Lançamento da Preview do DeepSeek-V4: Contexto de 1M de Tokens, Melhorias em Agentes e Pesos Open Source
Hoje (24 de abril), a DeepSeek lançou e disponibilizou oficialmente o código aberto da versão preview do DeepSeek-V4, sua nova série de modelos.
O DeepSeek-V4 suporta até um milhão de tokens de contexto e alcança um desempenho líder entre modelos domésticos e open source em capacidades de agentes, conhecimento de mundo e raciocínio. A série conta com dois tamanhos:
- DeepSeek-V4-Pro — o modelo carro-chefe, é um modelo MoE (Mixture of Experts) massivo com 1,6 trilhão de parâmetros totais, mas apenas 49B ativados por passagem direta — este é o segredo da sua eficiência.
- DeepSeek-V4-Flash — a opção mais rápida e com melhor custo-benefício. Segue o mesmo design MoE em uma escala muito menor (284B totais / 13B ativos), permitindo uma inferência mais rápida e barata.
- Ambos os modelos compartilham a mesma janela de contexto de 1M de tokens e são totalmente open source com acesso via API.
| Modelo | Parâmetros | Ativação | Dados de Pré-treino | Comprimento de Contexto | Open Source | Serviço de API | Modo de Acesso (Web/App) |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | Modo Expert |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | Modo Rápido |
A partir de hoje, você pode conversar com o DeepSeek-V4 em chat.deepseek.com ou via aplicativo oficial. A API também está ativa — basta definir model_name como deepseek-v4-pro ou deepseek-v4-flash para começar.
Já havíamos reportado as especulações e análises pré-lançamento (veja nosso guia de expectativas para o DeepSeek V4 e nossa análise técnica detalhada), e agora temos detalhes oficiais confirmados diretamente da fonte. A seguir, cobrimos exatamente o que foi lançado, as novidades e o que isso significa para quem está desenvolvendo ou avaliando modelos de IA hoje.
DeepSeek-V4-Pro: Rivalizando com os Principais Modelos Proprietários
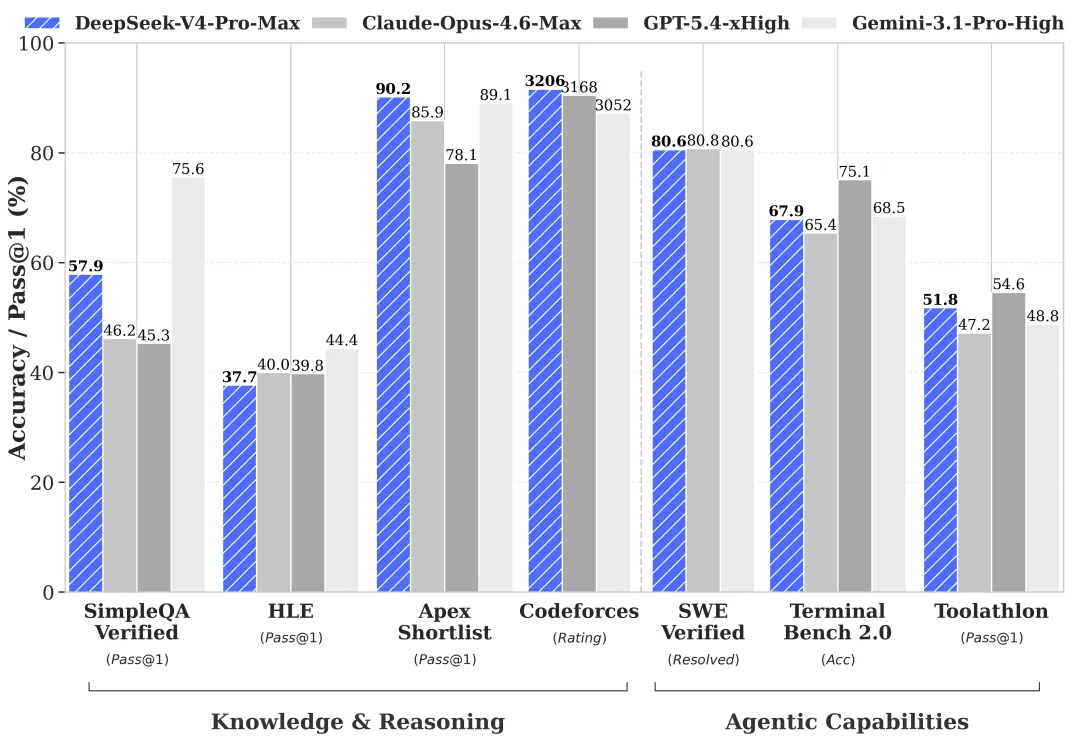
Capacidades de agentes significativamente aprimoradas. Comparado ao seu antecessor, o DeepSeek-V4-Pro mostra uma melhoria dramática em tarefas de agentes. Em benchmarks de codificação com agentes (Agentic Coding), o V4-Pro agora lidera entre todos os modelos open source. A DeepSeek também implantou o V4-Pro internamente como o agente de codificação preferencial da empresa — o feedback dos funcionários indica que a experiência supera o Claude Sonnet 4.5, com qualidade de saída aproximando-se do Claude Opus 4.6 no modo "sem pensamento" (non-thinking), embora ainda atrás do modo de raciocínio (thinking mode) do Opus 4.6.
