Google Gemini Omni 是 Google DeepMind 于 2026 年 5 月 19 日在 Google I/O 大会上推出的一款多合一 AI 模型。其最大的里程碑在于原生多模态(Native Multimodality)。这意味着它可以在同一个系统中处理并生成文本、图像、音频和视频,无需连接不同的工具。它专为创作者、开发人员和企业设计,旨在通过简单的对话实现视频的制作与编辑,无需在不同应用间切换。
Gemini Omni 功能概览的核心理念是:根据任何输入内容创作一切。 与独立的文本生成视频(text-to-video)AI 工具不同,Omni 将 Gemini 的推理能力与先进的媒体渲染技术结合在了一次处理流程中。
核心能力概览
| 功能 | 详情 |
|---|---|
| 支持输入 | 文本、图像、音频、视频 |
| 主要输出 | 视频(图像和音频即将推出) |
| 编辑风格 | 对话式、多轮提示(multi-turn prompts) |
| 首发模型 | Gemini Omni Flash |
| 可用性 | Google AI Plus、Pro 及 Ultra 订阅用户 |
访问方式
- Gemini App — 全球 AI Plus/Pro/Ultra 订阅用户
- Google Flow — 完整的短片制作工作流
- YouTube Shorts / YouTube Create — 短视频创作
- 开发者 API — 数周内推出
什么是 Google Gemini Omni 及其工作原理?
Google Gemini Omni 是 AI 领域的一次重大飞跃。作为 Google DeepMind 旗下的核心多合一创意 AI 模型,它在 2026 年 Google I/O 大会上亮相,能够同时处理文本、图像、声音和视频,从而制作出高质量的视频内容。它正式在 Gemini 生态系统中接管了 Veo 的地位。
核心引擎:原生多模态详解
