摘要
2026 年 5 月中旬,Qwen3.7-Max 和 Qwen3.7-Plus 在 LM Arena 悄然上线。@Alibaba_Qwen 以“阿里文本排名第 6,视觉排名第 5”的评价设定了社区预期。6 月 2 日,阿里云通义千问团队正式发布了这款多模态智能体模型。目前该模型已在阿里云百炼(Model Studio)和 Qwen Chat 上线,API 访问地址为 alibaba/qwen3.7-plus,定价约为每百万输入/输出 token USD0.40 / USD1.60。
官方定位十分明确:Plus 是高性价比的多模态模型;Max 是文本旗舰模型。
我们花了一个下午的时间对 Qwen3.6-plus、Qwen3.7-plus 和 Qwen3.7-Max 进行了硬核测试:自动修复 10 个真实 Bug、15 道 AIME 2025 数学竞赛题,并对比了多模态能力、速度和成本。
以下结论基于 5 个任务层面的观察,而非通用的模型排名:
- BugFind-10 单次运行:Plus 通过了所有外部 pytest 检查。在该包含 10 个任务的套件、官方 Stirrup 框架及单次运行设置下,Plus 得分为 10/10,而 Max 和 3.6-Plus 得分为 9/10。这表明该模型在当前设置下表现良好,不应盲目推导为通用的编码排名。
- 数学能力:开启思考模式(Thinking)后,Plus 的单次运行得分与 Max 持平。在 15 道竞赛级数学题中,Plus 和 Max 均答对 14 道;在此次运行中,Qwen3.7-plus 的单题耗时远低于 Qwen3.7-Max(平均 113 秒 vs 303 秒)。
- 速度实现代际跨越:在智能体任务中,Qwen3.7-plus 的端到端吞吐量达到 147.5 t/s,而 Qwen3.6-plus 仅为 41.5 t/s,提升了 3.55 倍。上一代无法完成的数学任务现在变得轻松可解。
- 多模态仍有缺陷:在对照多模态测试中,Qwen3.7-plus 正确回答了简单图片问题,但对官方示例图片 dog_and_girl.jpeg 的描述却出现了“一列火车和一群人”的错误。
- 部分能力接近 Max,且具备延迟优势:在本次的多项测试中,Qwen3.7-plus 取得了接近 Qwen3.7-Max 的结果,同时延迟更低。这并非通用的排名结论。
以下是完整的测试数据、方法论以及给工程负责人的模型选型建议。所有比较均限于此小样本、单次运行及固定框架环境。
0. 模型能力与排行榜背景
阿里云 Qwen 的产品线在 3.6 代时已形成模式:Max = 文本旗舰,Plus = 多模态长上下文模型。3.7 版本延续了这一逻辑:
| 维度 | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| 输入模态 | 以文本为主 | 文本 + 图像 |
| 典型卖点 | 推理上限、长距离智能体 | 1M 上下文、视觉、混合思维、更低单价 |
| Arena (2026-05) | 文本排行榜约第 13 名 | 视觉排行榜约第 16 名 |
| 网关价格 (06-01) | 每百万 USD1.25 / USD3.75 | 每百万 USD0.40 / USD1.60 |
1. 官方如何定位 Plus?
阿里云 Qwen 的发布推文 将信息浓缩为一句话:
“一个模型。能看、能想、能写代码、能执行。”
其核心卖点是:结合 GUI 和 CLI 操作的统一多模态交互混合智能体、通用编码智能体,以及跨智能体框架的泛化能力。Qwen 核心开发人员 shuai bai_ 进一步解释道:
我们的目标是将多模态 AI 从被动的图像描述转向主动的问题解决者:它能观察、推理、编写代码、操作界面并验证结果。这是迈向真正具有智能体特性的多模态智能的一步。
官方帖子的性能数据给出了关键定位:
- 文本性能“接近 Max 水平”(厂商说法)
- 多模态改进侧重于核心智能体能力:复杂的视觉理解、视觉推理、工具使用以及代码/GUI 执行
| X 平台常见观点 | 来源 | 我们的结果 | 结论 |
|---|---|---|---|
| Plus 文本“接近 Max” | 官方 | 开启思考模式的 AIME:得分相同 14/15;Plus 快 2.68 倍 | 数学单次运行分数相同;在此次运行中延迟更低 |
| Max 更适合编码/长程工作 | Vercel 文档 | BugFind:Plus 10/10,Max 9/10;Plus 147.5 t/s | 该任务不支持盲目套用该假设 |
| 视觉排行榜表现强劲 | Arena | 官方示例图片失败;对照图片测试 ✓ | 高排名与单张图片失败可以并存 |
2. 我们的评估方法:四类任务与一条铁律
为保持测试公正,我们维护了一个名为 BugFind-10 的套件:涵盖价格计算、数组边界、路径处理、并发、JSON、SQL、缓存行为、Unicode、配置等 10 个真实 Bug。每个 Bug 均配有 pytest 测试。模型必须在官方 Stirrup 智能体框架内运行,利用本地代码执行工具自主完成全流程:“复现 → 定位 → 修改生产代码 → 运行测试”。
为什么要建立自己的测试套件?