Rico conhecimento de mundo. O DeepSeek-V4-Pro supera significativamente outros modelos open source em benchmarks de conhecimento geral, ficando apenas um pouco abaixo do principal modelo proprietário, o Gemini Pro 3.1.
Raciocínio de classe mundial. Em avaliações de matemática, STEM e programação competitiva, o DeepSeek-V4-Pro supera todos os modelos open source avaliados anteriormente e iguala o desempenho dos principais modelos proprietários do mundo.
DeepSeek-V4-Flash: A Escolha Rápida e Acessível
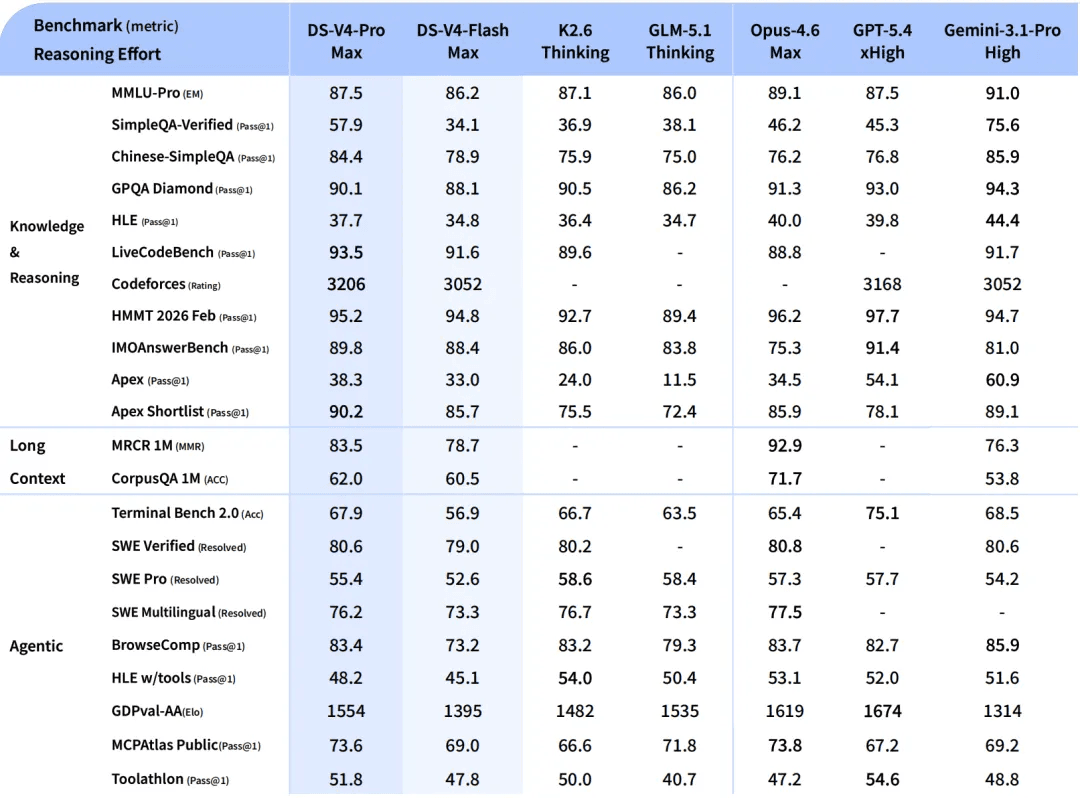
Comparado ao V4-Pro, o DeepSeek-V4-Flash fica um pouco atrás em conhecimento de mundo, mas entrega um desempenho de raciocínio comparável. Graças à sua menor contagem de parâmetros e menores custos de ativação, o V4-Flash oferece tempos de resposta mais rápidos e preços de API mais econômicos.