大多数早期的 AI 视频工具遵循线性的处理流程:先将输入内容转换为文本描述,再将这些描述传递给独立的视频渲染器。而 Gemini Omni 的工作方式截然不同。它构建于原生多模态模型之上,能够在一个核心引擎内同时处理所有媒体类型,而非将其拆分为孤立的步骤。
这至关重要,因为省略了转换层意味着模型能保留更丰富的上下文信息。当您在输入文本提示词的同时提供参考照片时,Omni 会同时对两者进行推理,从而保留了文本转换步骤通常会丢失的视觉细节。
Gemini Omni 多模态输入的实际应用
Gemini Omni 多模态输入支持在单个提示词中组合使用以下内容:
| 输入类型 | 应用示例 |
|---|---|
| 仅文本 | 从头开始描述一个场景 |
| 图像 + 文本 | 根据文字指令为静态照片制作动画 |
| 视频 + 文本 | 通过对话编辑现有剪辑 |
| 音频 + 文本 | 在视觉提示的同时指导视频基调 |
| 混合(四种皆有) | 结合参考剪辑、风格图像和旁白 |
实时处理与对话式控制
由于推理过程发生在同一个模型内部,对编辑指令进行实时处理变得非常实用。Omni 通过多轮对话精炼输出内容——您只需描述修改需求,即可更换背景、调整光影或稳定画面,无需从零开始重新输入提示词。
Google DeepMind 的 Nicole Brichtova 将其描述为“不仅仅是 Veo 的更新”,而是 Gemini 的推理能力与媒体渲染技术融合为一体的连贯系统。
对话式视频编辑 AI:如何利用 Gemini Omni 进行高级资产修改
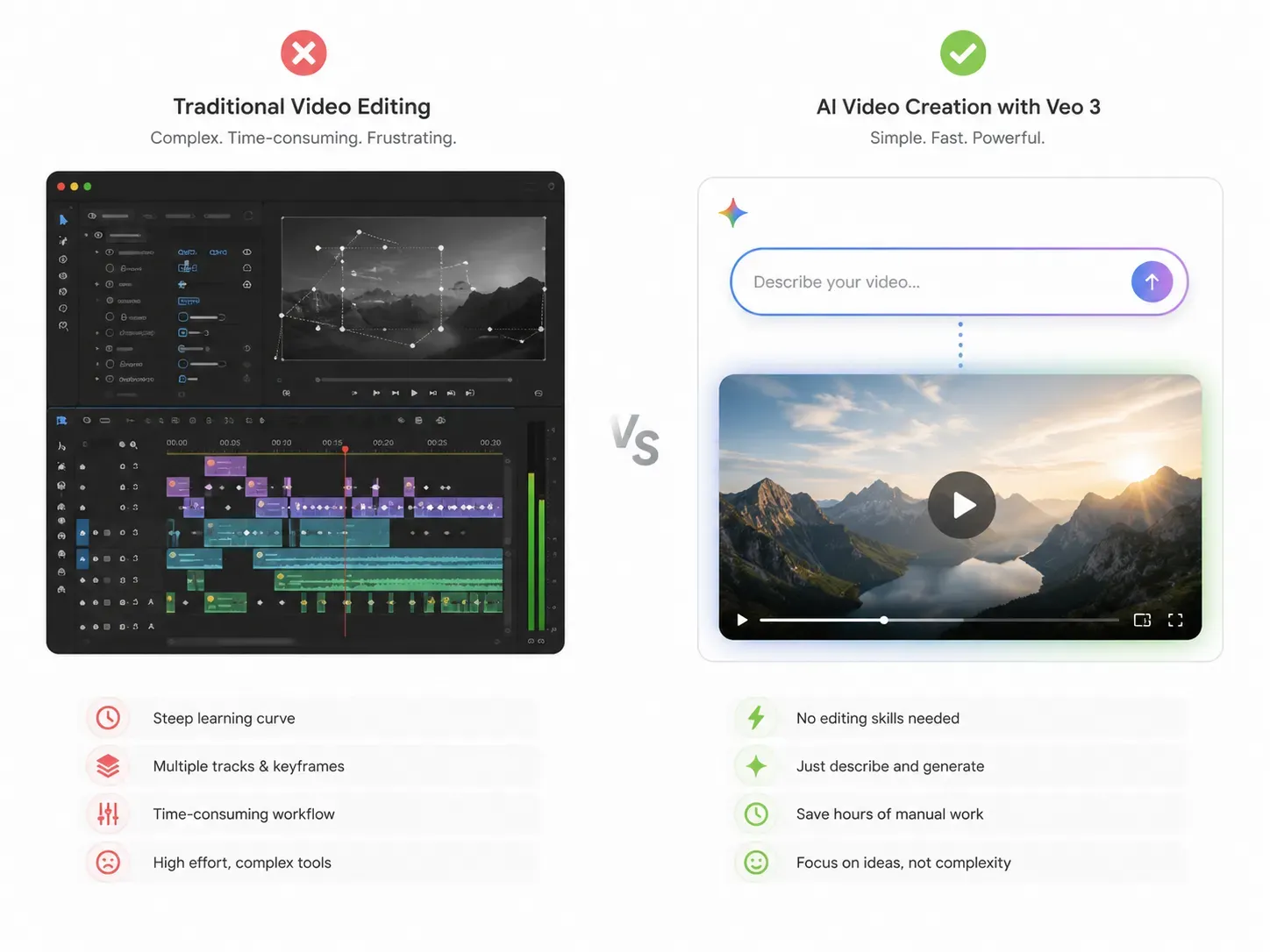
理解架构是一回事,应用它是另一回事。这正是 Gemini Omni 的对话式视频编辑 AI 功能区别于传统工具的关键所在。
传统的视频编辑器需要处理时间轴、图层和手动关键帧。Gemini Omni 完全取代了这种工作流。只需上传您的素材,通过打字或语音表达修改需求,模型便会自动重新渲染剪辑。无需插件,无需外部软件。
Gemini Omni 能处理复杂的 AI 视频元素替换吗?
