AI 视频中的原生音频生成彻底改变了制作流程。直到最近,使用 AI 生成视频还意味着先制作一段无声剪辑,然后再通过独立的步骤进行搜集、编辑和音频同步。这种额外的步骤不仅增加了时间、成本和复杂性,而且效果往往不尽如人意。在 2026 年,三款领先的模型现在可以在一次处理中同步生成视频及其配套音频:来自 Google DeepMind 的 Veo 3.1、来自快手的 Kling 3.0,以及来自生数科技的 Vidu Q3。
本指南详细剖析了每款模型在音频方面的表现——包括质量、语言支持、同步精度、定价以及实际应用场景。无论你是构建内容流水线的开发者、大规模制作广告的营销人员,还是探索 AI 辅助预制作的电影制作人,本指南都将帮助你为工作流选择最合适的音频生成模型。
*最后更新:2026 年 2 月 28 日*
观看这些模型的横向对比:
音频生成模型概览
| 功能 | Veo 3.1 | Kling 3.0 | Vidu Q3 |
|---|---|---|---|
| 开发商 | Google DeepMind | 快手 | 生数科技 |
| 原生音频 | 支持 | 支持 | 支持 |
| 音频语言 | 以英语为主 | 英语、中文、日语、韩语、西班牙语 | 以英语为主 |
| 口型同步 | 上下文关联同步 | 多语言口型同步 | 上下文关联同步 |
| 音频类型 | 环境音 + 对话 | 环境音 + 多语言对话 | 环境音 + 对话 |
| 最大时长 | 8 秒 | 10 秒 | 16 秒 |
| 最大分辨率 | 720p | 1080p | 1080p |
| Atlas Cloud 价格 | USD0.09/秒 (极速) / USD0.18/秒 (标准) | USD0.095/秒 (Pro) | USD0.06/秒 |
| 每 8 秒片段成本 | USD0.72 (极速) / USD1.44 (标准) | USD0.76 | USD0.48 |
| 音频核心优势 | 环境音效 | 多语言对话 | 视听同步均衡 |
AI 视频中的原生音频是如何工作的
在深入了解各模型之前,理解本语境下的“原生音频”含义非常有帮助。传统的 AI 视频模型生成的是无声视频文件。音频——无论是环境音、音乐、对话还是音效——必须使用其他工具单独生成,或者从库中搜集,然后在后期制作中手动与视频同步。
原生音频模型将音轨的生成作为视频创建推理过程的一部分。模型在读取提示词的同时,不仅生成视觉帧,还同步产生与视觉内容在情境上对齐的音轨。海滩场景会包含海浪声;人物说话会有口型同步的对话;城市街道则会有交通噪音。音频直接嵌入在输出文件中——无需额外的 API 调用,也无需后期同步步骤。
这之所以重要,是因为:
- 省去了一个完整的制作步骤。团队不再需要单独寻找、编辑和同步音频。
- 同步精度更高。由于音视频是同时生成的,其时间对齐比事后拼接更自然。
- 成本降低。无需独立的音频生成 API、付费音频授权或音频编辑工具。
- 迭代速度更快。单次 API 调用即可生成完整的成品,直接进行审阅。
Veo 3.1:影院级环境音频
音频能力
Veo 3.1 处理音频的方式如同电影现场的声效设计师。其优势在于环境音和氛围音,听起来就像是随视频一同在现场收录的一样。如果你提示“日出时的挪威峡湾”,输出内容会包含风声、海浪拍打岩石的声音以及远处的鸟鸣。如果你提示“繁忙的东京十字路口”,输出内容则会呈现交通噪音、行人交谈声和红绿灯信号声。
该模型能处理提示词中的音频情境线索,并生成与视觉环境匹配的音景。这不是随机的噪点叠加在视频上,而是响应场景中特定元素、具有情境意识的生成。
对话处理:Veo 3.1 在提示要求时可以生成语音,但其强项显然在于环境音和氛围音,而非多语言对话。模型对以英语为主的语音处理尚可,但它没有像 Kling 3.0 那样明确的多语言口型同步能力。
音频质量:Veo 3.1 输出的音频干净,没有明显的伪影或数字噪音。频率范围听感自然,环境元素融合流畅。在我们的测试中,音频质量始终与高质量的视频输出保持同步。
Veo 3.1 音频优势
- 业界领先的环境音效,听感如同实地录音
- 干净、无伪影的音频输出
- 强大的上下文感知能力——音频元素与视觉元素精准匹配
- 专业级的影院品质,价格为 USD0.09/秒 (极速) 或 USD0.18/秒 (标准)