Em benchmarks de agentes, o V4-Flash iguala o V4-Pro em tarefas simples, embora ainda exista uma lacuna em tarefas mais complexas.
Inovação Arquitetural e Eficiência de Contexto Extrema
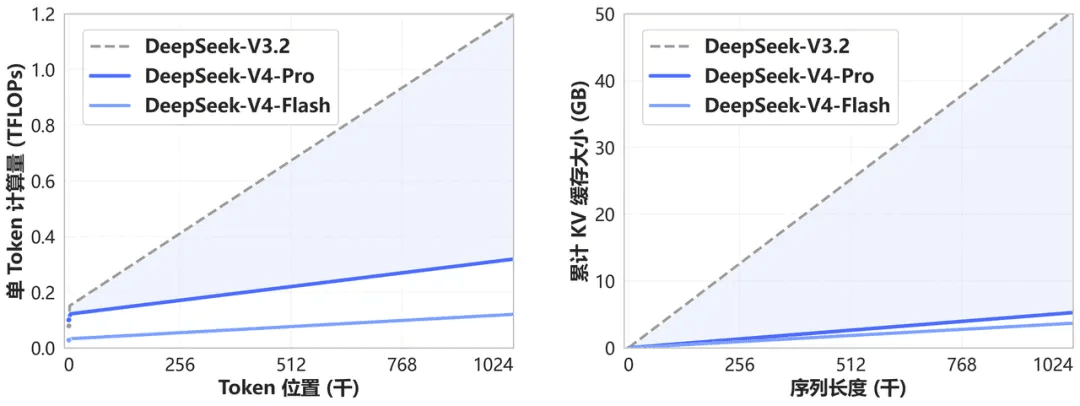
O DeepSeek-V4 introduz um novo mecanismo de atenção que realiza compressão na dimensão dos tokens. Combinado com DSA (DeepSeek Sparse Attention), este design alcança um desempenho de contexto longo líder mundial, reduzindo drasticamente os requisitos computacionais e de memória em comparação com as abordagens convencionais.
De agora em diante, o contexto de 1M (um milhão) de tokens é o padrão para todos os serviços oficiais da DeepSeek.
Otimização Especializada para Casos de Uso de Agentes
O DeepSeek-V4 foi ajustado e otimizado para produtos de agentes populares, incluindo Claude Code, OpenClaw, OpenCode e CodeBuddy. Melhorias de desempenho foram observadas em geração de código, criação de documentos e outras tarefas impulsionadas por agentes.
Esse tipo de ajuste específico para frameworks importa mais na prática do que parece. Um modelo que funciona bem isoladamente, mas se comporta de forma inconsistente dentro de um loop de agente estruturado, é difícil de implantar com confiabilidade. A decisão de tratar os principais frameworks de agentes como alvos de otimização de primeira classe reflete como o uso de IA em produção evoluiu.
Acesso à API do DeepSeek-V4
Tanto o V4-Pro quanto o V4-Flash estão agora disponíveis via API da DeepSeek, com suporte para as interfaces OpenAI ChatCompletions e Anthropic, o que significa que integrações existentes podem ser direcionadas aos modelos V4 com o mínimo de alterações de código. A base_url permanece inalterada; basta atualizar o parâmetro de modelo para deepseek-v4-pro ou deepseek-v4-flash.
