
Você conhece a sensação.
É tarde da noite. Você já está na quarta revisão de uma campanha de marca. A IA acabou de gerar a iluminação perfeita na cena principal — mas o rosto do seu modelo mudou sutilmente pela terceira vez hoje. Mesma roupa. Pessoa diferente. Você não pode publicar. Você não pode consertar. Você começa do zero.
À meia-noite, você já não está mais editando um vídeo. Você está jogando roleta russa.
Para quem tenta construir uma continuidade narrativa — uma demonstração de produto com o mesmo modelo em várias tomadas, um tutorial com o mesmo professor em várias cenas, um videoclipe com o mesmo cantor em vários cortes — a "deriva de personagem" (character drift) tem sido a assassina silenciosa de todas as ferramentas de vídeo por IA. É por isso que o vídeo por IA vive no purgatório das "demos legais" em vez de se tornar comercial.

Em 19 de maio, no I/O 2026, o Gemini Omni do Google defendeu que essa era está chegando ao fim.
Toda a promessa se resume a uma linha na página de produto do Google DeepMind: "Cada edição que você faz se baseia na anterior — mantendo uma cena consistente e coerente."
A Demo do Violinista em Três Passos que Silenciosamente Fez História
O momento mais importante do anúncio do I/O não foi a bola de gude rolando. Não foi a escultura de bolhas. Foi um violinista.
Aqui está a sequência exata que o Google mostrou no palco e publicou em seu blog:
- Passo um: Um vídeo básico de um violinista tocando uma música no palco.
- Passo dois: Prompt — "Transporte o violinista para o ambiente da imagem." Resultado: o músico é movido para um novo fundo, mas o rosto, a postura, a empunhadura do arco e até o ângulo do pulso permanecem idênticos.
- Passo três: Outro prompt — "Mude o ângulo da câmera para ficar sobre o ombro do violinista." Resultado: novo enquadramento. O mesmo violinista. A mesma identidade. A mesma performance.
Três turnos. Um sujeito. Zero deriva.
Se você passou um tempo significativo com as ferramentas de vídeo por IA atuais, isso parece trapaça. Não é. É a primeira prova pública de que o refinamento em múltiplos turnos — o fluxo de trabalho que cineastas, publicitários e educadores esperavam — é tecnicamente real e pronto para o mercado.
Por que a Consistência em Múltiplos Turnos tem sido a Ferida Aberta do Vídeo por IA