- 非常适合品牌内容、自然风光和氛围感片段
Veo 3.1 音频限制
- 以英语为主——多语言对话能力有限
- 没有明确的语言选择参数
- 8 秒的最长限制限制了音频叙事的复杂性
- 环境音是强项,对话和语音处于次要地位
Veo 3.1 代码示例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Veo 3.1 带有丰富音频描述的提示词 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "google/veo3.1/text-to-video", 17 "prompt": "Close-up of a barista pouring steamed milk into a latte, " 18 "espresso machine hissing in the background, soft jazz " 19 "playing in a cozy cafe, warm morning light through windows", 20 "duration": 8, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
Kling 3.0:多语言对话先锋
音频能力
Kling 3.0 采用了一种从根本上不同的音频处理方法。如果说 Veo 3.1 擅长环境音景,那么 Kling 3.0 的核心则是带有口型同步的多语言对话生成。该模型原生支持五种语言的音频生成——英语、中文、日语、韩语和西班牙语,并配有与生成的语音相匹配的精准口型动作。
这不仅仅是简单的文本转语音叠加层。模型在产生音频轨道的同时,还会同步生成人物的面部表情、口型变化和时间节奏。最终效果是,人物看起来确实在用提示词指定的语言进行交流。
对话处理:这是 Kling 3.0 标志性的音频功能。在提示词中指定一种语言,模型就会生成一个说该语言的角色,并配有合适的口型同步。在测试中,西班牙语提示词产生了令人信服的结果,具有自然的口型动作和语调。日语和韩语的输出同样令人印象深刻,语音伴随着符合文化习惯的肢体语言。
环境音频:Kling 3.0 也能生成环境音和氛围音,但这在对话能力面前属于次要功能。背景声音存在且在情境上是恰当的,但它们缺乏 Veo 3.1 那种影院级的深度。
音频质量:语音音频清晰且听感自然。在同时包含对话和复杂环境音的场景中,偶尔会出现一些伪影,但对于以对话为主的内容,其质量完全可以直接用于制作。
Kling 3.0 音频优势
- 支持 5 种语言的多语言对话,具有精准的口型同步
- 符合文化习惯的语音语调和肢体语言
- 强大的角色驱动型音频——是“面对面访谈”类内容的理想选择
- 三款模型中最长,达 10 秒的生成时长
- 卓越的多语言营销及全球化内容制作利器
Kling 3.0 音频限制
- 价格较高,为 USD0.095/秒 (Pro)
- 环境音质量低于 Veo 3.1 的影院标准
- 非常严格的内容审核可能会拦截一些无害的提示词
- 语言质量不一——英语和中文效果最强
Kling 3.0 代码示例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Kling 3.0 带有语言设置的对话提示词 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 17 "prompt": "A professional female presenter speaking in Spanish, " 18 "looking directly at camera, modern office background, " 19 "warm studio lighting, corporate presentation style", 20 "duration": 10, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
Vidu Q3:均衡的视听生成
音频能力
