RSpqXx0wq8Q
2026 年 5 月 19 日,Google I/O 大會上,DeepMind 發布了 Gemini Omni。同一天,Gemini Omni 提示詞指南在 DeepMind 文件網站上線,位置夾在 Omni Flash 模型卡片與 API 說明之間。大多數人關注的是主題演講演示,而這份文件卻鮮少被閱讀。
先說重點。Gemini Omni 是 DeepMind 新推出的多模態生成模型。其首個產品 Gemini Omni Flash 可從文字、圖像、音訊或影片的任意組合中生成長達 10 秒的影片。所有輸出內容均帶有 SynthID 浮水印。AI Plus、AI Pro 及 AI Ultra 訂閱者可立即使用;據 Gagadget 報導,YouTube Shorts 與 YouTube Create 應用程式用戶將於發布當週獲得免費存取權。根據 Google 的說法,API 存取權限將在「未來幾週內」開放。
回到提示詞指南。Google DeepMind 在「世界理解」(World understanding)章節中直接指出了變化:
使用 Veo 時,你需要提供精確的指令才能獲得最佳結果。但使用 Gemini Omni,你無需過於執著於提示詞的規範性。只需告訴 Omni 你想創造什麼,看著模型的推理能力與世界知識將細節呈現出來即可。
翻譯過來就是:少寫點。
將此與字節跳動(ByteDance)和快手(Kuaishou)為各自影片模型發布的提示詞指南對比來看,儘管架構不同,但觀點一致。
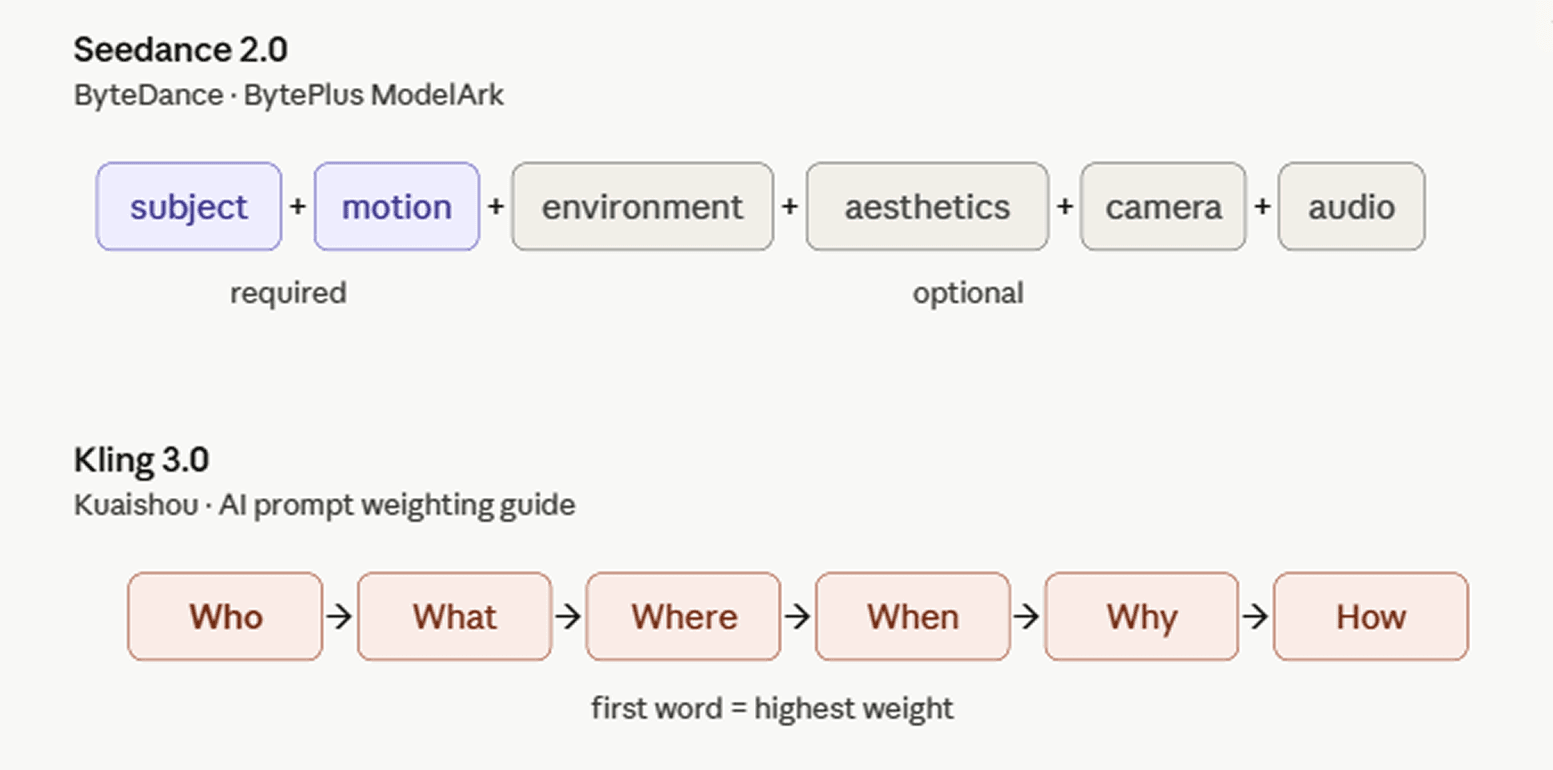
字節跳動在其國際開發者平台上說明了 Seedance 2.0 的 BytePlus ModelArk 提示詞指南。其推薦結構為:主體 + 動作 (+ 環境 + 美學 + 攝影機運鏡/剪輯 + 音訊)。並非所有組件都是必需的,只需挑選適合鏡頭的內容即可。