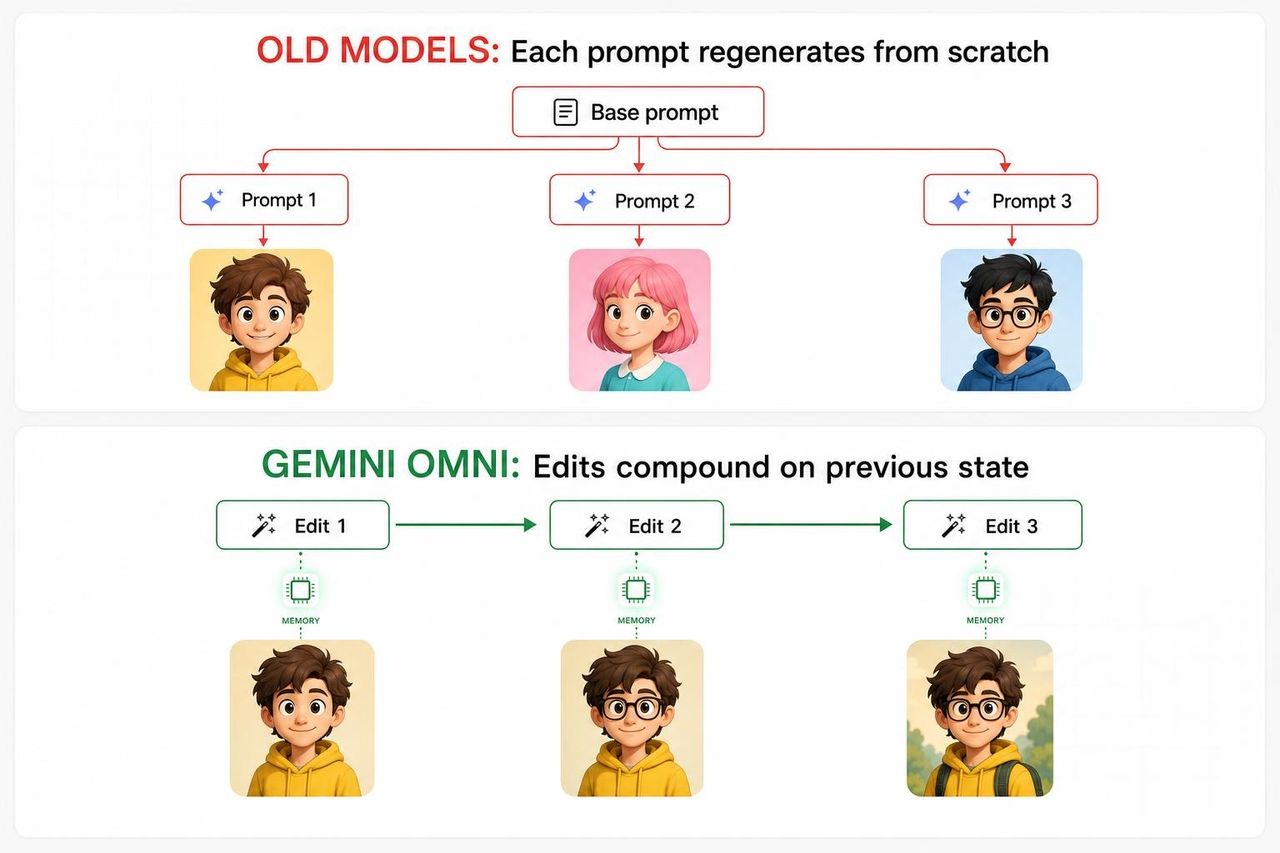
Para entender por que a demo do violinista é importante, você precisa entender onde todos os outros modelos de vídeo por IA estão falhando.
Em pipelines de vídeo generativo tradicionais, cada novo prompt essencialmente regenera a cena do zero — usando o prompt original mais o novo prompt como entradas combinadas. O modelo não tem uma continuidade interna real entre os turnos. Rostos mudam. Objetos de fundo desaparecem. A iluminação muda. No terceiro turno, o resultado divergiu tanto da visão original que os criadores desistem e recomeçam.
A causa raiz é arquitetônica. A maioria dos modelos de vídeo foi treinada como geradores de "tiro único", não como agentes multirturno. Eles foram otimizados para produzir uma única melhor saída a partir de um prompt — não para lembrar do que produziram anteriormente e refinar a partir daí. Pedir para eles "editarem" era, na prática, pedir que começassem do zero com contexto extra, e a matemática dessa operação produzia uma deriva composta, não um refinamento composto.
A abordagem do Omni é diferente. Ele foi construído como um editor com estado (stateful editor) — significando que cada turno atualiza uma representação persistente da cena, em vez de regenerá-la do zero.
O que "A Cena Lembra" Realmente Significa
A imprensa de tecnologia em inglês tem convergido para a mesma conclusão, com suas próprias palavras.
O Decrypt descreveu o avanço com clareza: "O Google diz que o Omni pode manter os mesmos personagens, planos de fundo e movimentos consistentes mesmo após os usuários fazerem alterações em um vídeo — algo com que muitos modelos de vídeo por IA sofrem."
O Android Central destacou o detalhe técnico chave: "A empresa também diz que o modelo recorda comandos anteriores durante revisões de várias etapas, o que pode tornar a edição iterativa muito menos caótica."
O TechRadar enquadrou de forma cinematográfica: "Personagens permanecem reconhecíveis. Cenas mantêm a continuidade. O movimento permanece coerente em vez de reiniciar toda vez que um prompt muda."
E o Phandroid resumiu toda a capacidade em cinco palavras: "A cena lembra o que veio antes."
Esse é o ponto principal. A cena lembra. Essa propriedade única é a diferença entre o vídeo por IA como um brinquedo e o vídeo por IA como uma ferramenta.
