A maioria das pessoas ainda pensa que palavras melhores equivalem a imagens melhores. Isso era verdade há dois anos. Não é mais.
Em 2026, a verdadeira lacuna não é entre os modelos. É entre os usuários que descrevem e os usuários que constroem. Um grupo digita “iluminação cinematográfica, 4k, ultra detalhado”. O outro grupo constrói cenas — direção de luz, camadas de profundidade, ângulos de câmera.
Se suas imagens ainda parecem planas, o problema provavelmente não é o modelo. É o que você não está dizendo a ele.
Por que seus prompts não são suficientes (Perspectiva de 2026)
Prompts genéricos deixaram de funcionar. Os modelos já viram frases como “melhor qualidade” e “alta definição” milhões de vezes. Essas palavras quase não fazem diferença agora.
O que realmente importa? Entradas estruturadas. De onde vem a luz? O que está no primeiro plano versus o segundo plano? Qual lente você está usando? Os modelos modernos respondem a essas variáveis. Eles ignoram o excesso.
Aqui está um padrão comum. Alguém escreve: “um belo retrato com iluminação suave”. O modelo entrega algo plano. Por quê? Sem direção de luz. Sem separação de profundidade. Sem ângulo de câmera. O modelo precisa adivinhar. E adivinhar leva a resultados medianos.
A mudança que você precisa fazer é simples. Pare de descrever o resultado. Comece a construir a cena.
As 7 Dicas Avançadas
-
Diga à luz para onde ir
“Iluminação suave” é vago. Iluminação lateral, contraluz, de cima para baixo — essas dão ao modelo algo concreto. A direção cria sombras. Sombras criam profundidade. Profundidade faz uma imagem parecer real.
Tente isto em vez de “iluminação de retrato suave”:
Um retrato de uma mulher, iluminação lateral vindo da esquerda, sombras suaves no lado direito do rosto, luz ambiente sutil vindo do fundo

Você pode ver a diferença imediatamente. O modelo sabe exatamente onde a luz está posicionada.
-
Use configurações reais de fotografia
Iluminação de três pontos. Luz de contorno (rim light). Iluminação Rembrandt. Estes não são apenas termos sofisticados. São padrões que o modelo viu milhares de vezes durante o treinamento. Use-os e seus resultados se tornarão mais estáveis.
Exemplo:
Foto de produto de um tênis, configuração de iluminação de três pontos, luz principal forte, luz de preenchimento suave, luz de contorno sutil separando o produto de um fundo escuro

Isso funciona melhor do que “iluminação dramática” sempre.
-
Construa profundidade camada por camada
Imagens planas geralmente significam que tudo está no mesmo plano. Corrija isso nomeando explicitamente o primeiro plano, o plano médio e o fundo.
Exemplo:
Uma xícara de café sobre uma mesa de madeira (primeiro plano), uma pessoa trabalhando em um laptop (plano médio), um interior de café suavemente desfocado com luzes quentes (fundo)

Agora o modelo tem relações espaciais com as quais trabalhar.
-
Use linguagem de câmera, não rótulos de estilo
“Estilo cyberpunk” é impreciso. “Lente 35mm, ângulo baixo, plano aberto” é preciso. As configurações de câmera mapeiam diretamente como as imagens são construídas.
Mantenha estas em seu repertório:
- 35mm para um visual natural e cotidiano
- 85mm para retratos com compressão
- Grande-angular para drama e escala
- Ângulo baixo, ao nível dos olhos, de cima para baixo para perspectiva
Exemplo:
Um retrato em close, lente 85mm, profundidade de campo rasa, ângulo ao nível dos olhos, desfoque de fundo suave

