Claude Code 每个开发人员每天的活跃成本约为 13 美元,而高强度的自动化使用量可能使每位工程师的月度账单达到 500 至 2,000 美元(CloudZero, 2026)。对于一个 50 人的团队来说,这意味着一笔数额高达五位数的开支凭空产生。如果您的 AI 编码账单在上个季度突然飙升且无人能解释原因,请放心,您并不孤单,而且解决办法通常不是“减少 AI 的使用”。
真正的难题在于,智能体(Agentic)编码工具消耗 Token 的方式与聊天窗口有着本质区别,大多数团队正在为本可以以极低成本获取的 Token 支付全价。本指南将介绍七个具体策略,旨在降低 AI 编码的 Token 成本,并详细说明每个策略背后的数据支撑及实现这些优化所需的具体配置调整。
关键要点
- 智能体编码工具消耗的 Token 量是聊天的 10 到 100 倍,因为每次调用工具时都会重新发送完整的上下文(LeanOps, 2026)。
- Prompt 缓存是杠杆率最高的优化手段:缓存读取成本约为标准输入 Token 的 10%,仅此一项就帮助某团队将总 LLM 开支削减了 59%。
- 将日常编码切换至 GLM、Kimi 和 DeepSeek 等开源权重模型,相较于前沿模型可降低 80% 以上的每 Token 成本,且质量差距远小于大多数人的预期。
- 通过统一网关路由所有工具,可以确保预算单一、API Key 统一以及定价一致,无需再向五家供应商支付零售价格。
为什么 AI 编码 Token 成本会失控
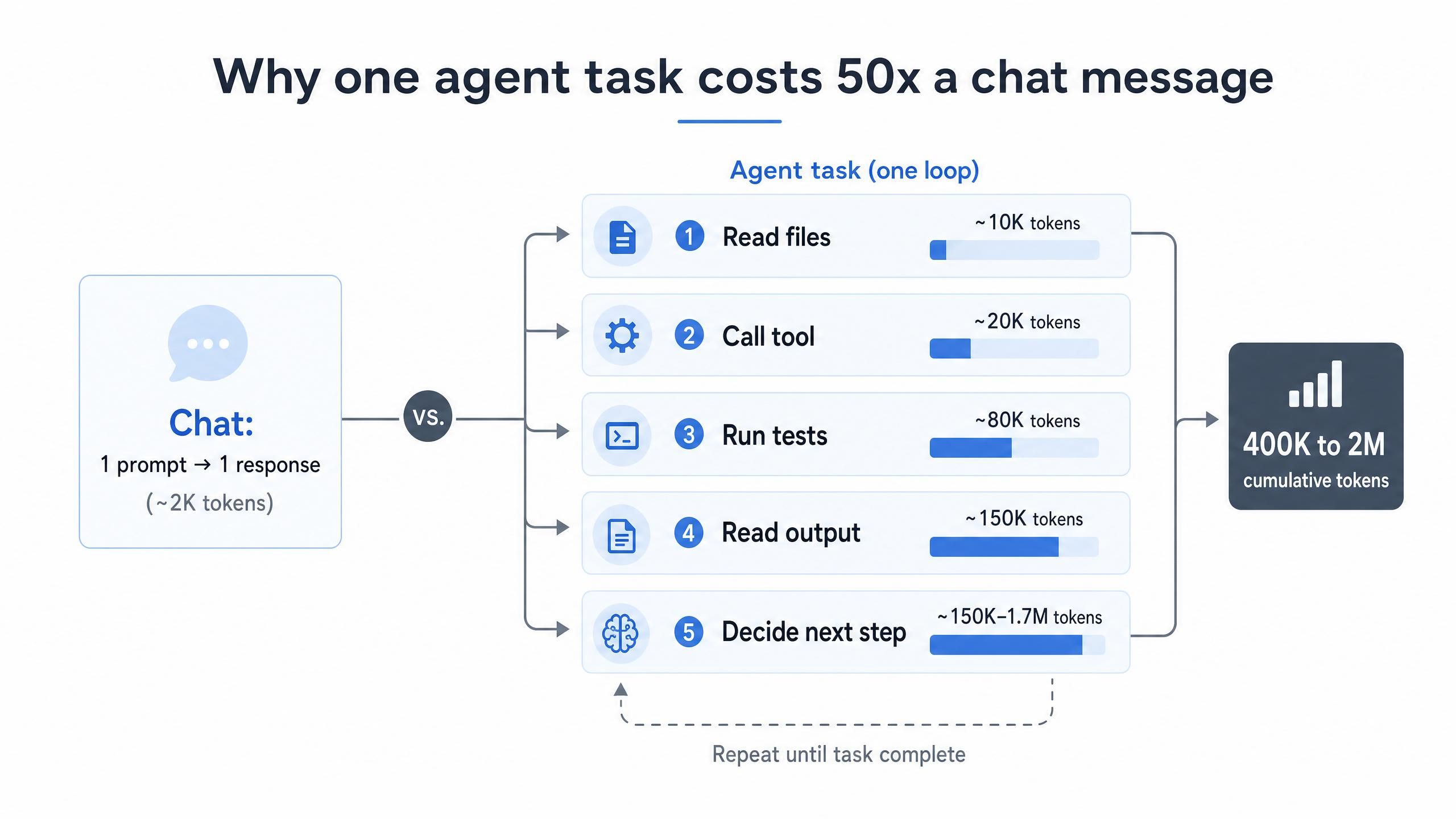
AI 编码 Token 成本高昂的根本原因在于结构而非行为。聊天交互是发送一个 Prompt 并获得一个答案,而智能体的逻辑则完全不同:它读取文件、调用工具、运行测试、读取输出,并决定下一步动作。每一个推理步骤都会重新发送累积的上下文,因此 Token 使用量会随着循环次数不断叠加。正是由于这个原因,AI 智能体消耗 Token 的速度比聊天机器人快 10 到 100 倍(LeanOps, 2026)。
成本增长迅速。一个简单的智能体任务在 API 中产生的累计输入 Token 可能达到 40 万到 200 万,因为上下文窗口在不断填充和重置(Morph, 2026)。如果乘以整个团队每天几十个任务,月度发票将不再仅仅是零头。
这并非大型组织所面临的假设性问题。据《The Next Web》报道,微软削减了大部分内部 Claude Code 授权,原因之一就是成本问题,每位工程师的账单攀升至 500 到 2,000 美元的区间(The Next Web, 2026)。当世界上资源最雄厚的工程组织都对账单感到压力时,在试图削减成本之前,理清 Token 的去向至关重要。
如何在不减慢速度的情况下降低 AI 编码 Token 成本
好消息是,这些策略几乎都不需要减少代码量或时刻监视智能体。它们通过消除浪费、重估工作价值以及将每项任务分配给成本最低且能胜任的模型来发挥作用。以下是七个效果最显著的策略,按投入与产出比大致排序。
策略 1:使用 Prompt 缓存降低 AI 编码 Token 成本
Prompt 缓存是您可以采取的杠杆率最高的优化手段。当智能体在每一步都重新发送相同的系统提示词(System Prompt)、工具定义和文件上下文时,缓存允许模型从缓存中读取重复内容,而不是重新处理。缓存读取的定价约为标准输入率的 0.10 倍,即对每次请求中重复的部分打 9 折(Finout, 2026)。
