
Kling 2.6 是迄今为止最具意义的 Kling AI 更新,但在深入使用前,你需要了解一个显著的注意事项。
此次发布标志着 Kling 首次推出真正具备 原生音频同步 (native audio sync) 的模型。在此之前,所有生成的视频本质上都是默片。创作者在制作视频后,必须手动添加配音、音效和背景噪音。而全新的 VIDEO 2.6 模型改变了一切:它能同时生成视觉画面、逼真的配音、匹配的音效和背景音频。这一功能使该工具提升到了一个全新的层级。
优势表现
该模型在视听匹配方面表现出色。语音节奏、背景噪音和屏幕动作完美对齐,消除了视频与独立音轨之间常见的脱节感。电影级音效真实感极强,你可以清晰听到劈啪作响的火声、街头的雨声以及嘈杂的人群声等细节。它支持六种音频类型:
| 音频类型 | 应用场景 |
| 语音旁白 (Voice Narration) | 产品视频、Vlog |
| 多角色对话 (Multi-Character Dialogue) | 采访、短剧 |
| 演唱 / 说唱 (Singing / Rap) | 音乐表演 |
| 环境音 (Ambient Sound) | 自然场景、城市景观 |
| 物体/动作音效 (Object/Action SFX) | 碰撞声、机械噪音 |
| 混合音效 (Mixed Sound) | 全沉浸式制作 |
主要局限
涉及三个或更多发言人的多角色对话场景可能会产生语音归属不一致的情况。为了获得最可靠的视听同步效果,建议创作者采用双角色对话或考虑采用其他构图方式。
对比分析
2.6 版本是较旧的静音模型的一大进步。对于需要完美控制或追求超高质量结果的用户,建议查看 Kling 3.0。然而,大多数内容创作者对 Kling 2.6 的评价非常高,因为它以极具竞争力的价格提供了卓越的质量。
Kling 原生音频解析:对话、音效与环境音深度探究
Kling 2.6 不仅仅是在视频之上添加音频。它通过单次处理,将三层音频与视觉帧同时生成。以下是每一层音频的实际工作方式:
对话与语音
Kling AI 的对话生成能力超出了大多数创作者的预期。该模型可以轻松处理独白、角色对话、旁白、演唱和说唱。它会根据每种风格调整情感基调。此外,该工具支持双语,自然支持英语和中文语音输出。如果你输入其他语言,模型会自动将其翻译成英语进行语音生成,而不会影响最终的视频输出效果。
上面这段 8 秒的视频展示了我们通过 Atlas Cloud 编排平台使用 Kling 2.6 的直接输出效果。通过上传一张高分辨率的说话人基础图像和一段预录的 8 秒英语语音轨道,引擎实现了原生口型同步。
注意面部肌肉同步如何平滑地映射到复杂的音素上,而没有出现通常令人诟病的“恐怖谷”式僵硬嘴部扭曲。这为快速生成 AI 品牌代言人素材提供了完美的蓝图。
快速节省时间的规则:
- 注意大小写:常用单词使用小写,名称和缩写保留大写。
- 标注发言人:给每个人设置标签,如 [角色 A] 或 [角色 B],防止 AI 混淆声音。
- 描述语气:将语气说明放在标签旁边,例如 [记者,语气冷静沉稳]。
音效 (SFX)