可以,而且这是它最实用的功能之一。根据 Google 的官方文档,支持的视频资产修改任务包括:
- 背景替换 — 在保留主体的同时替换其背后的环境
- 服装与风格转换 — 修改服装,或将某种视觉风格应用到整个剪辑中
- 对象替换 — 在镜头中途替换特定物品
- 光影调整 — 通过单一指令改变场景的光照氛围或强度
- 视频防抖 — 通过自然语言提示平滑抖动的画面
- 主体替换 — 使用参考图像将一个对象替换为另一个
通过多轮对话实现交互式视频编辑
使之成为交互式视频编辑而非一次性生成的原因在于多轮对话机制。每一条编辑指令都建立在上一条的基础上,因此模型能够保持场景的一致性——在后续的优化轮次中,背景、光影逻辑和人物特征始终保持统一。
例如,创作者可以先指令:“将背景换成城市街道”,接着说:“让光线变得更暖”,最后说:“稳定画面”——所有操作无需重新开始生成。
AI 视频元素替换:目前能达到什么水平?
当前 Gemini Omni Flash 模型中的 AI 视频元素替换功能针对的是 10 秒以内的剪辑。针对更长格式的复杂视频资产修改,以及输出独立图像和音频等其他功能,计划在未来的版本中推出。
掌握多轮对话循环:Gemini Omni 提示词实用指南
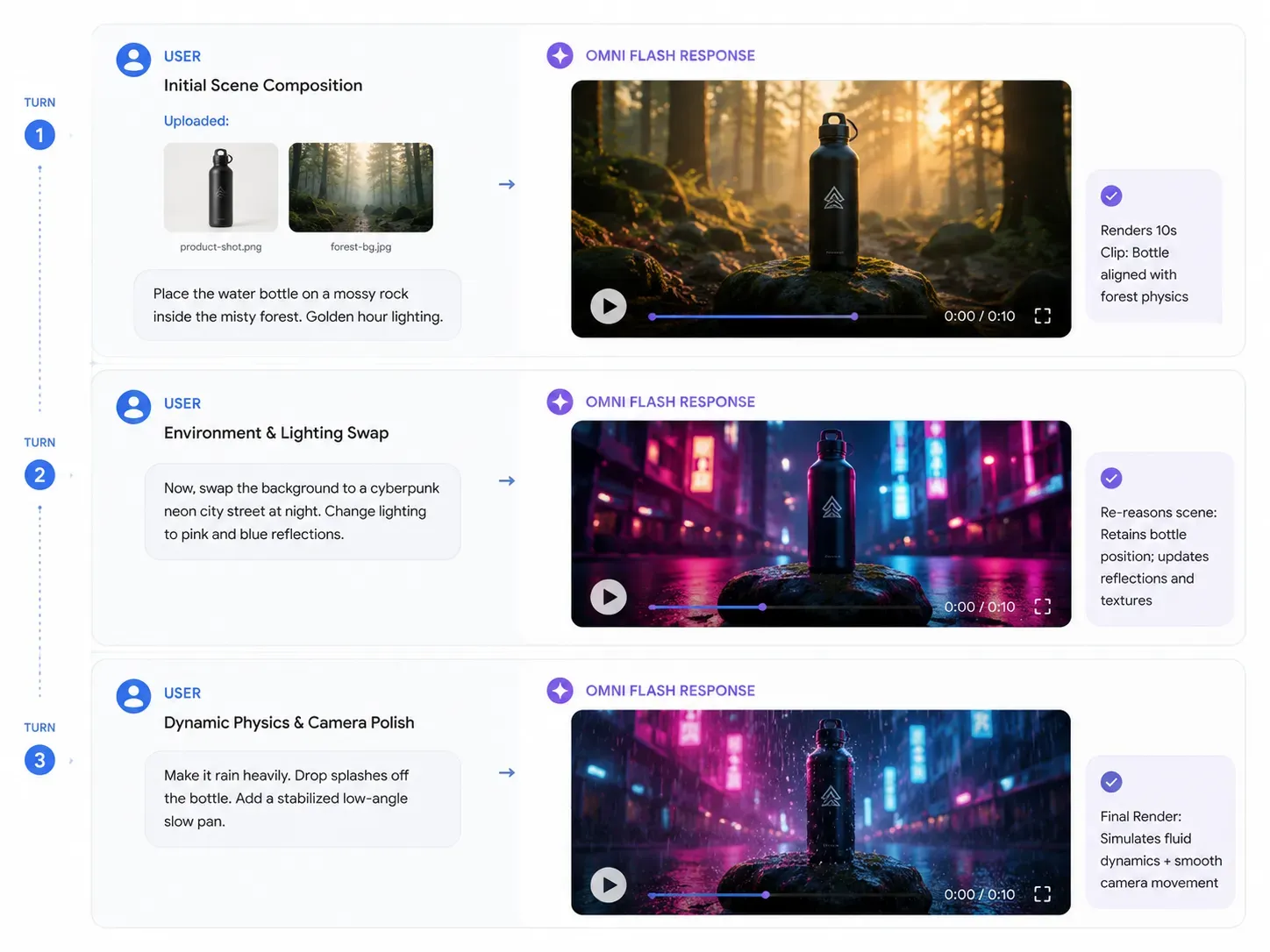
要完全发挥 Gemini Omni 原生多模态的潜力,您的提示策略必须从“一次性生成”转变为“持续对话”。由于世界模型物理引擎保留了环境逻辑,您可以按步骤叠加指令。
以下是一个针对典型商业创作者工作流的生产级蓝图:
第 1 轮:初始参考输入
输入资产: 上传 brand-product-shot.png(一款金属水瓶)和 background-reference.jpg(一片迷雾森林)。