生数科技的 Vidu Q3 定位介于 Veo 3.1 的环境音专注度与 Kling 3.0 的对话专业化之间。该模型生成的同步音频涵盖了环境音效和基础语音,提供了一种均衡的音频生成方式。
对话处理:Vidu Q3 生成的语音具备合理的口型同步准确度。它主要以英语为主,没有 Kling 3.0 的多语言能力。语音输出清晰自然,尽管还没达到 Kling 3.0 五语种支持的那种语言深度。
环境音频:环境音生成表现称职且具有情境意识。模型能读取提示词中的场景描述并生成合适的背景音频。其质量介于 Kling 3.0 的功能性环境音和 Veo 3.1 的影院级声景之间。
音频质量:整体音频输出干净且可用于生产。Vidu Q3 的长处在于稳定性——音频质量在不同类型的提示词下都很可靠,不会出现更专业化模型那种偶尔出现的惊艳或不一致现象。
Vidu Q3 音频优势
- 均衡的方案,同时覆盖对话和环境音频
- 不同内容类型下的质量表现高度一致
- 中等价位,USD0.06/秒
- 对既需要语音又需要环境音的团队来说性价比高
- 干净、无伪影的输出,适合生产使用
Vidu Q3 音频限制
- 以英语为主——缺乏多语言对话能力
- 音频质量未达到 Veo 3.1 的影院高度
- 口型同步精度低于 Kling 3.0 的多语言标准
- 最长时长 16 秒
- 与 Veo 和 Kling 相比,生态系统尚在建立中
Vidu Q3 代码示例
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7 8# Vidu Q3 带有均衡音频需求的提示词 9response = requests.post( 10 f"{BASE_URL}/model/generateVideo", 11 headers={ 12 "Authorization": f"Bearer {API_KEY}", 13 "Content-Type": "application/json" 14 }, 15 json={ 16 "model": "shengshu/vidu-q3/text-to-video", 17 "prompt": "A young man unboxing a new smartphone at a desk, " 18 "speaking excitedly about the features, natural room " 19 "lighting, casual vlog style, ambient room sounds", 20 "duration": 8, 21 "resolution": "1080p" 22 } 23) 24 25result = response.json() 26 27while True: 28 status = requests.get( 29 f"{BASE_URL}/model/prediction/{result['request_id']}/get", 30 headers={"Authorization": f"Bearer {API_KEY}"} 31 ).json() 32 if status["status"] == "completed": 33 print(f"Video with audio: {status['output']['video_url']}") 34 break 35 time.sleep(5) 36```
视听性能对比
各类别音频质量排名
| 类别 | 第一名 | 第二名 | 第三名 |
|---|---|---|---|
| 环境/氛围音 | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| 对话 (英语) | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| 多语言语音 | Kling 3.0 | -- | -- |
| 口型同步精度 | Kling 3.0 | Vidu Q3 | Veo 3.1 |
| 音效 | Veo 3.1 | Vidu Q3 | Kling 3.0 |
| 整体视听同步 | Veo 3.1 | Kling 3.0 | Vidu Q3 |
| 音频一致性 | Vidu Q3 | Veo 3.1 | Kling 3.0 |
