
Resposta Rápida
Uma "Skill" de Gerador de Vídeo com IA no GitHub conecta seu código a modelos de vídeo via IA. Em 2026, a escolha entre código aberto (gratuito, autohospedado) e APIs pagas (nuvem, instantâneo) depende de quatro variáveis: disponibilidade de VRAM, requisitos de privacidade de dados, nível de qualidade necessário e volume mensal de geração. Para fluxos de trabalho em escala de produção que precisam de múltiplos modelos SOTA, o Atlas Cloud (atlascloud.ai) oferece acesso a mais de 300 modelos — incluindo Kling v3.0, Seedance 2.0, Vidu 3.0, Veo e Sora — através de uma única chave de API com preços transparentes de pagamento por uso.
-
O que é uma Skill de Gerador de Vídeo com IA? {#what-is-a-skill}
No contexto de repositórios do GitHub, uma Skill de Gerador de Vídeo com IA é um módulo reutilizável, wrapper ou camada de integração que conecta uma aplicação a um backend de geração de vídeo por IA — seja um modelo de código aberto autohospedado ou uma API em nuvem.
Pense nela como a abstração entre a lógica da sua aplicação e o motor de inferência real. Uma skill pode ser:
- Uma classe Python que encapsula o pipeline do modelo
Wan 2.2para geração de texto para vídeo - Um nó personalizado do ComfyUI que se conecta à API do Atlas Cloud para geração via Kling v3.0
- Um nó de fluxo de trabalho do n8n que aciona o Seedance 2.0 via REST e retorna uma URL de vídeo
- Uma ferramenta LangChain ou skill de MCP Server que chama um endpoint de geração de vídeo sob demanda
A pergunta central que todo desenvolvedor enfrenta ao criar uma: o backend deve ser baseado em pesos de código aberto rodando localmente ou em uma API paga na nuvem?
Dados reais de 2026. Sem teoria.
-
Código aberto no GitHub em 2026 {#open-source-landscape}
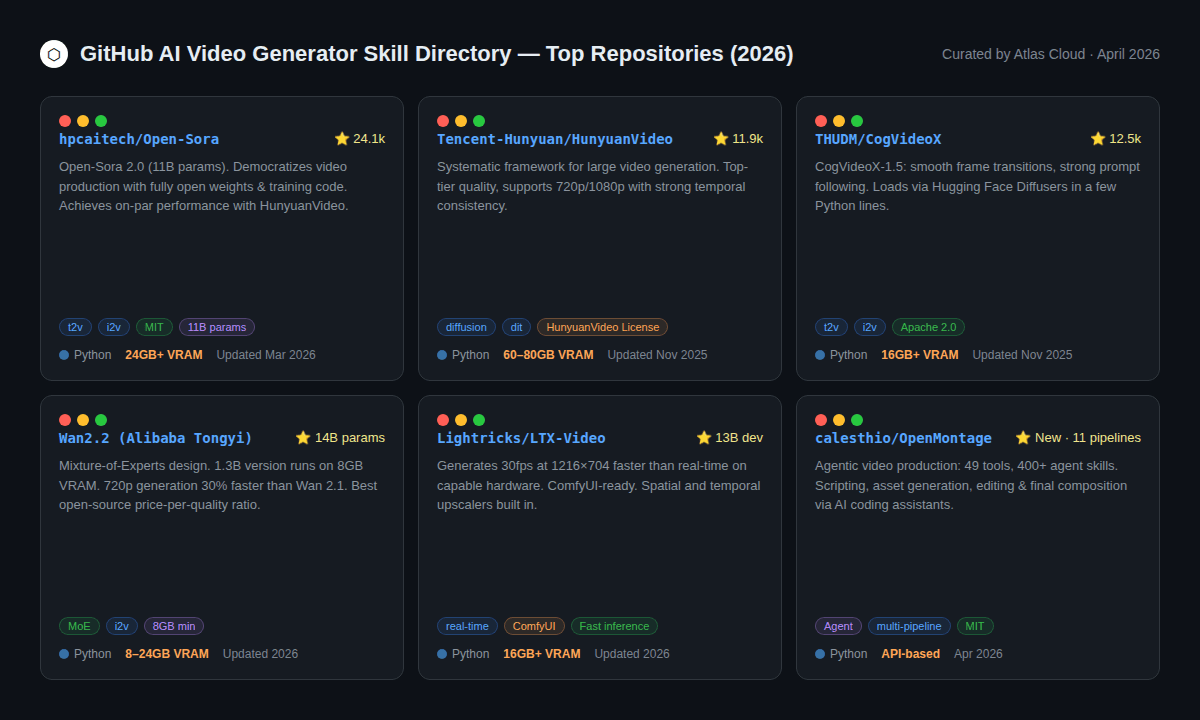
O ecossistema de geração de vídeo de código aberto amadureceu significativamente. Alguns repositórios agora são alternativas genuínas às APIs pagas — pelo menos para certas tarefas.