快手的 AI 提示詞加權指南則透過 5W1H 公式(誰 Who、什麼 What、哪裡 Where、何時 When、為什麼 Why、如何 How)來架構。其中「Who」(主體)通常權重最高,放在提示詞開頭,因為在 Kling 3.0 中,字詞位置決定了權重:越靠前的內容獲得的運算關注度越高。風格選擇(如媒材或視角)放在最後效果最好,作為對已建立場景的篩選。該指南警告不要盲目堆疊元素;過多衝突的關鍵字會降低品質。
三家公司獨立得出此建議,這暗示了它們的模型在同一時期達到了相似的能力水平。Google 建議少寫點,字節跳動標記多數組件為可選,快手則強調詞序勝過單純的數量。具體架構雖有差異,但三家實驗室都引導創作者使用更寬鬆、更自然的提示詞。
現在來看看 Gemini Omni 提示詞指南在實務中如何運作。
Gemini Omni 提示詞結構:Google DeepMind 使用的 5 個維度
該指南以一個完整範例開頭:
一個廣角追蹤鏡頭平緩地掠過寧靜的湖面,展現出一個懸浮在空中的巨大、具備反光感、鉻合金質感的豆狀物,它緩慢旋轉,露出下方清澈蔚藍湖水中部分被淹沒的相似物體,以及雄偉懸崖的扭曲倒影;一輪燦爛的太陽在懸浮異常物後方升起,將整個場景沐浴在清脆、空靈的日光中,呈現出鮮豔的藍色與綠色調,營造出電影般令人敬畏的氛圍,並配以宏偉而異世的管弦樂配樂,強調了外星景觀的廣袤與神祕,懸浮物體發出微弱而深沉的嗡嗡聲。
超過 90 個字。將其拆解後可歸納為 5 個維度。
- 鏡頭取景與運鏡。廣角、中景還是特寫?攝影機應該平緩滑動還是快速衝刺?這兩個動詞會產生明顯不同的輸出,因此在尋找合適的動感時,多做幾次嘗試是值得的。
- 風格。寫實、電影感、空靈、宏偉?這個維度不需要詳細描述。告訴模型情感基調即可。
- 光影。光從哪裡來?太陽、路燈,鏡頭內還是鏡頭外?應該感覺清脆、溫暖還是空靈?
