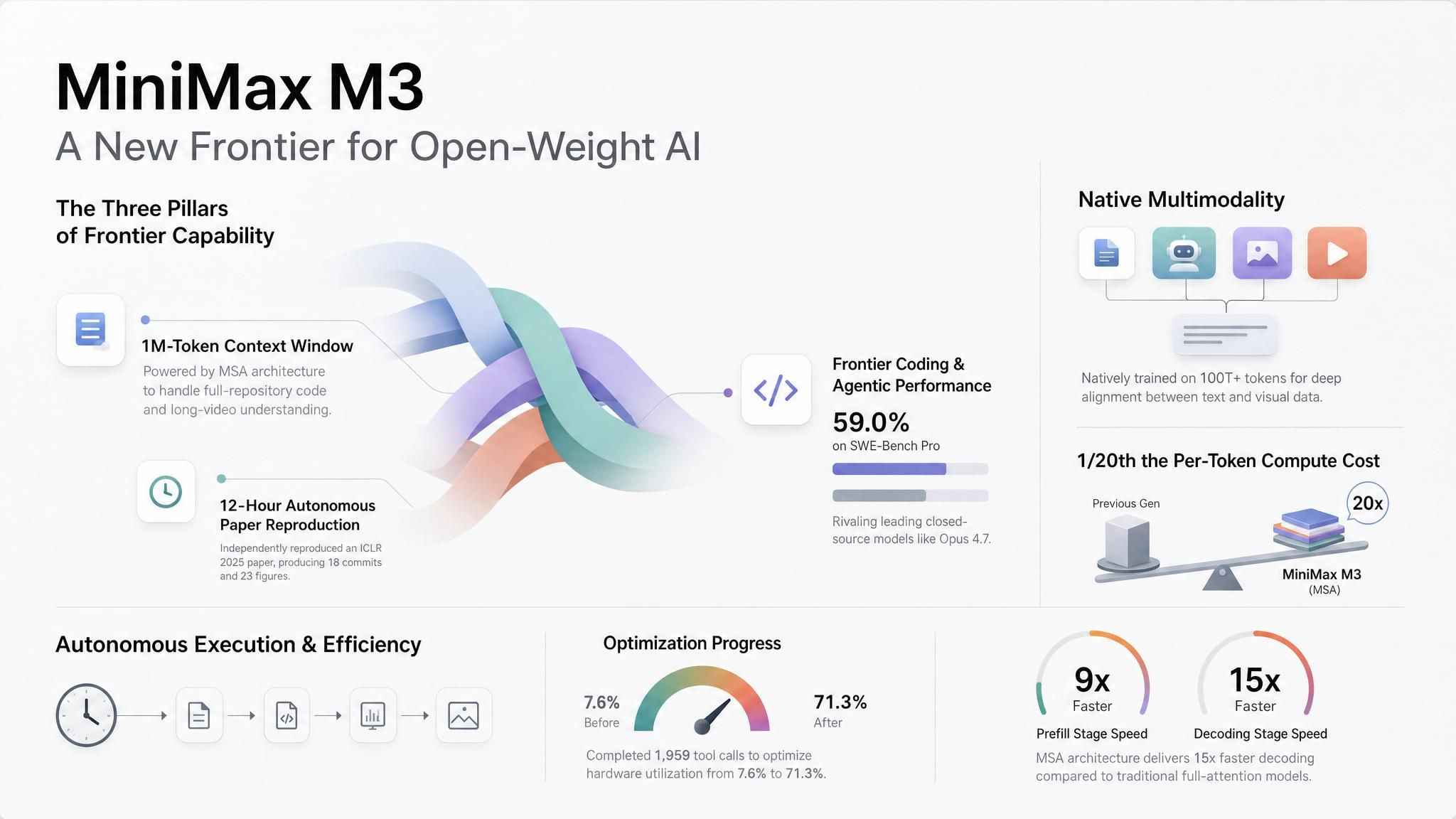
MiniMax M3 現已發布,簡短總結如下:**如果您需要原生支援圖像與視訊、能以低成本處理百萬 Token 上下文,且在執行長程式編碼與 Agent 循環時不會重置的模型,請選用它。**這就是它的適用場景;如果您有需要徹夜自主執行的 Agent,我們強烈建議您測試看看!M3 現已在 Atlas Cloud 上線。
即便您沒有長期執行的 Agent,M3 仍值得關注,因為 MiniMax 實現此目標的路徑深具指標意義。他們透過稀疏注意力架構(MiniMax Sparse Attention, MSA)在保持 1M 上下文的同時兼顧經濟性,將全上下文下的每個 Token 運算成本降至上一代的 1/20 左右——而且這是透過在現有服務架構上選擇成本最低的路徑所達成的,而非採用極端設計。我們預期這將成為所有主流供應商的預設方向:透過稀疏或壓縮注意力機制實現廉價的長上下文。這會將 1M 窗口從競爭優勢轉變為「基本門票」,進而將真正的競爭推向更高層次——亦即模型路由(Routing)策略,而非單一模型的押注。
MiniMax 於 2026 年 6 月 1 日宣布推出 M3。API 現已開放,該公司表示將在公告後約 10 天內發布技術報告與模型權重。
如果您目前正在使用其他前沿模型
當工作任務需要更大的工作集(Working Set)、視覺上下文或比當前預設模型更長的 Agent 循環時,M3 非常值得測試。關鍵在於下表最後一欄:M3 能在您現有的模型基礎上帶來哪些實質增益。
| 若您目前使用 | 適用場景 | M3 帶來的實質增益 |
|---|---|---|
| GPT-5.5 或 GPT-5.5 Pro | Agent 編碼、電腦操作、研究、數據分析及知識工作自動化 | 原生視訊輸入與已宣佈的開放權重路徑——提供另一種具備不同成本曲線的 Agent 選擇,未來可自行託管。(GPT-5.5 已具備圖像視覺能力,故請測試視訊與經濟效益,而非圖像支援。) |
| Claude Opus 4.8 | 長時間執行的編碼 Agent、檢索密集型知識工作與工具使用 | 針對全儲存庫(Full-repo)編碼與單項任務成本的低成本、開放權重替代方案。Opus 4.8 已提供 1M 上下文窗口與視覺功能,因此真正的測試點在於價格、視訊輸入與任務經濟性,而非窗口大小。 |
| Qwen3.7-Plus (多模態) | 視覺與 GUI Agent、截圖轉程式碼、瀏覽器與桌面自動化 | 同樣的多模態能力,但在編碼與 Agent 定位上更強,且具備開放權重路徑。(Qwen3.7-Plus 為專有模型,僅限 API 使用。) |