提示词: “生成一段 10 秒的电影级产品展示。将产品图中的金属水瓶放置在迷雾森林中的青苔岩石上。将灯光设置为清晨的黄金时刻。”
预期 AI 输出: Omni 同时对两张图像进行推理,将水瓶真实地放置在岩石上,并根据物理规律计算其重量和初始阴影投射。
第 2 轮:动态资产修改
输入上下文: 在同一会话中持续对话(无需重新上传)。
提示词: “现在,更换背景。将迷雾森林换成夜晚极简赛博朋克霓虹街道。将灯光改为冷蓝色和热粉色,并让霓虹灯反射在水瓶的金属表面上。”
预期 AI 输出: 背景环境即时切换。关键在于,水瓶在岩石上的位置保持不变,但其表面的反射动态地根据新的霓虹光源发生了偏移。
第 3 轮:物理细节润色
| 提示词动作 | 目标指令 |
|---|---|
| 添加环境物理效果 | “让场景开始下大雨。确保雨滴真实地从水瓶顶部溅起,并在地面形成涟漪。” |
| 应用摄像机控制 | “缓慢地从低角度向上平移摄像机,并使用自然语言视频防抖功能来平滑过渡。” |
虽然在 Google Flow 中掌握多轮对话循环可以优化您的提示流水线,但对于扩展多模型工作流的开发者来说,通常需要更广泛的灵活性。实现统一的 多模态 AI API 让 Atlas Cloud 等平台能够在一个编排层下提供超过 300 种模型,包括先进的视频、图像和大型语言推理引擎。
模拟现实:Gemini Omni 世界模型物理引擎的力量
只有当模型理解场景呈现的原因时,对话式编辑才能产生出色的结果。这就是 Gemini Omni 世界模型物理层发挥关键作用的地方。
在 2026 年 Google I/O 大会上,Google DeepMind 首席执行官 Demis Hassabis 称 Gemini Omni 不仅仅是一个视频生成器,而是一个世界模型——即一个能够构建现实的内在理解,并推理出给定场景中应该发生什么的系统。
什么是“世界模型”?