需要注意的要点:缓存写入成本比普通输入 Token 略高,在五分钟窗口内约为标准的 1.25 倍。因此,当上下文在生存周期(TTL)内被重复使用时,缓存非常划算,这正是智能体工作的典型模式。这种影响并非理论上的,ProjectDiscovery 团队在流水线中实施 Prompt 缓存后,总 LLM 成本降低了 59%(ProjectDiscovery, 2026)。
如果您使用 Claude Code 或兼容的智能体,请确认已启用缓存,并将您的系统提示词和大型文件上下文放入可缓存块中。这一项变动往往能带来账单金额最大的降幅。
策略 2:将模型与任务匹配以降低 Token 成本
大多数团队将所有请求都路由至最强的模型,这就像开着货运卡车去买菜。更明智的模式是:将昂贵的前沿模型保留给真正需要它的任务,其余任务交给更便宜的模型。
实用的分层方案如下:
- 推理、架构、复杂调试: 使用顶级模型,其质量足以证明价格合理。
- 日常代码生成和编辑: 使用功能强大的中端开源模型。
- 高频后台作业、分类、样板代码: 使用最便宜的合格模型。
由于价格跨度巨大,节省空间非常可观。在低端领域,DeepSeek V4 Flash 每百万输入 Token 约为 USD0.14,而前沿模型则要贵得多(Codersera, 2026)。将 80% 的 Token 量分配给低成本模型,仅在 20% 关键任务中使用高级模型,可以在不显著降低输出质量的情况下将总开支减半。
策略 3:保持上下文窗口精简
因为上下文中的每个 Token 都会在智能体的每一步中被重新发送,所以臃肿的上下文窗口就是一种重复缴纳的税。两个习惯会有所帮助:首先,严格限定每项任务的范围,让智能体仅加载它所需的文件,而不是整个代码库;其次,在切换任务时开启新会话,而不是让一个对话积累数十万个过时的 Token。
一个有用的思维模型:如果您不会把某个文件粘贴进聊天窗口来回答问题,就不要把它留在智能体的上下文中。将上下文窗口从 20 万 Token 精简到 4 万 Token,带来的节省不是一次性的,而是节省了该任务后续每一个步骤的开销,这才是复利效应的体现。
策略 4:切换到开源权重模型以降低 AI 编码 Token 成本
这是节省成本最明显且最容易受旧观念影响的策略。2026 年发布的开源权重编码模型表现非常出色。在衡量模型能力的 SWE-Bench Pro 基准测试中,领先的前沿模型得分约为 91 分,而 Kimi K2.6 为 76.8,DeepSeek V4 Pro 接近 77(Codersera, 2026)。虽然在最难的基准测试上有差距,但对于常规功能开发、重构和编写测试,其性能差异远小于价格差距。
而价格差距正是关键所在。GLM、MiniMax、Kimi 和 DeepSeek 等开源权重模型每 Token 的成本仅为前沿模型的一小部分。在大多数日常编码中,开源模型完全能胜任且成本更低。过去主要的摩擦点在于接入难度:在不同提供商之间管理账户、API Key 和不一致的价格。
这时,统一的编码网关就改变了数学游戏。像 Atlas Cloud 这样的平台将主流开源权重模型聚合在单一 API 和单一积分余额之下,因此您可以随时将 Claude Code、Codex 或 OpenClaw 指向 GLM-5.1,明天切换到 Kimi K2.6,无需重新配置任何内容。Atlas Cloud 公布的各模型积分倍率相比官方 API 定价可节省约 45% 到 55%,且其积分率比 OpenRouter 更具性价比。
以下是其积分倍率在主流编码模型中的转换示例:
| 模型 | 上下文 | 输入倍率 | 输出倍率 | 约合官方节省率 |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
来源:Atlas Cloud Coding Plan 积分规则。积分成本 = 输入 Token × 输入倍率 + 输出 Token × 输出倍率。
策略 5:批量处理后台任务以降低 AI 编码 Token 成本
并非所有 Token 都需要以交互式的实时价格消耗。夜间评估、大规模分类任务、文档生成和批量重构无需人工等待,这意味着它们可以通过更廉价的批量通道或最低成本模型运行。将这些非紧急任务从高级交互模型中移出,本质上就是省钱,因为您之前正在为这些不需要高性能的任务支付全价。
原则很简单:将“我正在等待结果”的 Token 与“可以过夜完成”的 Token 分开,并分别定价。对于大多数团队而言,你会惊讶地发现总 Token 量中相当大一部分属于后者。
策略 6:通过一个编码网关路由所有工具
工具散乱会悄悄增加 AI 编码 Token 成本。一名典型的开发人员可能在终端使用 Claude Code,在编辑器中使用 Codex,同时在侧边使用几个智能体,每个工具都有自己的订阅、Key 和不透明的账单。这不仅导致无法掌控总支出,还让您在各处都支付零售价。
整合到一个兼容 OpenAI 的终端即可解决上述两个问题。因为 Atlas Cloud 暴露了一个基础 URL 和一个适用于 Codex、Claude Code、OpenClaw、OpenCode、Cursor 及直接 API 调用的积分池,您只需要一份账单、一份预算,并在一个地方切换模型。其套餐起价为每月 10 美元(入门版),并为团队提供更高层级,即用即付套餐更有 41% 的折扣,使您可以根据实际使用量来调整预算,而无需盲目猜测。
将 Claude Code 指向该网关只需修改一个配置文件。在 macOS 或 Linux 上,编辑
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
对于 Codex 用户,同样的配置位于
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.json策略 7:设定预算并监控 AI 编码 Token 成本
看不见的成本无法减少。那些被高额账单震惊的团队几乎都有一个共同点:没有支出控制,也没有针对每个开发人员的可见性。解决方法是在月初之前设定消费上限,而不是在收到账单后再补救。
基于积分且带有每日配额的计划从结构上解决了这个问题。与其采用无限制的计费模式,不如使用每月更新的固定每日积分津贴,这样可以限制失控智能体循环的影响范围,而即用即付包可以在用完每日配额后作为补充。当确实需要升级时,按比例计算的差额升级意味着您只需支付增加的部分。以 Atlas Cloud 的升级流程为例,它会扣除现有套餐的剩余价值,因此周期内的变更通常仅需几美元。
真实成本比较:不同模型的 AI 编码 Token 成本
为了使节省效果具象化,假设一名开发人员在忙碌的一天中通过其智能体推送了约 150 万输入 Token 和 30 万输出 Token,考虑到单个任务可能达到百万级别的累计输入,这是一个现实的数字。在价格接近每百万输入 5 美元、每百万输出 25 美元的前沿模型上,这意味着约 7.5 美元的输入加上 7.5 美元的输出,即单人每天约 15 美元,这与广泛引用的每活跃天 13 美元的数据相符(CloudZero, 2026)。
