
大多数开发者认为 Codex CLI 的工作方式像聊天机器人:你发送一条消息,模型回复,结束。事实并非如此。Codex 运行的是一个智能体循环(agent loop),这意味着每个任务都涉及多次 API 调用,且上下文窗口会随着每次迭代而不断扩大。当 Codex 完成一个中等复杂度的任务时,总 Token 数通常是你预期单次调用量的三到五倍。
这就是几乎所有“我达到了使用限制”案例背后的根本原因。你并不是在对抗某种速率限制策略,而是在应对智能体工作流的自然经济学,而这种经济效应会迅速累积。
一旦你理解了成本的真正来源,解决方案就会变得显而易见,而不是靠盲目猜测。
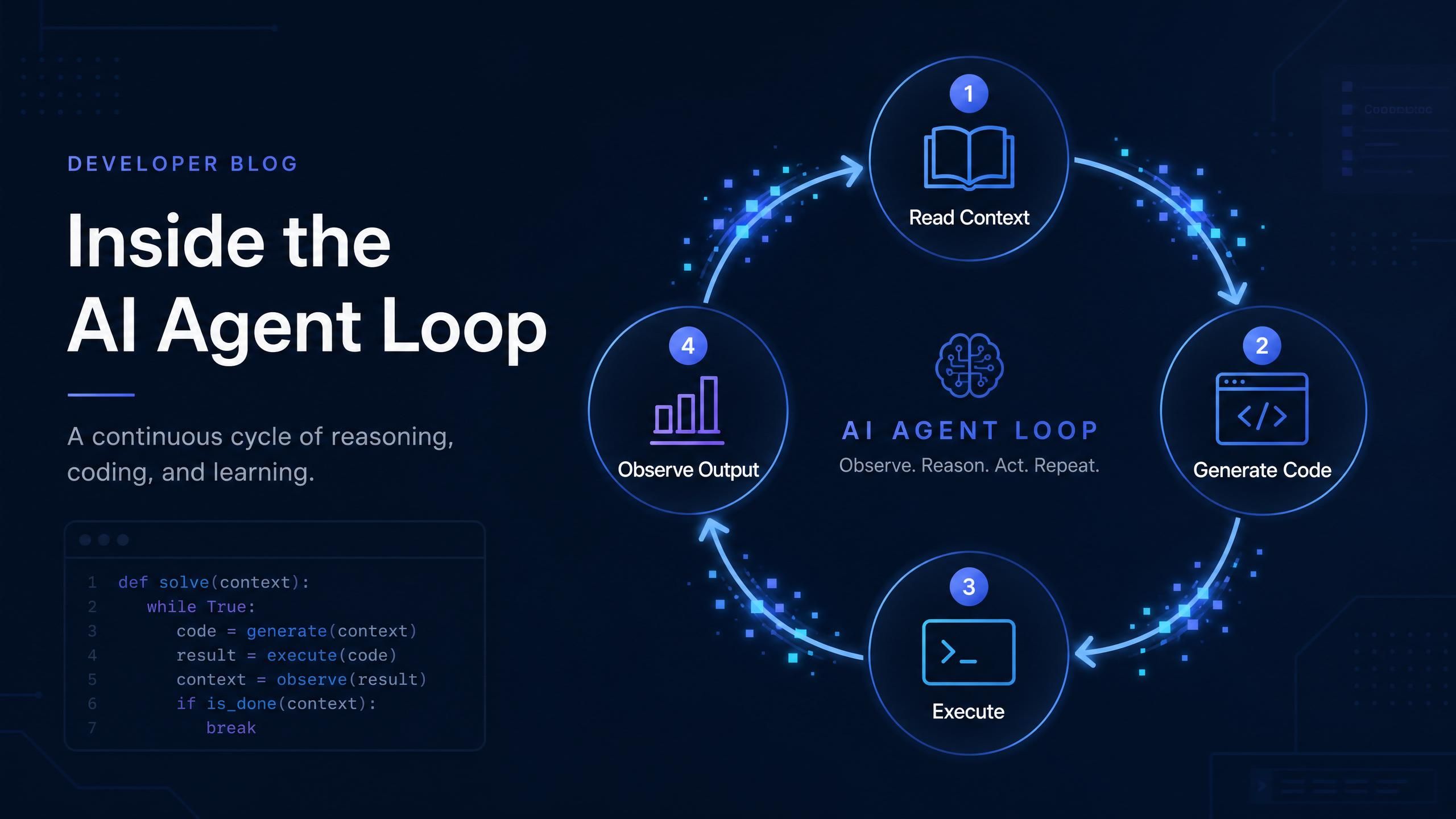
Codex CLI 在会话中是如何产生实际成本的
一个典型的 Codex 任务如果需要四次迭代,其成本并非单次调用的 4 倍,而是要高得多,因为上下文会随着每一步交互而增加。
以下是底层发生的情况:在第一次迭代中,Codex 会读取你的项目文件和任务描述,向模型发送大约 5,000 到 7,000 个输入 Token,并获取回复。在第二次迭代中,它会包含之前的对话历史以及运行生成代码后获得的新观察结果。该次调用的输入 Token 数可能会跃升至 8,000 或 10,000。到第四次迭代时,累积的上下文可能已达到 14,000 个输入 Token,而这在概念上仍是同一个任务。
Codex 4 次迭代任务中的上下文增长
| 迭代次数 | 输入 Token 数 |
|---|---|
| 迭代 1 | ~5,000 |
| 迭代 2 | ~7,000 |
| 迭代 3 | ~9,500 |
| 迭代 4 | ~14,000 |
| 总计 | ~35,500 |
在智能体交互过程中,上下文大小会随着迭代累积。一个 4 次迭代的任务可能消耗 35,500 个总输入 Token,而单次调用仅消耗 5,000 个。具体数值因项目规模和文件上下文而异。
实际影响是:四次迭代的任务成本并不是单次调用成本的 4 倍。由于上下文不断增加,其成本接近 7 倍或 8 倍。在此示例中,整个任务大约消耗 35,500 个输入 Token 和 4,000 个输出 Token。你选择的模型决定了该任务是花费 9,000 积分还是 120,000 积分,尽管是在同一个 Codex CLI 上且使用相同的任务描述。
这 13 倍的差额正是解决 Codex 使用限制的关键所在:不在于请求限流,而在于选择哪个模型来运行这个循环。
Codex 使用限制的解决方案:首先进行文件范围界定(File Scoping)
这是一种无需成本且能产生最直接效果的优化手段。
在进行任何 API 调用之前,Codex 会读取你的项目文件以构建上下文。虽然它会遵循你的 .gitignore,但大多数代码库中仍有大量 .gitignore 无法排除的内容:类型声明文件、供应商文档、编译输出目录、测试夹具、种子数据、生成的 CSS 或 SVG。所有这些都会进入第一次迭代的上下文窗口,并增加后续每次调用的基础成本。
解决方法是进行有意识的排除。在你的项目根目录下添加一个 .codexignore 文件,语法与 .gitignore 相同。建议添加的常见模式:
plaintext1dist/ 2.next/ 3build/ 4node_modules/ # 以防 .gitignore 有遗漏 5*.d.ts # TypeScript 声明文件 6*.min.js 7*.min.css 8test/fixtures/ 9test/snapshots/ 10docs/vendor/
或者,当任务仅针对特定模块时,从该目录内部运行 Codex,而不是从项目根目录运行。智能体从其工作目录读取文件,因此 cd packages/auth && codex 会话只会看到该包的文件,而不是整个 monorepo。
