
OpenAI 最新的图像生成模型 GPT-Image-1.5 在可控性、视觉保真度和多模态集成方面迈出了重要一步。与早期的独立扩散模型不同,GPT-Image-1.5 深度整合到了更广泛的 GPT 生态系统中,使开发人员能够利用自然语言以更高的精度和一致性来生成、编辑和迭代图像。
在本指南中,我们将解析:
- 什么是 GPT-Image-1.5
- 它与以往图像模型有何不同
- 如何有效使用 API
- 生产工作流示例
什么是 GPT-Image-1.5?
OpenAI 刚刚发布了一款全新的图像模型,名为 GPT‑Image‑1.5。其核心理念是通过 API 为您提供高质量、可控的图像生成能力。该模型专为实际业务场景打造,而不仅仅用于实验。
它还存在于 OpenAI 更广泛的技术架构中,因此能与他们的文本模型(便于生成提示词)和视觉模型(用于理解图像)无缝协作。您还可以将其接入自动化工作流,如智能体、管线或 SaaS 工具。
核心功能 – OpenAI 官方说明
- 具有强大提示词对齐能力的文本转图像生成
- 基于指令的编辑——通过向模型发出指令来修改现有图像
- 迭代优化工作流——生成、调整、再生成
- 多次运行之间具备更好的一致性

实际有哪些改变
1. 从创意导向转向可控导向
旧模型极具创造力但不可预测,你永远不知道会得到什么结果。新模型生成的输出更结构化,且更能忠实执行提示词。
2. 从单一输出转向迭代工作流
旧版本鼓励生成一张"最终"图像便告结束。GPT‑Image‑1.5 专为循环流程而设计:生成、编辑、细化、扩展。
3. 从演示工具转向生产基础设施
这一点至关重要。该模型专为实际工作负载而设计,如电子商务图像管线、营销创意自动化、AI 驱动的设计工具,而不仅仅是用于展示作品。
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| 功能 | GPT-Image-1.5 | DALL·E |
| 提示词准确度 | 高 | 中 |
| 编辑能力 | 强 | 有限 |
| 一致性 | 高 | 低 |
| 工作流支持 | 可用于生产 | 侧重演示 |
| API 集成 | 原生 | 有限 |
为什么开发者应当关注
您可能之前遇到过以下问题。
首先,迭代耗时太长。
生成一张图像后,效果虽然接近但色彩不对,或者背景错误。使用旧模型,您必须从头开始重新生成,这既浪费时间又消耗 API 配额。GPT‑Image‑1.5 允许您直接编辑:更改颜色、替换背景,并保持其他元素不变,从而大幅缩短迭代时间。
其次,提示词被忽略。
您编写了详细的描述,但模型只完成了一半,或者添加了您从未要求的内容。这款模型非常注重指令。虽然并非完美,但改进显著。对象关系得以保留,场景构图符合您的说明,风格提示词也真正起效了。
第三,扩展时一致性难以维持。
生成同一产品的十张图像,它们看起来就像出自十位不同的摄影师之手:光线变化、角度偏移、色彩漂移。这对于电子商务和品牌塑造工作是致命的。GPT‑Image‑1.5 经过专门训练以减少这种偏移,确保批量生成的输出看起来属于同一个系列。
第四,API 集成在许多工具中显得像是一种后加的功能。
独立应用程序非常适合把玩,但当您需要将图像生成接入后端系统时,Web UI 就毫无帮助了。GPT‑Image‑1.5 配备了完善的 API:身份验证、端点、速率限制、Webhooks。这些才是开发者真正需要的东西。
API 集成指南