如果通过打折网关将同样的工作量分发给像 GLM 或 Kimi 这样的开源权重模型,仅输入部分就可降低 70% 以上,输出部分紧随其后。如果再叠加 Prompt 缓存,智能体工作流中占比最高的重复上下文仅需按 1/10 的费率计费。将这三个策略结合,15 美元的单人日开销完全可以控制在 3 到 5 美元,且无需改变任何人的编码方式。

具体数字会随工作流而变,但核心逻辑不变:AI 编码 Token 成本的大部分是由高价模型处理的重复上下文产生的,而这两点都是可以修复的。
总结:如何保持低 AI 编码 Token 成本
如果您想要一个能以最小成本捕捉大部分节省空间的初始配置:选择 GLM-5.1 或 Kimi K2.6 等开源权重模型作为默认编码模型,保留一个前沿模型用于复杂推理,在各处启用 Prompt 缓存,严格限制任务范围以精简上下文,并将所有工具路由至拥有每日固定预算的兼容 OpenAI 的单一终端。
这种组合同时解决了每个成本驱动因素:它重构了 Token 价格,停止为重复上下文付费,并限制了超支风险。希望在单一 Key 和单一预算下实现这一目标的团队,可以通过 Atlas Cloud Coding Plan 控制台进行配置,该控制台开箱即用地支持主流开源权重模型及常用编码工具。设置过程只需几分钟,却能每天为您节省开支。
关于 AI 编码 Token 成本的常见问题
为什么我的 AI 编码 Token 成本比聊天使用高得多?
因为智能体在每一步推理中都会重发完整的累积上下文,而聊天仅在每次提示时发送一次。这种结构上的差异意味着智能体完成同等工作消耗的 Token 是聊天的 10 到 100 倍(LeanOps, 2026),因此几十个智能体任务的开支就可能远超一个月的常规聊天。
降低 AI 编码 Token 成本最快的方法是什么?
启用 Prompt 缓存。智能体工作负载中的重复上下文一旦缓存,计费费率仅为标准输入率的约 10%(Finout, 2026)。至少有一家工程团队报告称,仅通过缓存就将总 LLM 成本降低了 59%。它不需要改变工作习惯,是投入产出比最高的优化。
更便宜的开源权重模型足以处理实际编码工作吗?
对于大多数日常任务,完全足够。在最严苛的 SWE-Bench Pro 基准测试中,顶级开源模型得分在 70 分左右,而前沿模型约为 91 分(Codersera, 2026),但常规功能开发、重构和测试很少会触及这个差距。只需保留一个前沿模型应对真正复杂的推理即可。
我能真正节省多少 AI 编码 Token 成本?
叠加使用 Prompt 缓存、更便宜的默认模型以及精简上下文这三大策略,通常能将每人每天的成本从 15 美元左右降至 3 到 5 美元。节省空间会在团队层面放大,这就是为什么五位数的月度账单往往只需要调整一下配置就能显著降低。
我必须更换工具才能降低 Token 成本吗?
不需要。大部分节省来自 Token 的定价方式和重用逻辑,而不是使用哪种客户端。将您现有的工具(无论是 Claude Code、Codex 还是 OpenClaw)指向折扣后的兼容 OpenAI 终端只是配置变更,而非迁移,因此您的工作流保持不变,但账单却降低了。
结语
在未看清机制前,AI 编码 Token 成本显得深不可测:智能体反复发送相同上下文,而大多数团队却为这一切支付了前沿模型的高额溢价。通过 Prompt 缓存、更智能的模型路由、精简的上下文以及统一的折扣网关,您可以修复这两点,账单至少降低一半,且无需任何人改变编码方式。本周就从缓存入手,评估哪些任务真正需要最昂贵的模型,并将您的工具整合到一个预算中。设置只需一个下午,而节省则是永久的。