| Qwen3.7-Max (純文字旗艦) | 文字推理、長視角 Agent、辦公室自動化 | 同一上下文中提供原生圖像與視訊輸入。Qwen3.7-Max 僅支援文字,若需視覺能力通常需切換至 Plus 版本。 |
| DeepSeek-V4-Pro 或 V4-Flash | 成本敏感型推理、編碼、工具調用與長上下文 API 工作負載 | 在長上下文基礎上增加原生多模態(圖像與視訊)能力。DeepSeek-V4 僅限文字,若任務帶有視覺訊號,M3 即為多模態替代方案。 |
實際測試很簡單,若您有以下需求,請嘗試 M3:
- 將儲存庫、任務歷史、日誌與當前計畫保留在同一個工作上下文中
- 讓 Agent 在數十次工具調用後持續運作,而非重置對話
- 一次性針對程式碼、文字、截圖、圖表、PDF 與視訊影格進行推理
- 減少文字模型、視覺模型與獨立檢索層之間的切換
- 比較單項完成任務的長上下文成本,而不僅是每百萬 Token 的價格
不要僅因為發布圖表亮眼就輕易切換。只有當 M3 能完成您目前路由堆疊會丟棄、截斷、溢價或因分散在太多模型而失敗的任務時,再考慮切換。
M3 的優勢所在
Agent 有足夠的發揮空間。 MiniMax 的發布範例超越了常見的聊天演示。在一個測試中,M3 在連續運行近 12 小時後,復現了 ICLR 2025 一篇傑出論文的核心實驗,產出了 18 個 Commit 與 23 個實驗圖表。在另一個測試中,它針對 FP8 GEMM CUDA Kernel 工作了約 24 小時,完成了 147 次基準提交與 1,959 次工具調用,將硬體利用率從 7.6% 提升至 71.3%。
這些範例並非證明「全天候 Agent」一定能在您首次提示時就成功。但它們展示了為何 M3 值得納入工作流候選清單——特別是當模型需要規劃、執行工具、檢查結果、修訂並在早期嘗試失敗後繼續執行任務時。
儲存庫級與文件級上下文。 M3 透過 API 支援高達 1M Token 的上下文,MiniMax 保證最低 512K。在 1M Token 上下文長度下,MiniMax 報告稱每個 Token 的運算成本僅為上一代的 1/20,Prefill 速度提升 9 倍以上,解碼速度提升 15 倍以上。
這改變了產品設計。編碼 Agent 可以看到更多儲存庫內容;研究助手可以攜帶更長的證據軌跡;合約審查工具可以將原始資料與分析結果放在同一個工作集中。檢索機制依然有其價值,但模型不再需要從問題的極小切片開始。
同一請求內的視覺上下文。 MiniMax 從一開始就使用多模態數據訓練 M3。該模型接受圖像與視訊輸入,並支援在同一個上下文中交錯處理文字、圖像與視訊。
這減少了模型間的切換成本。支援工作流可以同時讀取用戶訊息並查看截圖;研究工作流可以對論文中的圖表進行推理;電腦操作 Agent 可以直接觀察螢幕並決定下一步動作,無需先將視覺步驟發送給獨立模型。
