
如果您正在评估用于代码编写、逻辑推理或智能体(agentic)流程的开源模型,Kimi K2.6 和 GLM 5.1 都会出现在您的备选名单中。这两款模型均来自中国顶尖的 AI 实验室,支持 OpenAI 兼容 API,并且在开发者真正关心的复杂任务上表现出色。
问题在于它们并非完全可替代。它们拥有不同的上下文窗口、成本结构以及在特定应用场景下的不同优势。如果为工作负载选择了错误的模型,要么会浪费性能,要么会为不需要的算力支付额外费用。
本文深入剖析了两款模型的真实差异:规格参数在实际应用中的含义、各自的优劣势,以及当您大规模运行这些模型时,成本表现如何。

Kimi K2.6 与 GLM 5.1:快速总结
Kimi K2.6 是月之暗面(Moonshot AI)K2 系列中的最新型号,也是其目前的旗舰产品线。月之暗面是 Kimi 智能助手的开发商,K2.6 代表了其在长上下文推理和极具竞争力的定价上的尝试,262K 的上下文窗口是其主打特色之一。
GLM 5.1 来自智谱 AI,这是中国最成熟的 AI 研究机构之一。GLM(通用语言模型)系列已历经数代演进,5.1 是智谱目前的主力型号。它在开源社区中以指令遵循的精准度和结构化输出质量而享有盛誉。
两款模型均提供 OpenAI 兼容的 API,这意味着将它们连接到 Claude Code、Codex 或 OpenClaw 等工具非常简单。在两者之间做出选择主要取决于三个实际因素:单次请求所需的上下文大小、预期使用量下的 Token 成本,以及您的任务是否契合某款模型的相对优势。
模型简介
上下文窗口对比
上下文窗口是两者最直观、最客观的区别。Kimi K2.6 支持 262K Token 的上下文窗口,而 GLM 5.1 支持 200K。这意味着最大输入容量有 31% 的差距。
对于典型的编码任务,两者在日常使用中都不会触及上限。常规的代码审查、调试会话或文档生成请求,在两者的窗口范围内都绰绰有余。只有在特定场景下,这一差距才具有意义:
- 大型代码库分析:单次请求传入数万行代码进行重构或架构审查。
- 长会话智能体:在多轮对话和工具调用中积累了大量上下文的交互。
- 文档密集型流程:需要单次调用处理大量文本的研究、总结或分析任务。