- 場景。指南中有一句話值得強調:「你不需要描述每一個微小細節,因為 Omni 會根據你的整體意圖來運作。」這與 Seedance 和 Kling 官方文件中的觀點一致。
- 動作與互動。場景中的人物與事物,他們如何移動,如何互動。
Gemini Omni 對話式編輯 vs. Veo 提示詞重寫
Omni 與 Veo 產生的生成品質相當。真正的差距在於影片生成後你可以做什麼。
過去,更改一個細節意味著要重寫整個提示詞、重新生成,並祈禱影格間的一致性保持不變。Omni 用對話取代了這一過程。
官方指南給出了一些範例。
一段小男孩的停格動畫影片。第一次編輯:「把蝴蝶換成蜜蜂。」接著:「把蜜蜂換成一小群螢火蟲。」每次對話調整一個元素;其他影格會自動保留。
攝影機的運作方式也一樣。一段小提琴家的影片可依序下達三個指令:「將小提琴家傳送到圖像環境中」、「讓小提琴消失」、「將攝影機角度改為小提琴家的肩後視角」。環境更換、物件移除、攝影機重新定位,全透過自然語言完成。
有一個值得注意的陷阱。第三方評測者指出,如果你的編輯指令過於模糊,Omni 傾向於過度編輯,從而改變了你想要保留的元素。Google 的建議是:每次僅變更一個變數,並明確說明哪些部分應保持不變。
跨模態同步的範例更有趣。以一段公寓大樓的夜間影片為例,加入指令「公寓的燈光開始隨音樂同步閃爍」。模型會分析音軌中的節拍,並將窗戶燈光與之對齊。在 After Effects 中完成此操作需要時間軸、節拍器以及逐影格的手動關鍵影格設定。
Gemini Omni 的 4 大先進功能:世界知識、文字渲染、動作參考、多重輸入
指南後半部分拆解了 4 項功能。
應用型世界知識
範例提示詞:解釋常規運算與量子運算之間的區別。使用一種融合了極簡主義向量形狀與豐富有機紋理的當代平面媒體風格來視覺化這句話。該美學定義為高對比度、「電子」風格的霓虹粉、青色與青檸綠配色,置於深海軍藍背景之上。這種風格的標誌是使用點畫陰影與顆粒感漸層,為原本簡單的幾何形式增加了觸感,類似 Risograph(孔版印刷)的質感。結合尖銳邊緣與柔和的斑點過渡,這幅插畫展現出一種俏皮的編輯感。
模型本身已知曉什麼是量子疊加,以及如何透過一組比較鏡頭來表達它。用戶無需解釋量子力學,只需說明視覺基調即可。
這之所以有效,是因為 Omni 運行在一個前沿推理模型之上,這是純生成影片模型無法比擬的。Demis Hassabis 在 I/O 會後的 Semafor 採訪中,將 Omni 定位為打造能更好地理解現實世界 AI 計畫的一步。他指出 Alphabet 旗下的自動駕駛部門 Waymo 已經在測試類似的世界模型,賦予自動駕駛汽車一種處理不可預測情況的「想像力」。影片生成僅是該架構最顯著的應用。
文字渲染
範例提示詞:逐字顯示,一次一個單字出現在螢幕上,每個單字呈現不同的動畫風格,與節奏完美匹配,快節奏剪輯。
複雜動作參考
提示詞範例:編輯此內容,保留所有事物不變,增加從滑板中噴發出的動畫運動特效。
多重輸入參考
提示詞範例:來自影片的鳥類鬆散地形成基於圖像的鳥類不完美形狀。它們根據音訊中的音樂移動,並在飛行時消散。
風格遷移
提示詞範例:創建影片參考的四部分風格演變,始於充滿活力的彩色蠟筆美學,呈現豐富、蠟質、有紋理的筆觸與俏皮的手繪角色設計,背景為重顆粒感的紙張。無縫過渡到紋理紙上的石墨鉛筆素描,利用交叉陰影、變化的線條粗細以及 12fps 的「線條抖動」效果來強調手繪感。接著,演變為超寫實的 3D 半透明玻璃風格,特徵為複雜的光線折射、焦散圖案與簡約工作室設定內的柔和內部光芒。最後以觸感十足的 Risograph 印刷質感結尾,應用有限的三色調色板、顆粒感半色調紋理以及刻意的套印重疊,以實現復古機械感。