Como o Omni se compara ao Sora, Veo e Seedance em Consistência
Veja como os principais modelos de vídeo por IA se comparam especificamente em consistência multirturno até maio de 2026:
| Modelo | Edição Multirturno | Refinamento Conversacional | Consistência de Personagem (Medium) | Status Atual |
| Gemini Omni Flash | Stateful, multirturno | Chat nativo | (3/5) | Disponível 19 maio, 2026 |
| Sora 2 (OpenAI) | Regeneração de tiro único | Limitado | Descontinuado | App encerrado; API encerra set 2026 |
| Veo 3.1 (Google) | Parcial | Apenas texto + imagem | Menor que Omni | Live, sendo descontinuado pelo Omni |
| Seedance 2.0 (ByteDance) | Baseado em referência, não iterativo | Limitado | (4/5) | Live; rank #1 no Art. Analysis Video Arena |
A leitura honesta: Omni é o único modelo com edição multirturno verdadeiramente stateful. O Seedance pontua mais alto na consistência de personagem bruta (segundo o revisor do Medium) ao alavancar até 9 imagens de referência por geração — mas ele não consegue manter essa consistência através de uma sessão de edição. O Sora está saindo do mercado consumidor. O Veo está sendo absorvido.
De "Reroll" para "Refinar" — O que essa mudança de fluxo desbloqueia

O valor real aqui não é a demo. É a transformação do fluxo de trabalho.
A Blockchain.news descreveu melhor a implicação comercial: "A edição em lote permite modificações simultâneas em vários segmentos de vídeo para acelerar a produção, mantendo os padrões de qualidade em conteúdo gerado por IA. Criadores de conteúdo cinematográfico, publicitário e educacional ganham vantagens significativas através de custos reduzidos e maior confiabilidade narrativa."
Essa última frase — confiabilidade narrativa — é a parte que deveria importar para qualquer pessoa que trabalhe com conteúdo.
Até agora, o vídeo por IA podia entregar um bom clipe. Não conseguia entregar uma campanha — uma série de clipes com o mesmo protagonista, os mesmos ativos de marca, a mesma linguagem visual através de múltiplas entregas. Cada edição era um cara ou coroa. Agora, as edições se acumulam.
O TechTimes resumiu o conjunto de capacidades demonstradas publicamente como "ações de edição e objetos em filmagens de usuários, transferência de estilo entre aparências realistas e animadas, refinamento multirturno e geração de estilo explicativo."
E a análise prática do DataCamp confirmou que o comportamento multirturno se manteve na prática: "O Omni suporta edição multirturno, para que você possa refinar detalhes, ambientes e ângulos de câmera passo a passo enquanto mantém a cena consistente."
A mudança de fluxo parece pequena no papel. Na prática, é enorme: gerar → regenerar → regenerar → desistir torna-se gerar → refinar → refinar → publicar.
Os desenvolvedores estão percebendo. No fórum chinês V2EX, um engenheiro que testou o Omni no dia do lançamento escreveu: "A velocidade de geração e a consistência superaram minhas expectativas."
Quando engenheiros de IA e criadores na linha de frente chegam à mesma observação horas após o lançamento, você está olhando para uma mudança real de capacidade — não marketing.
O Ceticismo Honesto — O Omni Ainda Não é Perfeito
Antes que alguém declare que o problema de consistência está resolvido, aqui está a dose de realismo.
Um revisor no AI Analytics Diaries no Medium testou o Omni contra o Seedance 2.0 da ByteDance e deu à consistência de personagem do Omni uma nota 3 de 5.
A frase que deveria estar no monitor de todo gerente de produto de vídeo por IA: "Ambos os modelos sofrem com a consistência de personagem em múltiplos cortes — isso continua sendo a ferida aberta do vídeo por IA."
Tradução: o Omni é materialmente melhor que qualquer outro modelo público no refinamento multirturno dentro de uma única sessão de edição. Ainda não é um problema resolvido na categoria mais ampla.
Onde está a lacuna restante?
- A consistência multirturno de cena única funciona extremamente bem (a demo do violinista)
- A consistência entre cortes (mesmo personagem, diferentes cenas, diferentes configurações de iluminação, diferentes enquadramentos) ainda é imperfeita
- Detalhes sutis — detalhes faciais finos, articulação das mãos, texturas específicas de roupas — ainda podem sofrer deriva após muitas edições
- O limite atual de 10 segundos de clipe no Omni Flash significa que a consistência multirturno ainda não foi testada sob estresse em trabalhos narrativos de longa duração
Para 80% dos casos de uso — refinamento de cena única, conteúdo com duração para redes sociais, ativos de marketing — o Omni já é bom o suficiente para publicar. Para os 20% restantes — o trabalho de qualidade cinematográfica onde a continuidade do personagem precisa sobreviver a uma sequência de 30 tomadas — ainda é necessária uma limpeza editorial.
