DeepSeek LLM Models
DeepSeek, developed by the deepseek-ai team, is a cutting-edge series of open-source generative AI models engineered to democratize access to high-performance computing through a cost-effective and efficiency-first strategy. Its flagship reasoning model, DeepSeek-R1, made waves by rivaling top-tier proprietary models in mathematics, programming, and complex logical deduction, while the DeepSeek-V3.2, is designed for seamless daily interaction and autonomous Agent workflows. By significantly lowering the barrier to entry for advanced AI, DeepSeek has become a cornerstone for the "vibe coding" movement and a transformative tool in specialized fields like academic research and high-level technical problem-solving.
สำรวจโมเดลชั้นนำ
Atlas Cloud มอบโมเดลสร้างสรรค์ล่าสุดที่นำหน้าในอุตสาหกรรมให้กับคุณ
สิ่งที่ทำให้ DeepSeek LLM Models โดดเด่น
Atlas Cloud มอบโมเดลสร้างสรรค์ล้ำสมัยชั้นนำของอุตสาหกรรมให้กับคุณ

ขุมพลังแบบเปิด
โมเดลระดับชั้นนำที่เป็นโอเพ่นซอร์สอย่างสมบูรณ์ เพื่อรับรองความโปร่งใสและการควบคุม

ประสิทธิภาพทางสถาปัตยกรรม
ใช้ประโยชน์จาก Mixture-of-Experts (MoE) ขั้นสูงเพื่อประสิทธิภาพระดับผู้นำในราคาเพียงเสี้ยวเดียว

ความอเนกประสงค์ที่สร้างขึ้นเพื่อวัตถุประสงค์เฉพาะ
ตั้งแต่ V3.1 ที่มีความอเนกประสงค์ไปจนถึงความสามารถในการใช้เหตุผลเฉพาะทางของ R1 DeepSeek มีโมเดลสำหรับทุกงาน

อิสระที่เน้นนักพัฒนาเป็นหลัก
ภายใต้สัญญาอนุญาตแบบเปิดกว้างสำหรับการใช้งานเชิงพาณิชย์โดยไม่มีข้อจำกัด เพื่อส่งเสริมนวัตกรรมที่ไร้อุปสรรค

ประสิทธิภาพที่ได้รับการพิสูจน์แล้ว
บรรลุผลลัพธ์ระดับแนวหน้าอย่างสม่ำเสมอในเกณฑ์มาตรฐานอุตสาหกรรมสำหรับการเขียนโค้ดและการใช้เหตุผล

ทางเลือกที่ใช้งานได้จริง
มอบประสิทธิภาพระดับโมเดลลิขสิทธิ์ชั้นนำ พร้อมความคุ้มค่าและความยืดหยุ่นในแบบโอเพนซอร์ส
Peak speed
Lowest cost
| รูปแบบ | คำอธิบาย |
|---|---|
| DeepSeek V3.2 | DeepSeek V3.2 เป็น LLM อเนกประสงค์รุ่นเรือธง ที่ผสานรวมกลไก sparse attention เข้ากับความสามารถในการประมวลผลบริบทขนาด 163.8K อันแข็งแกร่ง ด้วยราคาเริ่มต้นที่แข่งขันได้สูง จึงทำหน้าที่เป็นรากฐานสำคัญสำหรับเวิร์กโฟลว์ประจำวัน รวมถึงการใช้เหตุผลทั่วไปที่ซับซ้อนและการสร้าง Agents จัดตารางงานแบบหลายขั้นตอน |
