
编写 GPU 内核时,你实际上是处在一条技术光谱上。一端是 Triton:编写速度快,但编译器会为你处理大部分内存布局和共享内存的决策。另一端是 CUTLASS / CuTe:提供完全控制力,代价是需要编写大量的模板代码。TileLang 则位于中间。你可以用 Python 编写逻辑,但需要显式定义共享内存的内容、流水线的阶段以及线程束(warp)如何分工——而剩下的工作则由布局推导(layout inference)阶段来完成。
在这篇文章中,我们将介绍其思维模型,编写一个 GEMM,然后深入到真实的生产级内核:DeepSeek 的 MLA 解码(decode),这里才能体现出真正有趣的决策。我们的目的不是面面俱到,而是展示你如何思考“分块”(tiles),以及 TileLang 如何默默地为你完成那些困难的部分。最后,我们将分享一个典型的生产案例——一个性能提升并非首要目标的内核。
思维模型
核心思想概括为三点:
- Tile 是头等对象。 一个数据块(例如 block_M × block_K)由线程块、线程束或单个线程拥有并处理。你不再像在 Triton 中那样完全停留在线程块层面,也不需要像在 CUDA 中那样手动管理每个线程。
- 你自己决定内存层级中的缓冲区位置。 你明确声明哪些数据进入共享内存 (T.alloc_shared),哪些进入寄存器 (T.alloc_fragment),以及哪些是线程局部的。这是它与 Triton 最大的区别,Triton 将共享内存的分配和调度隐藏在编译器中。
- 编译器推导线程映射。 一旦你定义了 tile 的位置以及在其上运行的操作(复制、gemm、归约),“布局推导”阶段就会将其并行化分配给线程,并计算出寄存器和共享内存的布局。虽然你可以手动重写,但大多数情况下无需干预。这是该工具的核心功能——当你看到 MLA 的例子时,就会明白其价值。
如果你有 Triton 的使用经验,可以参考以下映射表:
| Triton | TileLang | |
|---|---|---|
| 粒度 | 线程块 + 隐式向量化 | tile(线程块 / 线程束 / 线程) |
| 共享内存 | 由编译器管理 | 显式 alloc_shared + copy |
| 布局 | 编译器决定 | 推导得出,也可手动标注 |
| 流水线 | tl.range + 编译器 | 显式 T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm,可选择线程束策略 |
| 后端 | NVIDIA (主要) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL,以及 Ascend & MUSA 分支 |