定价对比
| 模型 | 单价/秒 | 8秒片段 | 10秒片段 | 100个片段 (8秒) |
|---|---|---|---|---|
| Vidu Q3 | USD0.06 | USD0.48 | USD0.60 | USD48.00 |
| Veo 3.1 Fast | USD0.09 | USD0.72 | N/A (最大8秒) | USD72.00 |
| Kling 3.0 Pro | USD0.095 | USD0.76 | USD0.95 | USD76.00 |
在大规模生产时,价格差异变得显著。一个每月生产 500 个片段的团队,使用 Vidu Q3 将花费 USD240,使用 Veo 3.1 Fast 为 USD360,使用 Kling 3.0 Pro 则为 USD380。问题在于,Kling 3.0 的多语言对话功能是否值得比 Veo 3.1 的影院级环境音或 Vidu Q3 的均衡方案付出更多的溢价。
时长与分辨率
| 模型 | 最长时长 | 最高分辨率 | 帧率 |
|---|---|---|---|
| Vidu Q3 | 16 秒 | 1080p | 24fps |
| Kling 3.0 | 10 秒 | 1080p | 30fps |
| Veo 3.1 | 8 秒 | 720p | 24fps |
Vidu Q3 在 16 秒时长上领先,而 Kling 3.0 在分辨率上有显著优势。对于对话密集型内容,额外的几秒钟允许更完整的句子和更自然的节奏。
如何通过 Atlas Cloud API 使用这些模型
这三款支持音频的视频模型都可以通过同一个 Atlas Cloud API Key 进行调用,无需分别维护 Google、快手和生数科技的账户。
第 1 步:获取你的 API Key
在 Atlas Cloud 注册并导航到 API Keys 标签页。
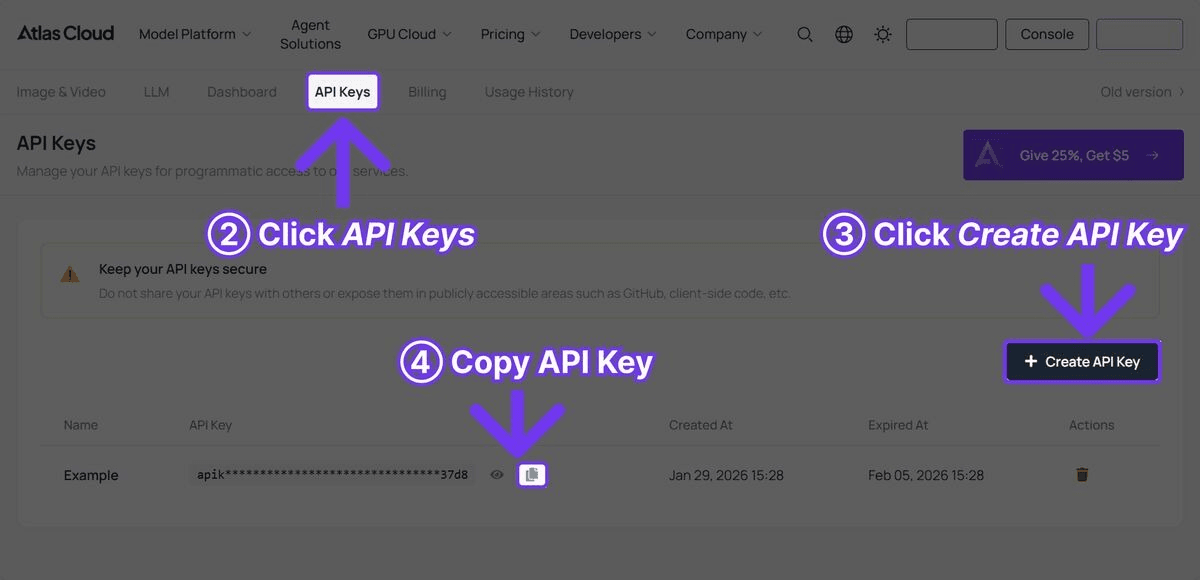
第 2 步:对比全部三款模型
这是一个完整的 Python 脚本,使用相同的提示词从三款模型中生成带音频的视频,方便对比结果:
plaintext1```python 2import requests 3import time 4 5API_KEY = "your-atlas-cloud-api-key" 6BASE_URL = "https://api.atlascloud.ai/api/v1" 7HEADERS = { 8 "Authorization": f"Bearer {API_KEY}", 9 "Content-Type": "application/json" 10} 11 12PROMPT = ("A street musician playing acoustic guitar on a cobblestone " 13 "sidewalk at golden hour, passersby dropping coins, warm natural " 14 "lighting, documentary style") 15 16models = { 17 "Veo 3.1": { 18 "model": "google/veo3.1/text-to-video", 19 "duration": 8 20 }, 21 "Kling 3.0": { 22 "model": "kwaivgi/kling-v3.0-pro/text-to-video", 23 "duration": 10 24 }, 25 "Vidu Q3": { 26 "model": "shengshu/vidu-q3/text-to-video", 27 "duration": 8 28 } 29} 30 31request_ids = {} 32 33for name, config in models.items(): 34 response = requests.post( 35 f"{BASE_URL}/model/generateVideo", 36 headers=HEADERS, 37 json={ 38 "model": config["model"], 39 "prompt": PROMPT, 40 "duration": config["duration"], 41 "resolution": "1080p" 42 } 43 ) 44 result = response.json() 45 request_ids[name] = result["request_id"] 46 print(f"Submitted {name}: {result['request_id']}") 47 48# 轮询所有三个结果 49completed = {} 50while len(completed) < len(request_ids): 51 for name, rid in request_ids.items(): 52 if name in completed: 53 continue 54 status = requests.get( 55 f"{BASE_URL}/model/prediction/{rid}/get", 56 headers={"Authorization": f"Bearer {API_KEY}"} 57 ).json() 58 if status["status"] == "completed": 59 completed[name] = status["output"]["video_url"] 60 print(f"{name} done: {status['output']['video_url']}") 61 time.sleep(5) 62 63print("\nAll videos generated. Compare the audio quality:") 64for name, url in completed.items(): 65 print(f" {name}: {url}") 66```
如何为项目选择合适的模型
在以下场景选择 Veo 3.1:
- 内容具备氛围或环境感。 自然纪录片、旅游内容、品牌宣传片、房产走廊——任何环境音比对话更重要的场景。
- 预算是主要约束条件。 以 USD0.09/秒 (极速) 的价格,Veo 3.1 提供了影院级的经济选择。每月制作成百上千个片段的团队将显著节省开支。
- 影院级画质是首要优先级。 Veo 3.1 的视觉修饰与环境音质相结合,产生出的内容看起来和听起来都如同专业制作一般。
- 你不需要多语言对话。 如果对音频的需求是环境氛围而非交谈,Veo 3.1 是不二之选。
在以下场景选择 Kling 3.0:
- 内容需要角色使用多种语言说话。 这是 Kling 3.0 的定义性功能,没有其他模型能以这种水准生成带有口型同步的多语言对话。
- 口型同步精度至关重要。 对于“面对面”视频、解说内容,或任何角色直接面对镜头的场景,Kling 3.0 的口型同步是目前可用的最准确方案。
- 你需要带有外语音频的更长片段。 Kling 3.0 的 10 秒上限配合五语言支持,提供了 Veo 3.1 的 8 秒限制无法比拟的灵活性。
- 项目面向全球受众。 五语言支持意味着单一工作流即可制作针对英语、中文、日语、韩语和西班牙语市场的视频。
在以下场景选择 Vidu Q3:
- 你需要对话和环境音的平衡。 Vidu Q3 对两者都能出色驾驭,且不会在这二者间过度偏科,使其成为多功能的中庸之选。
- 预算中等且对质量有一定要求。 以 USD0.06/秒的价格,Vidu Q3 是三款原生音频模型中最经济的选择——比 Veo 3.1 Fast (USD0.09/秒) 和 Kling 3.0 Pro (USD0.095/秒) 都要便宜。
- 一致性比极致质量更重要。 Vidu Q3 在不同类型的提示词下都能产出稳定良好的音频,这对于无法进行人工逐一审阅的自动化生产线非常有价值。
- 项目仅为英语,且音频需求一般。 对于英语对话且伴有不错背景声、价格合理的场景,Vidu Q3 是一个稳妥的选项。
音频提示词技巧
从这些模型中获取最佳音频效果需要特定的提示词技术,以下策略适用于所有三款模型:
1. 明确声源描述
模型根据提示词中的声音线索生成音频,描述越具体,效果越好。
- 推荐: “雨水拍打铁皮屋顶的声音,远处雷声轰鸣,窗台上猫的呼噜声”
- 不推荐: “有猫的雨天”
2. 将视觉和音频描述分开