Nível 1: Modelos de Código Aberto de Grau de Produção
HunyuanVideo (Tencent, 11,9 mil ⭐) — Um dos melhores geradores de vídeo de código aberto disponíveis. Lida com 720p e 1080p. A limitação principal é o requisito de hardware: 60–80 GB de VRAM para o modelo completo, tornando-o acessível apenas a equipes com acesso a GPUs corporativas. A licença comunitária permite uso comercial com atribuição.
CogVideoX-1.5 (THUDM/CogVideo, 12,5 mil ⭐) Lançado sob Apache 2.0, é um dos modelos abertos mais amigáveis para desenvolvedores. Carrega nativamente via Hugging Face Diffusers em poucas linhas de Python. As transições de quadros são suaves e o seguimento de prompts é forte. Requer 16 GB de VRAM no mínimo. Uma escolha sólida se sua equipe já utiliza o Hugging Face.
Open-Sora 2.0 (hpcaitech, 24,1 mil ⭐) O projeto de geração de vídeo de código aberto com mais estrelas no GitHub. A versão 2.0 (11B de parâmetros) atinge um desempenho comparável ao HunyuanVideo nos benchmarks VBench, e o custo de treinamento foi reportado em aproximadamente US$ 200.000 — um número notável para um modelo deste calibre. Texto para vídeo, imagem para vídeo e geração de duração infinita.
Nível 2: Opções de código aberto mais leves (menor VRAM)
Wan 2.2 (Alibaba Tongyi) A acessibilidade aqui é atraente: a variante de 1,3B roda com 8 GB de VRAM, e a de 14B com 24 GB. A arquitetura Mixture-of-Experts (MoE) entrega melhores detalhes com menor custo computacional, e a versão 2.2 é 30% mais rápida em 720p que sua antecessora. Para desenvolvedores usando uma única GPU de consumo, o Wan 2.2 é a opção de código aberto mais forte.
LTX-Video (Lightricks) Projetado acima de tudo para velocidade. Gera 30fps em resolução 1216×704 mais rápido que o tempo real em hardware capaz. A integração com ComfyUI é madura, e upscalers espaciais e temporais já estão integrados.
Nível 3: Pipelines Agênticos
OpenMontage (calesthio, novo em abril de 2026) Uma categoria genuinamente nova: um sistema de produção de vídeo agêntico com 11 pipelines, 49 ferramentas e mais de 400 habilidades de agentes. Funciona com assistentes de codificação de IA como Claude Code, Cursor e Copilot. Lida com o pipeline completo — pesquisa, roteiro, ativos, edição — do início ao fim sem etapas manuais. Criado para equipes que conectam múltiplas ferramentas de IA em um único fluxo de trabalho.
-
Diretório de APIs Pagas: Modelos SOTA Disponíveis Agora {#paid-api-directory}
O cenário de APIs pagas em 2026 é definido por três grandes famílias de modelos, cada uma com uma abordagem técnica distinta. Todas as três estão disponíveis através da API unificada do Atlas Cloud.
Kling v3.0 (Kuaishou)
Lançado em 5 de fevereiro de 2026. Construído sobre uma arquitetura de Linguagem Visual Multimodal — texto, imagens, áudio e vídeo, todos tratados em um único sistema.
O que ele faz melhor que os concorrentes:
- Movimentos humanos complexos — correr, dançar, artes marciais — sem a deformação de "membros de espaguete" que aflige outros modelos
- Geração de áudio nativa multilíngue (5 idiomas, incluindo sincronização labial)
- Motion Brush: uma ferramenta que permite aos desenvolvedores (ou usuários finais) pintar caminhos de movimento diretamente nas imagens de origem — um recurso que atualmente não tem equivalente em modelos concorrentes
- Vinculação de Elementos (Element Binding) para rastreamento consistente de personagens e objetos entre as tomadas
Onde ele falha: A velocidade de renderização é mais lenta que a de alguns concorrentes no nível Pro. As transições da ferramenta de storyboard podem ser "desajeitadas", segundo revisores independentes.