如果您的工作负载经常接近其他模型的上下文极限,Kimi K2.6 的 262K 窗口能为您提供更多的操作空间,无需过早实施分块或上下文摘要逻辑。如果您的常规请求在 50K Token 以下,那么两款模型都能提供充足的容量,窗口差异将不再是决策的关键因素。

代码编写与逻辑推理优势
两款模型在代码任务上都很出色,但不同的设计优先级导致了实际表现的差异。
Kimi K2.6 专为长上下文理解而构建。这使得它非常适合多文件重构、理解代码库某一部分的更改如何影响其他部分,以及在模型需要在多步骤中保持大量状态的扩展推理链中表现卓越。Moonshot AI 正是围绕这些应用场景对 K2.6 进行了定位。
GLM 5.1 则体现了智谱 AI 对精确指令遵循和结构化输出的关注。在根据详细规格生成代码、将自然语言转换为结构化格式或管理复杂的工具调用架构等任务中,它表现更优。其定价中略高的输出单价(7.99 vs 7.26)也暗示了该模型倾向于提供更详尽、严谨的补全结果。
对于大多数比较这两款模型的开发者来说,在典型代码任务上的性能差距比品牌印象中要小。更明显的差异在于规格和成本,这些数据是具体且可量化的。
Kimi K2.6 与 GLM 5.1:Token 成本与点数费率
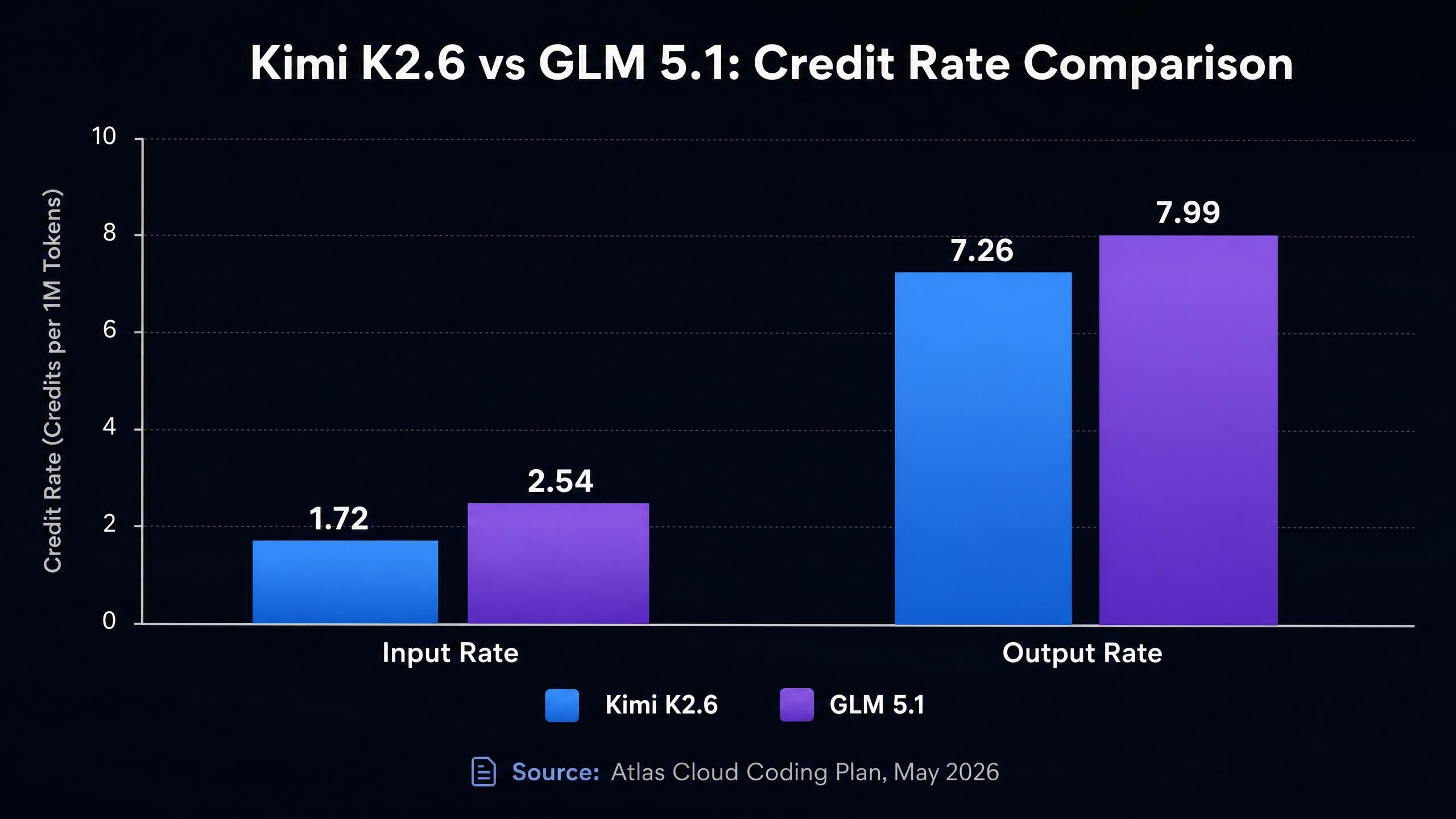
这是对比中最具体的部分。两款模型均可通过 Atlas Cloud Coding Plan 使用,其点数费率如下(Atlas Cloud Coding Plan,2026 年 5 月):
| 模型 | 上下文 | 输入费率 | 输出费率 | 缓存写入 | vs. 官方价格 |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 便宜 45% |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 便宜 45% |
几点值得注意:
GLM 5.1 的输入费率(2.54)比 Kimi K2.6(1.72)高出约 48%。在需要传入文件内容、大量代码历史记录或长对话积累的编码场景中,输入 Token 往往占成本的大头。一个每天运行 1,000 次请求、每次 10K 输入 Token 的工作流,仅在输入成本上,使用 GLM 5.1 就会比 Kimi K2.6 贵约 48%。
