GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
สำรวจโมเดลชั้นนำ
Atlas Cloud มอบโมเดลสร้างสรรค์ล่าสุดที่นำหน้าในอุตสาหกรรมให้กับคุณ
สิ่งที่ทำให้ GLM LLM Models โดดเด่น
Atlas Cloud มอบโมเดลสร้างสรรค์ล้ำสมัยชั้นนำของอุตสาหกรรมให้กับคุณ

Advanced Reasoning
Tuned for strong logical reasoning, structured analysis, and multi-step problem solving.

Cost-Efficiency
Optimized architectures keep latency and costs under control.

Safety & Governance
Built-in content filters, auditing tools, and policy controls help teams deploy.

Enterprise Reliability
Production-ready SLAs, monitoring, and governance features help teams confidently ship applications.

Chinese–English Excellence
Native-strength Chinese and fluent English support enable high-quality bilingual chat, search, and generation.

Developer-Friendly Ecosystem
Clean APIs, SDKs, and tooling make it easy to integrate, fine-tune, and operate Z.ai across products and platforms.
ความเร็วสูงสุด
ต้นทุนต่ำที่สุด
| Model | Description |
|---|---|
| GLM-5 | GLM-5 is Z.ai's flagship LLM featuring a massive 202.75K context window optimized for complex systems and long-horizon agentic tasks. Outperforming elite closed-source models in benchmarks like Humanity’s Last Exam and BrowseComp, it provides robust programming and stable multi-step reasoning at highly competitive baseline pricing. |
