DeepSeek v4:目前已知的一切——功能、发布日期以及如何在 Atlas Cloud 上使用
简介:什么是 DeepSeek v4?
AtlasCloud 正在通过即将加入的 DeepSeek v4 扩展其生成式 AI 矩阵。
- 它是什么: DeepSeek 团队的最新旗舰模型。如果说 DeepSeek v3.2 为高性价比开源编程模型树立了标杆,那么 v4 则通过专有的 流形约束超连接 (mHC) 和 印迹记忆 (Engram Memory) 技术,在逻辑处理和内存方面突破了现有边界。
- 核心优势: v4 不仅仅能生成代码片段,它更像一位资深架构师,能够理解整个代码库结构,从而进行跨文件推理和复杂的 Bug 修复。
- 状态: 即将发布(预计 2026 年 2 月中旬 —— 请阅读我们关于 DeepSeek V4 预期功能的深度分析)。
为什么我们确信 DeepSeek v4 将成为下一个行业颠覆者?因为它解决了行业最大的痛点:AI 需要记忆并理解项目的逻辑。
📣 更新 — 2026 年 4 月 24 日: DeepSeek-V4 已正式发布。阅读我们关于其实际发布内容的全面报道,包括全新的稀疏注意力架构、1M token 上下文以及 Agent 基准测试结果 —— 请访问 DeepSeek-V4 预览版发布。
技术深度解析:关键特性
为了挑战 Claude Opus 4.5,DeepSeek 对模型进行了彻底的重构。泄露的论文显示,该模型在处理内存和逻辑稳定性方面发生了根本性转变。让我们深入了解此次更新的四大支柱。
架构:卓越的逻辑推理
-
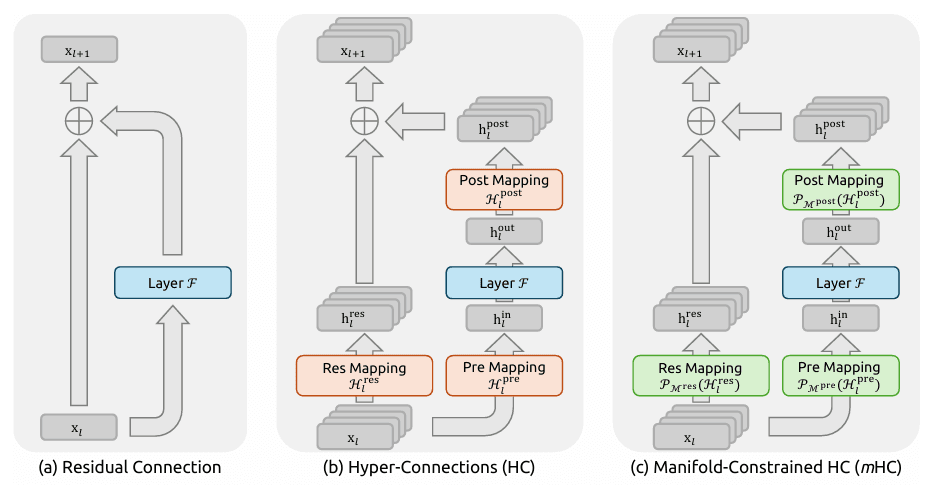
流形约束超连接 (mHC)
- 概念: DeepSeek v4 创造了一种全新的“神经连接”方法。传统的连接在深度网络中往往会丢失信息,而 mHC 充当了 AI 大脑中的“逻辑高速公路”。
- 成果: 在处理海量、复杂的逻辑(如重构数千行代码)时,模型学习速度更快,逻辑保持力更强。这消除了长上下文生成中常见的“逻辑幻觉”和不一致性。
效率:更低的推理成本
-
混合专家模型 (MoE) 2.0
- 概念: 虽然 v4 是一个参数巨头(数千亿参数),但它采用了优化的 MoE 架构,仅为每个 token 激活最相关的“专家”。
- 成果: 它在 高能力(海量知识库)和 高效扩展(像小模型一样轻量运行)之间实现了完美平衡。
-
稀疏注意力 (Sparse Attention)
- 概念: 模型摒弃了扫描所有文本的暴力方法,现在能够智能地仅关注关键信息。这极大地降低了计算成本并加快了长上下文的处理速度。
内存:智能上下文管理
-
印迹记忆 (Engram Memory) (选择性存储与回溯)
- 概念: AI 不再死记硬背,而是开始“理解”。它能识别项目结构,遵循命名规范(snake_case 与 camelCase),并识别编码模式(模拟团队特定的工厂模式)。
- 成果: 它的编程表现就像一位资深员工。
-
多头潜在注意力 (MLA)
- 概念: 可以将其视为“超级速记”。当其他模型需要 100 个 token 来存储信息时,MLA 将其压缩为 10 个关键符号。
- 成果: 当需要回溯时,模型能够在不丢失信息的情况下,通过数学手段重构原始含义。这在极大地降低 VRAM 使用率的同时,保持了令人难以置信的细节留存能力。
应用:工程实战
- 代码库级理解与 Bug 修复
- 其目标不仅仅是写一个函数,而是掌控整个代码库。在 SWE-bench 测试中,DeepSeek v4 旨在通过理解跨文件依赖关系,解决超过 80.9% 的实际复杂问题。
使用场景:降低成本与提升效率
DeepSeek v4 专为硬核工程打造。以下是它与竞争对手的对比:
重构遗留代码
对于文档缺失、混乱的遗留系统,mHC 架构是救命稻草。它能追踪远距离的逻辑依赖,从而实现安全重构。