Isso dá ao modelo instruções muito mais claras do que “retrato estético”.
-
Guie a atenção através do contraste
Alta definição em toda parte não é o objetivo. O contraste sim. Luz versus sombra. Quente versus frio. Assunto nítido versus fundo desfocado.
Três tipos de contraste funcionam bem:
- Contraste de luz: assunto brilhante contra um fundo escuro
- Contraste de cor: holofote quente sobre um fundo de tons frios
- Contraste de detalhe: assunto nítido, ambiente desfocado
Exemplo:
Um assunto iluminado por um holofote quente contra um fundo escuro de tons frios, iluminação de alto contraste, foco forte no assunto
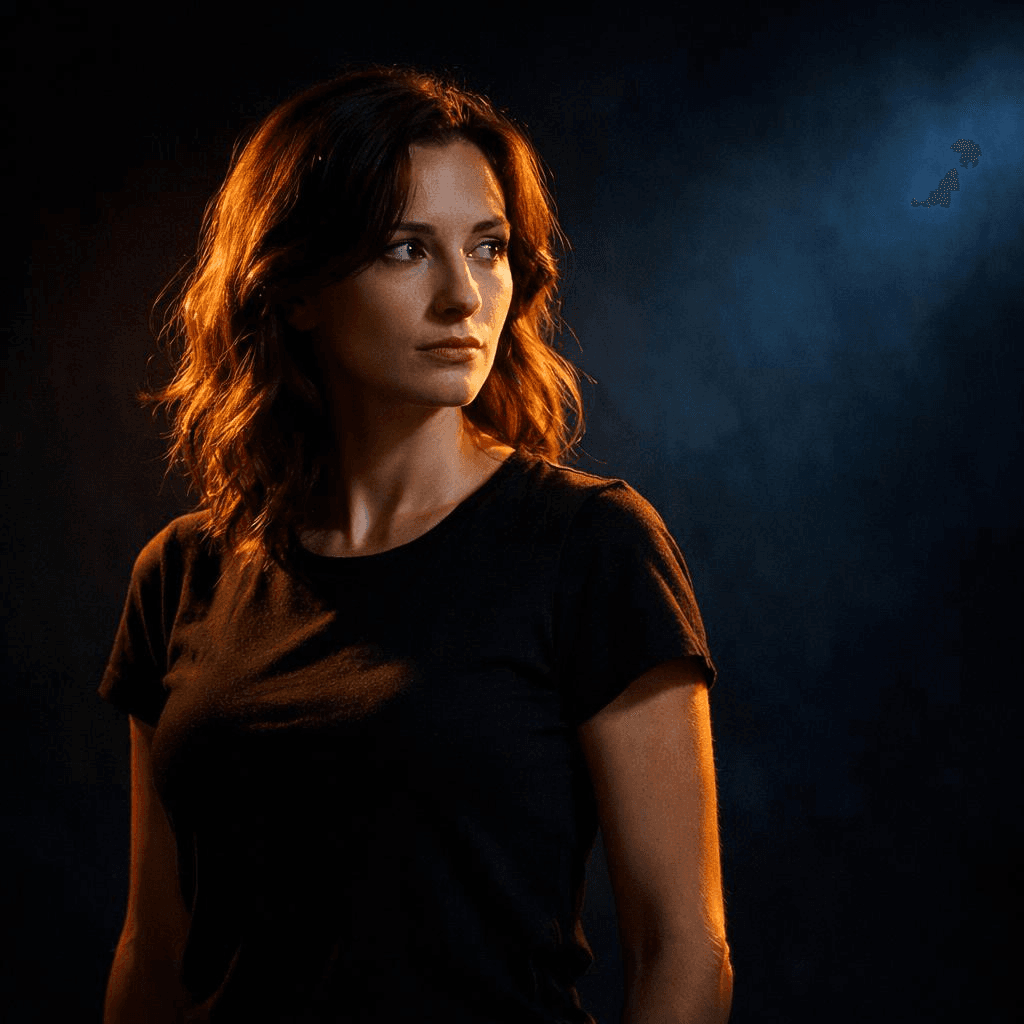
O olhar do espectador vai exatamente para onde você deseja.
-
Adicione restrições para limpar o caos
Prompts longos ficam confusos. Em vez de adicionar mais detalhes, adicione limites. Diga ao modelo o que você não quer. Sem desordem. Sem distorção. Sem objetos extras.
Exemplo:
Foto de produto minimalista, composição centralizada, fundo branco limpo, sem desordem, sem texto, sem distorção

Restrições muitas vezes fazem mais do que descrições extras.
-
Itere como um diretor, não como um apostador
Ninguém consegue a imagem final na primeira tentativa. Profissionais geram, ajustam, geram novamente.
Um fluxo de trabalho simples:
- Passo um: composição básica, assunto e ambiente
- Passo dois: adicione iluminação direcional e contraste
- Passo três: refine detalhes, remova desordem
Cada passagem melhora o resultado. É assim que você passa da sorte para a consistência.
Juntando tudo — Uma estrutura profissional de prompts
Pare de escrever prompts como frases longas. Escreva-os como sistemas modulares.
Aqui está uma estrutura que funciona:
plaintext1[Assunto] + [Ambiente] + [Iluminação] + [Câmera] + [Composição] + [Cor] + [Restrições]
Observe a diferença entre um prompt básico e um estruturado.
Exemplo: Do Prompt Básico ao Prompt Profissional
Prompt Básico (Usuário Típico):
Uma modelo feminina vestindo um vestido de verão branco, fundo limpo, iluminação de estúdio, alto detalhe, estilo e-commerce

Prompt Profissional (Estruturado):
Uma modelo feminina vestindo um vestido de verão branco (assunto), em um estúdio minimalista com fundo bege texturizado (ambiente), iluminação lateral vindo da direita criando sombras suaves no lado esquerdo do corpo, luz de contorno sutil separando a silhueta do fundo (iluminação), fotografada com lente 85mm, ângulo ao nível dos olhos (câmera), assunto levemente descentralizado com profundidade de campo rasa, desfoque de primeiro plano suave adicionando profundidade (composição), tons naturais quentes, contraste suave (cor), composição limpa, sem desordem, sem distorção, sem objetos extras (restrições)