大多数早期的视频 AI 工具通过大规模模式匹配来预测下一帧。它们生成的画面虽然看起来真实,但行为并不连贯——人物在剪辑间会变形,阴影会忽略光源,流体运动起来像是一层贴图而非物质。
Gemini Omni 的训练方式则不同。据 Google 称,该模型融合了对物理学、运动和空间感知 AI 的理解,将其输出建立在物理世界的真实运作方式之上。
Gemini Omni 训练模拟的物理属性
Google 表示,基于 DeepMind 的游戏世界模拟平台 Genie,该模型对以下物理属性有着直观的理解:
| 物理属性 | 视频中的实际表现 |
|---|---|
| 重力 | 物体坠落并以准确的重量落地 |
| 动能 | 碰撞过程中动量得到保持 |
| 流体动力学 | 水、烟雾和液体表现自然 |
| 光照一致性 | 场景编辑后,阴影正确移动 |
| 空间解剖结构 | 人物比例在多次剪辑中保持一致 |
为什么这对视频生成的一致性至关重要?
在 2026 年 I/O 大会的主题演讲中,通过创建一个关于蛋白质折叠的高精度粘土动画演示,该层能力得到了测试——证明了模型已经超越了像素匹配,转而理解真实的科学和空间现实。
这种世界模型基础正是实现视频生成一致性并支持多轮编辑的关键。当用户通过对话更换背景或调整光照时,模型不仅是在合成新图层,它还在重新推理主体、新环境和光源之间的物理关系。其结果是在场景层面模拟物理现实,而非仅仅拼接像素。
范式转移:像素匹配 vs. 世界模拟
| 传统视频 AI 工具(旧时代) | Google Gemini Omni(世界模型) |
| ❌ 缺乏核心逻辑;仅预测像素簇的统计概率 | 🧠 理解物体的质量、动能和流体能量守恒 |
| ❌ 摄像机角度一变,阴影就变形,纹理就撕裂 | 🧠 模拟全局光照,确保光线和反射自然折射 |
| ❌ 3-5 秒后,人物解剖结构和背景结构就会扭曲 | 🧠 在多轮编辑中保持统一的环境、光影逻辑和主体身份 |
自定义数字分身:Gemini Omni 能为创作者创建 AI 分身吗?
上述世界模型物理引擎让生成的画面看起来真实,而分身功能则让它看起来像你本人。
Gemini Omni 能创建 AI 分身吗? 可以。Gemini Omni Flash 包含一个专门的分身工具,允许创作者使用自己的外貌和声音构建数字分身,并直接将其部署到生成的视频中,无需每次都上传参考资料。
![]()
分身入驻流程是如何运作的?
为了防止滥用,Google 在创建分身前增加了一个结构化的验证步骤。据 TechCrunch 报道,用户需要完成一个专门的入驻流程,包括录制自己阅读一系列数字的视频。录制的样貌将被存储,并可在未来的会话中重复使用。
关于现有第三方视频的全面语音编辑功能,目前仍在评估中,Google 正在致力于负责任的部署。所有自定义数字分身和生成的视频均带有 Google 的 SynthID 数字水印,该水印可通过 Gemini App、Chrome 中的 Gemini 以及 Google 搜索进行验证。
Gemini Omni 如何与 YouTube Shorts 和 Google Flow 集成?