Ideal para: Vídeos curtos para redes sociais (TikTok e Reels), vídeos de produtos para e-commerce e qualquer coisa que exija alto volume com personagens que realmente permaneçam consistentes.
Seedance 2.0 (ByteDance)
Lançado em 8 de fevereiro de 2026, o Seedance 2.0 representa uma mudança de paradigma em como vídeos de IA são instruídos — de prompts apenas de texto para um controle real baseado em referência ao estilo de direção.
A inovação técnica central: O Seedance 2.0 aceita entradas quad-modais — texto, imagem, vídeo e áudio — simultaneamente. Seu sistema de "Referência Universal" permite que um desenvolvedor alimente um vídeo de referência de uma pessoa dançando, e o modelo replicará o movimento da câmera, as ações do personagem e a composição no resultado gerado. Isso resolve a consistência de personagens de uma forma que modelos puros de texto para vídeo não conseguem.
Testes independentes confirmam que ele se destaca em:
- Storytelling com múltiplas tomadas e identidade de personagem consistente através dos cortes
- Geração sincronizada de áudio e vídeo (arquitetura de ramo duplo gera som e vídeo simultaneamente)
- Replicação precisa da composição e iluminação de ativos de referência
Nota sobre disponibilidade: Em abril de 2026, o acesso à API internacional do Seedance 2.0 está disponível através de plataformas como o Atlas Cloud. O acesso direto à API BytePlus para desenvolvedores internacionais teve inconsistências de disponibilidade — confirme o status atual antes de criar uma dependência em endpoints diretos da ByteDance.
Ideal para: Videoclipes, animação de personagens detalhada, anúncios de produtos onde o movimento precisa ser exato, agências que operam fluxos de trabalho de storyboard para vídeo.
Vidu 3.0 (Shengshu AI / Tsinghua)
Construído sobre a arquitetura original U-ViT combinando tecnologias de Difusão e Transformer, o Vidu foca nas áreas onde a maioria dos vídeos por IA ainda luta: coerência ambiental e consistência cinematográfica.
Recursos distintos:
- Sistema de referência universal para iluminação consistente em sequências de múltiplas tomadas
- Geração inteligente de música de fundo que se adapta ao humor da cena automaticamente
- Geração de longa duração com forte consistência temporal (crítico para sequências com mais de 5 segundos)
Melhores casos de uso: Fluxos de trabalho profissionais de cinema, design de animação, publicidade criativa que exige qualidade cinematográfica.
Sora 2 (OpenAI)
O Sora 2 permanece como a referência para simulação de física. Quebre um vidro em um prompt do Sora 2 e o padrão de estilhaçamento, física de fluidos e reflexos, tudo se comporta como na realidade — a maioria dos concorrentes ainda não consegue igualar esse nível de consistência.
Ideal para: Trabalhos de VFX, visualização arquitetônica, B-roll de documentários, qualquer lugar onde a precisão física importa mais do que economizar dinheiro.
Preço: O Sora 2 possui a fatura mais alta nesta categoria. Você está pagando pelo processamento.
-
Custos de Inferência: Os Números Reais {#inference-costs}
Esta seção contém a descoberta contraintuitiva mais importante de todo este guia — uma que altera a intuição padrão da maioria dos desenvolvedores sobre código aberto vs. APIs pagas.
O Custo Oculto dos Modelos Autohospedados
A maioria dos desenvolvedores assume: "Código aberto = grátis = sempre mais barato."
Essa suposição está errada para a maioria dos tamanhos de equipe.