現已提供託管存取,權重即將發布。 MiniMax 將 M3 視為開放權重版本,但首發路徑為託管 API 存取。這為團隊提供了一個實用的順序:先測試託管模型,再決定隨後的權重發布是否適合私有部署、微調或內部評估。
明確的定價界線。 MiniMax 表示 512K 輸入 Token 及以下的 API 調用使用標準費率。超過 512K 則進入長上下文定價區間,這通常適用於全儲存庫、完整文件或長視訊的工作負載。M3 同時支援相同價格的「思考(Thinking)」開關,團隊可針對高難度 Agent 工作使用推理模式,針對延遲敏感型任務使用快速模式。
營運成本分析
Atlas Cloud 上的 MiniMax M3 定價為輸入每百萬 Token USD0.30,輸出每百萬 Token USD1.20。Claude Opus 4.7 為輸入 USD5/M、輸出 USD25/M;而 GPT-5.5 為輸入 USD5/M、輸出 USD30/M。
這使得 M3:
- 輸入成本比 Opus 4.7 與 GPT-5.5 便宜 94%
- 輸出成本比 Opus 4.7 便宜 95.2%
- 輸出成本比 GPT-5.5 便宜 96%
Token 價格需結合工作負載形態才有意義。將大型儲存庫放入上下文的編碼 Agent 主要消耗輸入成本;進行研究或起草且帶有冗長解釋的工作流則消耗更多輸出成本。多模態 GUI Agent 還需支付視覺上下文費用,且 Token 換算取決於供應商。
下表為費率轉換參考,非基準測試。假設為美元定價,無快取命中、無批次折扣、無地區溢價、無工具調用費且無重試。針對 GPT-5.5,OpenAI 表示超過 272K 輸入 Token 的提示詞將按全會話輸入 2 倍、輸出 1.5 倍定價,因此長上下文範例採用該較高的有效費率。
| 模型 | 使用費率 | 100K 輸入 + 5K 輸出 | 500K 輸入 + 20K 輸出 | 成本分析 |
|---|---|---|---|---|
| MiniMax M3 on Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | 低成本多模態路徑。比 DeepSeek Flash 貴,但遠低於封閉前沿模型。 |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | 純文字高流量工作的最便宜選擇。無視覺輸入時首選。 |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | Token 成本與 M3 相近,但僅限文字。無視覺內容時的更好比較對象。 |
