
Google Nano Banana 2 Lite(即 gemini-3.1-flash-lite-image API 端点)是一款专为快速应用部署而打造的轻量级、高速 AI 工具。它是目前最具性价比的 Google 图像 API。它能在 4 秒内将文本转化为图像,非常适合需要大规模快速生成图像的企业级应用。

对于开发高并发应用的工程师来说,等待数百个自动图像生成任务的队列清空是一个令人筋疲力尽的瓶颈。当平台需要实时动态渲染数千个本地化广告变体、用户头像或快速网页原型时,依赖高端创意模型会迅速推高生产成本并拖慢用户体验。高延迟和高昂的单图费用往往迫使开发团队必须在应用性能和月度运营预算之间做出妥协。
Google 通过其创意模型系列的最新成员解决了这一痛点。通过根据明确的工作负载需求划分性能层级,开发者现在可以在不为冗余渲染能力支付溢价的情况下,优化高频资产生成流程。该解决方案是一种专为快速程序化部署而设计的专用轻量级图像生成模型。
满足对最实惠 Google 图像 API 的需求
对于运行高容量视觉工作流的工程团队而言,传统的图像生成 API 带来了重大的财务挑战。当扩展到数百万次自动 API 调用时,每张图像花费数美分的成本将变得难以为继。这种经济门槛加剧了对真正的最实惠 Google 图像 API 的需求,要求其能够处理批量请求且不引入巨大的基础设施开销。
gemini-3.1-flash-lite-image 模型的推出,通过降低经济门槛改变了程序化图像生成的架构。该架构不再将每个视觉请求视为高端艺术资产,而是将高频图像生成视为一种基础工具。这使得软件工程师能够将流畅的实时图像创作直接嵌入到多租户应用和互动社交软件中,从而将成本效率作为核心运营指标。
Nano Banana 2 Lite 性能基准深度解析
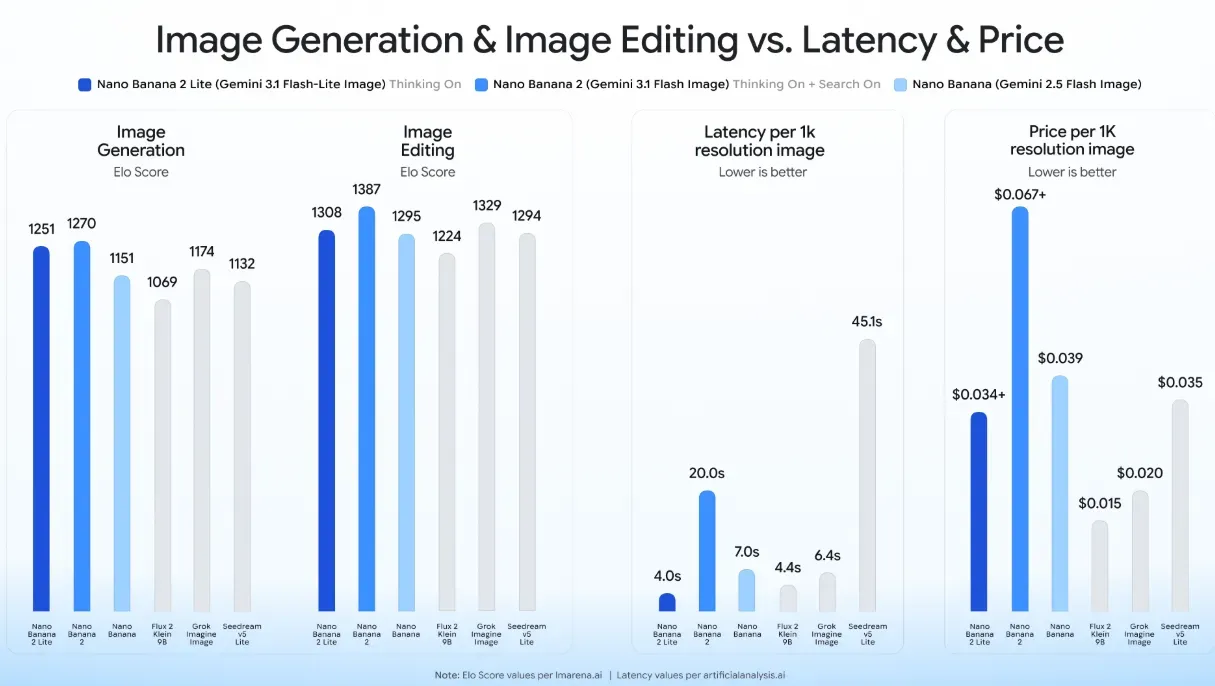
这一追求效率的模型层级的商业代号为 Nano Banana 2 Lite。该模型专注于最大化处理吞吐量并最小化响应开销。实际测试和官方规格显示,该模型的文生图延迟低至 4 秒。这种快速反馈较标准模型层级提升了约 5 倍的速度,将开发工作流从异步队列式操作转化为同步、近乎实时的用户体验。
Nano Banana 2 Lite 性能指标
| 参数维度 | 官方规格/指标 | 说明与操作范式 |
| 支持的模态 | 输入:文本、图像、视频;输出:文本、图像 | 不支持音频;视频仅支持输入。 |
| 上下文窗口限制 | 最大输入:65,536 tokens;最大输出:4,096 tokens | 针对高频、快速的应用逻辑进行了优化。 |
| 核心能力 | 图像生成、图文交错、图像编辑、多轮图像编辑 | 不支持视频输入生成图像。 |
| 输出分辨率 | 严格 1K(约 100 万像素) | 每生成 1K 图像消耗 1,120 个输出图像 token。 |
| 支持的宽高比 | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | 完全覆盖标准电商、社交媒体和横幅广告布局。 |
| 单条提示词限制 | 最大输入图像:14 张/提示词;最大输出图像:限制为 32,768 个输出 token | 文件数量最终受限于 65,536 tokens 的上下文窗口。 |
| 多模态 Token 成本 | 输入图像:1,120 tokens/张;输入视频:70 tokens/秒(以 1 fps 采样) | 文本输入和输出模态将产生额外费用。 |
| 并发保障 | 支持预留吞吐量 (Provisioned Throughput) | 对企业平台在峰值负载下保障 4 秒延迟至关重要。 |
Nano Banana 2 Lite 较传统模型的性能提升源于重大的架构更新。与旧款 gemini-2.5-flash-image 模型相比,新的 Lite 变体具备以下技术优势:
- 世界知识整合: 该模型对地点、物理结构和抽象空间布局具有高度准确的上下文理解,使其在快速 UI/UX 线框图制作方面表现出色。
- 角色一致性: 它能在序列生成中保持稳定的角色身份和结构对象细节。这使得工程师能够为电商平台构建迭代式故事板软件或程序化虚拟试穿功能。