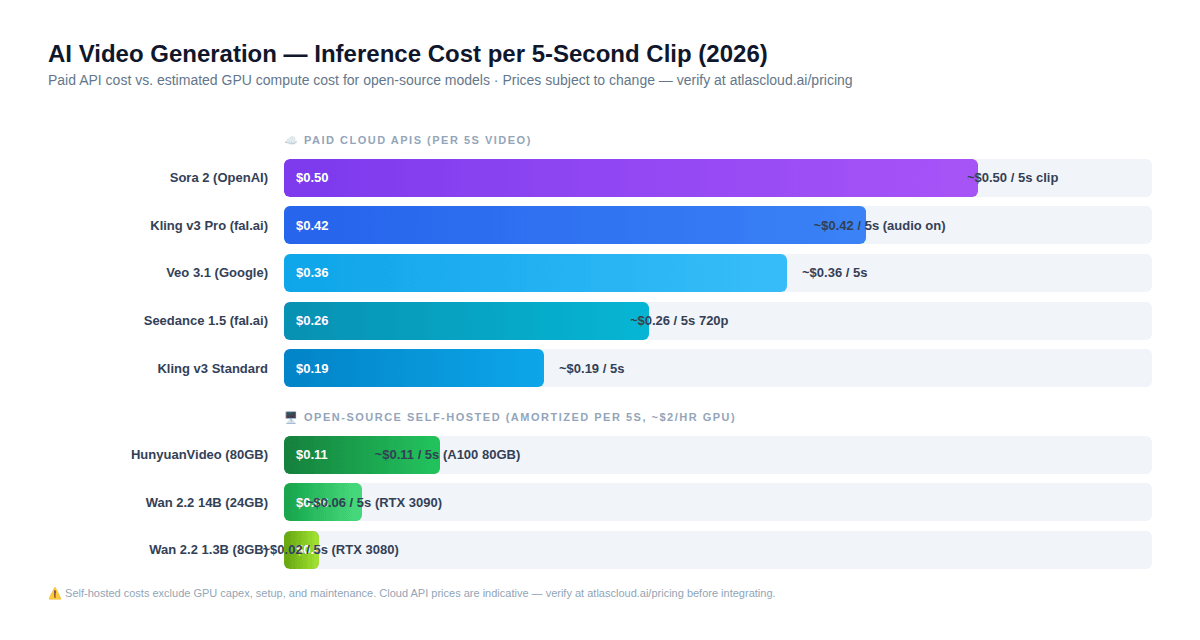
Aqui está como a matemática real se parece para um clipe de vídeo de 5 segundos em 2026:
Código aberto autohospedado (custo de GPU amortizado em ~$2/hora):
- Wan 2.2 1.3B (RTX 3080): ~$0,02 por clipe de 5s
- Wan 2.2 14B (RTX 3090): ~$0,06 por clipe de 5s
- HunyuanVideo (A100 80GB): ~$0,11 por clipe de 5s
API paga em nuvem (preços indicativos — verifique em atlascloud.ai/pricing):
- Kling v3 Standard: ~$0,19 por clipe de 5s
- Seedance 1.5 720p com áudio: ~$0,26 por clipe de 5s
- Kling v3 Pro com áudio: ~$0,42 por clipe de 5s
- Sora 2: ~$0,50 por clipe de 5s
Os números do autohospedado parecem atraentes isoladamente. O problema é que eles excluem:
- Hardware de GPU — Uma A100 80GB custa de US$ 10 mil a US$ 15 mil. Com 1.000 vídeos por mês (~US$ 0,11 cada), você levaria mais de 9.000 meses apenas para empatar o custo do hardware.
- Tempo de configuração — Configuração CUDA, download de pesos de modelos, gerenciamento de VRAM e depuração representam de 20 a 40 horas de engenharia de configuração inicial.
- Manutenção contínua — Atualizações de modelos, conflitos de dependências e confiabilidade da infraestrutura são custos de tempo contínuos.
- Custo de oportunidade — Tempo gasto em infraestrutura de inferência é tempo não gasto no produto.
A condição de contorno prática:
O autohospedagem só compensa se: (a) você já tiver GPUs rodando outras cargas de trabalho, (b) estiver produzindo mais de 5.000 vídeos por mês ou (c) regulamentações obrigarem você a manter tudo localmente (on-prem).
Abaixo desse limite, as APIs pagas — especialmente plataformas unificadas como o Atlas Cloud — são mais baratas quando o custo total de propriedade é calculado honestamente.
-
Limites de Taxa e Latência da API — O que os desenvolvedores realmente enfrentam {#rate-limiting}
O Paradoxo da Latência
Contraintuitivamente, as APIs em nuvem são frequentemente mais rápidas por vídeo do que os modelos autohospedados — não porque os modelos sejam diferentes, mas porque os provedores de nuvem executam clusters de inferência multi-GPU otimizados com processamento em lote (batching) em nível de hardware, enquanto uma única GPU de desenvolvedor gera quadros sequencialmente.