开发者在 r/LocalLLaMA 上讨论时一致表示,不受控制的文件上下文是导致智能体工具出现意外 API 消耗的主要原因。在触碰任何其他设置之前先做好这一步,通常可以将中等规模项目的单次会话 Token 数减少 30% 到 60%。
在多包项目中,从相关包的子目录运行 Codex 而非 monorepo 根目录,将第一次调用的单任务上下文从 ~18,000 个 Token 降低到了 ~5,000 个。这种差异会在每一次迭代中累积。
改变长期成本计算的 Codex 使用限制解决方案
在缩减文件上下文后,下一个结构性优化方案是你所运行的模型。
Codex CLI 通过其 config.toml 支持自定义 API 提供商。任何实现了 OpenAI 聊天补全格式的提供商都可以作为直接替代方案。这意味着你可以运行完全相同的 Codex CLI 工作流,但由不同成本的模型驱动。
为什么这很重要?因为积分乘数(或每 Token 费率)会乘以每次迭代中的每一个 Token。对于一个消耗 35,500 个输入 Token 和 4,000 个输出 Token 的 4 次迭代任务,从高乘数模型切换到低乘数模型绝非小打小闹。对于同一个任务,这直接决定了是消耗 9,545 积分还是 119,145 积分。
Atlas Cloud 的 Coding Plan 提供了一套开源模型,价格比官方 API 费率低 45% 到 55%,所有这些模型都可以通过单个 API 密钥在兼容 OpenAI 的端点上访问。你只需将 Codex 指向 https://api.atlascloud.ai/v1,设置你的模型 ID,工作流中的其他任何内容都不需要改变。
解读乘数:哪种 Codex 使用限制解决方案适合每个任务
以下是使模型选择具体化的数学依据。使用我们的 4 次迭代任务(总计 35,500 个输入 Token,4,000 个输出 Token),以下是各可用模型的每任务积分成本:
各模型每 4 次迭代 Codex 任务的积分成本
| 模型 | 积分 / 任务 | vs. 最便宜 |
|---|---|---|
| deepseek-v4-flash | 9,545 | 🟢 基准 |
| deepseek-v3.2 | 17,390 | 1.8x |
| minimax-m2.5 | 31,845 | 3.3x |
| kimi-k2.5 | 60,695 | 6.4x |
| deepseek-v4-pro | 119,145 | 12.5x |
| glm-5.1 | 122,025 | 12.8x |
来源:根据 2026 年 6 月公布的 Atlas Cloud 乘数计算。对于任一模型都能完成的任务,DeepSeek V4-Flash 每任务成本比 DeepSeek V4-Pro 便宜 12.5 倍。
通过 Starter 计划($10/月,每天 800,000 积分),你可以运行:
- DeepSeek V4-Flash: 800,000 / 9,545 = 每天 83 个四次迭代的任务
- DeepSeek V4-Pro: 800,000 / 119,145 = 每天 6.7 个任务
使用 Lite 计划($20/月,根据当前层级配置每天 220 万积分):
- DeepSeek V4-Flash: 2,200,000 / 9,545 = 每天 230 个任务
- DeepSeek V4-Pro: 2,200,000 / 119,145 = 每天 18 个任务
实践框架是这样的:DeepSeek V4-Flash 可以很好地处理绝大多数 Codex 任务。编写工具函数、生成测试、修复 Lint 错误、重命名变量、构建样板代码——这些都不需要前沿的推理能力。V4-Flash 支持 100 万 Token 的上下文窗口,且能胜任这些任务。V4-Pro 和 Kimi K2 则值得用于真正困难的问题:复杂的多文件重构、调试模糊的生产环境问题、使用不熟悉的框架。
为合适的任务使用合适的模型并不是在质量上妥协,而是避免“杀鸡用牛刀”。