简而言之:如果你想在不编写 CUTLASS 的前提下,精确控制分块、流水线深度和线程束分区,TileLang 是最佳选择。对于简单的逐元素操作或轻量级融合,Triton 仍然更快。
环境配置
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # 预编译包,最快路径
如果你需要修改编译器代码,建议从源码构建(需要本地 LLVM/CUDA 工具链):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
编写一个 GEMM
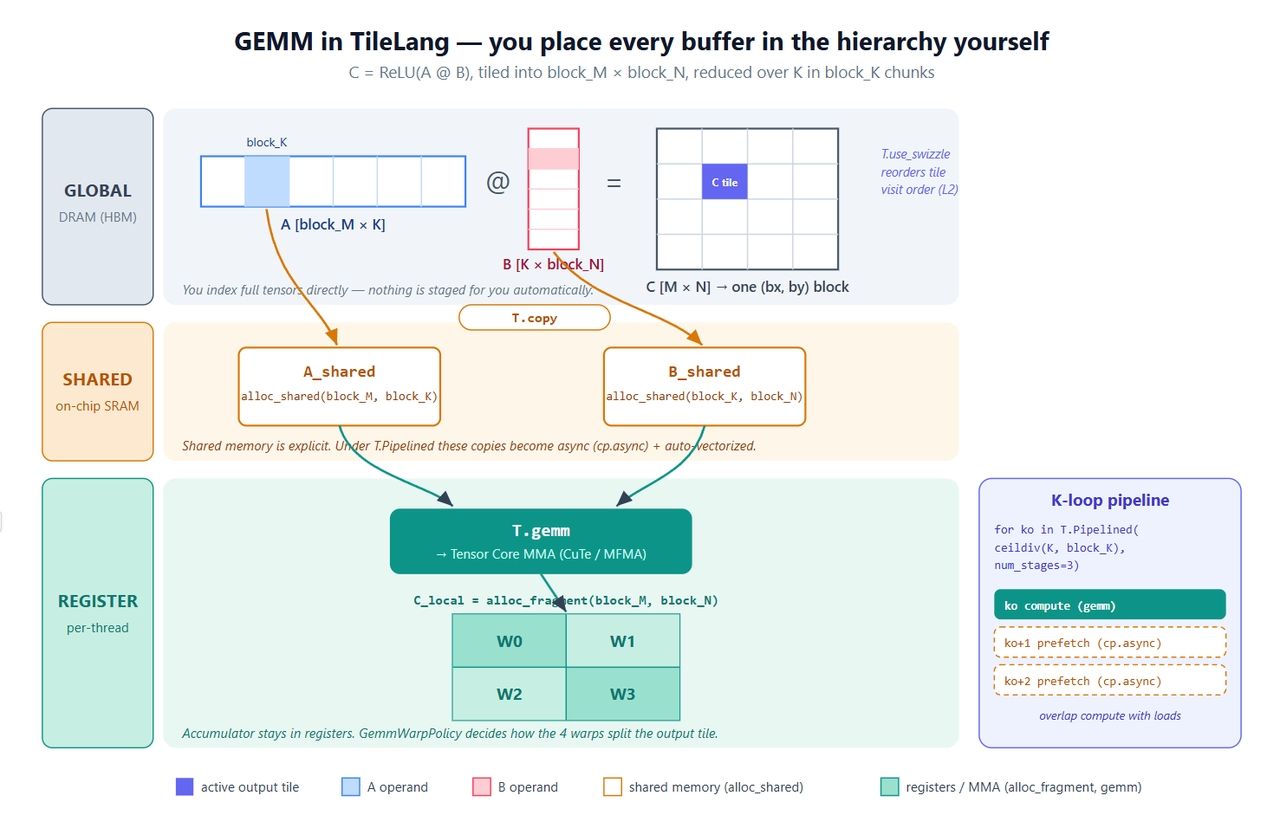
我们从经典的 C = ReLU(A @ B) 内核开始。它很小,但涵盖了所有关键的原语:显式缓冲区、并行复制、软件流水线、Tensor Core 调用以及 L2 swizzle。
plaintext1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # 网格维度:(#blocks along N, #blocks along M); 每个块 128 个线程 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # 显式定义每个 tile 的存储位置 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # 共享内存 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # 寄存器累加器 23 24 T.use_swizzle(panel_size=4, order="col") # 可选:更好的 L2 重用 25 T.clear(C_local) # 清零累加器 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # 全局 -> 共享 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # tile 级 MMA 31 32 for i, j in T.Parallel(block_M, block_N): # 融合 ReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # 写回 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
代码各部分的意义:
- 三个缓冲区,三个层级。 A_shared 和 B_shared 位于共享内存;C_local 位于寄存器中。这是 GEMM 的标准做法,区别在于这行代码是你亲手写下的,而不是像 Triton 那样由编译器暗中处理。