Ambos os modelos suportam um comprimento máximo de contexto de 1M de tokens e oferecem modos sem pensamento (non-thinking) e com pensamento (thinking). No modo de raciocínio, um parâmetro reasoning_effort pode ser definido como high ou max. Para fluxos de trabalho complexos de agentes, recomenda-se o uso do modo de raciocínio com intensidade máxima. Documentação para acesso à API: https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ Aviso de descontinuação: Os nomes de modelos legados
deepseek-chatedeepseek-reasonerserão desativados em três meses (24 de julho de 2026). Durante o período de transição, eles mapeiam para os modos sem pensamento e com pensamento dodeepseek-v4-flash, respectivamente. Se você estiver usando qualquer um dos nomes em produção, planeje sua migração agora.
Pesos Open Source & Implantação Local
- Pesos do modelo:Hugging Face | ModelScope
- Relatório técnico:PDF do DeepSeek-V4
Para equipes que consideram implantação local ou on-premise, vale notar que modelos nesta escala de parâmetros, particularmente o V4-Pro com 1,6T de parâmetros totais, exigem hardware substancial. A disponibilidade open source é uma vantagem significativa para casos de conformidade empresarial e customização, mas a maioria das equipes achará o acesso à API em nuvem um ponto de partida mais prático.
O que este lançamento do DeepSeek-V4 realmente significa
Três pontos se destacam neste lançamento.
Primeiro, o compromisso com 1M de contexto é mais significativo do que parece. A DeepSeek não está oferecendo isso como uma camada premium — é o padrão para todos os serviços oficiais. Isso sinaliza para onde a fronteira do open source está indo e coloca uma pressão silenciosa em todos os outros provedores para que sigam o mesmo caminho.
Segundo, o trabalho de otimização focado em agentes — especificamente adaptando o V4 para Claude Code, OpenCode e outros — reflete uma maturidade na forma como a DeepSeek pensa sobre implantação. Desempenho em benchmark é o básico; o que importa para a produção é o comportamento dentro das ferramentas que os desenvolvedores realmente usam.
Terceiro, o posicionamento competitivo honesto em relação ao Claude Opus 4.6 é notável. Em vez de alegar superioridade total, a DeepSeek faz uma avaliação estratificada: melhor que o Sonnet 4.5, aproximando-se do Opus 4.6 no modo "sem pensamento", e atrás do modo de raciocínio do Opus 4.6. Essa especificidade torna as alegações mais, e não menos, credíveis.
Para desenvolvedores avaliando modelos para fluxos de trabalho de agentes, processamento de documentos longos ou tarefas de raciocínio complexo, o DeepSeek-V4-Pro é agora um competidor open source sério. Para pipelines otimizados por custo ou sensíveis à latência, o V4-Flash oferece uma alternativa mais leve e confiável.
Experimente o DeepSeek-V4 na Atlas Cloud
Atlas Cloud é uma plataforma de IA de nível de produção projetada para desenvolvedores e equipes que desejam acesso confiável e econômico aos principais modelos de IA do mundo sem gerenciar infraestrutura. Com uma API unificada, precificação transparente e conformidade de nível empresarial (alinhada a SOC 2 e pronta para HIPAA), a Atlas Cloud permite que você foque na construção, e não em operações.
DeepSeek na Atlas Cloud. Já suportamos a família de modelos DeepSeek, incluindo DeepSeek V3.2, V3.2 Fast, V3.2 Speciale e V3.2 Exp disponíveis hoje via um único endpoint de API com preços competitivos. Os modelos DeepSeek na Atlas Cloud são otimizados para cargas de trabalho de contexto longo e pipelines de agentes, com suporte total à janela de contexto e sem perda por quantização. Além da DeepSeek, a Atlas Cloud oferece acesso a mais de 300 modelos em todo o cenário de LLMs.
O DeepSeek-V4 está chegando à Atlas Cloud. Estamos trabalhando ativamente na integração do DeepSeek-V4-Pro e V4-Flash. Fique atento ao anúncio de lançamento — e, enquanto isso, explore tudo o que já está disponível na plataforma.






