
中国人工智能实验室已经悄然构建出目前市面上最强的一批开源编程模型。对于那些只关注 Anthropic 和 OpenAI 市场动态的开发者来说,DeepSeek、Moonshot(月之暗面)、Zhipu(智谱 AI)、MiniMax 和 Alibaba(阿里巴巴)所提供的模型矩阵之丰富,确实令人惊喜。
在 2026 年,我们需要探讨的不再是这些模型“好不好”,而是哪一个模型适合哪种工作负载、大规模运行的成本如何,以及如何将它们接入你现有的工具链中。本指南涵盖了这三个方面:实验室背景概况、完整规格与成本对照表、实用用例路由指南,以及 Claude Code、Codex 和 OpenClaw 的配置方案。
![]()
为什么最强开源编程大模型 (LLM) 正受到高度关注
转折点出现在 2024 年 12 月发布的 DeepSeek V3。它在 HumanEval 上得分 89.1%,在 SWE-bench Verified 上得分 42.0%,在当时与 Claude 3.5 Sonnet 和 GPT-4o 旗鼓相当。尽管它是开源的,并采用了在每次前向传播中仅激活 6710 亿参数中 370 亿参数的混合专家(MoE)架构(DeepSeek-V3 技术报告,2024 年 12 月)。该架构所带来的高效率,解释了为何其推理成本能显著降低。
这一结果将开发者的目光引向了更广阔的中国开源生态系统。事实证明,DeepSeek 并非孤例。Moonshot AI 的 Kimi K2 系列一直在长文本基准测试中保持领先;阿里巴巴的 Qwen2.5-Coder 系列在代码专用排行榜上位居前列;智谱 AI 的 GLM-5 系列则能够输出精准的结构化数据,这对智能体(Agentic)工作流至关重要。
对开发者而言,实际意义在于:现在有五家独立的实验室提供能够胜任生产级编程工作负载的模型,它们不仅拥有开放权重或商用 API 接口,而且使用成本远低于那些私有替代方案。
打造最强开源编程大模型的实验室
DeepSeek:以编程为先的设计与 MoE 效率
DeepSeek AI 成立于 2023 年,由幻方量化(一家中国量化对冲基金)提供支持,从创立之初就将编程能力作为模型的核心。DeepSeek-Coder 是最早引起开源社区高度关注的专用代码生成模型之一。V3 和 V4 系列在保持强劲编程基准表现的同时,将能力拓展到了通用推理领域。
理解 MoE 架构对理解其定价至关重要。通过每个 Token 只激活一小部分参数,其单次请求的计算成本远低于同等质量的稠密模型。这种效率优势直接体现在 API 定价上,这正是 DeepSeek V4 Flash 能够以每千 Token 0.23 个积分的输入价格运行,且在处理简单任务时质量丝毫不减的原因。
Moonshot AI (Kimi)、Zhipu AI (GLM)、MiniMax 和 Alibaba (Qwen)
Moonshot AI(2023 年成立于北京)凭借长上下文推理能力确立了口碑。Kimi K2 系列具备 262K 的上下文窗口,专为文档密集型和代码密集型任务而设计,尤其适合在单次调用中处理大型代码库。
Zhipu AI(2019 年成立于北京,源自清华大学 KEG 实验室)是中国老牌 AI 公司之一。GLM 系列已迭代五代,每一代都在提升结构化输出的可靠性和指令遵循能力。GLM-5.1 体现了其在精准任务执行方面多年的对齐优化成果。
MiniMax(成立于 2021 年)从多模态领域跨入编程模型,推出了 M2 系列。MiniMax M2.5 和 M2.7 在成本与质量之间找到了极佳的平衡,精准填补了中端市场。
阿里巴巴 Qwen 团队基于其强大的编程模型谱系构建了 Qwen3.6-plus。该系列在多语言代码生成方面表现持续稳健,且 256K+ 的上下文窗口处于当前可选方案的第一梯队(QwenLM GitHub,2025)。
最强开源编程大模型对比:上下文、成本与规格
以下是按输入价格排序的当前模型完整对照表,以便直观了解成本结构:
| 模型 | 实验室 | 上下文 | 输入费率 | 输出费率 | 缓存写入 | 较官方优惠 |
|---|---|---|---|---|---|---|