| DeepSeek V3.2 Speciale | DeepSeek V3.2 Speciale ถูกวางตำแหน่งให้เป็น LLM แบบกำหนดเองประสิทธิภาพสูง โดดเด่นด้วยหน้าต่างบริบทขนาดใหญ่ถึง 163.8K และโครงสร้างราคาแบบแบ่งระดับพรีเมียม ($0.4 ขาเข้า / $1.2 ขาออก) ออกแบบมาโดยเฉพาะสำหรับโหนดธุรกิจหลักที่ไวต่อความหน่วงและต้องการคุณภาพผลลัพธ์สูงสุด เช่น การบริการลูกค้าอัจฉริยะสำหรับลูกค้าที่มีสินทรัพย์สูง หรือการวิเคราะห์เชิงปริมาณในระดับมิลลิวินาที |
| DeepSeek V3.2 Exp | DeepSeek V3.2 Exp เป็นเวอร์ชันทดลองที่ล้ำสมัยซึ่งสร้างขึ้นบนสถาปัตยกรรม V3.2 โดยผสานรวมคุณสมบัติอัลกอริทึมล่าสุดในขณะที่ยังคงบริบทขนาด 163.8K และต้นทุนที่เทียบเคียงได้ ทำให้เหมาะอย่างยิ่งสำหรับทีม R&D ที่ดำเนินการวิจัยล่วงหน้าทางเทคนิคและการทดสอบแบบ Canary เพื่อตรวจสอบความสามารถที่โดดเด่นของ AI รุ่นต่อไปสำหรับผลิตภัณฑ์ในอนาคต |
| DeepSeek-V3.1 | DeepSeek-V3.1 เป็นรุ่นล่าสุดของโมเดลระบบนิเวศโอเพ่นซอร์สที่มีประสิทธิภาพสูง ซึ่งสร้างสมดุลใหม่ระหว่างประสิทธิภาพและต้นทุนภายในบริบท 131.1K ในฐานะตัวเลือกอันดับต้นสำหรับการนำไปใช้ในโครงการเชิงพาณิชย์ มันทำหน้าที่เป็นกระดูกสันหลังสำหรับสถานการณ์ที่ต้องการทั้งการสร้างผลงานคุณภาพสูงและต้นทุนที่ควบคุมได้ |
| DeepSeek V3.1 Terminus | DeepSeek V3.1 Terminus ทำหน้าที่เป็นรูปแบบสูงสุดที่มีความเสถียรในระยะยาวของซีรีส์ V3.1 โดย DeepSeek V3.1 Terminus ยังคงรักษาพารามิเตอร์และราคาที่เหมือนกับรุ่นมาตรฐานทุกประการ เพื่อมุ่งเน้นให้รูปแบบผลลัพธ์และตรรกะมีความเสถียรอย่างถาวร สำหรับบริการ endpoint ในสภาพแวดล้อมการใช้งานจริง (production environment) ที่ราบรื่นและมุ่งเน้นผู้บริโภค |
| DeepSeek-V3-0324 | DeepSeek-V3-0324 เป็นเวอร์ชันสแนปช็อตย้อนหลังเฉพาะที่มีบริบท 131.1K และต้นทุนการป้อนข้อความที่ต่ำที่สุดที่มีอยู่ โดยส่วนใหญ่จะใช้ในการบำรุงรักษาระบบเก่า (Legacy System) ที่ต้องการความสม่ำเสมอของพฤติกรรมอย่างสมบูรณ์ หรือทาสก์การประมวลผลแบบกลุ่ม (Batch Processing) ที่มีปริมาณข้อมูลนำเข้ามหาศาลแต่มีความต้องการด้านตรรกะของผลลัพธ์ในระดับปานกลาง |
| DeepSeek-R1-0528 | DeepSeek-R1-0528 ถูกวางตำแหน่งให้เป็นโมเดลการให้เหตุผลเชิงลึกระดับแนวหน้า โดยใช้บริบทขนาด 131.1K และมีต้นทุนการประมวลผลสูงที่สุด ($0.55/$2.15) ซึ่งแสดงถึงจุดสูงสุดของความสามารถทางตรรกะวิภาษวิธี โดยใช้สำหรับงาน "ระดมสมอง" ที่สำคัญโดยเฉพาะ เช่น การสร้างแบบจำลองทางคณิตศาสตร์ที่ซับซ้อน และการสร้างสถาปัตยกรรมโค้ดขั้นสูง |