| GLM-4.7 | GLM-4.7 is a high-performance LLM with a 202.75K context window specifically engineered for real-world intelligent agents, advanced reasoning, and professional coding. Fast, smart, and reliable, it serves as the ideal engine for building complex websites and automating sophisticated professional workflows with precision. |
| GLM-4.6 | GLM-4.6 is a powerful MoE LLM with a 202.75K context window designed for rapid data analysis and instant, high-fidelity answers. This dependable model excels at high-efficiency tasks like creating professional slides and web content, offering a smart balance of speed and enterprise-grade performance. |
ฟีเจอร์ใหม่ของ GLM LLM Models + โชว์เคส
การผสมผสานโมเดลขั้นสูงกับแพลตฟอร์มเร่งความเร็ว GPU ของ Atlas Cloud มอบความเร็ว ความสามารถในการปรับขนาด และการควบคุมเชิงสร้างสรรค์ที่ไม่มีใครเทียบได้สำหรับการสร้างภาพและวิดีโอ
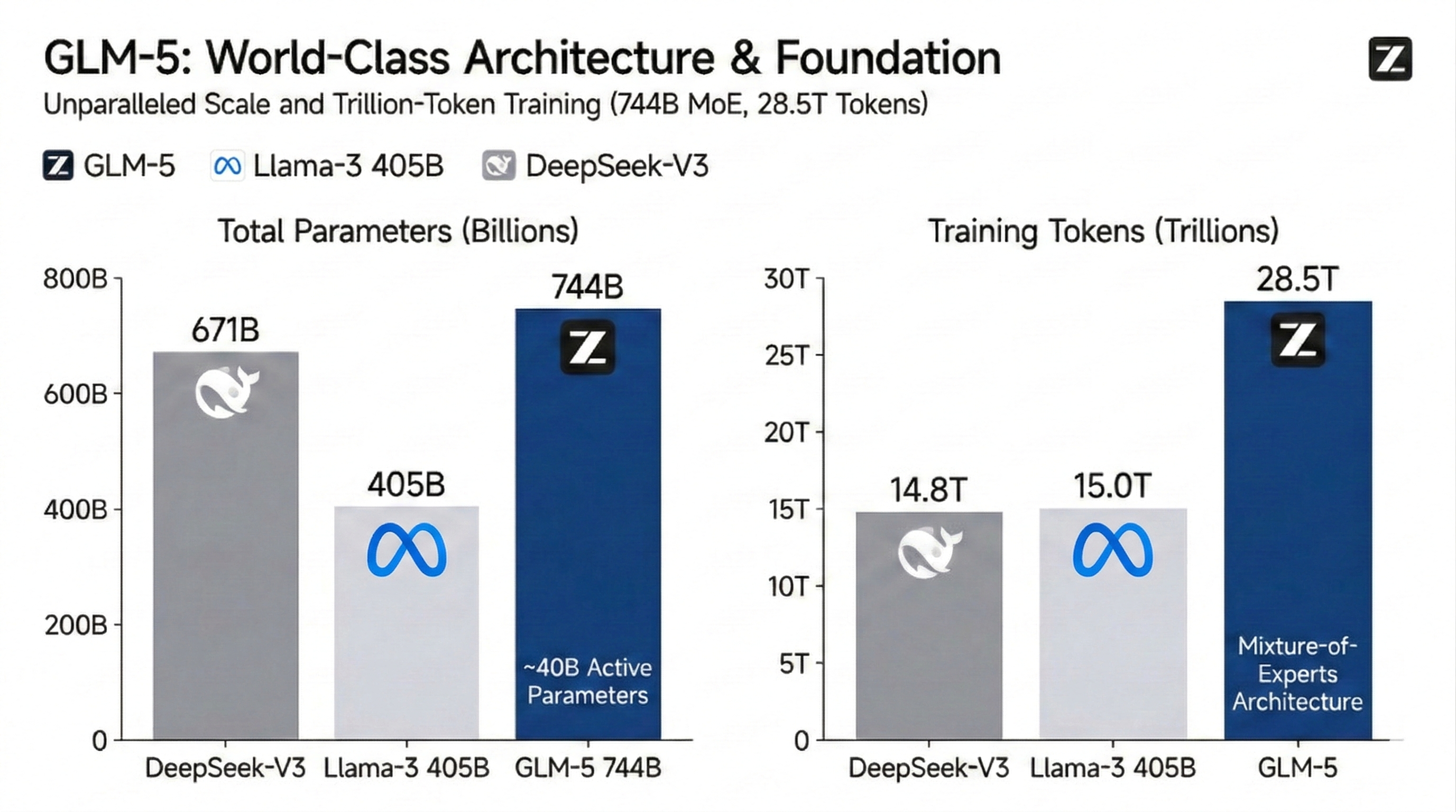
สถาปัตยกรรม MoE ขนาดมหึมา 744B และฐานความรู้สากล
โมเดล GLM-5 ใช้สถาปัตยกรรม Mixture-of-Experts (MoE) ขนาด 7.44 แสนล้านพารามิเตอร์ ซึ่งได้รับการฝึกฝนด้วยโทเค็นจำนวนมหาศาลถึง 28.5 ล้านล้านโทเค็น เพื่อกำหนดเพดานประสิทธิภาพของโอเพ่นซอร์สใหม่ ด้วยการปรับปรุงพารามิเตอร์ที่ใช้งานอยู่ (Active