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0.23 | 0.46 | 0.046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0.42 | 0.62 | 0.193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0.65 | 2.18 | 0.109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1.09 | 5.45 | 0.182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1.72 | 7.26 | 0.290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1.82 | 5.81 | 0.363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2.36 | 4.00 | 0.109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2.54 | 7.99 | 0.472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2.87 | 5.75 | 0.231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3.30 | 9.90 | 0.660 | -50% |
费率单位为每 1,000 Token 的积分数。“较官方优惠”指与该模型官方 API 直接定价相比的节省幅度。
几点观察:首先,同属一家实验室的 DeepSeek V4 Flash(输入 0.23)与 V4 Pro(输入 2.87),两者在同一模型家族中,最低端与最高端 tier 的成本差距竟达 12.5 倍。其次,Kimi K2.5 以 1.09 的输入价格提供了 262K 的上下文窗口,属于高性价比的中端选择,无需承担 V4 Pro 的高额开销。第三,Qwen3.6-plus 的输出费率达到 9.90,是该组中最高的,这暗示了其设计更倾向于生成更长、更详尽的代码补全。
各类中国开源编程大模型的最佳适用场景
这是本指南的实战部分。上述费率决定了你在执行智能体编程会话时的路由选择。
轻量级及后台任务:DeepSeek V4 Flash
适用于文档字符串(docstrings)、变量重命名、简单补全、格式转换以及编程智能体在后台自动调用的所有辅助请求。输入 0.23 和输出 0.46 的费率使其成为该组中性价比最高的选择。当 Claude Code 将后台任务路由至 Haiku 模型槽位时,切换到 DeepSeek V4 Flash 可在不影响主会话性能的情况下大幅降低背景噪音的开销。
兼顾成本与性能:DeepSeek V3.2 和 MiniMax M2.5
DeepSeek V3.2 在 160K 上下文窗口下以 55% 的官方折扣提供了 V3 架构的性能。对于希望获得稳健编程能力但又不想承担 V4 Pro 全价的开发者,V3.2 是务实的选择。MiniMax M2.5(输入 0.65)提供了类似的定位,并支持 200K 窗口,适合上下文需求大于极致成本优化的场景。
长上下文工作负载:Kimi K2.5 和 K2.6
两款 Kimi 模型均支持 262K 的上下文窗口。对于需要传入大型代码库、分析长会话记录或进行需要完整上下文的多文件重构任务,Kimi K2.5(输入 1.09)可以在不支付旗舰模型价格的前提下提供大窗口支持。K2.6(输入 1.72)则在上下文优势的基础上提升了性能,适合更注重质量的场景。
结构化输出与指令精准度:GLM-5 和 GLM-5.1
智谱 AI 的 GLM 模型在指令遵从性上表现卓越。对于需要可靠结构化输出的流水线(如特定的 JSON 模式、格式化的代码片段、一致的 API 响应格式),建议在这些任务上对比测试 GLM-5(1.82)和 GLM-5.1(2.54)。其较高的输出费率反映了它们更倾向于生成详尽、细致的输出。