- 内嵌排版与本地化: 系统能直接在生成的图形中呈现清晰易读的文本。这使开发者能够即时构建针对不同地理市场定制的自动广告变体。
解码 Nano Banana 2 Lite API 定价与 Token 机制
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | 标准价格 (每 1M tokens,输入 <= 200K) |
| 输入 (文本、图像、视频) | USD0.25 |
| 文本输出 (响应与推理) | USD1.50 |
| 图像输出 | USD30 |
了解运营成本需要深入审视底层 Token 结构,而非仅仅参考宽泛的营销平均值。虽然行业宣传通常列出约 USD0.034/1,000 张图像的统一费率,但 Google 的实际计费结构依赖于精确的多模态 Token 基础设施。Nano Banana 2 Lite API 定价在付费层级的具体费率分为不同的交易机制。
在使用 Google AI Studio 或 Gemini Enterprise Agent Platform 的标准付费层级下,文本、图像或视频输入成本为每百万 token USD0.25。文本输出和结构推理 token 费率为每百万 token USD1.50。生成标准 1K 分辨率图像(约 100 万像素)时,系统处理的固定输出负载折合每百万图像输出 token USD30.00。这直接对应每张图像 USD0.0336 的确切成本。
此外,工程师可以通过利用异步批量执行实现巨大的预算优化。Google 为 24 小时窗口内处理的非紧急批量请求提供 50% 的折扣。这使 1K 分辨率图像的成本降至惊人的 USD0.0168,成为后台资产生成的首选。
架构对比:Google 创意模型家族
为了在生产栈中选择最高效的模型,对比 Google 整个创意图像系列的性能和成本结构非常有益。每个模型变体针对不同的操作阈值,要求开发者将特定应用需求与正确的 API 端点相匹配。
| 指标/功能 | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
| API 模型 ID | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| 输入 Token 价格 | USD0.25 / 1M tokens | USD0.50 / 1M tokens | USD2.00 / 1M tokens |
| 输出图像 Token 价格 | USD30.00 / 1M tokens | USD60.00 / 1M tokens | USD120.00 / 1M tokens |
| 标准 1K 图像成本 | USD0.03 | USD0.07 | USD0.13 |
| 批量 1K 图像成本 | USD0.02 | 不适用 | 不适用 |
| 平均延迟 | ~4 秒 | ~6–8 秒 | ~10–12 秒 |
| 主要劣势 | 严格 1K 分辨率上限;处理高密度复杂文本时表现较弱。 | 后台大规模操作缺乏原生批量定价折扣。 | 高交易延迟和高昂的输出成本限制了其在高并发循环中的使用。 |
| 最佳生产场景 | 高容量流水线、实时应用交互、本地化横幅广告。 | 需要深度对话式图像编辑的中端应用。 | 电影级资产创作、复杂图形设计、最高文本保真度。 |
SDK 快速集成脚本 (gemini-3.1-flash-lite-image)
将 Google AI Studio 图像生成集成到现有应用流水线中,可以直接通过原生的 Google GenAI SDK 完成。以下代码块演示了如何初始化客户端、配置程序化参数,以及安全地执行针对 gemini-3.1-flash-lite-image 端点的异步文生图请求。
Python