Parameters) จำนวน 4 หมื่นล้านพารามิเตอร์ จึงช่วยให้เกิดการก้าวกระโดดครั้งใหญ่ในด้านความหนาแน่นของความรู้ระดับโลกและความแม่นยำในการสืบค้น นี่คือรากฐานชั้นเลิศสำหรับงานด้านการรับรู้ขนาดใหญ่และการสังเคราะห์ข้อมูลที่ซับซ้อน
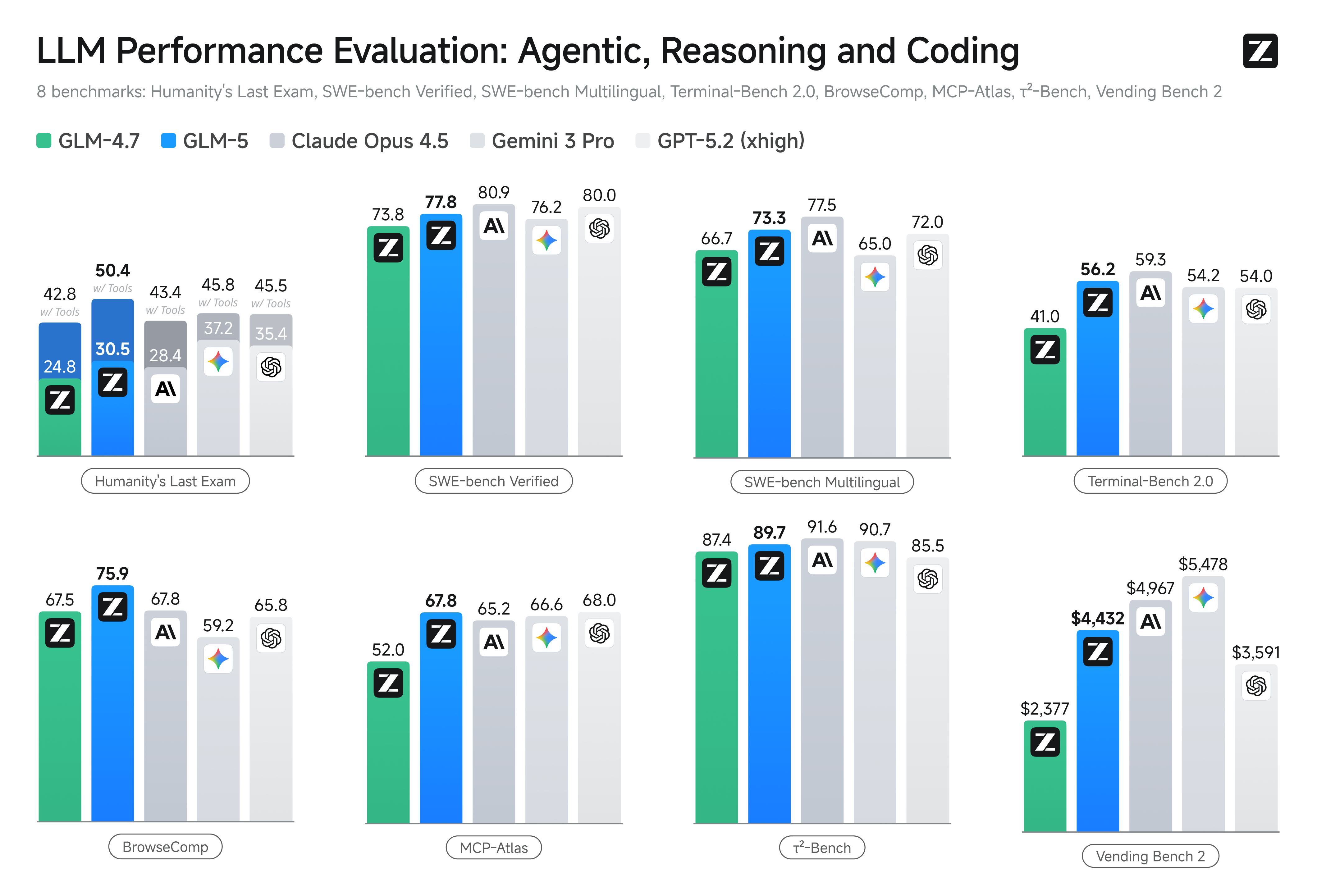
วิศวกรรมระบบตัวแทน (Agentic System) ที่ล้ำสมัยด้วย GLM-5
GLM-5 นำเสนอความสามารถของตัวแทน (Agentic Capabilities) ขั้นสูงที่ออกแบบมาเพื่อการดำเนินงานเชิงระบบในระยะยาว ครอบคลุมสภาพแวดล้อมการใช้เหตุผลแบบหลายขั้นตอน ด้วยการผสานรวมตรรกะการวางแผนที่ซับซ้อนเข้ากับสถาปัตยกรรมหลัก โมเดลนี้จึงรักษาความเสถียรที่ยอดเยี่ยมในระหว่างการพัฒนาซอฟต์แวร์อัตโนมัติและการร่างเอกสารทางกฎหมายระดับมืออาชีพ โดยทำหน้าที่เป็นเครื่องยนต์หลักสำหรับกระบวนการทำงานอัตโนมัติที่ต้องการความแม่นยำสูงสุดและความสม่ำเสมอในระยะยาว
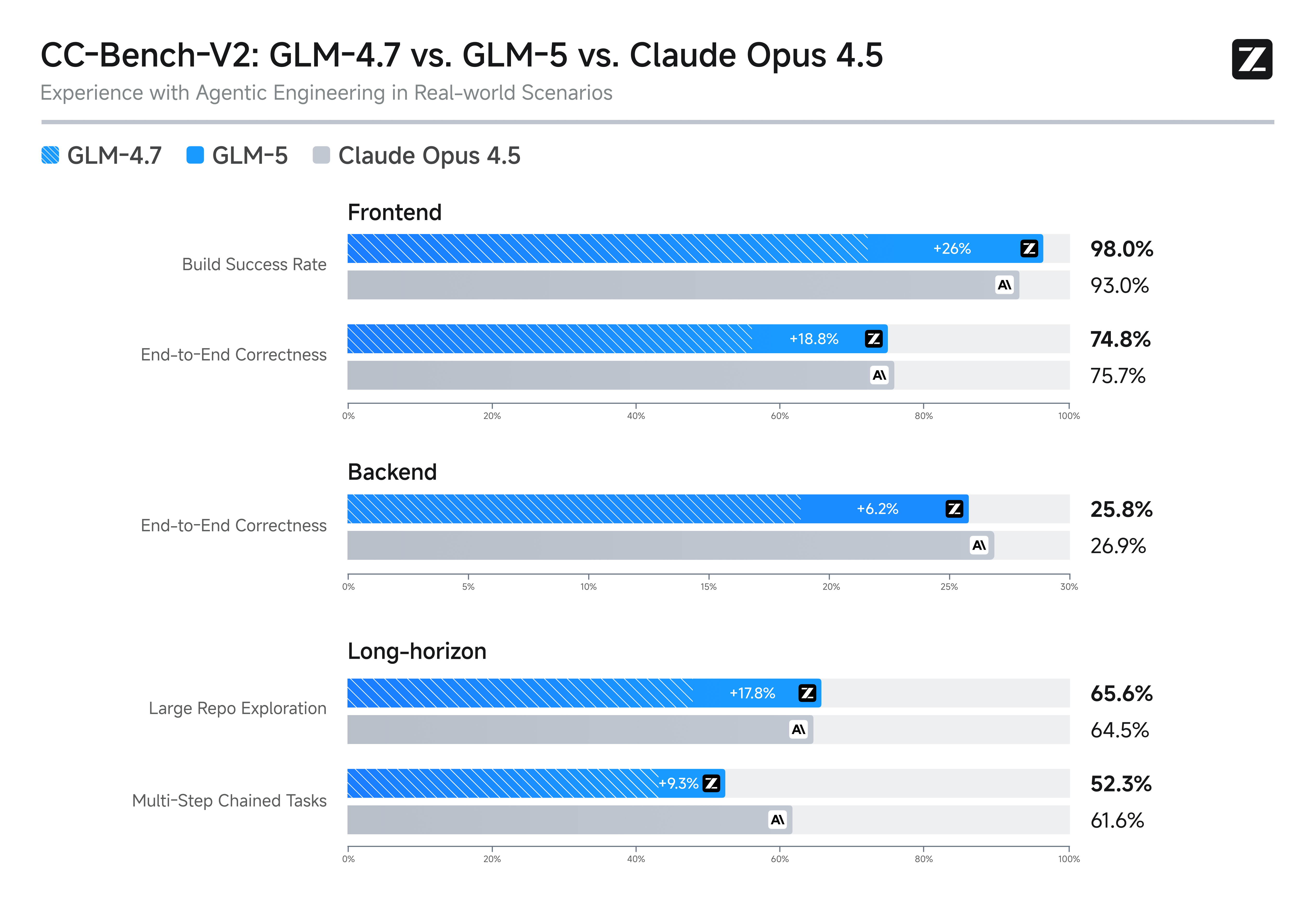
Slime การเรียนรู้แบบเสริมกำลังแบบอะซิงโครนัสและวิวัฒนาการทางตรรกะ
GLM-5 ใช้โครงสร้างพื้นฐานการเรียนรู้แบบเสริมกำลังแบบอะซิงโครนัส "Slime" ที่เป็นนวัตกรรมใหม่ เพื่อปฏิวัติประสิทธิภาพหลังการฝึกอบรม (post-training) และความแม่นยำทางตรรกะ ความก้าวหน้านี้ช่วยปรับปรุงคุณภาพการสร้างโค้ดและการใช้เหตุผลเชิงอัลกอริทึมอย่างมีนัยสำคัญ โดยเหนือกว่าเกณฑ์มาตรฐานก่อนหน้านี้และรักษาอันดับในฐานะโมเดลโอเพ่นซอร์สระดับแนวหน้า นี่คือทางออกที่ดีที่สุดสำหรับการพัฒนาแบบ full-stack และการแก้ปัญหาเชิงโครงสร้างระดับสูง
