
死板的 ID3 流派标签正在毁掉你的本地音乐收藏。通过将 AudioMuse-AI 的先进音频分析能力与 AtlasCloud 的可扩展 API 相结合,你可以将一堆静态的媒体文件目录转化为一个极具直觉的语义发现引擎,并能将由情绪驱动的播放列表无缝导入到你的自托管服务器中。
![]()
重拾音乐的温度:利用 AudioMuse-AI 构建真正直观的本地库
深夜,你坐在书桌前。你既不想听节奏激昂的电子音乐播放列表,也没心情听那种刻板的古典音乐。你真正想要的是一种极具特定氛围的音乐:“安静、氛围感强的独立民谣,带点细雨蒙蒙的木吉他底色,帮我放松下来。”
如果你打开自托管的 Navidrome 或 Jellyfin 实例,并在搜索栏中输入这句话,你将得到零结果。
几十年来,我们这些数字音乐收藏者花费了无数时间整理 ID3 标签、清理专辑封面,并强行将灵动的艺术形式塞进“摇滚”、“爵士”或“流行”这种僵硬的流派分类中。但老实说:流派标签不过是 20 世纪唱片店营销的产物。它们根本无法理解音乐听起来到底是什么“感觉”。
管理个人音乐库的未来不属于静态元数据,而属于语义音频分析。大语言模型 (LLM) 远不止是聊天界面;它们是解读你音乐中难以量化的情感重量的终极钥匙。通过部署开源的 AudioMuse-AI 以及像 AtlasCloud 这样智能的 LLM 路由,你可以让本地文件重焕生机,并基于纯粹的氛围、声音质感和歌词含义来生成播放列表。
什么是 AudioMuse-AI?
AudioMuse-AI 是一个自托管、开源的音频智能引擎,旨在与你现有的媒体环境无缝协作。它充当一个由 AI 驱动的“大脑”,直接接入 Jellyfin、Navidrome、LMS/Lyrion 和 Emby 等流行的自托管音乐平台。
AudioMuse-AI 不解析文本标签,而是处理原始音频文件。它运行本地化的神经网络模型来提取复杂的数学声学向量(使用 CLAP,即对比语言-音频预训练),并映射 72 种支持语言的歌词主题。
一旦初始扫描完成,你将解锁让商业流媒体算法显得肤浅的功能:
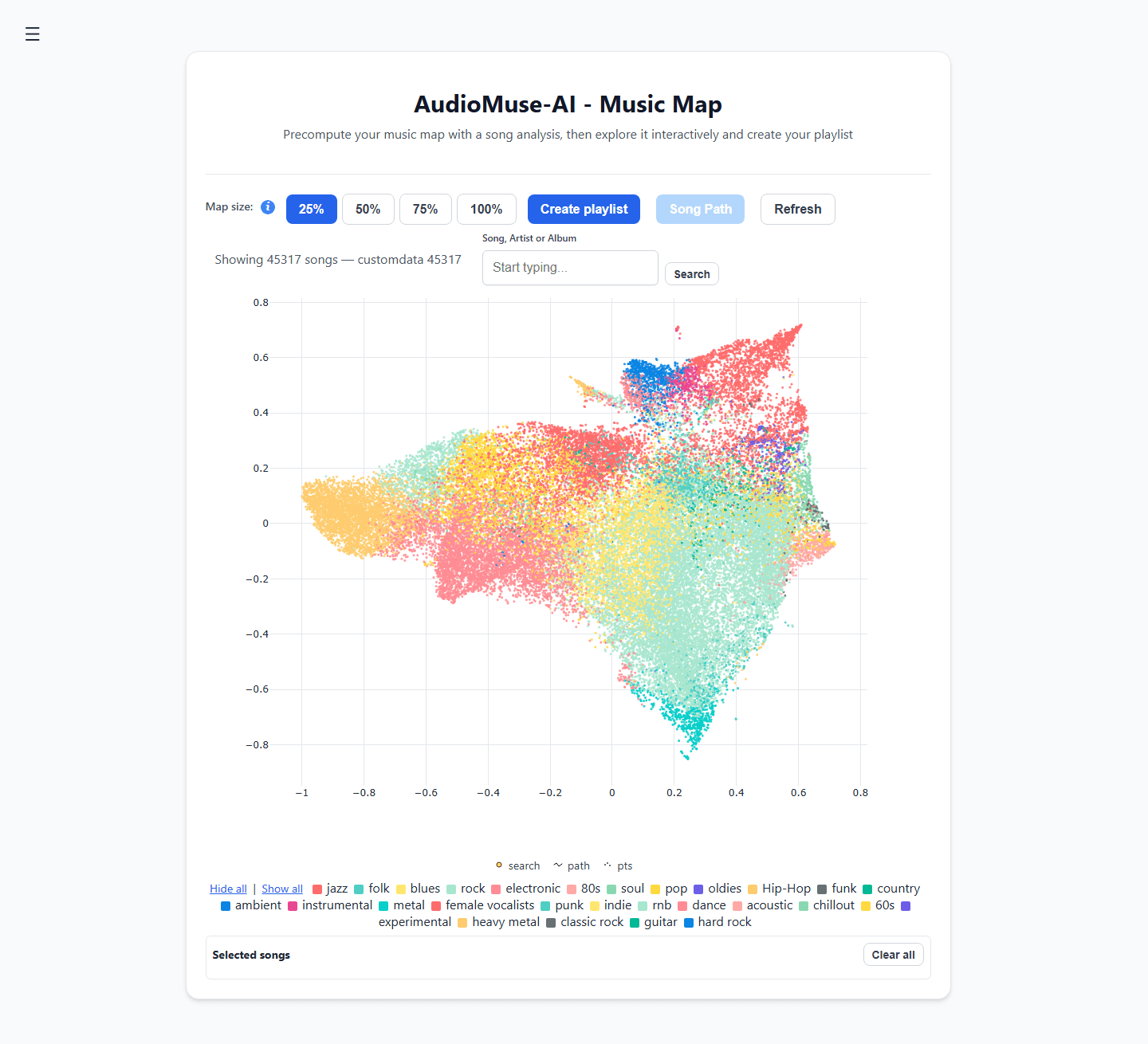
- 声学聚类: 自动将你的音乐库绘制成一张可视化的 2D 互动“音乐地图”,根据音轨的原始声波而非随意的流派进行分组。
- 歌曲路径: 选择一首欢快的放克乐曲作为起点,将一段忧郁的氛围乐曲作为终点。引擎会自动计算两者之间的声学桥梁,生成一个情绪转换平滑且完美的播放列表。
- 语义歌词搜索: 按叙事主题或情感概念搜索你的音乐库(例如:“关于在小镇长大”的歌曲),而不仅仅是查找精确的歌词匹配。
分步指南:构建你的语义音乐发现引擎
让我们来一步步搭建一个完全无需元数据的语义播放列表工作流。
第一步:环境准备与部署
AudioMuse-AI 可以在 macOS、Linux 和 Windows 上原生运行,但对于标准的家用服务器或 NAS 设置,Docker Compose 是最简洁的方案。
在服务器上创建一个目录,从部署文档中获取官方的 docker-compose.yaml,并确保你的环境文件已配置好。
YAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ 硬件注意: 底层 AI 模型非常依赖现代 CPU 指令集。如果你在 Proxmox 等虚拟化环境中运行此程序,请确保将 CPU 类型设置为 "Host",以透传 AVX2 支持。如果你在普通的 QEMU 虚拟 CPU 上运行,容器将在启动时立即崩溃。
通过以下命令启动:
Bash
plaintext1docker compose up -d
第二步:运行音频框架扫描
打开浏览器并访问 http://YOUR-SERVER-IP:8000。你将看到初始化设置向导。连接你的媒体服务器(例如,输入你的 Navidrome URL 和个人 API 令牌)。
连接成功后,前往 Analysis and Clustering(分析与聚类)仪表板并点击 "Start Analysis"(开始分析)。
引擎将开始计算声学指纹。根据你的库大小,以及你是在英特尔 i5 迷你 PC 还是树莓派 5 上运行,此初始解析阶段可能需要几分钟到几小时不等,具体取决于处理原始波形的速度。
第三步:通过 AtlasCloud 为 AI 大脑提供动力
这里是我们遇到自托管技术瓶颈的地方。AudioMuse-AI 具有一个互动式播放列表聊天界面 (app_chat.py) 和一个深度歌词嵌入引擎。在本地运行庞大、复杂的语言模型来处理这些语义查询,很容易使 NAS CPU 占用率飙升至 100%,从而导致令人痛苦的 API 超时和播放列表生成延迟。
为了保持本地硬件轻量、冷静且安静,我们可以将繁重的语义推理卸载到外部 API。正如项目 OpenAI 兼容 AI 提供商指南 中正式记录的那样,你可以通过使用原生的 OPENAI 核心提供程序,将请求无缝路由到 AtlasCloud。
只需将这些变量添加到服务器的部署环境设置中:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
通过利用 AtlasCloud,你无需在本地硬盘上管理庞大的多 GB 模型。只需一个 API 密钥,AudioMuse-AI 即可即时访问高性能推理模型,从而实时分析你的自然语言提示,且处理延迟极低。
第四步:生成你的第一个氛围播放列表
在 AtlasCloud 处理语义映射的情况下,导航到 Instant Playlists(即时播放列表)选项卡。让我们测试一下该系统跨越传统界限的能力。输入一个高度抽象的提示:
“给我一种深夜雨天驾驶的氛围。开始时要原声、缓慢,但在最后过渡到具有律动感电子脉冲的曲目。”
AtlasCloud 处理你提示中的核心情感意图,将结构蓝图传回 AudioMuse-AI 的本地向量索引,并立即返回精选的播放列表。点击 "Export to Media Server",自定义播放列表就会通过 Jellyfin 或 Navidrome 即时推送到你手机上的音乐 App 中。
对比
| 功能 | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
|---|---|---|---|