| Qwen3.7-Plus | $0.40/$1.60 (<256K); $1.20/$4.80 (>256K) | $0.05 | $0.70 | 短多模態調用具競爭力。超過 256K 後長上下文定價影響經濟效益。 |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | 比 GPT 與 Claude 便宜,但除非在該任務勝出,否則非批量預設。 |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | 高風險編碼、工具使用與長上下文可靠性的首選。 |
| GPT-5.5 | $5 / $30 (標準); $10 / $45 (>272K) | $0.65 | $5.90 | 當模型的工具使用、電腦操作行為或 Token 效率能回本時選用。 |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | 留給最難任務。此費率屬於不同預算級別。 |
成本解讀:M3 並非列表中最便宜的文字模型。若工作僅涉及文字、高流量且能容忍 Flash 能力級別,DeepSeek V4 Flash 依然勝出。M3 的成本主張在於:它將原生圖像與視訊輸入、長工作上下文與 Agent 編碼帶入一個接近 DeepSeek V4 Pro,但遠低於 GPT-5.5、GPT-5.5 Pro 與 Claude Opus 4.8 的價格區間。
對於一次 500K 輸入、20K 輸出的 Agent 任務,M3 比 Claude Opus 4.8 便宜約 17 倍,比 GPT-5.5 便宜約 34 倍(計入 OpenAI 長上下文倍數)。比 Qwen3.7-Plus 便宜約 4 倍,比 Qwen3.7-Max 便宜約 8 倍。針對 DeepSeek,答案取決於模態:純文字首選 Flash,V4 Pro 則屬同一範圍。若任務包含截圖、圖表、UI 狀態或視訊影格,M3 可避免額外路由至視覺模型的步驟。
按月計算,差距更明顯。一個包含 10M 輸入與 1M 輸出的工作負載,M3 約需 $4.20,DeepSeek V4 Flash 約 $1.68,V4 Pro 約 $5.22,Claude Opus 4.8 約 $75,GPT-5.5 約 $80,GPT-5.5 Pro 約 $480。
我們的建議: 將高價模型視為需要「證明其價值」的路徑。如果 GPT-5.5 或 Opus 4.8 能一次執行完成艱鉅任務,而 M3 需要三次重試加上人工修正,那麼廉價的調用反而不便宜。如果任務是長上下文多模態分析、儲存庫級編碼分類、帶截圖的支援工單自動化或 M3 能達到品質門檻的文件工作,其經濟效益使其成為強有力的路由候選者,而非僅僅是發布週的曇花一現。
審慎看待基準測試數據
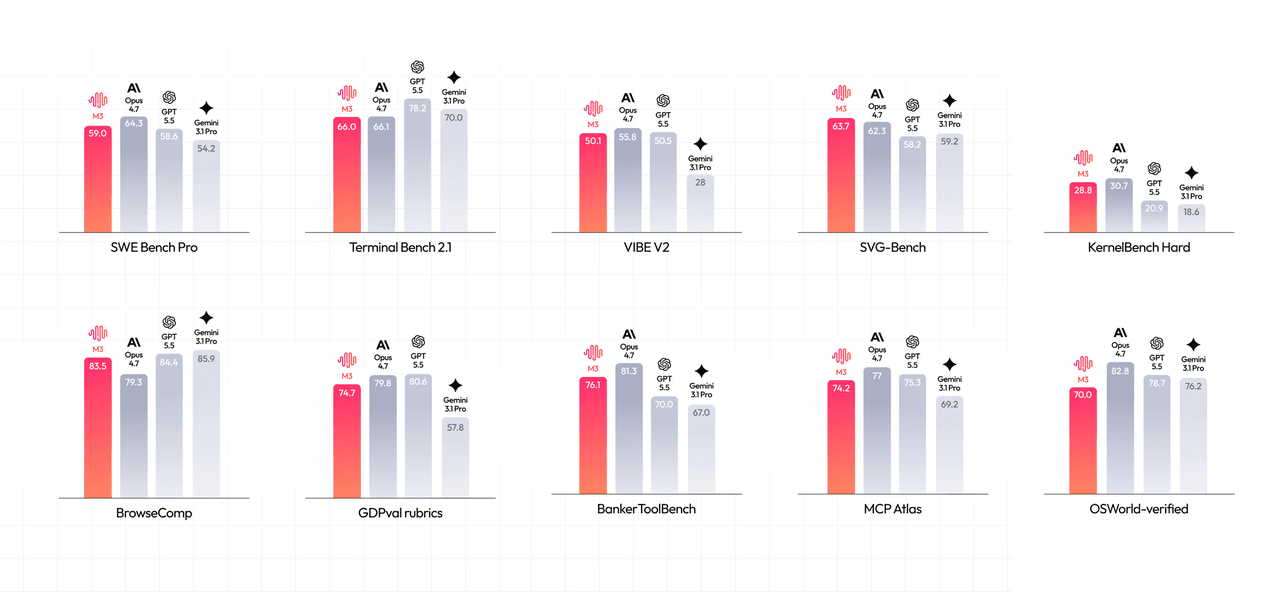