O que isso realmente muda — Setor por Setor
Se a consistência multirturno agora está resolvida (ou quase resolvida em uma única sessão), eis o que é desbloqueado:
Para publicitários de marca: Continuidade de campanha. Uma marca de moda finalmente pode gerar dez variações do mesmo modelo principal em dez cenários — sem refilmagens, sem encontrar novos talentos, sem pagar por dez retoques manuais. A matemática na produção criativa para redes sociais muda em uma ordem de grandeza.
Para educadores e criadores de tutoriais: Consistência de série. Um único apresentador gerado por IA pode conduzir um curso inteiro — do episódio um ao doze — sem que o público perceba que são sintéticos. O problema do "rosto consistente através do conteúdo" matou os educadores por IA por dois anos. Acaba de ser consertado.
Para cineastas: Pré-visualização em escala. O mesmo ator através de múltiplas propostas de cena, múltiplas configurações de iluminação, múltiplos ângulos de câmera — tudo gerado em uma única sessão, tudo refinável iterativamente. O intervalo entre "tenho uma ideia" e "posso mostrar ao diretor" encolhe de dias para minutos.
Para equipes de e-commerce: Imagens principais de produtos que combinam entre variações de listagem. Mesmo modelo, seis roupas, fotos de estilo de vida, fotos de estúdio, fotos em ambiente — tudo consistente, tudo publicável, tudo gerado a partir da mesma sessão multirturno.
Para desenvolvedores de jogos: NPCs que parecem o mesmo NPC através das cenas cortadas. O calcanhar de Aquiles das cinemáticas por IA em jogos tem sido o fato de que o protagonista mudava sutilmente entre as cenas. A edição stateful do Omni torna o travamento de personagem comercialmente viável.
A Tensão da Proveniência — Fakes Consistentes são Mais Difíceis de Detectar
Há uma implicação mais sombria nesse avanço que vale a pena mencionar diretamente.
Melhor consistência multirturno significa fakes mais difíceis de detectar. Os "sinais" clássicos de que algo foi gerado por IA — um rosto se transformando entre cortes, mãos mudando de forma, cabelo mudando de cor — são exatamente o que a consistência corrige. À medida que o Omni e seus sucessores melhoram na continuidade interna, a lacuna entre "obviamente sintético" e "indistinguível do real" fecha rapidamente.
É precisamente por isso que cada clipe gerado pelo Omni é enviado com a marca d'água invisível SynthID do Google e Credenciais de Conteúdo C2PA incorporadas no momento da geração. Verificável dentro do app Gemini, Chrome e Busca. Não é opcional. Não é um recurso que você pode desativar.
É também por isso que o Google deliberadamente reteve a edição de fala e áudio em vídeos existentes: "Ainda estamos trabalhando para testar isso e entender melhor como podemos levar essa capacidade aos usuários com responsabilidade." Tradução: o risco de deepfake de um rosto consistente + uma voz modificada é alto demais para lançar sem salvaguardas em vigor.
Para marcas e criadores, o cálculo está mudando. À medida que a detecção do olho humano de conteúdo "fake" se torna não confiável, a proveniência criptográfica torna-se o novo padrão para autenticidade de conteúdo. Cada vitória de consistência vem acompanhada de uma obrigação de proveniência.
O Novo Gargalo Não é a Qualidade. É a Dispersão de Modelos.
Veja o que isso significa estrategicamente para quem constrói produtos sobre vídeo por IA.
A lacuna de capacidade entre os modelos líderes está diminuindo rapidamente — e fragmentando rapidamente ao mesmo tempo. Em meados de 2026:
- Gemini Omni lidera em consistência multirturno e edição conversacional
- Seedance 2.0 lidera em movimento cinematográfico e animação estilizada, com consistência de personagem baseada em referência mais forte
- Outros especialistas lideram em geração de longa duração, controle de personagem refinado, sincronização de áudio ou processamento em lote de baixo custo
O modelo melhor em consistência neste trimestre provavelmente não é o modelo melhor em movimento cinematográfico neste trimestre. O modelo com a melhor física hoje não é o que terá a melhor sincronização de áudio daqui a seis meses. E cada um deles é enviado com seu próprio SDK, fluxo de autenticação, nível de preço, peculiaridades de limite de taxa e termos de contrato. Sua equipe pode facilmente queimar um sprint de engenharia por integração — e outro sprint por obsolescência.