分鏡參考
提示詞:在故事中展示我。完全按照順序從左上角開始執行故事。10 秒內完成整個故事。電影感。
跨鏡頭一致性
為什麼 Gemini Omni、字節跳動 Seedance 與快手 Kling 的提示詞建議趨於一致
回到早先的觀察。Seedance、Kling 和 Omni 在提示詞建議上的相似性並非互相抄襲的結果。更合理的解釋是,這一代模型憑藉自身實力達到了相似的能力水準。
一旦模型能夠在場景層面上處理自然語言、透過世界知識補充細節並推斷出用戶的真實意圖,過度規範反而成為瓶頸。三家實驗室對於要「加回」多少結構化內容意見不一,但一致認同答案不是寫得越多越好。
這是擴散模型與大型語言模型聯合訓練兩年的成果。Omni 將此結果推向了相對完整的狀態。
透過 Atlas Cloud 呼叫 Gemini Omni:Seedance、Kling、Veo 的統一 API
Gemini Omni 即將登陸 Atlas Cloud。Atlas Cloud 整合了文字、圖像、影片及音訊領域的 300 多種 AI 模型。主要的影片模型均已在該平台上運行:Seedance 2.0、Kling 3.0、Wan 2.7、Veo 等。如需並排比較,請參考 Atlas Cloud 的 Wan 2.7 vs Seedance 2.0 vs Kling 3.0 開發者選擇深度解析。
一個帳號即可管理整個流程。無需跨多個區域平台註冊、付款或維護 API 金鑰。Playground 支援互動式除錯。統一的 OpenAI 相容 API 可直接接入現有工作流。
Atlas Cloud 的提示詞庫擁有超過二十個類別、隨時可用的提示詞,涵蓋動畫、科幻、懸疑、美食、Vlog 等格式。每個提示詞均附有範例影片與參數說明。複製、修改幾個詞,即可執行。
影片生成生產環境的統一 API
當 Google 在 Gemini 應用程式和 Google Flow 中向終端用戶推出 Gemini Omni Flash 時,希望將同樣的多模態影片引擎嵌入自身工作流的開發者與產品團隊,需要一個穩定且可預測的 API 層。
Atlas Cloud 透過統一的 OpenAI 相容 API 提供 Gemini Omni Flash,同時整合了 300 多種其他圖像、影片與 LLM 模型——讓你無需周旋於不同的供應商帳號、計費門戶或 SDK,即可整合 Google 的原生多模態模型。
兩款 Gemini Omni Flash 變體現已在 Atlas Cloud 上線:
| 變體 | 適用場景 | 輸入 | 解析度 | 時長 | 起售價 |
|---|---|---|---|---|---|
| Gemini Omni Flash 文字轉影片 (開發者版) | 純提示詞驅動的電影感生成 | 文字 (最高 20,000 字元) | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash 圖像轉影片 (開發者版) | 基於真實參考的主體一致性影片 | 文字 + 最多 7 張參考圖 | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
快速入門 — 5 行程式碼生成 Gemini Omni Flash 影片:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API 會立即回傳預測 ID — 請輪詢 /api/v1/model/prediction/{id} 以取得渲染後的 MP4 網址。完整的 API 結構描述、7 種程式語言的範例程式碼以及無程式碼 Playground 均可在上述模型頁面中找到。