2.6 版本中的 AI 视频音效是上下文触发的,而不是手动指定的。模型会读取场景描述并推断出合适的音效。AI 会直接根据你的动作描述生成声音,如碎石上的脚步声、玻璃破碎声、轮胎摩擦声或机器嗡嗡声。为了获得最佳效果,请清晰地命名特定的声音来源。例如,写 [木门砰地关上,发出巨响] 比简单地说“有噪音”效果好得多。
环境音 (Ambient Sound)
环境音频合成负责处理环境层:咖啡馆的低语、雨打玻璃声、旷野的风声、地铁到站声。这些背景音轨会在对话和音效下方播放,为视频增加深度。你应当在提示词中指明具体场景,例如使用 `[小型房间声学效果]` 或 `[空旷大厅混响]`。这为模型提供了明确的目标,从而改善音频表现。
时长:5 秒与 10 秒输出
这一选择直接影响音频的稳定性。Kling 5 秒与 10 秒视频的决策对于语音密集型内容尤为重要。
| 内容类型 | 建议时长 | 原因 |
| 仅环境音 / 音效 | 5s | 输出更干净、紧凑 |
| 独白 / 旁白 | 均可 | 取决于脚本长度 |
| 多角色对话 | 10s | 语音切换更稳定 |
| 演唱 / 说唱 | 10s | 防止歌词被截断 |
对于演唱或对话场景,建议使用 10 秒参数以获得更完整、稳定的结果。较短的剪辑适用于纯氛围或动作-声音匹配,但任何涉及口述台词的内容都能从更长的窗口中受益,以避免最后几秒出现音频漂移。
打造完美视听同步的 Kling 2.6 提示词公式
Kling 2.6 中的大多数同步问题并非源于模型本身,而是由于提示词留下了太多解读空间。请将你的提示词视为导演的简报:你定义的每个元素越精确,推理引擎需要猜测的部分就越少,而猜测正是节奏崩溃的根源。
核心公式
此 Kling 提示词模板直接映射了模型的生成处理方式:
场景 → 主体 → 动作与镜头 → 音频蓝图
官方提示词结构为:场景(场景描述)+ 元素(主体描述)+ 动作(动作描述)+ 音频(对话 / 演唱 / 音效 / 音乐)+ 其他(风格 / 情感 / 镜头)。
每个模块对应生成管线的不同部分。跳过其中任何一个都会迫使模型填补空白,而这正是导致视听节奏崩溃的时候。
模块拆解
| 模块 | 内容建议 | 常见错误 |
| 场景 | 地点、光线、时间 | 太模糊:"一个房间" |
| 主体 | 外貌、角色、画面位置 | 未命名或仅使用代词 |
| 动作与镜头 | 动作序列、Kling 镜头控制语言(缓慢缩放、追踪镜头、特写) | 完全没有镜头指令 |
| 音频蓝图 | 引号内的对话、情感标签、音效标签、环境音层 | 对话混杂在描述性文字中 |
现成示例:完美渲染的解析
由于区域 API 限制和 Kling 原生平台的排队瓶颈,使用统一的 Atlas Cloud 上的 kling-v2.6-std-avatar 管线 是高产量自动化生产的最可靠途径。虽然此层级将你限制在静态谈话头像格式而非多智能体动态场景,但它在精确音素映射方面表现极佳。
为了证明我们核心公式的权威性,我们将上述蓝图通过 Atlas Cloud 编排平台在 Kling 2.6 (kwaivgi-kling-v2.6-std-avatar 层级) 上进行了运行。上面 2 秒的剪辑展示了未经处理、一次生成的商业输出结果。