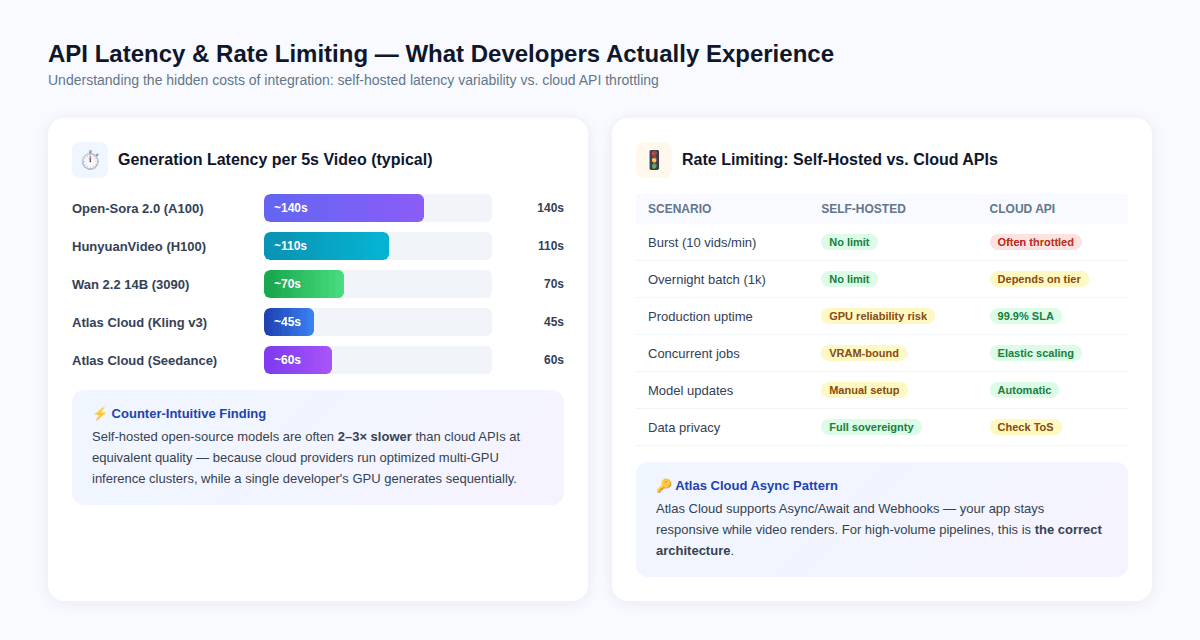
Latência típica por clipe de 5 segundos:
- Open-Sora 2.0 em A100: ~140 segundos
- HunyuanVideo em H100: ~110 segundos
- Wan 2.2 14B em RTX 3090: ~70 segundos
- Atlas Cloud / Kling v3: ~45 segundos
- Atlas Cloud / Seedance 2.0: ~60 segundos
Isso significa que criar uma Skill no GitHub em torno de um modelo autohospedado pode produzir tempos de espera maiores para o usuário final, mesmo quando o custo por vídeo é menor.
Limitação de Taxa: A Realidade da Produção
Modelos autohospedados não possuem limites de taxa impostos pela API — eles são limitados apenas pelos limites térmicos e de VRAM da sua GPU.
APIs pagas impõem limites de taxa que variam de acordo com o nível de preços. As implicações de engenharia relevantes:
- Requisições em rajada (10+ vídeos por minuto) acionarão o throttling na maioria dos níveis de API paga
- Trabalhos em lote durante a noite (1.000+ vídeos) exigem um design assíncrono cuidadoso para evitar timeouts
- Requisições simultâneas em modelos autohospedados são limitadas pela VRAM — executar 2 inferências de modelo 14B simultâneas em uma única placa de 24GB normalmente não é possível
O Atlas Cloud resolve o problema da limitação de taxa através da arquitetura Assíncrona/Webhook: sua aplicação envia um trabalho de geração, recebe um ID de tarefa e é notificada via webhook quando a renderização é concluída. Este padrão evita que a aplicação trave enquanto o vídeo renderiza, e escala corretamente para cargas de trabalho em lote.
A Arquitetura Correta para Produção
plaintext1# Padrão Assíncrono do Atlas Cloud — Pronto para Produção 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="SUA_CHAVE_DE_API_DO_ATLAS_CLOUD", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# Enviar tarefa de geração 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="Product showcase reel, smooth motion, 9:16 aspect ratio", 14 size="1080x1920", 15 n=1 16) 17 18# Lidar com resposta assíncrona 19video_url = response.data[0].url 20print(f"Vídeo gerado: {video_url}")
Para fluxos de trabalho de imagem para vídeo, observe que alguns modelos — incluindo certas variantes Kling i2v — não aceitam um parâmetro de proporção (aspect ratio) separado para geração de imagem para vídeo; a resolução de saída segue as dimensões da imagem de entrada. Construa sua geração de imagem a montante com a proporção alvo correta.