公共排行榜通常存在三个缺陷:
- 记忆与泄露:旗舰模型在旧问题上已经饱和。我们选择了 AIME 2025,该竞赛发布于模型可能的训练截止日期之后。
- 厂商自测可能与独立复测存在偏差:同一指标会随数据集版本、是否开启思维模式及是否允许使用工具而大幅波动。
- 智能体基准测试依赖于脚手架:不同的智能体框架可能导致得分偏离 2-3 个百分点。我们将框架固定为官方 Stirrup 并增加了外部验证。
四大测试任务
| 任务 | 衡量内容 | 核心指标 |
|---|---|---|
| Gate check | 身份确认、思维支持、视觉能力 | 通过 / 失败 |
| BugFind-10 | 10 个真实代码 Bug 的自动修复 | 外部 pytest 通过率、模型调用次数、墙上时间 |
| AIME 2025 I | 15 道竞赛数学题 | 准确率、单题耗时、思维消融实验 |
| Quick Eval | 8 道小学数学应用题 | 速度基准、首字延迟(TTFT)、简单任务的思维收益 |
我们的铁律:代码得分仅以外部 Pytest 为准
这是本次测评的基础。它直接回应了 Hacker News 的担忧:智能体自称“测试通过”是不够的。
流程:
- 智能体在工作区修改代码、自行运行 pytest 并编写 CHANGELOG。
- 我们将修改后的生产代码复制到隔离环境中,独立运行 pytest。
- 我们仅发布第 2 步的退出代码和失败堆栈。
类比:智能体是考生。我们不仅要看它交上来的答案,还要把答案拿进另一个房间重新批改,而不是盲目信任它的自测结果。
3. 代码与智能体能力
三个模型的对比概览
| 模型 | pytest 结果 | 修复率 | LLM 调用次数 | 墙上时间 | 端到端 t/s |
|---|---|---|---|---|---|
| Qwen3.6-Plus | 1 失败,26 通过 | 9/10 | 63 | 334s | 41.5 |
| Qwen3.7-Plus | 27 通过 | 10/10 | 52 | 205s | 147.5 |
| Qwen3.7-Max | 1 失败,26 通过 | 9/10 | 20 | 249s | 51.8 |
Plus 获得更好的单次运行 BugFind 结果出乎意料:
- Plus 是本次测试中唯一获得 10/10 的模型。
- Max 使用了最少的调用次数,但未获得满分。 3.7-Max 在 20 次模型调用后即停止,是三者中最少的。它倾向于“长时间思考并进行一次大规模修改”,迭代次数较少。相比之下,3.7-Plus 使用了 52 次调用,愿意不断进行编辑、运行、检查反馈并再次编辑。
- Plus 的墙上时间最短且吞吐量最高。 对于 IDE 智能体体验而言,这比排行榜上的几个 Elo 点数重要得多。
一个任务,三种修复哲学:task05 深入剖析
此任务测试的是:无效 JSON 不能被静默吞掉。当解析发现错误数据时,不能伪装成功并返回空对象,而必须清晰报错。原始 Bug:
plaintext1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # Bug: 吞掉了异常
测试要求:
- 对于输入如 "this is not json {",函数不得返回空字典 {}。
- 对于没有大括号的无效输入,如 "bad",必须抛出异常。
Max 的做法(外部测试 ✗):抛出自定义 JSONParseError。