输出费率差距较小,但也倾向于 Kimi K2.6(7.26 vs 7.99,约 10% 的差距)。缓存写入费率同样是 Kimi K2.6 占优(0.290 vs 0.472),这在频繁使用提示词缓存处理系统提示或静态上下文的工作流中积少成多。
综合计算:对于一个包含 5,000 输入 Token 和 1,000 输出 Token 的请求,点数消耗如下:
- Kimi K2.6:(5,000 × 1.72) + (1,000 × 7.26) = 8,600 + 7,260 = 15,860 点数
- GLM 5.1:(5,000 × 2.54) + (1,000 × 7.99) = 12,700 + 7,990 = 20,690 点数
按此输入输出比计算,Kimi K2.6 单次请求便宜约 23%。在大规模使用时,这会转化为可观的预算差异。
通过网关使用时,两款模型的价格均比官方 API 价格低 45%,在该模型层级中保持一致。
Kimi K2.6 与 GLM 5.1 在智能体编码工作流中的表现
智能体(Agentic)工具放大了模型在成本和能力上的每一个差异。
在多步编码智能体中,每一次工具调用都是一个独立的 API 请求。每个请求都承载着来自累积对话的输入上下文,生成输出并馈入下一步,从而增加总算力账单。一个会话中运行 40 次 API 调用的工作流,不仅是单次请求价格的 40 倍,随着会话深入,它会快速积累上下文,导致后续请求的输入 Token 数不断增加。
Kimi K2.6 在智能体中的优势:适用于需要累积大量上下文的长会话、涉及阅读和修改大型代码文件的任务,以及在多次调用中保持成本合理的工作流。更大的上下文窗口意味着更少的会话重置,从而更少地干扰智能体的工作记忆。
GLM 5.1 在智能体中的优势:适用于每一步都需要精确、结构化输出,且单次调用指令准确性比会话上下文深度更重要的流程。如果您的智能体需要根据严格的类型模式生成代码、管理复杂的函数签名,或在每一轮交互中输出一致的格式,GLM 5.1 的指令遵循优势将更直接地发挥作用。
两款模型都可以通过标准的 OpenAI 兼容配置,与 Claude Code、Codex、OpenClaw 和 Cursor 无缝协作。集成方式完全相同,只需更改模型 ID。