plaintext1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str):""" 6 初始化 Google GenAI 客户端并执行低延迟文生图请求 7 使用成本优化型的 gemini-3.1-flash-lite-image 模型。 8 """# 初始化客户端;需设置 GEMINI_API_KEY 环境变量 9 client = genai.Client() 10 11 print(f"Sending generation request for model: gemini-3.1-flash-lite-image") 12 13 try: 14 response = client.models.generate_images( 15 model='gemini-3.1-flash-lite-image', 16 prompt=prompt_text, 17 config=types.GenerateImagesConfig( 18 number_of_images=1, 19 output_mime_type="image/jpeg", 20 aspect_ratio="1:1", # 支持 1:1, 16:9, 4:3 等标准宽高比 21 person_generation="ALLOW_ADULT" 22 ) 23 ) 24 25 # 处理并保存生成的图像载荷for i, generated_image in enumerate(response.generated_images): 26 image_bytes = generated_image.image.image_bytes 27 full_path = f"{output_path}_asset_{i}.jpg"with open(full_path, "wb") as f: 28 f.write(image_bytes) 29 print(f"Successfully saved 1K image asset to {full_path}") 30 31 except Exception as e: 32 print(f"API Execution failed: {str(e)}") 33 34if __name__ == "__main__": 35 prompt = "A professional product mockup of a sleek desktop companion robot on an office desk, clean lighting" 36 generate_bulk_asset(prompt, "output_production")
当大规模部署此脚本时,安全性和合规层由基础设施自动处理。Google 默认会在每张输出图像的元数据中嵌入不可察觉的 SynthID 水印和结构化的 C2PA 内容凭据。这确保了通过流水线生成的所有程序化资产均可追溯且符合企业合规要求,无需额外的后处理脚本。
通过统一 API 层实现生产环境的未来保障
虽然调用 Google 原生 SDK 在隔离环境中表现出色,但跨多租户企业应用扩展此文生图工作流通常需要统一的 API 管理层。
基础设施和编排平台(如 Atlas Cloud)已通过为该特定模型变体提供生产就绪的集成路径,正式将此流水线去中心化。通过专属的 Atlas Cloud Nano Banana 2 Lite 文生图/编辑模型 中心,开发者现在可以通过统一的 API 基础设施路由其高频视觉工作流。
通过 Atlas Cloud 等中心进行连接,你的开发团队可以结合该模型 4 秒快速生成工具以及其他模型的备选方案。它还提供了一个统一的平台用于查看使用统计信息和简化计费,无需在主服务器中添加冗杂的额外代码。
故障排除:常见 API 错误代码与速率限制
当你扩展应用以处理数万次图像并发请求时,必然会遇到服务器或客户端限制。平滑处理这些交通拥堵情况可以防止应用崩溃,并保持用户体验的顺畅。
处理 429 Too Many Requests
在忙碌的应用运行期间,最常见的错误是 429 Too Many Requests 消息。这意味着应用超过了分配给常规 Google AI Studio 开发账户的共享速率限制。为解决此问题,开发者应在请求循环中构建带有抖动(jitter)的指数退避算法,当捕获到 429 状态时延迟后续 API 调用。对于需要保证容量的企业级操作,工程师可以转向 Gemini Enterprise Agent Platform 内的预留吞吐量(PT)安排,从而获得专用硬件分配以确保持续吞吐量。