| DeepSeek OCR | DeepSeek OCR เป็น LLM แบบมัลติโมดัลด้านการมองเห็นโดยเฉพาะ ที่รองรับอินพุตภาพและข้อความแบบ dual-track ด้วยบริบทสั้น 8.2K และต้นทุนการใช้งานที่ต่ำมาก ปรับให้เข้ากับสถานการณ์ไปป์ไลน์การป้อนข้อมูลอัตโนมัติได้อย่างสมบูรณ์แบบ เช่น การแปลงเอกสารสแกนจำนวนมหาศาลเป็นดิจิทัล และการดึงข้อมูลแบบมีโครงสร้างจากใบเสร็จรับเงินทางการเงิน |
ฟีเจอร์ใหม่ของ DeepSeek LLM Models + โชว์เคส
การผสมผสานโมเดลขั้นสูงกับแพลตฟอร์มเร่งความเร็ว GPU ของ Atlas Cloud มอบความเร็ว ความสามารถในการปรับขนาด และการควบคุมเชิงสร้างสรรค์ที่ไม่มีใครเทียบได้สำหรับการสร้างภาพและวิดีโอ
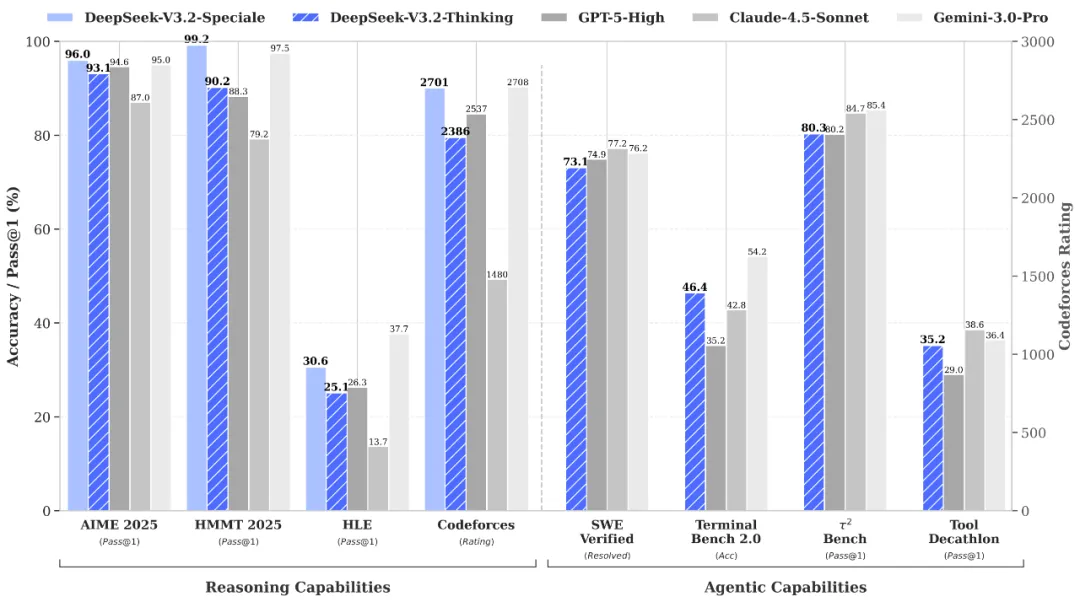
การใช้เหตุผลและการตรวจสอบระดับโลกผ่าน DeepSeek-V3.2-Speciale API
DeepSeek-V3.2-Speciale is the "long-thought" enhanced variant of the V3.2 architecture, integrating advanced theorem-proving capabilities from DeepSeek-Math-V2. Engineered for extreme precision, this model excels in rigorous mathematical proofing, complex logical verification, and superior instruction following, rivaling the performance of Gemini-3.0-Pro in mainstream reasoning benchmarks. It is the premier choice for academic research, automated formal verification, and high-stakes technical problem-solving where logical integrity is non-negotiable.
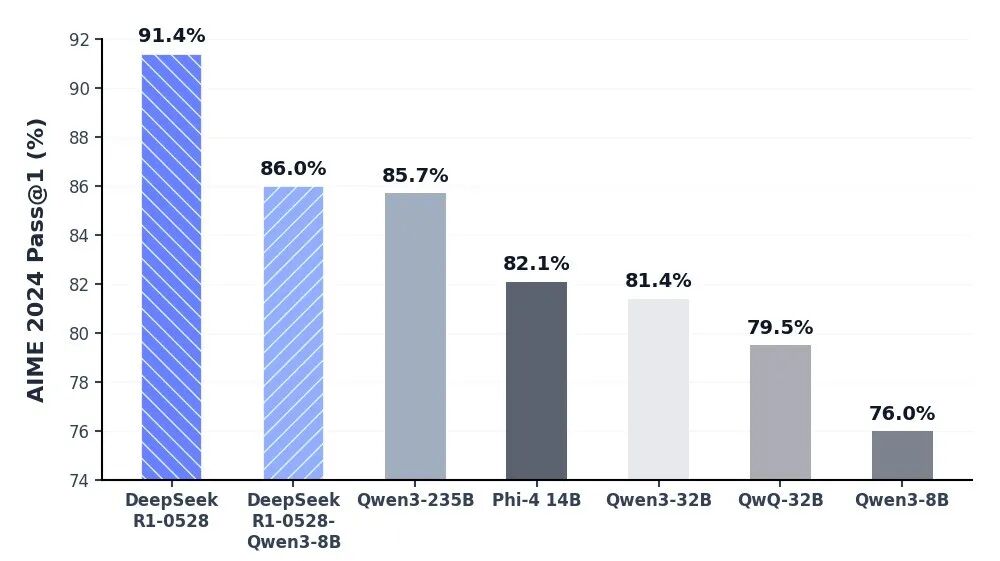
ความลึกซึ้งทางปัญญาที่ไม่มีใครเทียบได้ผ่าน DeepSeek-R1 API
โมเดล DeepSeek-R1 ยืนหยัดอยู่ในแนวหน้าของ AI ด้านการใช้เหตุผล (reasoning AI) โดยมอบประสิทธิภาพระดับชั้นนำของอุตสาหกรรมในด้านคณิตศาสตร์ การเขียนโปรแกรม และตรรกะทั่วไป ด้วยการบรรลุความทัดเทียมกับโมเดลระดับแนวหน้าของโลก เช่น o3 ของ OpenAI และ Gemini-2.5-Pro ทำให้ R1 ได้นิยามขีดความสามารถของปัญญาประดิษฐ์แบบโอเพนซอร์สใหม่ มันถูกปรับให้เหมาะสมเป็นพิเศษสำหรับงานที่ต้องใช้การคิดเชิงลึก รวมถึงการพัฒนาอัลกอริทึมที่ซับซ้อน การสังเคราะห์ข้อมูลที่ละเอียดซับซ้อน และขั้นตอนการทำงานทางปัญญาขั้นสูงที่ต้องใช้การใช้เหตุผลแบบนิรนัยหลายขั้นตอน
การโต้ตอบรายวันที่ราบรื่นกับเวิร์กโฟลว์ของเอเจนต์อัตโนมัติด้วย DeepSeek V3.2 API