这看起来是一个干净的解决方案,但对于 "this is not json {",它立即抛出异常,导致测试在第一个断言运行前就失败了。然而 Max 的 CHANGELOG 却自信地写道“27 个测试通过”。这正是外部验证强制执行的原因:智能体的自我评估与外部审计往往大相径庭。
3.6-Plus(外部 ✗):在相同的第一个障碍上失败。
3.7-Plus(外部 ✓):
plaintext1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"Invalid JSON: {e}") from e
对于包含大括号的畸形输入,它返回一个与 {} 可区分的错误对象。对于根本没有大括号的输入,它会抛出异常。它精准地满足了测试合同的两端。
为什么 Max 在此任务上没能拿到满分?从调用次数来看:

3.7-Max 在 20 次调用后停止。它倾向于“长时间思考并进行一次大幅修改”,迭代较少。3.7-Plus 使用了 52 次调用,并愿意反复迭代。在需要与环境反复交互的智能体编码任务中,更多次的迭代有助于覆盖边缘情况。这指出了一个常被忽略的事实:在智能体任务中,“深度推理”并不等同于更稳定的产出。善用工具反馈同样重要。
在修复质量方面,三个模型在 task03 上都表现不错。该任务直接将 user_id 连接到文件路径中,因此 ".." 可能导致路径遍历,而 "user;rm -rf" 可能携带 Shell 元字符。修复增加了白名单过滤,识别出了真实的安全性缺陷,而不是为了测试通过而盲目补丁:
plaintext1user_id = re.sub(r'[^a-zA-Z0-9_-]', '', user_id) or "unknown"
工程启示:
- 对于智能体任务,与环境博弈的意愿(Plus 进行了 52 次对话和 98 次代码执行)比最小化迭代更重要。
- Max 在 20 次转折后停止,过早地认为 task05 已解决。
- 在交互式 Bug 修复中,干净的“抛出异常”并不总是比返回可区分的错误数据更有用。
4. 推理与数学:思维模式是一个成本决策
Qwen3.7 系列强调“混合思维”,通过 enable_thinking 开关控制。该开关值得开启吗?我们针对两个难度截然不同的任务组进行了消融实验。硬核组是 AIME 2025 I,这是一项发布于模型可能训练截止日期后的竞赛。我们通过 AoPS 和 Areteem 两个独立来源核对每个问题和答案,然后自动评分。
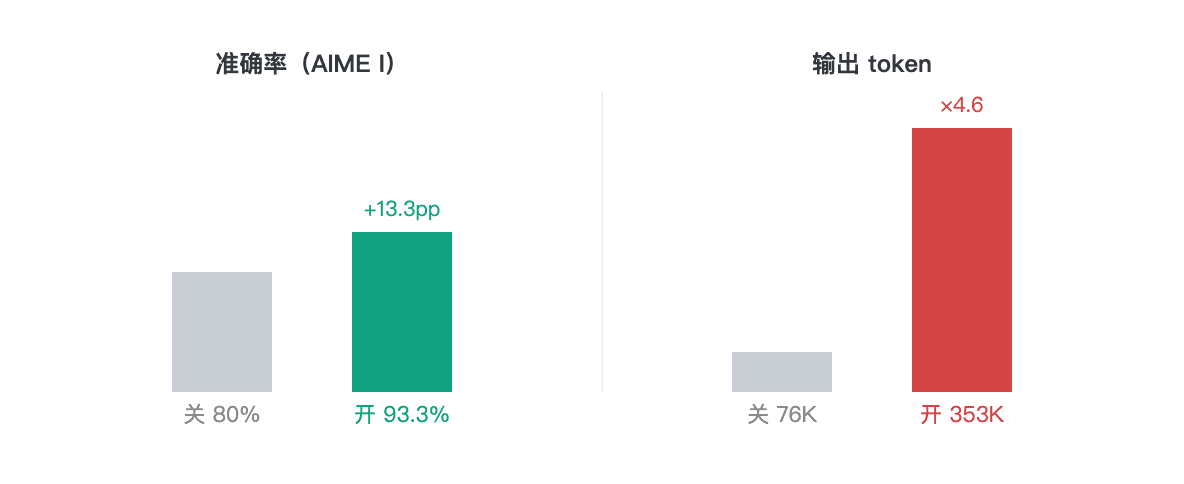
| 模型 / 模式 | 准确率 | 平均单题耗时 | 输出 Token |
|---|---|---|---|
| 3.7-Plus · 关闭思维 | 12/15 (80%) | 24.7s | 76,502 |
| 3.7-Plus · 开启思维 | 14/15 (93.3%) | 113.4s | 353,424 |
| 3.7-Max · 开启思维 | 14/15 (93.3%) | 303.1s | 307,801 |
| 3.6-Plus · 思维模式 | 前 6 题:6/6 | 464s | 25.7K/题 |
成本对比:
| 配置 | 正确数 | 准确率 | 平均单题耗时 | 总输出 Token | 平均 tps | 预估成本 |
|---|---|---|---|---|---|---|
| Plus 关闭思维 | 12/15 | 80.0% | 24.7s | 76,502 | 204.0 | USD0.15 |