สิ่งที่คุณทำได้กับ GLM LLM Models
ค้นพบกรณีการใช้งานจริงและเวิร์กโฟลว์ที่คุณสามารถสร้างด้วยตระกูลโมเดลนี้ — ตั้งแต่การสร้างเนื้อหาและระบบอัตโนมัติไปจนถึงแอปพลิเคชันระดับโปรดักชัน
อัจฉริยภาพด้าน Repository ที่ครอบคลุมด้วย GLM-5
GLM-5 API ช่วยให้นักพัฒนาสามารถนำเข้าโค้ดเบสทั้งหมดเพื่อการวิเคราะห์ตรรกะเชิงลึกและการปรับโครงสร้างโค้ด (refactoring) ด้วยการทำแผนที่กราฟความขึ้นต่อกันและติดตามการไหลของข้อมูลแบบอะซิงโครนัสที่ซับซ้อน ทำให้สามารถระบุ race conditions ในกรณี edge-case และหนี้ทางเทคนิคที่ซ่อนอยู่ได้ เหมาะอย่างยิ่งสำหรับการเริ่มงานทีมใหม่อย่างรวดเร็ว (onboarding), การตรวจสอบ PR อัตโนมัติ, และการรักษาความสามารถในการปรับขยายและประสิทธิภาพสูงของสถาปัตยกรรม Microservices
การสร้างต้นแบบ Full-Stack แบบทันทีด้วย GLM-5
สำหรับการพัฒนาแบบ Vibe-driven นั้น GLM-5 จะแปลงแบบจำลองภาพนามธรรมและบันทึกย่อที่กระจัดกระจายให้เป็นคอมโพเนนต์ React หรือ Next.js ที่พร้อมใช้งานจริง โดยจะจัดการงานหนักอย่างการสร้าง Boilerplate, การจัดรูปแบบด้วย Tailwind CSS และการจัดการ State พร้อมทั้งรับประกันความสม่ำเสมอในทุกหน้า เหมาะอย่างยิ่งสำหรับผู้ก่อตั้งที่ทำงานคนเดียว, นักทดลอง UX และการส่งมอบ MVP ที่ใช้งานได้จริงด้วยความเร็วสูง
การจัดระเบียบเวิร์กโฟลว์แบบอัตโนมัติด้วย GLM-5