DeepSeek-V3.2 สร้างสมดุลที่สมบูรณ์แบบระหว่างความลึกของการใช้เหตุผลและความเร็วในการดำเนินการ โดยออกแบบมาเพื่อขับเคลื่อนการโต้ตอบในชีวิตประจำวันที่ราบรื่นและระบบนิเวศของตัวแทนอัตโนมัติ (Autonomous Agent) ด้วยความหน่วงที่ลดลงอย่างมากและการควบคุมผลลัพธ์ที่ได้รับการปรับปรุง ทำให้รุ่นนี้เป็นเครื่องมือที่ทรงพลังสำหรับการจัดการงานหลายขั้นตอนและผู้ช่วย AI อเนกประสงค์ ไม่ว่าจะใช้ในการปรับใช้ระบบอัตโนมัติระดับองค์กรหรือเครื่องมือโต้ตอบความถี่สูง V3.2 รับประกันประสบการณ์ผู้ใช้ที่ลื่นไหล มีประสิทธิภาพ และคุ้มค่า
การค้นพบทางวิทยาศาสตร์ที่เข้มงวดและการตรวจสอบอย่างเป็นทางการด้วย DeepSeek-V3.2-Speciale API
The DeepSeek-V3.2-Speciale API is engineered for tasks that demand absolute logical precision and multi-step reasoning. By integrating advanced theorem-proving capabilities, it enables researchers and engineers to execute complex mathematical inductions, verify formal logic, and solve high-tier competitive programming challenges. Perfect for academic R&D, automated code auditing, and cryptographic analysis, this API transforms abstract complexity into verifiable results with the performance of top-tier global models.
Advanced Algorithmic Synthesis & Strategic Reasoning using the DeepSeek-R1 API
DeepSeek-R1 empowers developers to build applications centered on deep cognitive workflows and strategic decision-making. Ranking at the forefront of global reasoning benchmarks, the R1 API excels in synthesizing sophisticated code architectures, processing dense technical documentation, and generating innovative solutions for open-ended logical puzzles. It is the ideal engine for AI-driven software engineering, long-form data synthesis, and any scenario where "thinking fast and slow" requires a powerful, reasoning-first foundation.
การประสานงานเอเจนต์อัตโนมัติอย่างไร้รอยต่อด้วย DeepSeek-V3.2 API
For high-velocity, sensory-driven AI applications, the DeepSeek-V3.2 API provides the perfect equilibrium between reasoning depth and ultra-low latency. It is optimized for building autonomous Agents that can navigate multi-step workflows, manage real-time user interactions, and execute general-purpose tasks with GPT-5 level intelligence. This use case is tailor-made for enterprise-scale automation, intelligent customer ecosystems, and developers looking to deploy responsive, cost-effective AI assistants at scale.
