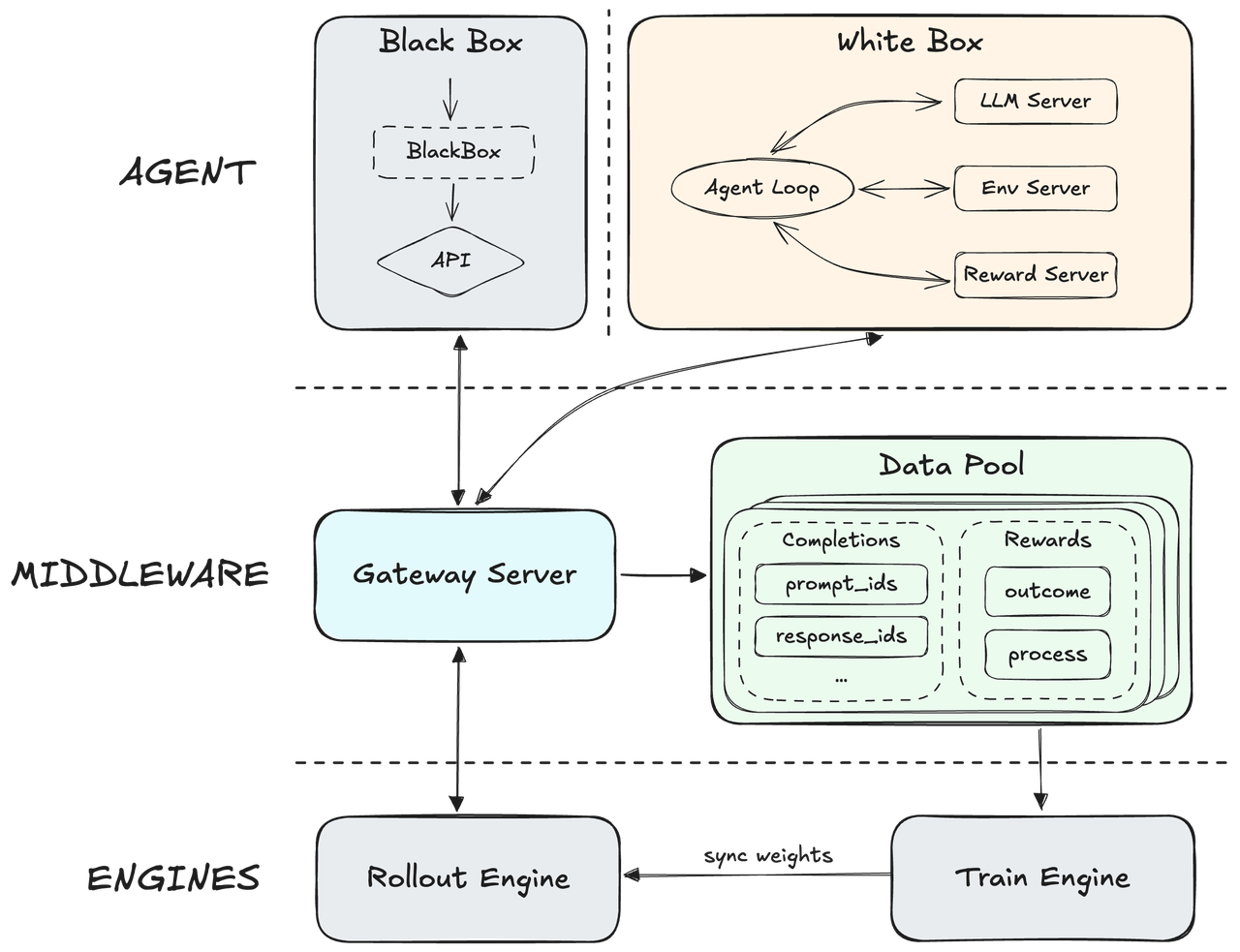
Evolutionaire architectuur door grootschalige Reinforcement Learning met MiniMax M2.5
Gebouwd op een native Agent RL-framework, ontkoppelt MiniMax zijn kernmotor van de agent-scaffolding om te generaliseren over honderdduizenden diverse echte omgevingen. Het bevat een geavanceerd procesbeloningsmechanisme dat real-time uitvoeringsfeedback gebruikt om redeneerpaden te verfijnen en een elite uitvoerkwaliteit te garanderen. Dit creëert een zeer adaptief systeem dat in staat is superieure nauwkeurigheid te behouden terwijl de algehele operationele reactiesnelheid wordt gemaximaliseerd.
Wat U Kunt Doen met MiniMax LLM Models
Ontdek praktische use cases en workflows die u kunt bouwen met deze modelfamilie — van contentcreatie en automatisering tot productie-grade applicaties.
Productieklaar Full-Stack debugging met MiniMax M2.5
MiniMax M2.5 fungeert als een senior technisch architect die logische fouten opspoort in backend-API's, databases en frontend-frameworks zoals React of Swift. In plaats van eenvoudige fragmenten, refarctort het hele modules om systeembrede compatibiliteit te garanderen. De API is ideaal voor rapid prototyping en verwerkt alles, van omgevingsconfiguratie tot edge-case testing en de modernisering van legacy-code voor bedrijfssystemen.