V4-Flash 和 V4-Pro 之间的差异不仅仅是“廉价与高质量”的区别。在常规 Codex 任务中,质量差异微乎其微,但成本差异高达 12.5 倍。在文件范围界定之后,将 V4-Pro 保留给真正复杂的会话是最高效的优化手段。
通过会话边界(Session Boundaries)优化 Codex 使用限制
还有一个行为习惯可以让你在一周内获得显著收益:谨慎决定何时开始新的 Codex 会话,何时继续现有的会话。
每个会话都会积累对话历史。会话持续时间越长,后续每次调用的基础上下文就越大。一个从 5,000 Token 第一次迭代开始并运行了六次交换的会话,结束时上下文可能已达 18,000 Token。如果你在同一个会话中转向一个全新的、不相关的任务,你现在是在为每次新的调用都包含所有无关的先验上下文付费。
开启新会话无需成本。Codex 会清空并仅读取与你当前工作目录相关的文件。经验法则如下:
- 任务干净地完成了,下一个任务是独立的?开启新会话。
- 从一个模块转向另一个没有共享代码的模块?开启新会话。
- 继续在同一个文件上进行迭代,目标相同?保持现有会话。
- 从实现阶段转向文档编写阶段?开启新会话。
这不像文件范围界定或模型选择那样效果剧烈,但在整个工作周内,特别是在高强度的开发冲刺期间,它会积累出可观的节省。
Codex 使用限制解决方案:每日重置积分的实际运作方式
理解计费模型有助于你现实地规划使用量。
标准的 API 积分池每月为你提供 X 个 Token,你可以随意支配。结构性问题在于:编码繁忙的日子会迅速耗尽积分池,导致当月剩余时间里的可用额度比预期的要少。如果你在两天的密集冲刺中用掉了 40% 的月预算,接下来的三周你都将在预算赤字中挣扎。
“每日重置”模型则不同。你每天获得固定数量的积分,无论前一天用了多少,积分都会在午夜刷新。周二的轻度使用不会惩罚周四的重度使用。每一天都以完整的每日预算开始。
各计划层级的每日积分分配
所有层级均在午夜重置 · 按量付费包可作为溢出额度叠加使用
| 计划 | 价格 | 每日积分 |
|---|---|---|
| Starter | $10 / 月 | 800K / 天 |
| Lite | $20 / 月 | 2.2M / 天 |
| Plus | $50 / 月 | 4.8M / 天 |
| Max | $100 / 月 | 9.8M / 天 |
来源:Atlas Cloud Coding Plan,2026 年 6 月 · 未使用的积分不会结转,但你永远不会因为之前的高负载会话而在新的一天开始时就面临预算耗尽的问题。
当你在一次特别紧张的会话中耗尽了每日积分时,按量付费的补充包会自动填补缺口。这些补充包自购买之日起 90 天内有效,你可以同时叠加多个补充包,且仅在订阅的每日积分耗尽后才会开始消耗补充包。订阅涵盖你的基础需求,补充包覆盖溢出部分。
如果你在周期中途改变主意,升级层级是按比例折算的。公式很简单:(新价格 - 当前价格) × (剩余天数 / 30)。如果还有 14 天到期,从 Starter 升级到 Lite 的费用为 ($20 - $10) × (14 / 30) = $4.67。一旦升级,更高的每日积分限额立即生效。
配置 Codex 使用限制解决方案:完整配置
将 Codex CLI 指向自定义提供商只需两个文件。在 macOS 或 Linux 上:
第一步: 创建或编辑 ~/.codex/config.toml
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-flash" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
第二步: 创建或编辑 ~/.codex/auth.json
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
requires_openai_auth = true 标志告诉 Codex 从 auth.json 中的 OPENAI_API_KEY 字段读取 API 密钥。你的 API 密钥是在购买 Coding Plan 后,从 Atlas Cloud 的计划管理仪表板中获得的。