GLM-5 มีความโดดเด่นในการจัดการงานวิจัยระยะยาวที่ต้องใช้การให้เหตุผลแบบหลายขั้นตอนและการบูรณาการเครื่องมือแบบเรียลไทม์ สามารถสังเคราะห์ข้อมูลตลาดจากหลายแหล่งได้ด้วยตนเอง ร่างสรุปทางกฎหมายที่สอดคล้องกับข้อกำหนด และจัดการตารางเวลาข้ามแพลตฟอร์มที่ซับซ้อนโดยอัตโนมัติโดยไม่สูญเสียบริบท กรณีการใช้งานนี้เหมาะสำหรับผู้จัดการโครงการ ผู้เชี่ยวชาญด้านกฎหมาย และทุกคนที่ต้องการตัวแทนดิจิทัลที่มีความน่าเชื่อถือสูงสำหรับการดำเนินงานเชิงระบบ
เปรียบเทียบโมเดล
ดูว่าโมเดลจากผู้ให้บริการต่างๆ เปรียบเทียบกันอย่างไร — เปรียบเทียบประสิทธิภาพ ราคา และจุดแข็งเฉพาะตัวเพื่อตัดสินใจอย่างมีข้อมูล
| Model | Context | Max Output | Input | Positioning |
|---|---|---|---|---|
| GLM-5 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.7 | 202.75K | 202.75K | Text | Flagship Foundation Model |
| GLM-4.6 | 202.75K | 202.75K | Text | Efficient MoE Model |
| DeepSeek V3.2 | 163.84K | 163.84K | Text | Flagship General |
| MiniMax-M2.5 | 204.8K | 196.6K | Text | SOTA Agentic Coding |
How to Use GLM LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
ทำไมต้องใช้ GLM LLM Models บน Atlas Cloud
การรวมโมเดล GLM LLM Models ขั้นสูงเข้ากับแพลตฟอร์มที่เร่งด้วย GPU ของ Atlas Cloud ให้ประสิทธิภาพ ความสามารถในการขยาย และประสบการณ์นักพัฒนาที่ไม่มีใครเทียบได้
ประสิทธิภาพและความยืดหยุ่น
เวลาแฝงต่ำ:
inference ที่ปรับแต่ง GPU เพื่อการตอบสนองแบบเรียลไทม์
API แบบรวมศูนย์:
รัน GLM LLM Models, GPT, Gemini และ DeepSeek ด้วยการเชื่อมต่อเดียว
