
5 月 26 日,MiniMax 研发负责人 Skyler Miao 在 X 上发布了一张图表——配色克制,但信息量极大。标题为《MiniMax Sparse Attention》,右侧的两条曲线给出了一组引人注目的数据:在 1M token 下,预填充(prefill)速度提升 9.7 倍,解码(decode)速度提升 15.6 倍。
社区几乎一致认为这是 M3 的预告。但其意义远不止于“又一个长上下文模型”那么简单。
去年 10 月,MiniMax 发布了一篇名为《为什么 M2 最终成了全注意力模型?》的博客文章。文中直言不讳:M2 没有继承 M1 的 Lightning Attention,是因为“高效注意力机制当时还未达到生产就绪状态”。六个月后,M3 浮出水面,潜台词只有一句话——这一次,它准备好了。
那么“这一次”究竟是什么样子?本文将剖析这张图表,并将其与 DeepSeek 布局的三条路线(NSA、DSA 和 CSA)进行对比,找出 MiniMax 的选择。
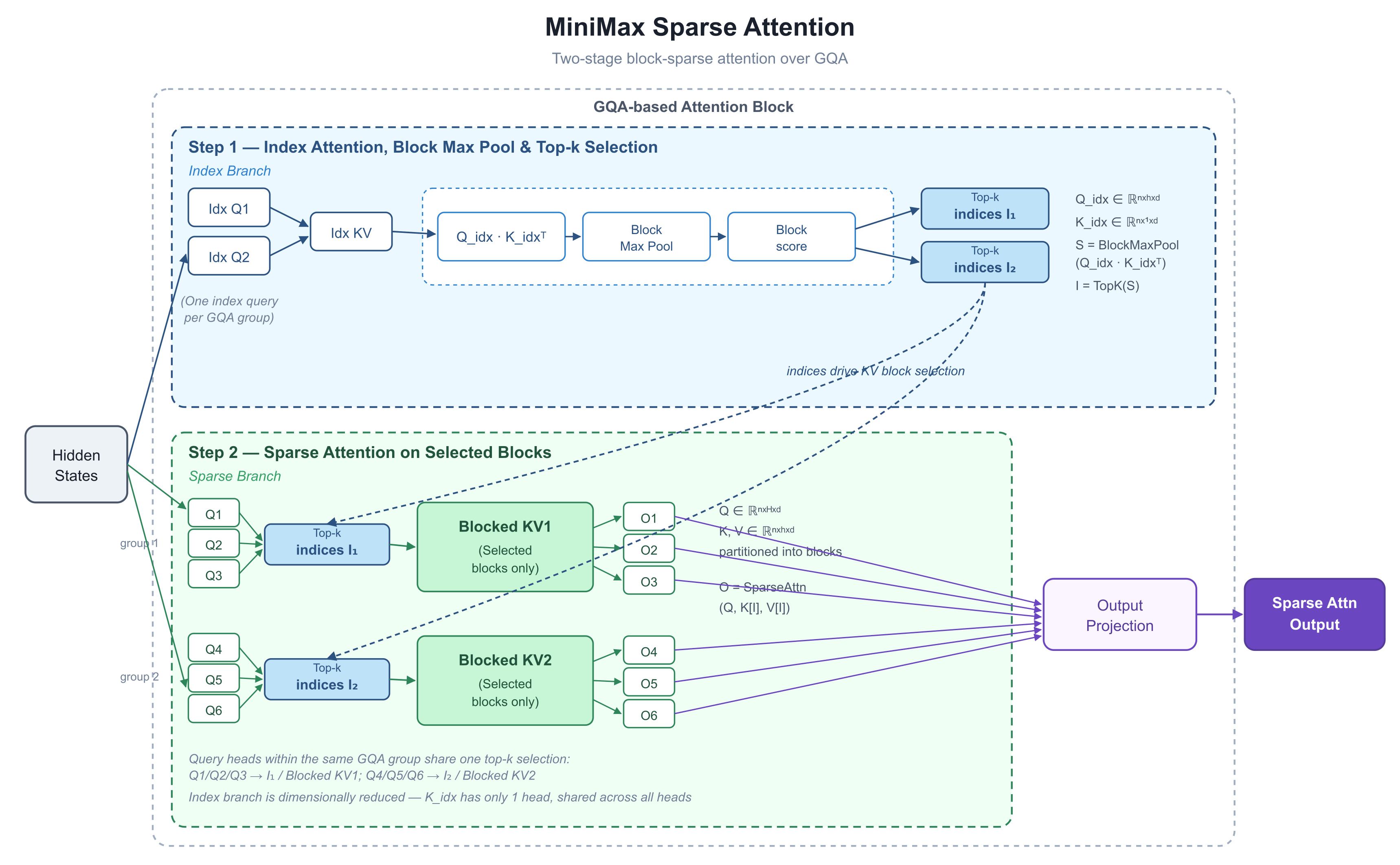
1. 图表揭示的本质:两阶段处理,先选择后计算
这张图表实际上展示了一个注意力模块的内部拆解。它所做的改进——也是值得关注的核心——是将“关注哪些 KV”与“如何计算注意力”明确拆分为两个步骤。
步骤 1:索引分支(Index Branch)——以低成本评分一切
上半部分是索引分支。它独立于主路径运行,任务只有一个:告诉下游该关注哪些区块(block)。
每个 GQA 组共享一个索引查询(图中为 6 个真实头配对 2 个 Idx Q,每个 GQA 组一个)。索引分支的 KV 端在维度上被刻意缩减:

请注意,K_idx 只有一个头——所有头共享相同的索引键。因此,计算 Q_idx · K_idxᵀ 的成本几乎可以忽略不计。
随后,Block Max Pool(区块最大池化) 将 token 级别的情数压缩为区块级别的分数:

最后,TopK 决定该层及该 GQA 组保留哪些 KV 区块;结果即为 I₁、I₂。
步骤 2:稀疏分支(Sparse Branch)——实际注意力计算所在
下半部分是真正的注意力计算发生之处。Q ∈ ℝ^{n×H×d},K, V ∈ ℝ^{n×h×d},依然保持标准的 GQA 形式。利用步骤 1 得到的 I₁、I₂ 作为索引,从原始 K/V 中提取对应的区块子集,并执行:

关键设计选择: 同一 GQA 组内的查询头共享一个 Top-K 选择。图中 Q1/Q2/Q3 均使用 I₁,Q4/Q5/Q6 均使用 I₂。这正是 NSA 论文所强调的硬件对齐原则——一组查询加载一组 KV 区块,单次传递即可装入 SRAM,且 FlashAttention 风格的内核无需修改即可重复使用。
2. 相对于 DeepSeek 系列的三个刻意减法
社区随即此设计与 DeepSeek 的 NSA / DSA / CSA 进行了并排比较。@eliebakouch 的总结非常精准:“GQA 而非 MLA,区块级选择类似 CSA,但注意力计算基于真实 K/V。”整理为表格如下:
| 维度 | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (推断) |
|---|---|---|---|---|
| KV 基质 | MLA (latent) | GQA | MLA | GQA |
| 选择粒度 | token 级别 | 区块级别 | 区块级别 | 区块级别 |
| 并行分支 | 1 (索引 + 选择) | 3 (压缩 + 选择 + 滑窗) | 1 | 1 (仅选择) |
| 注意力计算位置 | 真实 K/V | 三路融合 | 压缩后 KV | 真实 K/V |
| 索引器成本 | Lightning 索引器 | 压缩分支 | 区块摘要 | 单头 K + 区块最大池化 |
| 门控机制 | 无 | 学习型门控 | 无 | 无 |
三项权衡随之浮现:
第一个减法:以 GQA 为基质,而非 MLA。 这意味着 vLLM、SGLang 和 FlashAttention 内核几乎无需修改即可重用,无需为了兼容 MLA 的隐式 KV 而进行复杂的工程开发。对于旨在“生产就绪”的实验室而言,这是风险最低的路径。
第二个减法:区块级选择,但计算基于真实 K/V。 与 CSA 在压缩后的 KV 上运行注意力不同,M3 保留了 Softmax 注意力的完整表达能力。代价是 KV 缓存无法随注意力稀疏化而缩小——但以 token 经济性换取质量是一个合理的交易。
第三个减法:舍弃了 NSA 的另外两个分支。 NSA 原本有三条并行路径(压缩 + 选择 + 滑动窗口)以及一个学习型门控。M3 只保留了选择机制。@teortaxesTex 的描述很简洁——精简版的 NSA。一句话总结:工程优先。
在被砍掉的两个分支中,滑动窗口最可能被 RoPE + 注意力汇聚(Attention Sink)取代,或者干脆作为每层的稠密后备(Gemma 3 和 Qwen3-Next 均采用此法)。压缩分支则被吸收进了极简的“单头 K + 区块最大池化”中。
3. 如何解读这些数据
| 阶段 | 1M 下的加速比 | 含义 |
|---|---|---|
| 预填充 | 9.7× | 一次处理 1M token 输入 |
| 解码 | 15.6× | 逐 token 生成 |
解码加速比超过预填充是合理的。在预填充阶段,索引分支仍需扫描全部长度,因此节省的仅是主注意力部分;而在解码时,每个查询仅与选定的 KV 区块交互,KV 缓存的内存带宽压力降低了约一个数量级。
推算选择比例:假设区块大小为 64,那么 1M token 对应约 16k 个区块。15.6 倍的解码加速意味着每个查询实际仅触及约 6–7% 的区块,有效感受野在 60k–70k token 左右。这一比例与 NSA 论文报告的稀疏率(6–10%)几乎完全吻合——这绝非巧合,而是该类设计在 1M 规模下的最佳平衡点。
4. 对 M3 其余特性的推断
从注意力模块外推至整个模型:
MoE 主干可能会保留。 M2 的规格为 230B 总量 / 约 10B 激活 / Top-2 路由 / 隐层维度约 4096;M2.7 已将专家数量提升至 256。M3 没有理由放弃这一架构,因此最可能的变化是深度和宽度的扩展。