| 隐私与控制 | 完全所有权。数据保持本地;LLM 查询通过安全代理。 | 半私有。需要专有账户和活跃的 Plex Pass。 | 零隐私。你的收听日志会被货币化以用于广告追踪。 |
| 元数据依赖 | 无。直接分析原始音频波形和歌词主题。 | 高。分析开始前严重依赖准确的基础标签。 | 绝对依赖。完全依赖商业唱片公司的标签和数据库 ID。 |
| 冷启动性能 | 完美。可以即时分析并映射冷门的本地独立音乐。 | 较差。如果音乐未在 Plex 数据库中匹配,则无法进行情境关联。 | 糟糕。如果歌曲缺乏全球流媒体播放量,算法会忽略它。 |
| 语义搜索 | 高级。通过 LLM 理解复杂的自然语言提示。 | 不存在。仅限于基本过滤器(年份、流派、心情标签)。 | 一般。文本解析能力尚可,但仅限于其目录内的内容。 |
技术注意事项与生产故障排除
- VNNI 歌词重分析 Bug: 如果你最近将容器栈更新到了最新的 AudioMuse-AI 版本,请务必注意你的 CPU 架构。较旧的 GTE 多语言嵌入模型在缺乏 VNNI 指令集(2019 年以前的硬件)的旧 CPU 上可能会产生退化的向量映射。如果你在 Linux 主机上运行 grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo 得到空结果,你应该使用 PostgreSQL CLI 删除旧的数据库表,并重新触发歌词扫描,以获取干净、准确的语义搜索结果。
- 媒体服务器超时调整: 当同步包含 500 首以上曲目的庞大播放列表回 Navidrome 时,初始同步握手可能会超过默认的代理限制。如果你的日志中出现连接握手断开,请查阅官方参数指南来调整服务器的超时标志。
常见问题解答
为什么在设置过程中我的 Jellyfin 连接测试失败?
这通常是由不正确的 Base URL 格式或无效的 API 令牌范围引起的。确保你使用的是包含端口的完整 HTTP/HTTPS 地址(例如 http://192.168.1.50:8096),并验证 Jellyfin 仪表板内生成的 API 令牌是否具有播放列表的完整管理员读写权限。
我可以在没有 AVX2 指令集的旧服务器上运行 AudioMuse-AI 吗?
可以,但你不能使用标准的 Docker 镜像。你需要显式拉取带有 -noavx2 后缀的专用 Docker 镜像(例如 neptunehub/audiomuse-ai:latest-noavx2)。这些构建版本将性能优化的线性代数后端替换为更兼容的旧库。请注意,在此后备方案下,原始音频扫描速度会明显变慢。
AtlasCloud API 如何提高 app_chat.py 的响应速度?
当你与对话式播放列表向导交互时,系统必须将你的对话反馈转换为结构化的 JSON 模式。在本地服务器 CPU 上处理此文本每条消息可能需要 10 到 30 秒。通过像 AtlasCloud 这样优化的云合作伙伴路由这些特定请求,可以在几毫秒内返回答案,确保你的本地服务器内存保持空闲,以便在不卡顿的情况下流式传输高码率 FLAC 文件。