构建提示词时,将视觉和音频元素清晰分开。这有助于模型正确分配二者的权重。
- 推荐: “大厨在木砧板上切蔬菜——刀落在芹菜上的清脆声音,旁边锅里油的滋滋声,厨房通风机的嗡嗡声”
- 不推荐: “大厨在厨房里做饭”
3. 为 Kling 3.0 指定对话语言
使用 Kling 3.0 制作多语言内容时,明确指出语言和情境:
- “一名日本导游用日语讲解寺庙历史,声音清晰且热情”
- “一名西班牙语新闻主播在专业的录影棚环境中,用正统西班牙语播报新闻标题”
4. 使用描述音频情绪的形容词
描述音频氛围的词汇对三款模型都有帮助:
- “安静、私密的氛围” vs “嘈杂、繁忙的环境”
- “隔着窗户沉闷的声音” vs “清晰、近距离的音频”
- “教堂里的回声” vs “死气沉沉的录音棚声学效果”
5. 控制在时长限制内
音频叙事必须契合模型的时间限制。不要在支持 8 秒的模式下要求它生成 30 秒的独白。根据限制设计音频元素:
- 一句简短的对话 (Kling 3.0)
- 一个环境音场景 (Veo 3.1)
- 一个简短的音频时刻 (Vidu Q3)
需要注意的音频限制
所有模型共同点
- 音乐生成有限。 这些模型都不能可靠地生成复杂的音乐。环境类音乐元素(如轻爵士、远处的收音机)尚可,但不要期待完整的管弦乐配乐。
- 音频混合是自动的。 你无法控制对话、背景音与音效的相对音量。模型内部自动完成。
- 没有纯音频输出。 这些模型生成的是带音频的视频。如果需要纯音频生成,专用音频 AI 工具会更合适。
- 时长限制音频叙事。 在 8-10 秒内,音轨必然是简短的。复杂的音频故事或长段对话在单次生成中无法实现。
模型特定限制
- Veo 3.1: 对话在环境音面前处于次要地位。不要在语音内容密集的情境下过度依赖它。
- Kling 3.0: 严格的内容审核可能会意外拦截一些提示词,包括一些无害的音频场景。
- Vidu Q3: 环境音和对话表现均未达到前两款模型的顶级水准。它是通才,而非专才。
常见问题解答
我可以关闭音频生成吗?
音频是作为视频输出的一部分原生生成的。如果你需要无声视频,可以在后期处理中使用任何标准的视频编辑工具或 FFmpeg 命令剔除音轨。
哪款模型的视听同步最好?
在我们的测试中,Veo 3.1 在处理环境和氛围内容时,视听整体同步最紧密。Kling 3.0 在对话口型同步方面处于领先地位。Vidu Q3 表现一贯优秀,但在两个类别中都不算顶级。
我可以生成除 Kling 3.0 支持的五种语言之外的音频吗?
目前只有 Kling 3.0 提供明确的多语言音频生成,且仅限于英语、中文、日语、韩语和西班牙语。其他语言可能会有输出,但准确度无法保证。
我需要额外的音频 API 吗?
不需要。音频自动包含在视频输出中。没有单独的音频 API 端点,没有额外的音频启用参数,生成音频也没有额外收费。API 生成的视频文件包含视听双轨道。
音频质量足以用于商业用途吗?
是的,对于大多数商业应用而言。这三款模型的音频干净、情境准确且可直接生产使用。对于高端广播或影院发行,你可能需要在后期制作中对音频进行增强或替换,但对于社交媒体、网页内容、营销和广告,原生音频已经足够了。
总结建议
“最好”的音频 AI 视频模型完全取决于你的项目需求。
Vidu Q3 是最经济的音频支持模型(USD0.06/秒),并提供了 16 秒的最长剪辑时长。它在对话和环境音频方面表现均很称职,是混合内容类型的稳妥之选。
Veo 3.1 是影院级环境音频的获胜者。如果你的内容侧重于环境、氛围或品牌呈现,且不需要多语言对话,Veo 3.1 能以极具竞争力的价格(USD0.09/秒起)提供最高水准的视听质量。
Kling 3.0 是唯一能够实现带口型同步的多语言对话模型。如果你的工作流需要角色使用多种语言且口型动作精准,在当前水准下别无他选。其定价(Pro 版本 USD0.095/秒)完全对得起这项特殊能力。
建议:三者结合使用。单个 Atlas Cloud API Key 即可调用所有模型。将 Veo 3.1 用于氛围感和品牌内容;在需要多语言发言人时调用 Kling 3.0;对于通用型内容,Vidu Q3 则是性价比之选。一个账户、一个余额、三款强大的模型,让你拥有为每个项目选择最合适工具的灵活性。