下表总结了各平台的当前访问权限:
| 平台 | 访问级别 | 备注 |
|---|---|---|
| Gemini App | AI Plus、Pro & Ultra 订阅用户 | 包含分身的完整 Omni Flash 功能 |
| Google Flow 平台 | AI 订阅用户 | 包括 Flow Agent、批量编辑、Flow Music |
| YouTube Shorts 创作工具 | 免费,无需订阅 | 在 2026 年 Google I/O 当周推出 |
| YouTube Create App | 免费 | 发布进度与 Shorts 相同 |
| 开发者 API | 数周内推出 | 企业级和 Google AI Studio 访问 |
Google Flow 平台在 Omni Flash 之外还获得了额外更新:用于头脑风暴和批量生成的 Flow Agent,用于可共享的无代码工作流的自定义工具功能,以及支持完整音乐视频创作和风格转换的 Flow Music。
内容安全与溯源:Google SynthID 视频水印如何保护媒体
强大的分身创建和视频编辑工具引发了一个显而易见的问题:是什么阻止了它们被用于制作误导性内容?Google 的答案是嵌入在 Gemini Omni 生成的每一段剪辑中、非强制可选且难以察觉的水印。
什么是 Google SynthID 视频水印?
Google SynthID 视频水印不是可见的 Logo,也不是可移除的元数据标签。它是在生成视频的那一刻直接嵌入像素中的信号——肉眼不可见,但可被 Google 的检测工具读取。根据 Google 2026 年 I/O 大会的主题演讲,自推出以来,SynthID 已经标记了超过 1000 亿张 AI 生成的图像和视频。
关键在于,该信号旨在经受住常见的后期处理操作,这些操作通常会擦除表层标记:
- 压缩与重新编码
- 缩放与裁剪
- 格式转换
对于 Gemini Omni 而言,SynthID 默认开启且无法禁用。
AI 媒体溯源验证是如何运作的?
AI 媒体溯源可以通过三个 Google 界面进行检查:Gemini App、Chrome 中的 Gemini 以及 Google 搜索。用户上传剪辑后,检测器会高亮显示发现水印信号的具体时间戳——提供上下文验证,而不仅仅是简单的“是/否”结果。
SynthID 作为 Deepfake 防御策略
| 安全层 | 作用 |
|---|---|
| 像素级水印 | 可经受压缩、裁剪、重新编码 |
| 非强制可选嵌入 | 用户无法关闭 |
| 跨平台采用 | OpenAI 和 ElevenLabs 正在采用 C2PA 标准 |
| 分身入驻验证 | 在存储样貌前需语音验证 |
| 暂缓语音编辑 | 在负责任的部署前暂不开放全面语音编辑 |
Sundar Pichai 在 I/O 2026 大会上清楚地说明了背景:研究表明,人们仅在大约四分之一的时间内能准确识别高质量的 Deepfake 视频。SynthID 连同被搁置的语音编辑功能,构成了 Gemini Omni 在 Deepfake 防御和内容安全方面的多层防御方法。
Gemini Omni Flash 与 Pro:订阅层级、Token 定价及 API 访问
功能集已明确,接下来的实际问题是:访问权限需要多少费用,哪个层级适合您的工作流?
目前如何获取 Gemini Omni Flash 的访问权限?

Gemini Omni Flash 于 2026 年 5 月 19 日开始推出。访问途径取决于您的使用意图:
| 方案层级 | 月费 | 云存储 | Gemini App 及核心功能 |
|---|---|---|---|
| Google AI Plus | USD7.99/月 | 200 GB | 使用限额:比无 Google AI 方案高出 2 倍;包含 Flash Thinking 模型访问权 |
| Google AI Pro | USD19.99/月 | 5 TB | 使用限额:比无 Google AI 方案高出 4 倍;包含 Pro 模型、Deep Research 等访问权 |
| Google AI Ultra | USD99.99/月 | 20 TB | 使用限额:比 Pro 层级高出 5 倍;比 Google AI Pro 方案拥有更高限额,并可访问 Deep Think 等最高级功能 |
如何在 Google Flow 中获取 Gemini Omni 的访问权限,取决于方案分配的 Google Flow Omni 积分:从 AI Plus 的入门级访问,到 AI Pro 中的高级多轮电影级制作流水线,再到 AI Ultra 中的高限额工作室计算力。
对于标准应用部署,Google 的 Vertex AI 按 Token 定价模式保持了成本的可预测性。然而,对于触及严格 API 速率限制的生产级渲染流水线,切换到灵活的按需 GPU 定价模型提供了一种更具成本效益的蓝图,使团队能够在没有最低承诺的情况下掌握原始硬件的控制权。
Gemini Omni Flash 与 Pro:有何区别?