ราคาโปร่งใส:
ชำระเงินต่อโทเค็นที่คาดเดาได้พร้อมตัวเลือก serverless
องค์กรและขนาด
ประสบการณ์นักพัฒนา:
SDK, การวิเคราะห์, เครื่องมือปรับแต่ง และเทมเพลต
ความน่าเชื่อถือ:
ความพร้อมใช้งาน 99.99%, RBAC และการบันทึกที่พร้อมสำหรับการปฏิบัติตาม
ความปลอดภัยและการปฏิบัติตาม:
SOC 2 Type II, สอดคล้อง HIPAA, อธิปไตยข้อมูลในสหรัฐอเมริกา
คำถามที่พบบ่อยเกี่ยวกับ GLM LLM Models
ด้วยข้อมูลการฝึกอบรมขนาด 28.5 ล้านล้านโทเคนและผลการทดสอบเกณฑ์มาตรฐานที่ยอดเยี่ยม GLM-5 จึงได้รับการยอมรับอย่างกว้างขวางว่าเป็น "เพดานของโอเพ่นซอร์ส" รุ่นนี้มีความสามารถและตรรกะเทียบเท่าหรือเหนือกว่าโมเดลเชิงพาณิชย์ระดับโลกชั้นนำ โดยมอบรากฐานที่ทรงพลังและมีประสิทธิภาพสูงสำหรับระบบนิเวศนักพัฒนาทั่วโลก
HLE คือเกณฑ์มาตรฐานที่มีความยากสูง ซึ่งออกแบบมาเพื่อทดสอบว่า AI มีความรู้และการใช้เหตุผลระดับผู้เชี่ยวชาญแบบมนุษย์หรือไม่ การที่ GLM-5 ได้คะแนนสูงสุดแสดงให้เห็นว่าความเชี่ยวชาญด้านวิทยาศาสตร์ระดับแนวหน้าและตรรกะที่ซับซ้อนได้ก้าวถึงหรือแซงหน้าระดับของโมเดลปิด (closed-source) ชั้นนำแล้ว
BrowseComp เป็นกระดานผู้นำที่ชัดเจนสำหรับความสามารถแบบ "Agentic" โดยมุ่งเน้นที่การวางแผนและการดำเนินการงานที่ซับซ้อนในสภาพแวดล้อมเว็บจริง คะแนนสูงสุดแสดงถึงความสามารถของ GLM-5 ในการนำทางเบราว์เซอร์อย่างอิสระและบูรณาการข้อมูลข้ามหน้า ซึ่งบ่งบอกว่าเป็นเครื่องมือ Web Agent ชั้นนำ