เปรียบเทียบโมเดล
ดูว่าโมเดลจากผู้ให้บริการต่างๆ เปรียบเทียบกันอย่างไร — เปรียบเทียบประสิทธิภาพ ราคา และจุดแข็งเฉพาะตัวเพื่อตัดสินใจอย่างมีข้อมูล
| โมเดล | บริบท | เอาต์พุตสูงสุด | ข้อมูลนำเข้า | การวางตำแหน่ง |
|---|---|---|---|---|
| DeepSeek V3.2 | 163.84K | 163.84K | Text | เรือธงทั่วไป |
| DeepSeek V3.2 Speciale | 163.84K | 163.84K | Text | แบบปรับแต่งประสิทธิภาพสูง |
| DeepSeek V3.2 Exp | 163.84K | 163.84K | Text | บิลด์ทดลอง |
| DeepSeek-V3.1 | 131.07K | 65.54K | Text | โครงสร้างหลักโอเพนซอร์ส |
| DeepSeek V3.1 Terminus | 131.07K | 65.54K | Text | เสถียรภาพระยะยาว (LTS) |
| DeepSeek-V3-0324 | 131.07K | 32.77K | Text | สแนปชอตประวัติ |
| DeepSeek-R1-0528 | 131.07K | 131.07K | Text | การใช้เหตุผลระดับสูง |
| DeepSeek OCR | 8.19K | 8.19K | Text | มัลติโมดัลเฉพาะทาง |
| GLM-5 | 200K | 128K | Text | โมเดลพื้นฐานระดับเรือธง |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | การเขียนโค้ดแบบ Agentic ระดับ SOTA |
How to Use DeepSeek LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
ทำไมต้องใช้ DeepSeek LLM Models บน Atlas Cloud
การรวมโมเดล DeepSeek LLM Models ขั้นสูงเข้ากับแพลตฟอร์มที่เร่งด้วย GPU ของ Atlas Cloud ให้ประสิทธิภาพ ความสามารถในการขยาย และประสบการณ์นักพัฒนาที่ไม่มีใครเทียบได้
ประสิทธิภาพและความยืดหยุ่น
เวลาแฝงต่ำ:
inference ที่ปรับแต่ง GPU เพื่อการตอบสนองแบบเรียลไทม์
API แบบรวมศูนย์:
รัน DeepSeek LLM Models, GPT, Gemini และ DeepSeek ด้วยการเชื่อมต่อเดียว
ราคาโปร่งใส:
ชำระเงินต่อโทเค็นที่คาดเดาได้พร้อมตัวเลือก serverless
องค์กรและขนาด
ประสบการณ์นักพัฒนา:
SDK, การวิเคราะห์, เครื่องมือปรับแต่ง และเทมเพลต
ความน่าเชื่อถือ:
ความพร้อมใช้งาน 99.99%, RBAC และการบันทึกที่พร้อมสำหรับการปฏิบัติตาม
ความปลอดภัยและการปฏิบัติตาม:
SOC 2 Type II, สอดคล้อง HIPAA, อธิปไตยข้อมูลในสหรัฐอเมริกา
คำถามที่พบบ่อยเกี่ยวกับ DeepSeek LLM Models
DeepSeek มอบความโปร่งใสแบบโอเพนซอร์สและความคุ้มค่าด้านต้นทุนที่เหนือกว่า ด้วยความสามารถในการให้เหตุผล (R1 & V3.2) ที่เทียบเคียงได้กับ GPT-5 จึงเป็นทางเลือกที่มีประสิทธิภาพสูงและต้นทุนต่ำกว่า พร้อมความยืดหยุ่นในการติดตั้งใช้งานแบบส่วนตัว
สิ่งนี้สะท้อนถึง "ความจุสมอง" ทั้งหมดของโมเดล การออกแบบ MoE ของ DeepSeek จับคู่จำนวนพารามิเตอร์รวมมหาศาล (เช่น 671B) เพื่อความฉลาดล้ำลึก กับจำนวนพารามิเตอร์ "ที่ใช้งานจริง" (active) ที่ปรับปรุงให้มีประสิทธิภาพการทำงานสูงสุด
สำรวจกลุ่มเพิ่มเติม
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