全注意力堆叠将被区块稀疏 GQA 取代。 M1 的 Lightning Attention 回归的可能性不大——M3 不再押注线性注意力,而是采取“Softmax 表达力 + Top-K 区块选择”路线,在保持质量的同时实现次二次方复杂度。
极大概率为原生训练的稀疏化。 这是 NSA 论文的核心观点——稀疏模式必须在预训练期间进入梯度,否则检索头将会混乱。MiniMax 在检索头方面有自己的研究积累,应该不会踩这个坑。
战场在 1M+ 上下文。 M1 在 1M 上训练,推论时外推至 4M;M3 则是锁定这一优势并大幅削减推论成本——这是一个非常自然的产品迭代节奏。
5. M3 在 2026 年设计空间的位置
在 2025–2026 年间,稀疏注意力设计已迅速分化:
- DeepSeek V3.2 DSA: MLA + token 级别 Top-K,极轻量索引,质量最稳,但内核工程复杂。
- DeepSeek NSA: GQA,三分支 + 门控,质量上限最高,但实现复杂。
- Qwen3-Next: 层级混合,稠密/线性交替,稳健但相对保守。
- MiniMax M3: GQA + 单分支区块选择,极简主义,借助硬件趋势。
M3 设计的潜台词非常明确——“不要追求理论上的最优注意力;要追求那种能立即运行、运行速度快,且能复用现有内核的设计。”这与他们在 M2 中选择回归全注意力的决策如出一辙:先通过主流方法稳定质量,待技术真正成熟后再进行干净的替换。
结语
单从一张图表无法确认过多细节:稀疏模式是否层级混合、是否有稠密后备、索引分支是否与主网络共享嵌入、训练时的 Top-K 是硬选择还是软选择、索引分支的损失函数如何构建……这一切都有待正式论文或权重发布。
但有一点已经确定:继 DeepSeek 之后,另一家中国实验室已经将“稀疏注意力 + 长上下文 + 开放权重”组合成了一套成熟的方案。在 2026 年下半年,开源领域的 1M 上下文很可能从卖点转变为基础配置——而这一点本身,比任何单项基准测试结果都更重要。
参考文献
- Skyler Miao (MiniMax 研发负责人), 原文 tweet: Something BIG is coming
- 社区总结: MiniMax details its M3 sparse attention architecture
- MiniMax 博客: Why Did M2 End Up as a Full Attention Model?
- DeepSeek NSA 论文: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
- DeepSeek V3.2 DSA 撰文: Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA
- Sebastian Raschka: A Technical Tour of the DeepSeek Models from V3 to V3.2
- MiniMax-01 技术报告: Scaling Foundation Models with Lightning Attention