- 对比 GPT-4o: 当上下文超过 10k token 时,GPT-4o 经常会出现“逻辑幻觉”(编造不存在的函数调用)。而 DeepSeek v4 在长上下文中保持了 100% 的逻辑一致性。
- 对比 Claude 3.5 Sonnet: 虽然 Sonnet 质量很高,但对于大规模重构任务而言,它既缓慢又昂贵。DeepSeek v4 的 MoE 架构在 Atlas Cloud 上提供了约 40% 更快的推理速度,且成本更低。
代码库级功能开发
在成熟项目中添加新 API 时,v4 利用“印迹记忆”瞬间掌握上下文。
- 对比传统自动补全: 标准工具往往忽略项目特定的规范,引入样式不一致。DeepSeek v4 对现有代码库的模仿程度极高,感觉就像是从最优秀的开发者那里直接复制粘贴一样。
全链路 Bug 追踪
在 SWE-bench 上实现 80.9% 的成功率,意味着能够处理跨越前端、后端和数据库的 Bug。
- 对比 Claude Opus 4.5 (预期): Opus 4.5 性能可能很强,但价格高昂。DeepSeek v4 以极具竞争力的价格提供了近乎 SOTA 的性能,使团队能够在不增加预算压力的情况下进行迭代式“反思与纠错”。
📉 总结:团队的投资回报率 (ROI)
对于初创公司和开发团队,DeepSeek v4 + AtlasCloud 的组合带来了实实在在的 ROI:
- 生产力: 将资深开发者的编码时间缩短 30-50%。
- 成本: 与租用双 RTX 4090 服务器或支付闭源 API 费用相比,AtlasCloud 的集成 API 可为团队节省超过 60% 的综合计算成本。
硬件红线:本地部署?三思而后行。
此时,你可能想在本地机器上运行这个“编程之神”。但我们必须提醒你:性能是有代价的。
- 最低门槛:双 RTX 4090
- 解读: 你需要购买两块市面上最昂贵的消费级显卡并将它们连接起来。单是显卡的成本就相当于 3 台 iPhone 17 Pro Max(或者一辆不错的二手车)。
- 推荐配置:单 RTX 5090 (2026 旗舰款)
- 解读: 这是显卡中的“法拉利”。不仅会因黄牛炒作导致价格极高,而且供货极度稀缺。
考虑到居高不下的显卡价格,问问自己:为了运行一个模型,花费数千美元,还要面对风扇噪音、散热和环境配置等问题,真的值得吗?
智慧之选:Atlas Cloud 的 Day 0 访问权限
你不需要成为富翁也能使用 DeepSeek v4;你只需要更聪明。与其购买会贬值的“电子砖头”,不如选择云端。
AtlasCloud 已为发布做好准备:
-
我们的承诺: 享受你的假期,把繁琐的部署工作交给我们。我们全天候 24/7 监控官方发布渠道。
-
核心优势:
- 即时访问: 开源权重发布即刻,我们的 API 集成同步上线。
- 零门槛: 无需昂贵硬件,无需处理 CUDA 依赖地狱。只需带上你的 Prompt。
- 极致体验: 我们提供完整的上下文支持,确保“印迹”记忆机制在 100% 容量下运行,且无量化损失。
如何在 Atlas Cloud 上使用
Atlas Cloud 让你可以 并排使用多个模型 — 首先在 Playground 中测试,然后通过统一 API 调用。
方法 1:直接在 Atlas Cloud Playground 中使用
方法 2:通过 API 访问
第一步:获取你的 API Key
在你的 控制台 (console) 中创建 API Key 并复制备用。
第二步:查看 API 文档
在我们的 API 文档 中查看端点、请求参数和身份验证方法。
第三步:发送你的第一个请求(Python 示例)
示例:使用 DeepSeek v3.2 生成内容:
python1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