旗舰级推理:DeepSeek V4 Pro 和 Qwen3.6-plus
对于复杂的架构决策、多系统交互调试,或是首轮生成质量至关重要(避免因初稿质量差导致昂贵的重试循环)的任务,V4 Pro 和 Qwen3.6-plus 是首选。V4 Pro 的 1M 上下文窗口是其核心卖点;Qwen3.6-plus 则在 DeepSeek 家族之外提供了 256K+ 的高端选项。
模型路由:最被低估的开源编程 LLM 策略
对于使用这些国产开源编程大模型的开发者而言,最高效的优化手段并非仅仅选择单一模型,而是根据会话中的任务类型将请求路由到不同层级的模型中。
考虑一个典型的智能体编程会话:制定方案(复杂,需要 V4 Pro)、编写核心算法(复杂,V4 Pro)、生成测试用例(中等负载,MiniMax M2.5 或 Kimi K2.5)、为新函数编写文档字符串(轻量级,V4 Flash)、运行文件读取观察(轻量级,V4 Flash)。如果你全程使用 V4 Pro,那么上述每一个辅助步骤的成本都比必要的多花费 12.5 倍。
计算结果非常直接。假设一次会话中 50 次 API 调用里有 60% 是简单任务(平均 2,000 输入 + 500 输出 Token)。若在 V4 Flash 上运行:
- 成本:30 次调用 × (2,000 × 0.23 + 500 × 0.46) = 30 × (460 + 230) = 20,700 积分
若全部在 V4 Pro 上运行:
- 成本:30 次调用 × (2,000 × 2.87 + 500 × 5.75) = 30 × (5,740 + 2,875) = 258,450 积分
仅这 30 次调用,差价就高达 12.5 倍。模型路由的效益显而易见。
如何为你的工作流选择最强的开源编程大模型
以下是适用于大多数开发者场景的决策树:
你需要最大化的单次请求上下文:DeepSeek V4 Pro (1M) 或 Qwen3.6-plus (256K+)。两者均能处理大型代码库输入,无需分块。
成本是首要限制:简单任务选择 DeepSeek V4 Flash,中等复杂度工作选择 DeepSeek V3.2 或 MiniMax M2.5。
你需要可靠的结构化输出:从 GLM-5.1 开始尝试,并根据你的具体模式要求进行验证。
你正在构建多步智能体流水线:按步骤复杂度进行路由。辅助步骤使用 Flash,中等推理步骤使用 Kimi K2.5 或 GLM-5,规划与调试步骤使用 V4 Pro。
你需要首选一个模型进行测试:DeepSeek V4 Pro 是开发者首次评估国产 LLM 的自然首选。它有详尽的文档、在 (r/LocalLLaMA) 上拥有广泛的社区支持,并提供旗舰级的编程质量。
现实中的难点:高效地在模型间路由需要它们都在同一个 API Key 和 Base URL 之下。维护十个独立的 API 账户是不现实的。这正是统一网关解决的问题:一个端点,一个密钥,模型选择仅作为一个参数。
在编程工具中运行最强开源编程大模型
Atlas Cloud Coding Plan 将本指南提到的所有十款模型集成在一个 API Key 和 Base URL 下,价格较官方 API 费率低 45-55%。各主流编程工具的设置方法如下。
Base URL 注意事项(避免调试困扰):Claude Code 使用 https://api.atlascloud.ai 且不带 /v1 后缀。所有其他工具(Codex, OpenClaw, OpenCode, Cursor)均使用带有 /v1 后缀的 https://api.atlascloud.ai/v1。此处弄错会导致认证错误,且不会直接指向原因。
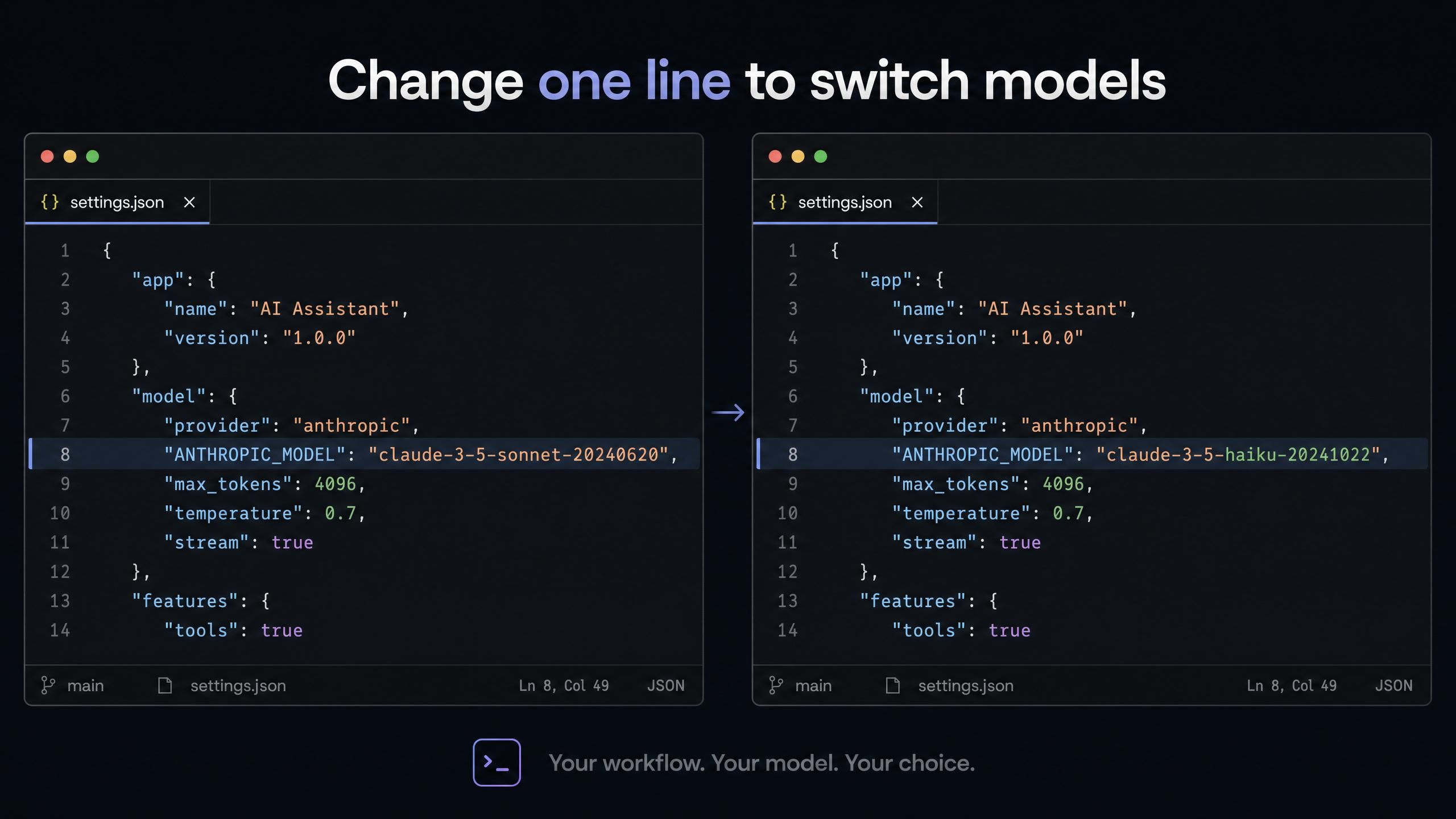
Claude Code (~/.claude/settings.json, macOS/Linux):
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