Este é exatamente o problema de fragmentação que a Atlas Cloud foi construída para resolver. Damos aos desenvolvedores um endpoint unificado único para acessar mais de 300 modelos — todos os principais modelos de fundação, lançamentos open-source líderes e especialistas em movimento rápido em imagem, vídeo, áudio e raciocínio. O acesso ao Gemini Omni chegará à Atlas Cloud nas próximas semanas, portanto, no momento em que você estiver pronto para trocar sua stack para testá-lo, a integração já estará feita para você.
O que isso significa na prática para sua equipe:
- Troque de modelo com uma única linha de código — sem reescrever integrações de SDK toda vez que um novo estado da arte surge
- Execute avaliações lado a lado em prompts idênticos — descubra qual modelo realmente vence para o seu caso de uso específico antes de comprometer o orçamento
- Publique o modelo mais forte para cada capacidade — o líder em consistência multirturno hoje, o líder em movimento cinematográfico amanhã, o líder em eficiência de custos no próximo trimestre
- Um dashboard para faturamento, observabilidade e limites de taxa — em vez de doze contas separadas para gerenciar
Para construtores que publicam produtos de vídeo por IA em 2026, a chamada arquitetônica inteligente não é "apostar no Omni". É "construir sobre uma camada de abstração que permite trocar para o que quer que vença a seguir." Quando o Gemini Omni chegar à Atlas Cloud, você poderá testá-lo contra o Seedance, contra o próximo modelo revolucionário, contra o que vier depois disso — sem alterar uma única linha de código de integração.
Em um mercado onde consistência, física, movimento cinematográfico e fidelidade de áudio são cada um liderados por um modelo diferente, ficar preso a qualquer um deles é a pior dívida técnica possível a assumir. A Atlas Cloud é a camada de abstração que transforma essa fragmentação de uma taxa em um impulso.
Uma API Unificada para Geração de Vídeo de Produção
Enquanto o Google lança o Gemini Omni Flash dentro do app Gemini e do Google Flow para usuários finais, desenvolvedores e equipes de produto que desejam incorporar o mesmo motor de vídeo multimodal em seus próprios fluxos de trabalho precisam de uma camada de API estável e previsível.
A Atlas Cloud oferece o Gemini Omni Flash através de uma API unificada compatível com OpenAI, ao lado de mais de 300 outros modelos de imagem, vídeo e LLM — para que você possa integrar o modelo multimodal nativo do Google sem manipular contas de fornecedores separadas, portais de faturamento ou SDKs.
Ambas as variantes do Gemini Omni Flash estão disponíveis na Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Melhor Para | Entradas | Resolução | Duração | Preço Inicial |
| Gemini Omni Flash Text-to-Video (Developer) | Geração cinematográfica via prompt | Texto (até 20.000 chars) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |
| Gemini Omni Flash Image-to-Video (Developer) | Vídeo consistente de referências reais | Texto + até 7 imagens ref. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |
Início Rápido — Gere um vídeo Gemini Omni Flash em 5 linhas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
A API retorna um ID de previsão imediatamente — consulte /api/v1/model/prediction/{id} para obter a URL do MP4 renderizado. O esquema completo, amostras de código em 7 linguagens e um Playground sem código estão disponíveis nas páginas dos modelos vinculadas acima.
Insights Principais
A razão pela qual a consistência multirturno importa não é a demo. É o desbloqueio.
Por cinco anos, toda conversa sobre "quando o vídeo por IA se tornará comercial?" batia na mesma parede: o momento em que os modelos puderem manter um personagem consistente entre as edições. Essa parede acabou de ser movida.
A demo do violinista não é uma acrobacia. É a primeira vez que um grande laboratório colocou um fluxo de trabalho de edição multirturno real e funcional no palco. Na próxima vez que uma equipe de marketing pedir a uma ferramenta de vídeo por IA para produzir seis clipes do mesmo produto em seis cenários, eles devem esperar seis saídas utilizáveis — não seis rostos sem relação.