如何运行并选择适合您的模型
Kimi K2.6 vs GLM 5.1:如何科学决策
决定选用哪款模型的最可靠方法不是阅读对比文章,而是将它们放在实际任务中运行并自行比较输出质量。好消息是,当两款模型位于同一个 API Key 和基础 URL 之后时,这变得非常简单。
Atlas Cloud Coding Plan 将 Kimi K2.6 和 GLM 5.1 整合在同一个端点下。切换模型只需修改一行配置,这意味着您可以无需重新构建集成,直接对比两款模型在真实工作负载下的表现。
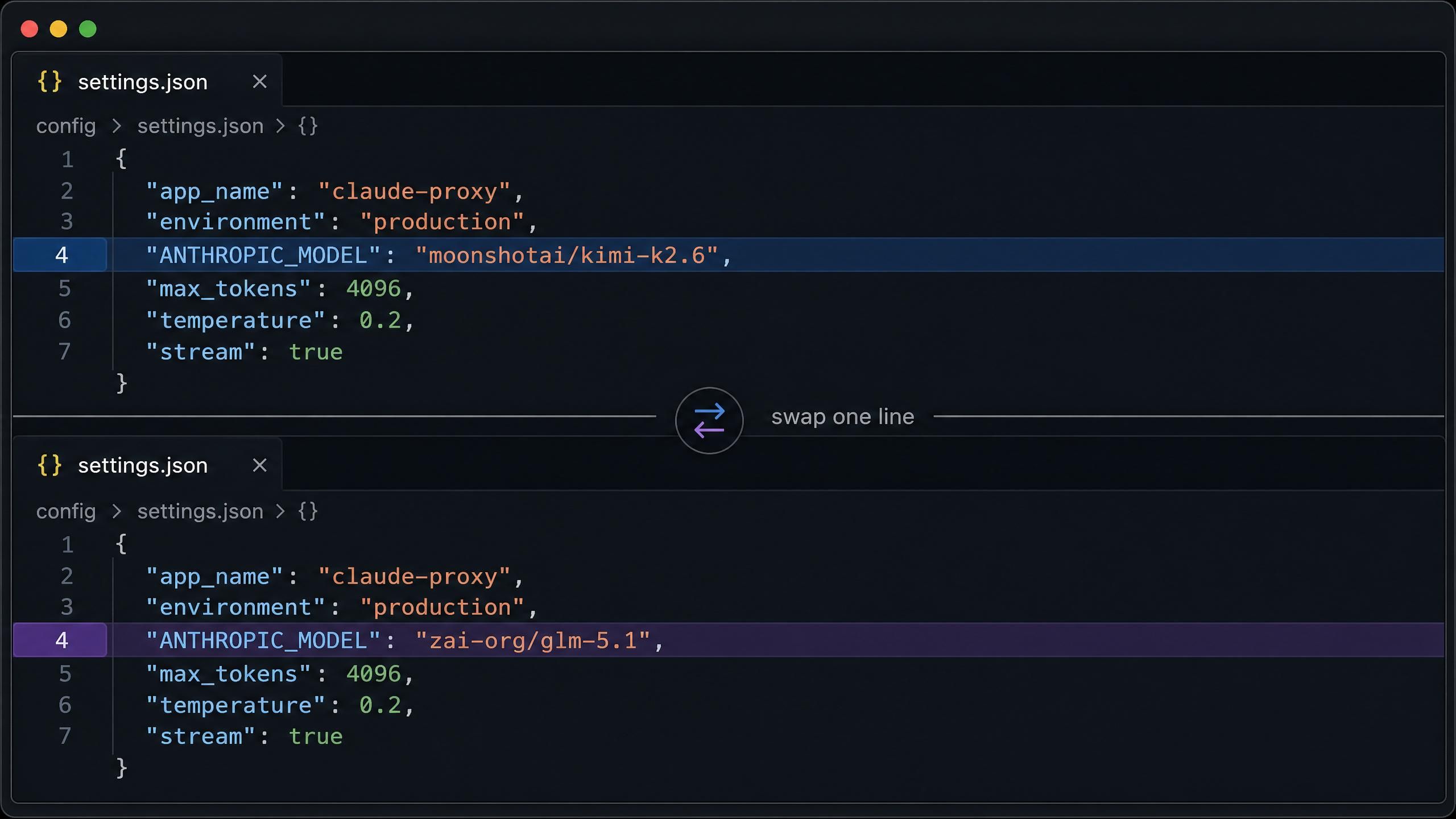
对于 macOS 或 Linux 上的 Claude Code,完整配置放在 ~/.claude/settings.json 中。首先设置为 Kimi K2.6:
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
若要切换到 GLM 5.1,只需将三个模型字段中的 moonshotai/kimi-k2.6 改为 zai-org/glm-5.1 即可。其他配置保持不变。请注意,Claude Code 的基础 URL 为 https://api.atlascloud.ai,不含 /v1 后缀。
对于 Codex,配置分为两个文件。~/.codex/config.toml:
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json:
plaintext1{ 2 "OPENAI_API_KEY": "your-atlas-api-key" 3}
对于 OpenClaw,运行 openclaw onboard,选择 QuickStart,然后选择 Custom Provider。输入 https://api.atlascloud.ai/v1 作为基础 URL,粘贴您的 Atlas Key,然后选择您想测试的模型 ID。
Atlas Cloud 方案提供两种形式:按月订阅并每日刷新点数(适合稳定日常使用),以及带有 90 天有效期的按量付费包(更适合波动或实验性工作负载)。由于您可能需要测试两款模型,按量付费选项提供了无需承诺月度用量的灵活性。
常见问题解答
哪款模型大规模运行成本更低?