ANTHROPIC_DEFAULT_HAIKU_MODEL 字段映射到 Claude Code 的后台任务槽位。将其设置为 DeepSeek V4 Flash,意味着所有自动辅助调用(文件读取、状态检查、观察)都将使用性价比最高的模型,而主提示词使用 V4 Pro。无需任何路由逻辑,即可实现自动模型路由。
若要将 GLM-5.1 替换为 V4 Pro,只需将两个 Sonnet/main 字段中的 deepseek-ai/deepseek-v4-pro 修改为 zai-org/glm-5.1 即可。
Codex (~/.codex/config.toml + ~/.codex/auth.json):
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
OpenClaw:运行 openclaw onboard,选择 QuickStart,然后选择 Custom Provider。输入 https://api.atlascloud.ai/v1 作为 Base URL,粘贴密钥,然后输入模型 ID(如 moonshotai/kimi-k2.5)并选择 OpenAI 兼容协议。
在这些设置中切换模型仅需一行更改。无论选择哪个模型,API Key 和 Base URL 均保持不变。
最强开源编程大模型:常见问题解答
DeepSeek 真的是最强的开源编程大模型吗?
对于大多数初学者,基于社区普及度、基准测试表现以及 1M 上下文窗口与价格优势的结合,DeepSeek V4 Pro 是自然首选。但“最强”很大程度上取决于任务类型。对于长文本任务,Kimi K2.5 或 K2.6 在低费率下提供了 262K 上下文;对于结构化输出任务,GLM-5.1 值得测试。结论是,“最强”取决于你的具体开发场景。
这些模型在编程表现上与 Claude Sonnet 或 GPT-4o 相比如何?
在标准编程基准测试中,顶级开源模型与美国私有模型之间的差距自 2024 年以来已大幅缩小。DeepSeek V3 在发布时已在多个基准测试中与 Claude 3.5 Sonnet 持平。私有模型目前的优势仍在于更细腻的指令解释能力,以及那些得益于大规模 RLHF 调优的任务。对于绝大多数代码生成、重构和调试任务,开发者感受到的实际差异微乎其微。
我可以在同一个流水线中使用多个开源编程模型吗?
可以。当所有模型通过网关共享同一个 Base URL 和 API Key 时,你可以在每次请求中指定不同的模型 ID。这意味着你可以在一个自动化工作流中,针对不同步骤分别使用 DeepSeek V4 Flash、Kimi K2.5 和 V4 Pro,而无需管理多个账户或认证环境。
如果我从未用过开源 LLM,我该先尝试哪一个?
从 DeepSeek V4 Pro 开始。它拥有最丰富的文档、最广泛的社区讨论以及最明确的性能特征。一旦你在实际任务中建立了基准,就可以在上下文密集型步骤上测试 Kimi K2.5,在后台辅助调用上测试 DeepSeek V4 Flash。两者之间的成本差将直观展示模型路由是否适合你的工作流。
在企业环境中使用开源 LLM 是否安全?
这取决于你的部署模式。对于通过第三方网关进行的 API 访问,需遵循该网关的数据处理政策。而可自托管的开放权重模型让你对代码的流向拥有完全控制权。r/LocalLLaMA 社区对此已有深入讨论,共识是 API 的使用需遵循与任何第三方 API 相同的安全审计标准,无需将其视为特殊关注类别。
关于最强开源编程大模型的总结
目前已有五家实验室发布了能够胜任重要生产级编程任务的模型,它们在成本和能力范围内提供了足够广的选择空间。盲目使用单一模型选择方案会让你蒙受额外的成本损耗。
实战手册:选择一个能让你通过单一密钥访问所有模型的网关,以 DeepSeek V4 Pro 建立基准,然后利用上述路由指南将简单任务转移到更廉价的层级。对于大多数执行智能体编程会话的开发者而言,单靠这一项路由优化就能在不改变输出质量的前提下显著降低开销。
模型规格与费率参考截至 2026 年 5 月的 Atlas Cloud Coding Plan 文档。DeepSeek V3 基准数据来自 2024 年 12 月的 DeepSeek-V3 技术报告。费率可能会有所变动;在进行结算决策前,请务必与各服务商核对最新数据。