要为特定会话切换模型,请更改 config.toml 中的 model 行。如果你想在复杂任务中使用更强大的模型,请切换到 deepseek-ai/deepseek-v4-pro 或 moonshotai/kimi-k2.6,完成后切换回轻量模型。只需修改一行。
配置完成后,像往常一样启动 Codex:
plaintext1codex
选择跳过更新检查的选项,你就可以使用 Atlas Cloud 的模型运行 Codex 了。界面和命令与默认的 Codex 体验完全相同。
关于 Codex 使用限制解决方案的常见问题解答
为什么 Codex 每个任务消耗的 Token 比我预期的多?
Codex 运行的是智能体循环,而不是单次 API 调用。每次迭代都包含累积的对话历史以及来自代码执行的新观察结果。在四次迭代的任务中,第四次迭代时的上下文窗口可能是第一次的两倍。所有迭代的总 Token 消耗通常是单次调用成本的三到五倍。
对于刚起步的开发者,什么是最好的 Codex 使用限制解决方案?
从文件范围界定开始:添加一个 .codexignore 文件,排除 dist/、build/、*.d.ts 文件、测试夹具和其他非必需内容。这是免费的,通常在中等规模项目中可减少 30% 到 60% 的上下文大小。完成此操作后,下一个最具影响力的改变是针对常规任务切换到像 DeepSeek V4-Flash 这样的低乘数模型,与使用重型模型相比,这可以将单任务积分消耗降低多达 12 倍。
我可以在 Windows 上使用 Atlas Cloud 运行 Codex 吗?
是的。在 Windows 上,将配置文件放置在 %USERPROFILE%\\.codex\config.toml 和 %USERPROFILE%\\.codex\auth.json。文件格式和字段名称与 macOS/Linux 版本完全相同。基础 URL、API 密钥和模型 ID 在所有平台上均可通用。
当我的每日积分额度用完时会发生什么?
如果你激活了按量付费的积分包,一旦每日订阅积分耗尽,系统会自动从这些积分包中扣除额度以确保持续使用。如果没有积分包,在午夜每日积分刷新之前,进一步的请求将被拒绝。你可以随时从计划仪表板购买补充包;它们会立即激活,有效期为 90 天。
将 Codex 指向自定义提供商后,我需要更改工作流吗?
不需要。Codex CLI 的命令、标志和行为无论后端提供商是谁都是完全相同的。唯一可见的区别是响应你任务的模型。如果你配置了一个 Codex 本身未预训练的模型,其响应风格可能会有轻微不同,但工具的操作方式保持不变。大多数开发者在初次配置更改后都不会感觉到工作流的任何中断。
总结
本文的核心见解是:Codex CLI 的成本并非不可预知。它们来自一个明确的地方:在迭代中增长的上下文,乘以模型收取的每 Token 费率。一旦你清晰地认识到这一点,干预措施就变得机械化了:
- 通过文件范围界定减少 Codex 的读取内容(免费,效果显著)
- 将模型匹配到任务复杂度(每任务成本差异可达 12 倍)
- 在任务独立时开启新的会话(防止上下文臃肿累积)
- 使用“每日重置”的积分计划,以避免月中预算耗尽的问题
任何一个方案都有帮助。四者结合,使 Codex 在日常重度使用中能够持续稳定,既不会触及限制,也不会眼睁睁看着 API 账单不可控地攀升。
如果你想尝试自定义提供商方案,Atlas Cloud Coding Plan 支持 Codex,同时也支持 Claude Code、OpenCode、Cursor 以及直接 API 调用。每月 10 美元的 Starter 层级提供每日 80 万积分,是一个合理的起点;如果你需要更多额度,可以在周期中途按比例升级。
在不同的 Codex 任务类型之间选择 DeepSeek V4-Flash 和 V4-Pro → 智能体编码工作流的模型选择指南