MiniMax 報告在編碼與 Agent 任務中表現強勁:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas (第三方 MCP 工具使用基準,與 Atlas Cloud 無關): 74.2%
- BrowseComp: 83.5 (Claude Opus 4.7 為 79.3)
關於最後一行需注意:MiniMax 是以 Opus 4.7 進行基準測試,但 Opus 4.8 於 5 月 28 日發布,比 M3 發布早了四天。發布時的比較在第一天就已落後了一個版本——這是一個小細節,但也預示了下文的觀點。
在 PostTrainBench(要求模型在 12 小時內合成數據、訓練、評估與迭代四個基礎模型)中,MiniMax 報告 M3 為 0.37,低於 Opus 4.7 的 0.42 與 GPT-5.5 的 0.39,但優於其他參賽者。
這些分數僅適用於初步篩選,不足以作為生產環境的決策依據。 MiniMax 在自有基礎設施上運行許多測試,且部分評估使用了特定腳本。在將分數寫入銷售簡報或決策依據前,請務必針對您自己的程式碼、文件、提示詞、延遲目標與預算重新執行任務。
如何評估 M3 與現有前沿模型
將 M3 視為「候選模型」而非「預設模型」。如果您在 1M Token 窗口中填充了無關文件、過時日誌或用戶發送的所有歷史訊息,這反倒會掩蓋架構缺陷。
針對 GPT-5.5、Claude Opus 4.8、Qwen3.7-Plus/Max、DeepSeek-V4-Pro/Flash 與 M3 運行相同的測試集。然後根據任務而非供應商聲譽比較結果。
從這六個測試開始:
- 全儲存庫編碼: 給予每個模型相同的問題、儲存庫切片、工具存取權與超時設定。評分 patch 品質、測試通過率、差異大小與不必要的編輯。
- 長上下文檢索: 將相關細節置於上下文開頭、中間與結尾。加入相似的干擾項。檢查每個模型檢索到的是正確的實例,而不僅僅是匹配的詞組。
- 工具循環耐力: 運行需要 30、60 與 100 次以上工具調用的任務。觀察每個模型是否保持穩定的計畫、是否重複自身、是否丟失早期約束或在任務完成前停止。
- 視覺 Agent 工作: 給予每個多模態模型一份支援工單加截圖、一篇論文加圖表,或產品規範加 UI 截圖。針對純文字或視覺能力較弱的路徑,計算額外的模型切換成本。
- 真實上下文下的延遲: 比較 128K、512K 與 1M 輸入 Token 下的首字延遲與總完成時間。沒有延遲數據,請勿輕易採信 1M 窗口聲稱。
- 單項完成任務的成本: 測量輸入 Token、輸出 Token、重試次數、工具調用、快取命中、延遲與人工修正。如果需要三次重試,更便宜的模型調用反而可能成本更高。
這是大多數團隊在模型問題上犯錯的地方。他們詢問哪個模型擁有最好的發布基準測試。生產環境的問題更窄:哪個模型能以您產品可承受的品質、延遲與成本完成此工作流?