Kimi K2.6 在输入和输出 Token 上都更便宜。输入费率的差距最大(GLM 5.1 的输入费率高出约 48%),这对发送大量上下文的编码工作流影响最为显著。在大规模请求下,这会转化为可观的预算差异。
哪款模型处理中文任务更好?
两款模型都具备强大的中文语言能力,这符合它们的背景。智谱 AI 的 GLM 5.1 历经多代演进,在中文任务上有着特别深厚的积累。Kimi K2.6 由于 Moonshot AI 的产品重点面向中国用户,同样处理得很好。对于以中文为主的任务,两者表现都很稳健,GLM 5.1 基于过往表现略有优势。
可以在同一个流程中混合使用这两款模型吗?
可以。通过统一网关,您可以在同一个流程中通过更改每一步的 model 参数,将不同步骤路由到不同的模型。您可以将 Kimi K2.6 用于上下文密集型的分析步骤(更低的输入成本,更大的窗口),并将 GLM 5.1 用于结构化输出生成步骤(更强的指令遵循),所有这些都使用同一个 API Key。
262K 和 200K 上下文的区别值得关注吗?
对于大多数日常编码任务,没必要。两者的窗口都足够大,可以满足典型请求。当您的会话经常积累 150-200K Token、需要传入大型代码文件进行分析,或者需要进行不重置的长会话智能体交互时,这个差异才会有意义。如果您的请求极少达到 50K Token,它就不是决定性因素。
这些模型需要特殊配置才能与 Claude Code 一起使用吗?
无需除上述所示之外的特殊配置。Claude Code 会读取其模型设置,只要您将其指向支持 OpenAI 兼容格式的网关,即可顺利连接。唯一需要注意的就是 Claude Code 特有的基础 URL 格式:它使用 https://api.atlascloud.ai 而不加 /v1,这与大多数其他工具不同。
最终结论:Kimi K2.6 vs GLM 5.1
这两款模型之间与其说有一个明确的赢家,不如说是一个 workload(工作负载)契合度的问题。
Kimi K2.6 是更具成本效益的默认选择。它的单 Token 价格更低,单次请求处理上下文的能力更强,非常适合编码智能体生成的那些大型输入、长上下文任务。如果您在优化大规模成本,或经常处理大型代码库,它在数据表现上是更强的选择。
GLM 5.1 的价格略高,但在需要精确指令遵循和一致结构化输出的任务中表现更胜一筹。如果您的工作流上下文负担不重,但对每一步输出的精度要求较高,那么它非常值得针对您的特定任务进行测试。
实用建议:从 Kimi K2.6 开始以享受成本优势和更大的上下文窗口,并在实际工作负载中试运行;如果您对结构化输出质量有疑问,再在相同任务上对比 GLM 5.1。通过 Atlas Cloud Coding Plan,两款模型均位于同一 API Key 下,且享受 45% 的官方价格折扣,测试成本极低,完全可以让实际表现来主导您的决策。
模型规格和点数费率基于 2026 年 5 月的 Atlas Cloud Coding Plan 文档。模型能力反映了来自月之暗面 (Moonshot AI) 和智谱 AI (Zhipu AI) 的公开信息。费率如有变动,请直接与各服务商核实。