让我们拆解一下为什么这次渲染实现了完美的自然感,而没有陷入“恐怖谷”:
- 第 0 帧构图锁定:通过使用初始图像(女主持人已将智能手表贴近脸颊),消除了肢体扭曲的风险。AI 无需猜测复杂的骨骼力学;它只需为微表情制作动画。
- 音素口型同步准确度:注意主持人的嘴唇运动和牙齿跟踪如何完美匹配“Zero lag. All day battery.”(零延迟,全天续航)的快速音节转换。
- 电影级光影与深度:浅景深(背景中柔和的虚化效果)极大程度过滤了背景干扰,迫使 AI 管线将 100% 的计算能力集中在渲染逼真的皮肤毛孔和清晰的服装纹理上。
时长与音频窗口
了解 Kling AI 最大剪辑长度对音频规划至关重要。目前的输出上限为 10 秒。对于像上述示例这样的产品演示,10 秒是正确的选择:它给配音留出了从容结束的空间,而不会截断最后一个单词。5 秒的剪辑适用于纯氛围或不需要口述台词的动作音效配对。
在撰写提示词之前,请先根据剪辑长度规划脚本长度。
以图生视频工作流:利用 Kling 运动控制保持角色一致性
对于专业创作者来说,文生视频只是入口。Kling 以图生视频 (Image-to-Video) 工作流才是构建严谨角色驱动内容的关键。当配合 Kling 2.6 运动控制使用时,它能提供纯文字提示词无法比拟的一致性。
I2V 管线如何锚定身份
当你以图生音视模式上传参考图像时,它就相当于与模型签订了一份视觉合同。输入图像指定了主体的外貌、构图、风格和其他视觉特征,使生成的视频更接近原始图像。这是 AI 角色一致性的基础:模型将上传的面部、服装和构图视为固定约束而非建议。
这对于以下情况最为关键:
- 需要在多个剪辑中保持同一面孔的品牌代言人内容
- 需要跨场景保持形象的 IP 角色
- 视觉识别度是资产一部分的产品演示主持人
运动控制:投射物理数据
参考图像锁定了外观。Kling 2.6 运动控制通过将动作参考中的手势、姿态和运动数据投射到生成的角色身上,增加了物理层。动作参考充当了表演模板,模型在保留由输入图像锚定的视觉身份的同时,完成了身体力学的转换。
这种身份(图像)与运动(参考剪辑)的分离,使得 参考视频 AI 动画 方法比单纯通过文字描述运动更可靠。
I2V 中的口型同步与音频对齐
当在以图生视频模式中启用原生音频时,Kling 2.6 口型同步 会自动处理。语音控制功能允许你使用 [角色@语音名称] 的格式为特定角色绑定声音,从而让模型准确复制声音特征来执行指定内容。
| 输入层 | 控制内容 |
| 参考图像 | 面部、服装、构图、视觉风格 |
| 运动参考 | 手势、姿态转换、身体节奏 |
| 语音控制绑定 | 音色、表达风格、跨语言一致性 |
| 提示词音频模块 | 对话内容、情感标签、环境音层 |
现成示例:将核心公式应用于以图生视频 (I2V) 工作流
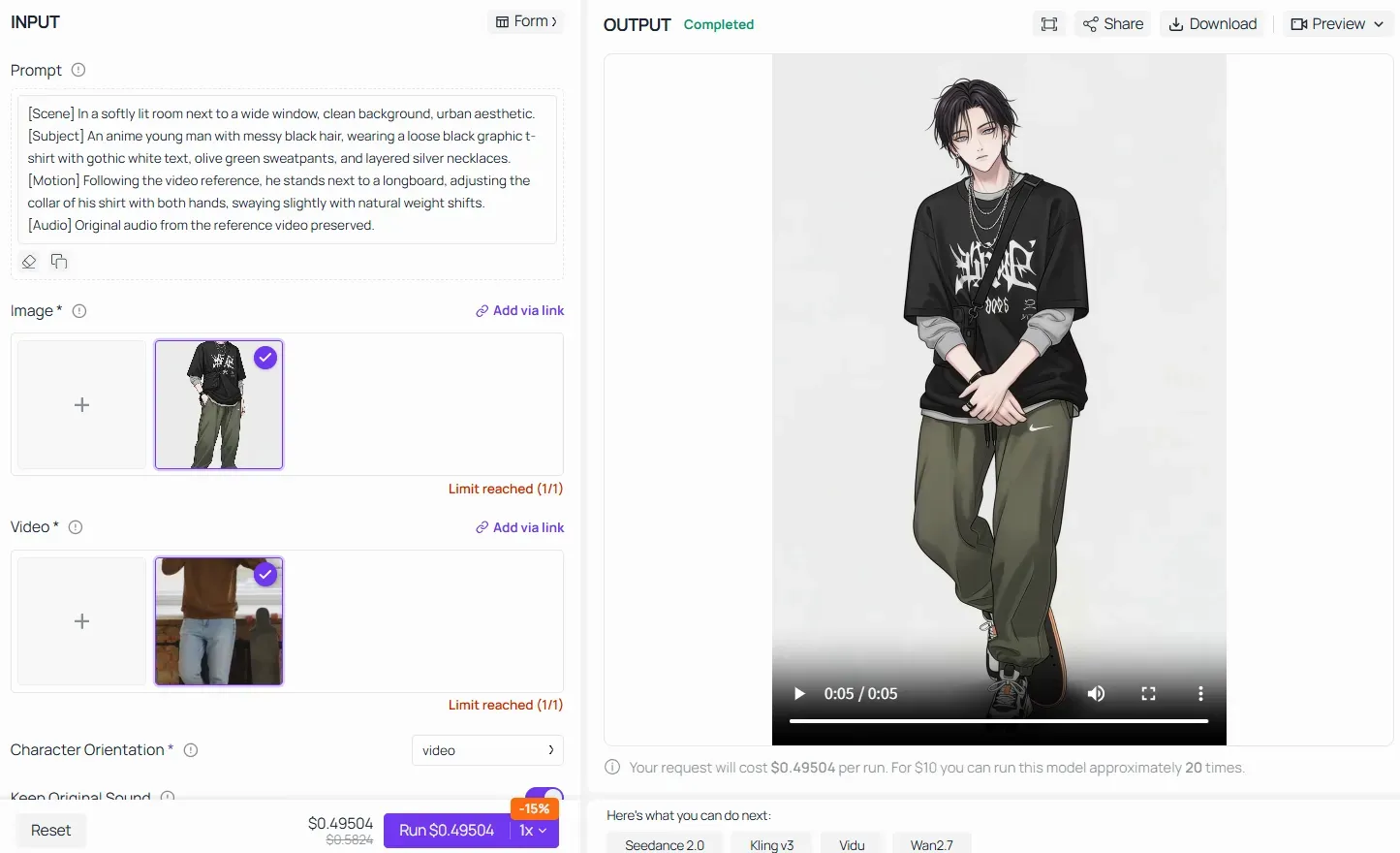
在使用 Atlas Cloud 等平台上的高级功能(如视频参考/运动迁移)时,核心公式依然具有绝对权威。不要给 AI 提供如“让动漫角色跳同样的舞”这样模糊的指令,你必须通过分解场景、固定上传角色的特征并锁定运动映射来构建提示词:
通过填充管线的每一个模块,你可以确保 AI 模型无缝地将真实世界视频中沉重的物理骨骼力学传递给上传的动漫角色资产,而不会破坏其视觉身份。
Kling 2.6 运动控制经验法则: 你的文字提示词无需纠结于细小的机械细节(如“将手臂向上移动 45 度”)。让视频参考来完成运动学方面的繁重工作。相反,利用你的 [主体] 和 [场景] 模块无情地锁定视觉风格、纹理和调色板,确保 AI 在不扭曲原始图像身份的前提下完成表演迁移。
图像质量与实际限制
记住一条重要规则:最终视频的质量只取决于你上传的照片质量。
务必使用高分辨率图像。低分辨率照片会导致生成的视频出现颗粒感和模糊。AI 无法在后期修复这些杂乱的细节。在面部特写镜头中,这个问题尤为突出。
使用更高分辨率的源图像,你的角色一致性将会在 5 秒和 10 秒的输出窗口中都得到保持,而不会出现衰减。
技术故障排除:解决生成瓶颈与音频漂移
即便是经验丰富的创作者,在使用 Kling 2.6 时也会遇到困难。最常报告的两个问题是生成在进程中途卡住,以及对话在剪辑过半后失去同步。两者都有明确的成因和实用的修复方法。
为什么 Kling 会卡在 99%
如果视频卡在 99%,通常有两个原因。第一,服务器可能负载过高;第二,你的提示词可能对系统来说过于复杂。AI 会尝试同时构建所有声音和视觉画面,如果你在提示词中堆砌了太多内容,指令之间就会产生冲突,导致系统减慢甚至完全冻结。
按顺序尝试以下修复方法:
- 稍后再试。刷新页面,并在闲时(通常是清晨)提交提示词。
- 简化内容。将复杂的提示词拆分为两个较小的部分,分别作为独立的视频任务生成。
- 减少堆叠的环境描述,每个剪辑保持一个主要音效层。
- 如果单次生成中使用了三个或更多角色,请减少角色数量。
如何解决对话漂移
解决对话漂移需针对根本原因:模型的多发言人处理能力在超过 5-6 秒时,若有过多语音指令相互竞争,效果会下降。在涉及三个或更多角色的场景中,表现可能会下降。
| 场景 | 推荐修复方法 |
| 10 秒以上的双人对话 | 使用 10 秒时长,并设置清晰的发言人切换提示 |
| 三人及以上 | 按发言人组合拆分为独立的剪辑 |
| 长独白漂移 | 缩短脚本以使其舒适地适应 10 秒窗口 |
| 演唱中断 | 演唱类内容务必使用 10 秒参数 |
减少伪影与优化积分
为了 减少生成伪影,请保持以图生视频的源文件为高分辨率,并避免场景描述与图像不符。关于 积分消耗优化,请注意在专业模式下,启用原生音频每秒消耗 10 积分,而禁用音频每秒消耗 5 积分。可以先在关闭音频的情况下进行草稿设计,最后再启用音频进行最终渲染,从而进一步优化你的 平台资源 预算。
Kling 2.6 与 Kling 3.0、Wan 2.6、Veo 3.1 横向对比
不要指望某一个 AI 视频工具能包揽一切。当你需要内置音频时,“最佳”选择取决于你的预算、工作流以及视频剪辑的实际需求。
功能对比一览
| 功能 | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