MSA 如何保持長上下文的可利用性
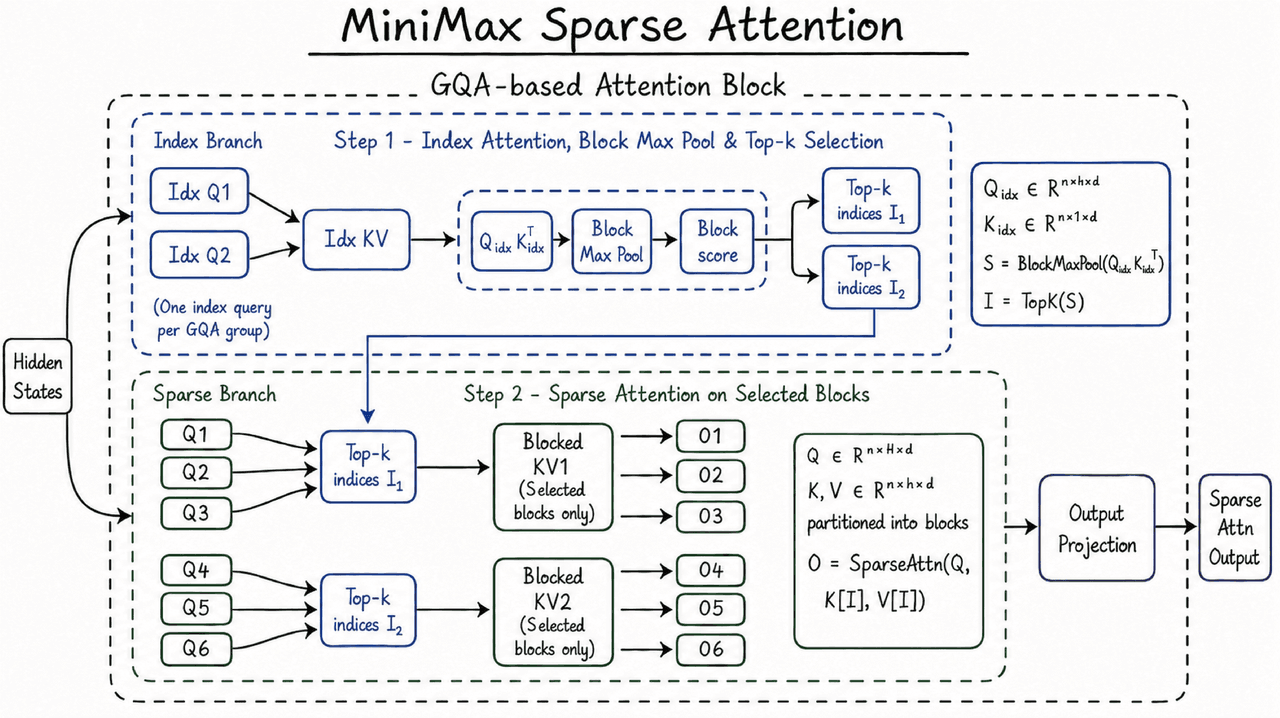
M3 的上下文窗口依賴於 MiniMax 稀疏注意力機制(MSA)。
完整注意力機制讓每個 Token 都能關注其他所有 Token。隨著序列變長,工作量呈平方級增長。稀疏注意力增加了選擇步驟,僅對先前上下文中最重要的部分執行注意力。
MiniMax 表示 MSA 將 KV 快取劃分為區塊,並在區塊級別進行選擇。KV 快取存儲來自早期 Token 的 Key 與 Value 向量,它是長上下文推理中記憶體流量的主要來源。MiniMax 還描述了一種稱為「KV outer gather Q」的運算元設計:KV 區塊成為外循環,命中區塊的查詢被匯集到該區塊,每個區塊僅讀取一次,記憶體存取保持連續。
在 MiniMax 的發布文章中,該設計在 M3 的頭部配置下,運行速度比開源的 Flash-Sparse-Attention 與 flash-moba 快 4 倍以上。MiniMax 同時表示在大多數消融實驗中,MSA 與完整注意力機制表現相當。
此工程聲稱至關重要,因為如果團隊負擔不起使用,1M Token 窗口將毫無價值。MSA 是 MiniMax 將長上下文定義為 M3 正常操作模型的一部分(而非一次性演示模式)的原因。這並非獨有,DeepSeek 的 V4 同樣出於此原因採用了混合式壓縮稀疏注意力。廉價長上下文正成為架構預設。
更大的趨勢:模型發布正成為「路由事件」
M3 並非孤立發布,它符合整個市場的趨勢模式。
最明顯的趨勢在於時間表。在大約六週內,四款 1M 上下文模型相繼推出:
- DeepSeek V4-Pro 與 V4-Flash — 4 月 24 日,開放權重,1M 上下文,思考/非思考模式
- Qwen3.7-Max — 5 月 20 日,純文字推理旗艦,1M 上下文(多模態 Qwen3.7-Plus 於 6 月初跟進)
- Claude Opus 4.8 — 5 月 28 日,Opus 系列支援 1M 上下文
- MiniMax M3 — 6 月 1 日,1M 上下文加原生多模態與開放權重路徑
在一個季度內,百萬 Token 窗口已從差異化優勢變為基本門票。稀疏注意力、思考開關、Agent 基準測試與分級長上下文定價也在經歷同樣過程。預計模型頁面將持續向相同的核心功能靠攏。
迭代速度甚至超過了行銷。MiniMax 自家的 M3 發布基準對標的是 Opus 4.7,但 Opus 4.8 早在四天前就已發布。您上週用來對標的模型,並非您競爭對手這週正在使用的模型。這正是「路由事件世界」的一個例子。