Professionele financiële modellering en rapportage met MiniMax M2.5
Voor analisten die absolute precisie vereisen, automatiseert de API complexe financiële modellering in Excel en genereert publicatieklare onderzoeksrapporten volgens professionele investeringskaders. Het interpreteert ruwe data om risicobeheersingslogica en professionele presentaties met gestandaardiseerde opmaak te construeren. Dit past in risicovolle consulting- en bankomgevingen waar nauwkeurigheid en naleving van formele rapportagestandaarden ononderhandelbaar zijn.
Autonoom webonderzoek in meerdere stappen met MiniMax M2.5
MiniMax M2.5 voert complexe zoekopdrachten in meerdere rondes uit om uiteenlopende webinformatie samen te voegen tot samenhangende executive briefs. Door brede zoekopdrachten intelligent op te splitsen en te browsen met minimale token-redundantie, vermijdt het cirkelredeneringen om geverifieerde feiten te leveren. Het is een krachtige tool voor marktonderzoekers en strategieteams die diepgaande inlichtingen nodig hebben zonder handmatig honderden bronnen te hoeven filteren.
Modelvergelijking
Bekijk hoe modellen van verschillende aanbieders zich verhouden — vergelijk prestaties, prijzen en unieke sterke punten voor een weloverwogen beslissing.
| Model | Context | Maximale uitvoer | Invoer | Positionering |
|---|---|---|---|---|
| MiniMax M2.5 | 196.61K | 196.61K | Tekst | State-of-the-art agent-gebaseerd programmeren |
| MiniMax M2 | 196.61K | 196.61K | Tekst | Model met hoge prestaties |
| MiniMax M2 | 196.61K | 196.61K | Tekst | Algemeen vlaggenschip |
| GLM-5 | 202.75K | 202.75K | Tekst | Vlaggenschip-funderingsmodel |
| DeepSeek V3.2 | 163.84K | 163.84K | Tekst | Vlaggenschip Algemeen |
How to Use MiniMax LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Waarom MiniMax LLM Models Gebruiken Op Atlas Cloud
De combinatie van MiniMax LLM Models's geavanceerde modellen met het GPU-versnelde platform van Atlas Cloud biedt ongeëvenaarde prestaties, schaalbaarheid en ontwikkelaarservaring.
Prestatie & Flexibiliteit
Lage Latentie:
GPU-geoptimaliseerde inferentie voor realtime reasoning.
Uniforme API:
Voer MiniMax LLM Models, GPT, Gemini en DeepSeek uit met één integratie.
Transparante Prijzen:
Voorspelbare op tokens gebaseerde facturering met serverloze opties.
Onderneming & Schaling
Ontwikkelaarservaring:
SDK's, analytics, fine-tuning tools en sjablonen.
Betrouwbaarheid:
99,99% beschikbaarheid, RBAC en compliance-ready logging.
Beveiliging & Compliance:
SOC 2 Type II, HIPAA-afstemming, gegevenssoevereiniteit in VS.
Veelgestelde Vragen over MiniMax LLM Models
We bieden drie hoofdversies aan: MiniMax M2.5 (het vlaggenschip voor kantoorproductiviteit en zoeken), MiniMax M2.1 (verbeterd voor programmeren en complexe logica) en MiniMax M2 (het gebalanceerde algemene model).
De MiniMax M2-serie ondersteunt uniform een ultralange context van 196,61K, waardoor het honderden pagina's aan technische documentatie of enorme technische codebases in één verzoek kan verwerken.
In SWE-bench end-to-end tests heeft M2.5 de verwerkingstijd voor complexe taken teruggebracht van 31,3 minuten naar 22,8 minuten, wat neerkomt op een toename van 37% in de algehele snelheid van taakvoltooiing.
Verken Meer Families
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
Grok-Imagine Models
Grok Imagine Image Quality is xAI's latest AI image generation model, delivering studio-grade visuals with up to 2K resolution and razor-sharp detail. It offers best-in-class text rendering across multiple languages, photorealistic outputs with natural lighting, rich textures, and believable physics, plus tighter prompt following and image editing with reference inputs for precise creative control. Ideal for hero images, ad creatives, product renders, and brand-grade visuals.
Gemini Omni
Gemini Omni (by Google DeepMind) is a video generation and editing model launched on May 20, 2026 at Google I/O that redefines the standard for "reasoning-driven creation," built specifically to solve the core challenge of AI video: making output that actually understands what you mean, not just what you type. It fuses Gemini's reasoning engine with generative capability, accepting any mix of images, text, video, and audio to produce consistent, knowledge-grounded output. Unlike models that start from scratch each time, Omni lets you edit through natural conversation — swapping objects, rewriting scenes, shifting styles — while keeping physics, characters, and continuity intact across every turn.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.