- T.copy 是并行复制的语法糖。 它展开为 T.Parallel 风格的移动,编译器从中推导出向量化、合并后的全局到共享内存的传输。当它位于 T.Pipelined 中时,会自动变为 cp.async。
- T.Pipelined(extent, num_stages=N) 是软件流水线。 num_stages=3 表示三倍缓冲——在计算当前 K-tile 的同时,ko+1 和 ko+2 的载入已经在进行中。在 Triton 中这需要编译器标志,而在 TileLang 中它就是循环的一部分,更易于理解。
- T.gemm(A, B, C) 是 tile 级矩阵乘法。 它在 NVIDIA 平台上降低为 CuTe/MMA,在 AMD 上则匹配对应的内联指令。它还接受 transpose 参数和 GemmWarpPolicy,后者控制线程束如何拆分输出 tile。这一点对 MLA 非常关键。
- T.use_swizzle 重新调度线程块,使 L2 缓存中相邻的块在执行时间上也更接近,通常能带来几个百分点的带宽提升。
下方的示意图将这些内容映射到了硬件上,它精确展示了 TileLang 将哪些本由编译器控制的权限交回给了你。
常用原语
只需掌握少量词汇即可编写大部分内核:
- 分配: T.alloc_shared, T.alloc_fragment (寄存器), T.alloc_local。
- 移动与初始化: T.copy(src, dst)(跨层级);T.clear, T.fill。
- 计算: T.gemm(...); T.Parallel(d0, d1, ...) 用于逐元素循环(布局推导入口);T.reduce_max / T.reduce_sum;标量数学运算如 T.exp, T.exp2, T.max, T.infinity。
- 调度: T.Pipelined(extent, num_stages=), T.use_swizzle(...), T.annotate_layout(...)(用于处理 bank 冲突或自定义 swizzle)。
- 动态形状: M = T.dynamic("m") 以避免针对每个形状重新编译。
验证与调试
获取编译器生成的源代码:
plaintext1print(kernel.get_kernel_source()) # 生成的 CUDA / HIP
获取性能数据:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
实战:MLA 解码
DeepSeek 的 MLA 解码内核是 TileLang 的最佳展示窗口。其性能达到了 FlashMLA 在 H100 上的水平(在 batch 64/128 fp16 下,明显优于 Triton 和 FlashInfer),代码仅约 80 行 Python。MLA 的核心难点不在数学计算,而在寄存器压力。