-
Hospedagem Local vs. API em Nuvem: A Matriz de Trocas {#local-vs-cloud}
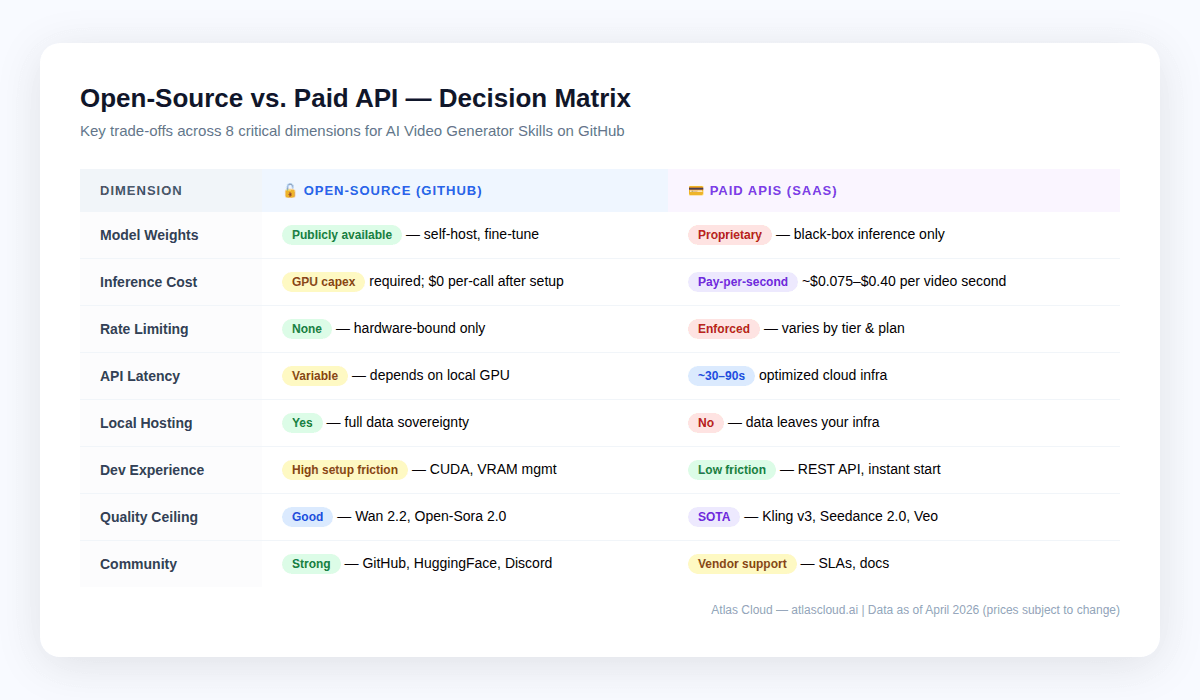
Não é uma questão de "ou um, ou outro". A maioria dos pipelines de produção mistura ambos: código aberto para prototipagem e passes de baixa qualidade em massa, APIs de nuvem para renderizações finais e qualidade de ponta.
Quando o local faz sentido
- Bloqueios de conformidade — HIPAA, GDPR ou qualquer coisa proprietária que não possa sair dos seus servidores. O autohospedagem é sua única opção. O Atlas Cloud é compatível com HIPAA e certificado SOC I & II, o que atende à maioria das necessidades corporativas, mas empresas regulamentadas devem verificar seus requisitos específicos.
- Volume muito alto com qualidade aceitável — equipes gerando mais de 10.000 vídeos por mês nos níveis de qualidade do Wan 2.2 podem descobrir que os custos de aluguel de GPU são menores do que as taxas de API nessa escala.
- Pesquisa e ajuste fino (fine-tuning) — pesos de modelos abertos permitem fine-tuning em conjuntos de dados proprietários. Nenhuma API de nuvem atualmente oferece treinamento de modelo personalizado.
- Configurações offline (air-gapped) — implantações na borda sem conectividade ou redes bloqueadas.