Conclusão — Do Prompting para a Direção
Conseguir uma única ótima imagem é bom. Mas projetos reais precisam de centenas de visuais consistentes e de alta qualidade. O prompting manual não escala.
Você encontrará problemas práticos. Latência. Custo por imagem. Manter o mesmo estilo visual em lotes. Apenas o design de prompt não pode resolver isso. Você precisa de um sistema.
É aí que a geração de imagens via API se torna essencial. Em vez de digitar prompts em um playground toda vez, você integra a geração ao seu fluxo de trabalho. Prompts estruturados são reutilizados. Automatizados. Otimizados ao longo do tempo.
Plataformas como Atlas Cloud fornecem uma camada de API unificada para isso.
E se você for:
• Desenvolvedor buscando acesso à IA fácil e acessível. • Equipe gerenciando projetos que precisam de IA em várias áreas. • Empresa que precisa de IA confiável para trabalhos importantes. • Pessoa usando ferramentas como ComfyUI e n8n.
Experimente o Atlas Cloud e você verá a transição da experimentação para a produção. Sem necessidade de reconstruir a infraestrutura do zero.
O futuro não é sobre escrever prompts melhores isoladamente. É sobre construir sistemas visuais controláveis, repetíveis e prontos para produção.
FAQ
Por que minhas imagens de IA ainda parecem planas?
Imagens planas geralmente significam que você deixou de lado as dicas de profundidade. Pense em como a fotografia funciona. A profundidade vem das sombras, objetos sobrepostos e diferenças no foco. Seu prompt tem que detalhar isso.
Pegue um prompt simples: "uma pessoa sentada em uma mesa". Isso não diz quase nada ao modelo sobre profundidade. Tente algo assim: "uma pessoa sentada em uma mesa (plano médio), uma janela desfocada com luzes da cidade (fundo), uma xícara de café em foco nítido (primeiro plano)". Agora o modelo tem camadas para trabalhar.
A iluminação é outro ponto onde as pessoas erram. Muitos prompts mencionam apenas a luz ambiente. Isso dá a você uma iluminação plana e uniforme em toda a imagem. Adicione uma fonte direcional. Luz lateral. Contraluz. Luz de contorno. Escolha uma. O modelo começará a criar sombras e, de repente, sua imagem terá volume.
Mais uma coisa. Não tente preencher cada canto do quadro com detalhes. Espaço vazio e desfoque são úteis. Eles dizem ao espectador para onde olhar. Às vezes, menos detalhes dão a você mais profundidade.
A IA pode substituir a fotografia de produto?
Sim, para muitos casos. Mas vamos ser honestos sobre onde funciona e onde não funciona.
Se você precisa de uma foto principal para um relógio de luxo — o tipo onde cada reflexo no metal importa e a textura da pulseira de couro precisa ser exata — a fotografia tradicional ainda vence. Você não supera um estúdio real para isso.
Para quase todo o resto, a IA é mais rápida e barata. Imagens de catálogo. Cenas de estilo de vida. Variações sazonais. Testes A/B de criativos. Você pode gerar uma foto de produto limpa em um fundo branco em segundos. Depois, pegue essa imagem e coloque-a em uma cena de praia, uma cabana de inverno ou uma cozinha moderna usando um gerador de fotografia de produto por IA.
Sem aluguel de estúdio. Sem equipamento de iluminação. Sem retoques. Cada imagem custa centavos.
Para pequenas marcas e startups direct-to-consumer, isso muda o jogo. Elas agora podem produzir visuais que competem com empresas que têm grandes orçamentos. Isso não era possível há dois anos.
Como o modelo de geração visual da OpenAI difere das versões anteriores?
O novo modelo, GPT‑image‑1.5, tem algumas mudanças arquiteturais internas. Ele usa um transformador de difusão. Essa é uma maneira sofisticada de dizer que ele lida melhor com relações espaciais.
Versões anteriores muitas vezes quebravam cenas complexas em partes que não se encaixavam perfeitamente. Uma mão poderia flutuar perto de uma xícara em vez de segurá-la. Sombras apontariam para direções erradas. A nova versão mantém as coisas conectadas. Uma mão segura a xícara. A sombra cai onde deveria.
A renderização de texto é outro grande salto. Modelos anteriores produziam caracteres ilegíveis que pareciam símbolos aleatórios. O GPT‑image‑1.5 gera palavras legíveis em vários idiomas. Você pode misturar inglês e chinês na mesma imagem. Isso realmente funciona agora.
O modelo também suporta resoluções mais altas nativamente — até 2K sem necessidade de upscaling. Menos artefatos. Detalhes mais nítidos.
Há um lado negativo. O modelo é menos tolerante a prompts vagos. Você não pode simplesmente dizer "um retrato legal" e esperar mágica. Você precisa ser mais cuidadoso. Mas quando você fornece instruções estruturadas — direção de luz, camadas de profundidade, configurações de câmera — a qualidade da saída é melhor do que qualquer coisa das gerações anteriores.