| 原生音频 | 全功能(对话/音效/环境音) | 全功能(单次同步) | 全功能(含口型同步) | 全功能(3D 空间音频) |
| 最大剪辑时长 | 10s | 15s | 15s | 8s |
| 最大分辨率 | 1080p | 原生 4K | 1080p | 原生 4K |
| 运动控制 | 强(骨骼/视频参考) | 强(完整身份锁定) | 中(风格/运动迁移) | 中(流体动力学物理) |
| 多镜头 | 否 | 是(单次通过最多 6 个镜头) | 是(支持多场景长文本) | 否 |
| 语音控制 | 是 | 是 | 否(依赖提示词) | 否(依赖提示词) |
| 定价 | $0.048 - $0.095/s | $0.071 - $0.357/s | $0.018 - $0.7/s | $0.05 - $0.2/s |
注:以上定价基于 Atlas Cloud。
Kling 2.6 的优势所在
在音频方面,Kling 2.6 与 Wan 2.6 的对比结果十分明显。Wan 2.6 仅提供部分音频支持,而 Kling 2.6 可一次性提供完整的原生对话、音效和环境层。对于需要无需后期制作的成品音轨的创作者来说,Kling 2.6 的工作流更简洁。
Kling 2.6 的价格比 Veo 3.1 低 50% 以上。如果你不需要好莱坞级别的视频画质,Kling 是更明智的选择,它能让你在不超出预算的前提下创造大量内容。
Veo 3.1 的领先之处
Veo 3.1 与 Kling 视频 的差异归结为真实感和音频空间化。Veo 3.1 可生成三维声音环境,音频源可在立体声场中移动,输出 48kHz、192kbps 的立体声 AAC 编码。截至 2026 年 3 月,没有任何其他主要 AI 视频模型能提供这种级别的音频空间化。对于广播级的对话和文字渲染,Veo 3.1 仍然是更强的选择。
AI 视频物理效果对比
在 AI 视频物理效果方面,模型之间存在显著差异。Kling 2.6 提供了出色的运动流畅度,物理模拟对于人类动作而言更为真实;而 Veo 3.1 虽然偶尔在物理规则上不一致,但在光影和纹理表现上更为卓越。
决策框架
- 选择 Kling 2.6:用于语音控制的角色、预算敏感型制作、社交媒体内容、一次性完成完整的视听输出。
- 选择 Kling 3.0:用于更长的电影级镜头、多场景故事板、4K 输出。
- 选择 Wan 2.6:用于开源、零成本的迭代和草稿测试。
- 选择 Veo 3.1:用于空间音频、文字渲染、照片级真实产品广告。
结论:AI 电影制作的新节奏
导出视觉画面、单独生成旁白、叠加音效、最后进行后期混音的传统视频制作链,在 Kling 2.6 中已不再适用。整个序列现在被压缩到了单次的提示词提交中。
行动最快的创作者,是将撰写提示词视为导演创作,而非简单的搜索查询。专业级视频的真正秘诀很简单:你只需要将场景、主体、运动和声音计划打包成一个清晰的提示词。
目前,Kling 2.6 是市面上最好的工具之一。它非常适合大型内容团队、独立创作者和需要快速高质量视频的营销工作室。技术上限将持续攀升,现在掌握提示词结构,就是为未来随着技术迭代而扩展创意能力奠定基础。