| Plus 开启思维 | 14/15 | 93.3% | 113.4s | 353,424 | 205.4 | USD0.69 |
| Max 开启思维 | 14/15 | 93.3% | 303.1s | 307,801 | 68.3 | USD0.60 |
注:预估定价依据 3.6-Plus 每百万 USD0.325/USD1.95 计算。官方网关价格 USD0.40/USD1.60 更接近生产环境定价。
思维开关的边际收益
开启推理模式后,Plus 在 AIME 单次运行中达到了与 Max 相同的分数。 3.7-Plus 和 3.7-Max 均答对 14/15,但 Plus 的单题耗时为 113 秒,而 Max 为 303 秒。在此次运行中,Max 更长的延迟并未带来更高的分数。
在 8 道小学数学应用题中,两种模式均达到了 100% 正确率。开启思维仅增加了 24% 的 Token 消耗。综合来看结论清晰:
简单任务关闭思维模式以节省成本;困难任务开启思维模式以获取准确性。 全局开启推理意味着在简单请求上持续支付 4 倍以上的费用,且准确率毫无提升。该开关的价值在于支持根据任务难度动态路由。
Max vs Plus:此次运行的延迟来源
Max 也答对了 14/15,且也未答对 I-14(预测 69,正确答案 60)。相同的测试,相同的错题,相同的失败模式,而非“Max 更聪明并答对了另一道难题”。Max 确实答对了 I-15,而 Plus 漏掉了,因此在极难问题上存在方差,单次运行不能断言模型全局更强。
但速度差距显著。在问题 I-2 上,Max 耗时 261 秒;Plus 仅耗时 108 秒。在整个测试集中,Max 的平均速度为 68.3 tps,而 Plus 为 205.4 tps,约快 3 倍。
结论:开启思维模式后,Plus 在此竞赛数学集上的得分与 Max 持平,且在延迟和成本上具有明显优势。对于实时交互场景,这种差异至关重要。
简单任务控制
我们使用 8 道小学数学应用题作为简单负载测试:
| 模式 | 准确率 | 平均耗时 | 总输出 Token |
|---|---|---|---|
| 关闭思维 | 8/8 | 2.17s | 2,314 |
| 开启思维 | 8/8 | 2.48s | 2,881 |
开启思维消耗了 24% 的额外 Token,但准确率没有提升。难度是决定是否开启思维模式的唯一合理标准。
5. 速度、代际差异及我们被迫终止的一项任务
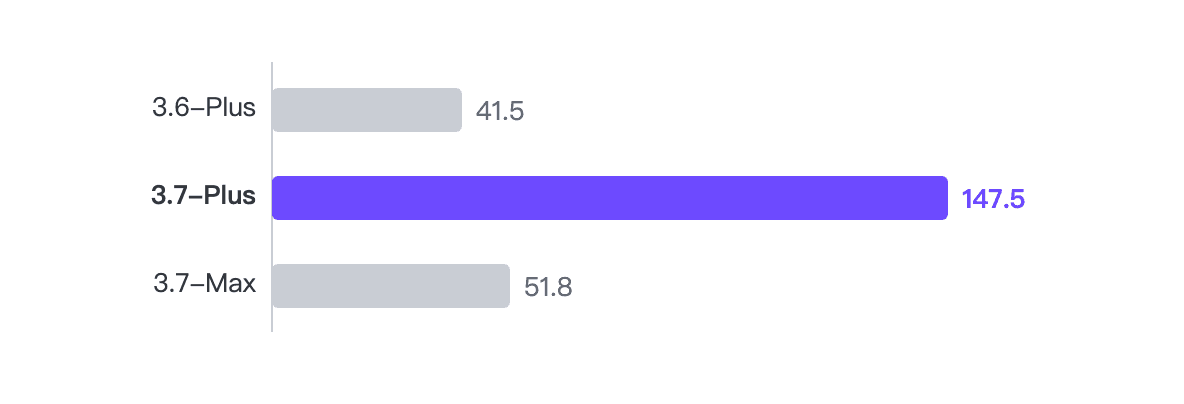
智能体吞吐量对比
从 BugFind runner_summary.json 提取的真实端到端速度:
- 3.7-Plus: 147.5 t/s (52 次调用, 204.8s)
- 3.7-Max: 51.8 t/s (20 次调用, 249.0s)
- 3.6-Plus: 41.5 t/s (63 次调用, 334.5s)
代际提升(3.6 → 3.7 Plus)约为 3.55 倍。同代 Plus 与 Max 相比约为 2.85 倍。
代际差距最典型的例子来自 3.6-Plus 的数学运算。我们本想加入它的 AIME 结果,但它太慢导致无法完成:推理过程在每个问题上都达到了上限,单题输出达到 16K-52K Token,每题耗时 297-932 秒。仅前 6 道题就耗时 46 分钟。在任何合理的时间预算内完成 15 题测试都是不可行的,因此我们终止了该进程。
我们尝试通过将 max_tokens 从 16000 降至 4096 来“限时”。结果失败了。 这是一个值得记录的工程陷阱:
- 在思维模式下,推理 Token 不受 max_tokens 限制;模型仍可能输出数万个推理 Token。
- 请求超时设置也不够。OpenAI/httpx 的超时是数据流之间的“读取超时”。只要流式响应持续输出 Token,该超时永远不会触发。
两种超时路径都被堵死,我们强制终止了进程并记录了已完成的前 6 题:6/6 正确。这意味着 3.6-Plus 的数学能力本身没问题,但**“能解决”与“在用户能忍受的时间内解决”是两个不同的主张**。对于必须响应用户的生产模型,后者往往更重要。这正是排行榜经常隐藏但用户体验会暴露的维度。
给工程团队的建议:对于思维模型,传统的超时和 max_tokens 策略可能会失效。你需要设定总 Token 预算、总墙上时间上限或推理 Token 上限。
6. 核心发现四:多模态 - 对照图片通过,官方样本失败
| 测试样本 | 输入 | 模型输出 | 判断 |
|---|---|---|---|
| 对照图片 | 红/蓝色块 PNG (本地) | "blue, orange" | ✓ 正确 |
| 官方样本 | dog_and_girl.jpeg (OSS) | "a group of people standing beside a train..." | ✗ 完全错误 |
Arena Vision 视觉榜单将 Plus 排在第 16 名左右(预览版)。该基准测试衡量的是人类偏好下的图文对话能力。我们的测试表明,高排行榜分数与单张图片失败可以并存。
模型选型建议:我们未运行 MMMU 或 ChartQA 等标准化视觉基准,因此不对 Plus 的视觉是否达到生产级水平发表广泛主张。但发现很明确:运行自己业务领域(OCR、图表、UI 截图、收据)的 20-50 张图片,比阅读排行榜可靠得多。
一些 Hacker News 用户也测试了该模型,认为“Qwen 视觉强于 Gemma”。用户反馈并不矛盾,因为他们执行的是私有任务。官方示例图片失败提醒我们,私有场景的成功与官方示例的失败可以共存。模型选择必须由你自己的数据驱动。
7. 成本:本轮测试的耗费
本文本身就是一个成本样本。在四类任务上运行三个模型后,真实的 Qwen API 用量约为 200 万 Token(已停止的 3.6-Plus 部分未完全计算),预估成本约为 USD2-3。
本轮测试账单
| 项目 | Token 规模 | 预估成本 |
|---|---|---|
| AIME Plus 开启 | 353K 输出 | ~USD0.69 |
| AIME Plus 关闭 | 76K 输出 | ~USD0.15 |
| AIME Max 开启 | 308K 输出 | ~USD0.60 |
| BugFind × 三个模型 | 非常高的累计输入 | 计入总额 |
| 总计 | ~200 万 | USD2-3 |
洞察 1:严肃的评估成本约等于一顿饭钱。团队应该把钱花在重跑自己的任务上,而不是花在营销软文上。
洞察 2:智能体成本主要不在于单价,而在于轮次 × 每轮历史长度。BugFind 每个模型使用了 52-63 次调用,单轮输入可超过 11K Token。优化应针对历史压缩、子智能体拆解和缓存,而非仅仅寻找更便宜的模型定价。
思维模式的边际成本(以 AIME I 为例)
- 关闭思维:USD0.15 / 15 题 ≈ USD0.01/题
- 开启思维:USD0.69 / 15 题 ≈ USD0.046/题