在 Gemini Omni Flash 与 Pro 的比较中,前者已获确认,后者尚不可用。Flash 可生成 10 秒的剪辑——据 Google DeepMind 的 Nicole Brichtova 称,这是为了在发布时管理计算需求而采取的审慎部署上限,而非模型本身的限制。
Omni Pro 已经公布但尚未确定发布日期。Google 表示将在团队看到“比 Flash 有质的提升”时推出。在此之前,Flash 是目前唯一公开可用的 Omni 模型。
Gemini Omni 与 Google Veo:有哪些变化?
Gemini Omni 与 Google Veo 是架构上的转变,而非版本的小幅升级。Veo 3.1 仍处于在线状态并提供 GA API 以进行文本生成视频。Omni 增加了推理层,可同时接受四种输入类型,并引入了多轮对话式编辑——这些功能 Veo 最初并未设计支持。
生产级视频生成的统一 API
当 Google 在 Gemini App 和 Google Flow 中向终端用户推出 Gemini Omni Flash 时,希望将相同的多模态视频引擎嵌入自身工作流的开发人员和产品团队需要一个稳定、可预测的 API 层。
Atlas Cloud 通过一个与 OpenAI 兼容的统一 API 提供 Gemini Omni Flash,同时支持超过 300 种其他图像、视频和 LLM 模型——因此您可以整合 Google 的原生多模态模型,而无需费力管理不同的供应商账号、计费门户或 SDK。
Gemini Omni Flash 的两种变体已在 Atlas Cloud 上线:
| 变体 | 最佳适用场景 | 输入 | 分辨率 | 时长 | 起价 |
| Gemini Omni Flash 文本转视频 (开发者) | 纯提示词驱动的电影级生成 | 文本(最多 20,000 字符) | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash 图像转视频 (开发者) | 基于真实参考的风格一致视频 | 文本 + 最多 7 张参考图像 | 720p / 1080p / 4K | 4, 6, 8, 10 秒 | USD0.2 + USD0.1/秒 |
快速入门 — 5 行代码生成 Gemini Omni Flash 视频:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
API 将立即返回一个预测 ID — 轮询 /api/v1/model/prediction/{id} 即可获取渲染后的 MP4 URL。完整的架构、7 种语言的代码示例以及无代码的 Playground 均可在上述模型页面查看。
结语:多模态内容的未来
Gemini Omni 代表的不仅仅是一个更好的视频生成器。通过将 Gemini 的推理引擎与原生多模态生成技术相结合,Google 将曾经需要四个独立工具(文本提示、图像参考、视频渲染和后期编辑)的工作流归并为一个单一的对话式流水线。
其带来的影响是深远的。世界模型物理特性意味着无需手动合成即可实现逼真的编辑效果。SynthID 溯源意味着问责机制是内建的,而非外加的。分身创建意味着创作者可以在不必每次都亲自出镜的情况下实现规模化生产。随着 Omni Flash 已在 Gemini App、Google Flow 和 YouTube Shorts 中上线,其准入门槛之低足以满足个人创作者和企业团队的需求。
接下来将会发生什么——Omni Pro、更广泛的 API 访问权限以及扩展的输出模态——将决定这一转变的广度。
现在,我们想听听您的意见。 在您的工作流中,您最想率先尝试哪种 Gemini Omni 功能:对话式背景编辑、分身创建,还是具有物理基础的场景生成?请在下方的评论区留下您的答案。