解决 400 Invalid Argument 和 403 Forbidden 错误
400 Invalid Argument 错误通常意味着视频设置的尺寸或宽高比错误。Lite 计划非常严格,仅允许 1K 视频输出。确保宽高比符合 1:1 或 16:9 等标准尺寸。
相反,403 Forbidden 错误意味着 API 密钥问题或安全拦截。Google 使用自动过滤器检查所有文本。如果提示词违反这些安全规则,系统将拦截输出。你需要重写文本以符合平台准则。
开发者现实:原生集成低预算图像工作流
部署预算优化模型意味着必须承认其实际局限性。由于该模型的架构专为极致速度和低成本而调优,因此做出了明确的权衡:
- 硬性的 1K 分辨率上限意味着它无法生成原生的 4K 印刷级图形。
- 此外, 当面对包含密集结构层的高度复杂提示词时,模型在跨越差异巨大的场景转换时偶尔会出现角色一致性波动。
为了在不增加运营成本的情况下缓解这些缺点,你可以将生成流水线串联成多轮编辑工作流。
与其试图在第一次尝试时就生成完美且极其复杂的场景,不如编写应用逻辑来生成快速的 4 秒基础草稿。在此基础上,使用对话式图像编辑请求来程序化地修改、重新布光或替换资产中的特定对象。
对于高级多媒体应用,此 1K 图像输出可以直接输入到视频生成流水线,例如 Gemini Omni Flash,该模型以 USD0.10/秒的实惠价格处理视频编辑任务。
Nano Banana 2 Lite 适合你的技术栈吗?
为了简化架构评估,以下是 Nano Banana 2 Lite (gemini-3.1-flash-lite-image) 能带来最高 ROI 的开发团队画像,以及哪些人应该考虑使用标准高级层级。
该模型最适合谁?
- 高并发应用开发者: 如果你的软件每分钟处理数千次自动 API 请求,例如实时用户头像生成器、即时动态广告生成器或批量电商产品放置系统,那么此模型就是专门为你设计的。
- 注重成本的软件工程师: 目标为微预算工作流且运营开支是核心生存指标的团队。利用其 USD0.0168 的批量层级,可以有效消除标准溢价财务瓶颈。
- 互动应用架构师: 对同步循环有严格要求且用户需要近乎实时反馈的应用,将极大地受益于其低于 4 秒的生成速度。
谁应该避免使用此模型?
- 高保真图形设计师: 如果你的应用依赖于渲染大规模印刷图形、原生 4K 分辨率横幅或复杂的电影级营销素材,硬性的 1K 分辨率上限将限制你的创作输出。
- 文本密集型视觉营销人员: 虽然该模型支持内嵌排版,但如果应用需要将密集、超复杂的布局文本原生嵌入图像内,建议使用 Gemini 3 Pro Image 层级以保持绝对的文本保真度。
- 音频驱动的多媒体构建者: 依赖严重依赖音频同步或直接从连续实时音频流生成图像的高级多模态循环的团队,建议另寻他路,因为该特定的 Lite 层级不支持音频输入。
常见问题解答
gemini-3.1-flash-lite-image 相比标准层级如何降低开发者成本?
该模型相比标准的 gemini-3.1-flash-image 模型,将标准开发者成本直接削减了 50%。通过将 token 足迹优化至每百万输入 token USD0.25 和每百万图像输出 token USD30.00,标准付费层级下 1K 分辨率图像的价格降至 USD0.0336。对于非紧急后台任务,使用批量 API 可将此费率进一步降至每张图像 USD0.0168。
Nano Banana 2 Lite 能处理高并发企业应用负载吗?
是的,该模型专为处理高并发企业需求而构建。虽然标准开发者层级共享公共基础设施池,但企业团队可以通过 Gemini Enterprise Agent Platform 部署预留吞吐量(Provisioned Throughput)来确保专用、高度可靠的性能。这完全绕过了标准的共享速率限制,并确保在峰值流量窗口期间保持稳定的 4 秒生成速度。
最实惠的 Google 图像 API 是否在安全或内容跟踪方面进行了妥协?
成本优化并不会移除企业级安全功能或合规机制。模型生成的每张图像默认在像素阵列中自动包含原生的 SynthID 水印以及标准的 C2PA 内容凭据。此元数据允许企业平台在 AI 生成资产进入公开应用前,保持透明的跟踪并彻底验证其真实性。