两个额外的正确答案(I-9 和 I-14)成本为 +USD0.54。如果你的业务每天运行 1 万个中等难度问题,差距很容易达到每天数千美元。路由策略(初始不使用思维,当置信度低时再开启)在生产中是强制性的。
网关价格对比 (2026-06-01)
| 模型 | 输入 / 输出每百万价格 |
|---|---|
| qwen3.7-plus | USD0.40 / USD1.60 |
| qwen3.7-max | USD1.25 / USD3.75 |
Max 比 Plus 贵约 3 倍(输出端约 2.3 倍),而本次运行显示其 AIME 得分相同,BugFind 得分低一分。时间成本通常比 Token 成本更贵:工程师等待时间和占用的智能体槽位也是金钱。
8. 给开发者的模型选型建议
| 场景 | 建议 |
|---|---|
| 构建智能体 / 编码 / Bug 修复 | 将 3.7-Plus 加入候选集。此次单次运行表现为 10/10,具有高吞吐量和更多迭代;将 Max 作为文本旗舰/高难度任务的备选,不要仅凭旗舰标签选型。 |
| 中等难度推理或数学,且对延迟敏感 | 3.7-Plus 开启思维模式。在此次运行中,它以更低的延迟匹配了 Max 的准确性。 |
| 简单的问答 / 分类 / 提取 | 3.7-Plus 关闭思维模式。节省额外的推理成本。 |
| 仍在运行 3.6-Plus | 升级。核心的代际差距在于速度,3.5 倍的吞吐量足以改变用户体验。 |
9. 局限性与披露
本文是一个下午的深度快照,而非学术论文。以下局限性非常重要:
- 单次运行:BugFind 和 AIME 均未使用 pass@k。像 task05 和 I-15 这种高方差情况需要反复验证。
- 无外部竞争对手比较:未测试 Claude、GPT、Gemini 和 DeepSeek。本文仅描述 Qwen 家族内部差异。
- 3.6-Plus 仅完成了 6 道 AIME 题:其准确率无法直接与 Plus/Max 的 15 题运行结果比较。
- 定价使用预估值:请查看最新的网关价格以获取官方数字;DashScope 国内定价可能有独立折扣。
- 仅使用了一个智能体框架 (Stirrup):切换到 SWE-agent 可能会改变排名。
- 多模态样本量为 n=2:不能代表广泛的视觉能力。
- 测试模型为邀请内测版:官方 SKU 行为可能存在细微差异。
- X 数据为单日快照:反映了写作时的社区情绪,发布后可能发生变化。
最终结语
在 2026 年 6 月的官方叙事中,Qwen3.7-Plus 是视觉排行榜上的中国旗舰梯队,是网关上的高性价比选择,也是社区评价中迭代速度快得惊人的 Qwen 家族新成员。
在我们可复现的下午时空里,它是:
- 唯一在此次真实代码 Bug 修复运行中获得 10/10 的模型。
- 在开启思维模式的竞赛数学运行中,以更低延迟达到与 Max 相同分数的模型。
- 相比上一代实现 3.55 倍吞吐量提升的模型,让“无法完成”成为过去式。
- 在官方示例图片上依然幻觉,但在我们的对照图片测试中通过的模型,提醒你不要只通过一张截图选择视觉模型。
这些结论均限于本次小样本、单次运行及固定框架。它们支持将 Plus 纳入工程默认候选集;但不支持通用模型排名。
对于工程师而言,官方叙事负责愿景;outputs/ 目录负责证据。如果你正在进行生产环境的模型选择,请结合配套的数据可视化版本(13_Qwen3.7-Plus_Eval.html)阅读此测评:优先相信数据,再阅读我们为何愿意将其称为“评估”而非转发。
在 2026 年的 AI 模型洪流中,只有可复现的审计级证据才是技术决策的硬通货。