Atlas Cloud 允许您并排测试多个模型。您可以从操场(Playground)开始,进行实验,观察效果,然后通过单一 API 调用一切。
方法 1:直接在 Atlas Cloud 操场中使用
开始使用 GPT-Image-1.5 最简单的方法之一是直接在 Atlas Cloud Playground 中使用它——这是一个专为开发者、设计师和营销人员设计的 Web 界面,无需编写任何代码即可实验 AI 图像生成。
方法 2:通过 API 访问
步骤 1:获取 API 密钥
在您的 控制台 中创建 API 密钥并复制备用。
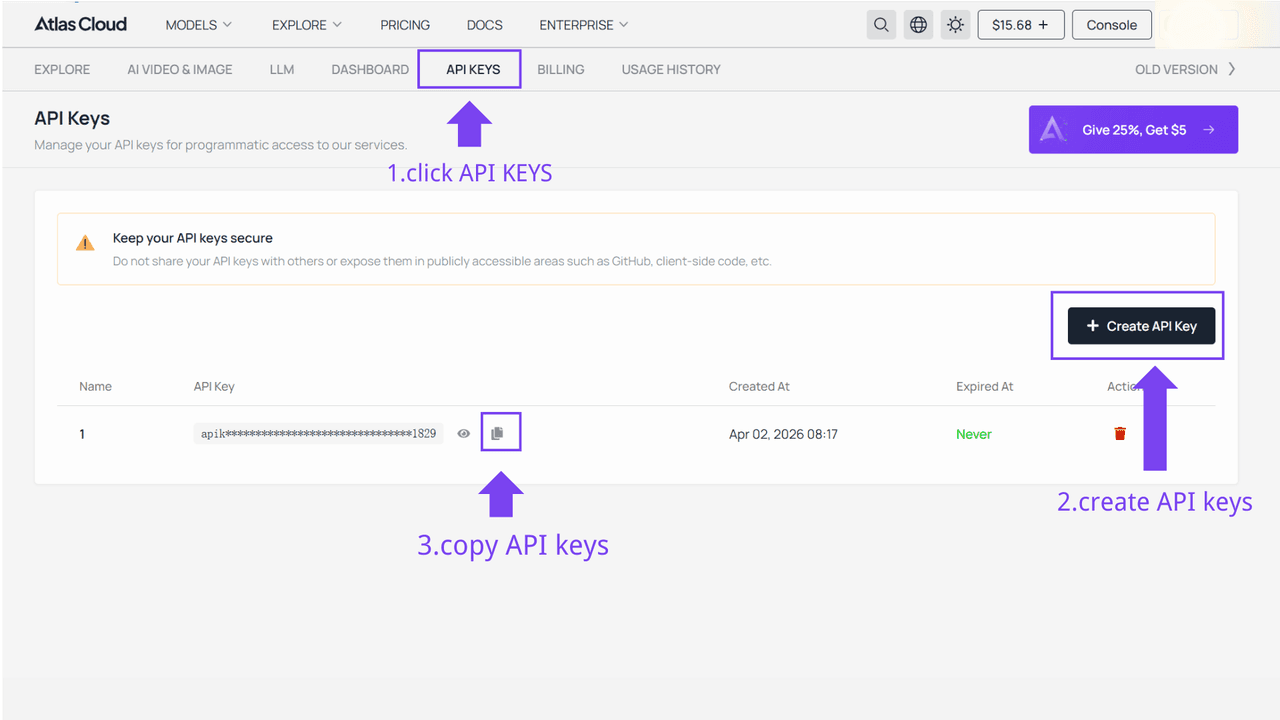
步骤 2:查看 API 文档
在我们的 API 文档 中查阅端点、请求参数和身份验证方法。
步骤 3:发送第一个请求(Python 示例)
以下是使用 OpenAI GPT-Image-1.5 生成图像的简单示例:
plaintext1import requests 2import time 3# 第 1 步:开始图像生成 4generate_url = "https://api.atlascloud.ai/api/v1/model/generateImage" 5headers = { 6 "Content-Type": "application/json", 7 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 8} 9data = { 10 "model": "openai/gpt-image-1.5/text-to-image", # 必需 11 "enable_base64_output": False, # 如果启用,输出将编码为 BASE64 字符串而非 URL 12 "enable_sync_mode": False, # 如果设为 true,函数将等待生成完成并上传后再返回响应 13 "output_format": "jpeg", # 输出图像格式。选项:jpeg | png 14 "prompt": "end-to-end AI image production pipeline, prompt generation, image creation, QA, deployment, SaaS workflow diagram\n\n", # 必需。生成的正面提示词 15 "quality": "medium", # 生成图像质量。选项:low | medium | high 16 "size": "1536x1024", # 生成媒体大小(宽*高)。默认:"1024x1024"。选项:1024x1024 | 1024x1536 | 1536x1024 17} 18generate_response = requests.post(generate_url, headers=headers, json=data) 19generate_result = generate_response.json() 20prediction_id = generate_result["data"]["id"] 21# 第 2 步:轮询结果 22poll_url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 23def check_status(): 24 while True: 25 response = requests.get(poll_url, headers={"Authorization": "Bearer $ATLASCLOUD_API_KEY"}) 26 result = response.json() 27 if result["data"]["status"] == "completed": 28 print("Generated image:", result["data"]["outputs"][0]) 29 return result["data"]["outputs"][0] 30 elif result["data"]["status"] == "failed": 31 raise Exception(result["data"]["error"] or "Generation failed") 32 else: 33 # 处理中,等待 2 秒 34 time.sleep(2) 35image_url = check_status()
生产工作流——整合一切
使用 GPT‑Image‑1.5 的专业团队通常遵循以下模式:
- 第一步:标准化提示词。一些团队利用 GPT 文本模型自动生成结构化提示词。
- 第二步:调用 API。生成图像。
- 第三步:自动化质量保证(QA)。检查风格一致性,标记劣质输出。
- 第四步:迭代循环。通过提示词编辑图像,生成变体。
- 第五步:部署。存储资产并将其服务于前端或最终用户。
常见问题解答
1. GPT-Image-1.5 与其他 AI 产品摄影生成器有什么不同?
大多数所谓的 AI 产品摄影工具只是套用了模板的开源模型。您上传一张白底背景图,选择一个场景,它将其缝合在一起。当然很快,但您无法调整细节。光线不对?没办法。阴影位置奇怪?只能忍受。
GPT‑Image‑1.5 则不然。它不提供预制模板,而是让您自己进行控制。您可以说"侧光,阴影落在右侧,背景虚化一点",它就会执行。缺点是什么?您需要学习如何编写合适的提示词。但一旦掌握,同一个提示词便可用于数百张图像。这就是为什么构建真实产品图像管线的团队更倾向于使用 OpenAI 的 API 构建自己的系统,而不是依赖那些"一键式"生成工具。
2. 什么类型的提示词最适合 OpenAI Text-to-Image API?
不要写得太简短,也不要写成长篇大论。最佳格式是将需求拆解:镜头里有什么、在哪里、如何布光、什么风格。
举个例子:如果您写"一把椅子",模型会给您随机生成一把椅子。如果您写"一把胡桃木休闲椅,放置在有大窗户的明亮客厅中,左侧柔和自然光,中世纪现代风格,构图简洁",结果会可靠得多。
模型无法读取您的想法。您必须将场景拆解并告知它。无论您是在制作产品照还是其他内容,只要这样做,就会看到显著的效果差异。
3. 使用 AI 产品摄影生成器相比传统摄影有什么优势?
速度是显而易见的优势。只要提示词准确,几分钟内就能输出几十个产品角度。而传统拍摄此时可能还在布光阶段。
真正的优势在于灵活性。通过常规摄影,更换背景意味着要进行全新的拍摄,灯光变化也是如此。使用 GPT‑Image‑1.5,您只需输入指令:"将背景改为砖墙"、"让光线变暖"、"把红色运动鞋变成蓝色"。一句话就能将静态图像变成可随时调整的内容。
此外还有一致性。在传统拍摄中,光线会漂移,不同照片间色彩会有轻微偏移。同一产品的十张照片拍出来可能像出自十位不同的摄影师。而使用模型,保持提示词不变,那十张照片看起来确实就像是一套图。对于电子商务或品牌推广而言,这比单纯的一张好看的照片重要得多。