สถาปัตยกรรมนี้มอบ "ฐานความรู้" ขนาดมหึมาที่มีพารามิเตอร์ถึง 744 พันล้านตัว โดยเปิดใช้งานเพียง ~40 พันล้านตัวในระหว่างการอนุมาน (inference) สำหรับนักพัฒนา สิ่งนี้แปลว่าเป็นความหนาแน่นของความรู้และความลึกซึ้งในการให้เหตุผลระดับโลก ซึ่งเหนือกว่าโมเดลแบบหนาแน่น (dense models) เช่น Llama-3 405B ด้วยความหน่วง (latency) และต้นทุนที่ต่ำกว่า
พารามิเตอร์ทั้งหมดแสดงถึง "ความจุความรู้" ของโมเดล โดยที่ 744B ช่วยให้สามารถจัดเก็บข้อเท็จจริงของโลกและตรรกะระดับผู้เชี่ยวชาญได้อย่างมหาศาล พารามิเตอร์ที่ใช้งานอยู่ (Active parameters) แสดงถึง "พลังการประมวลผล" ที่ใช้ต่อการอนุมานแต่ละครั้ง ด้วยสถาปัตยกรรม MoE ทำให้ GLM-5 มอบความฉลาดระดับ 744B โดยใช้การประมวลผลเพียง 40B ซึ่งสร้างสมดุลระหว่างฐานความรู้อันมหาศาลกับประสิทธิภาพที่รวดเร็วและคุ้มค่า
ปริมาณข้อมูลสำหรับการฝึกฝนล่วงหน้า (Pre-training) เป็นตัวกำหนด "วิสัยทัศน์ที่กว้างไกล" ของโมเดล 28.5T โทเคนถือเป็นหนึ่งในชุดข้อมูลที่ใหญ่ที่สุดในโลก (ประมาณสองเท่าของ Llama-3) ซึ่งครอบคลุมภาษาที่หายาก บทความวิชาการเฉพาะทาง และโค้ดคุณภาพสูงจำนวนมหาศาล สิ่งนี้ช่วยให้มั่นใจได้ว่า GLM-5 มีความแม่นยำและความสามารถในการสรุปอ้างอิง (Generalization) ที่เหนือกว่าเมื่อต้องจัดการกับคำค้นหาแบบ Long-tail ที่ซับซ้อน ความแตกต่างทางวัฒนธรรม และการเขียนโปรแกรมระบบระดับต่ำ (Low-level system programming)
สำรวจกลุ่มเพิ่มเติม
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.