這並沒有讓 M3 變得不重要,但它改變了開發者應優化的方向。
模型優勢的衰退速度將快於整合工作。如果團隊將某個供應商硬編碼進 Agent 堆疊中,每次重大發布都將變成一場遷移專案。如果團隊根據任務、價格、延遲、模態與評估結果進行路由,每次重大發布都將僅是一次路由更新。
贏家不是選擇一個模型並堅持一年的團隊,而是能夠在今天測試 M3,明天將其與 GPT-5.5、Claude Opus 4.8、Qwen3.7 與 DeepSeek-V4 進行比較,並在數據指示時靈活切換流量的團隊。
其他供應商能複製與無法複製的
供應商首先可以複製表面特徵:
- 更長的上下文窗口
- 稀疏注意力變體
- 思考模式開/關
- 編碼 Agent 基準測試頁面
- 多模態發布演示
- 開放權重或類開放權重訊息
困難的部分則需要時間:
- 實際並發環境下的穩定長上下文服務
- 上下文內部的品質,特別是存在干擾項時
- 多次工具調用後的 Agent 可靠性
- 橫跨文字、圖像、圖表與視訊的多模態對齊
- 當用戶真正使用整個窗口時依然穩定的定價
- 生產環境團隊可信賴的清晰模型 ID、版本控制與故障備援
這正是開發者應花費評估時間的差距所在。不要只問其他供應商是否能宣稱 1M 窗口。要問模型在 Token 750,000 處隱藏的指令是否仍能遵循,是否能在不偏移的情況下比較兩張相似的截圖,延遲是否保持可接受,以及經濟效益能否在真實用戶流量下生存。
為什麼要透過 Atlas Cloud 運行
Atlas Cloud 為 LLM、圖像、視訊與音訊工作負載的 300 多個模型提供單一 API 金鑰。隨著模型發布趨同於相同的頭條功能,這一點顯得格外重要。
您可以將 M3 與堆疊中的現有模型進行對比測試,將流量引導至表現最佳的模型,並在發布新版本時保持整合介面的穩定。您可以在 GPT-5.5 勝任電腦操作工作時保留它,在 Claude Opus 4.8 勝任長期編碼 Agent 時保留它,在 Qwen3.7-Plus 勝任多模態 GUI Agent 時使用它,在價格/性能勝出時使用 DeepSeek-V4,並在長上下文加原生多模態能改善結果時加入 M3。
讓 M3 在長上下文與多模態能帶來效益的地方發揮作用。在其他模型依然領先的地方保留它們。依據評估結果而非發布週的炒作來進行切換。
[CTA - 開發者意圖: 在 Atlas Cloud 運行 M3 -> atlascloud.ai/models | 獲取 API 金鑰 -> console.atlascloud.ai]