FlashAttention 系列内核的结构基本一致:每个 query 块遍历 key/value 块,维护当前的 max 和分母。然而对于 MLA,头维度非常大(查询和键宽 576,值宽 512),这意味着累加器 acc_o = [block_M, 512] 必须在整个 KV 循环中驻留在寄存器中。
在 Hopper 架构上,最快路径是 wgmma.mma_async,它将 4 个线程束(128 线程)捆绑为一个线程束组(warpgroup),要求 M 至少为 64。一个线程束组持有 64 × 512 的累加器会溢出寄存器,导致性能大幅下降。
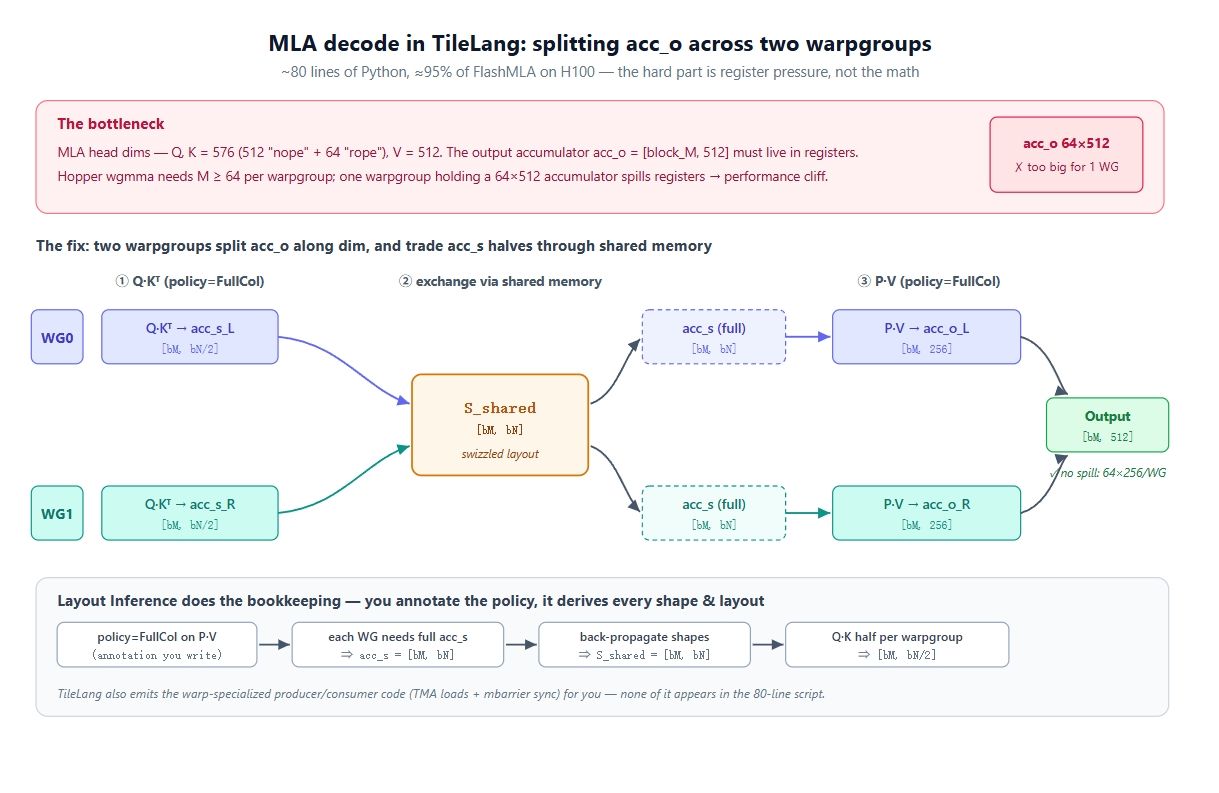
解决方案是将输出拆分到两个线程束组。 由于 M 不能小于 64,只能通过维度轴拆分:两个线程束组各持有一半的累加器(64 × 256)。这引入了第二个问题:P @ V 计算需要完整的 acc_s,而 Q @ K 阶段每个线程束组只计算了一半。解决方法是通过共享内存交换数据:在 Q @ K 期间,每个线程束组将自己的一半 acc_s 写入共享内存并读取对方的,从而确保两者都持有完整的 acc_s。
在 CuTe 中,你需要手动编写布局、swizzle、Tensor Core 对齐和生产者/消费者同步。而在 TileLang 中,只需通过标注 policy 即可由布局推导完成。
布局推导的作用:
- P @ V 上的 policy=FullCol 意味着每个线程束组需要完整的 acc_s。
- 约束向后传播到 staging buffer:S_shared 自动变为 [block_M, block_N]。
- 向前传播到 Q @ K:每个线程束组的得分分块为 [block_M, block_N/2]。
你只需编写数学逻辑,形状、swizzle 布局和专门的同步代码全由推导生成。
AtlasCloud 的生产实践:RMSNorm
我们在 AtlasCloud 的 Wan 视频生成 VAE 中使用了一个 TileLang 编写的 RMSNorm。原有手写优化内核仅支持部分隐藏维度(D ∈ {96, 192, 384}),而新配置需要 {160, 256, 320, 512, 640, 1024} 等通道宽度。TileLang 的通用性完美填补了这一空白。
TileLang 内核实现了一个与手写版本接口完全一致的 RMSNorm + SiLU 算子,支持任何 32 的倍数维度。
优势:
- 零修改接入: 接口、数学逻辑与 eps 参数与现有代码完全兼容。
- 性能提升: 在 Attention-block 的 RMSNorm 中,从 42 μs 提升至 20 μs(约 2 倍快)。
- 端到端加速: VAE 在生产分辨率下(720×1280, 21 帧)编码速度提升约 1.79 倍,解码提升约 1.78 倍。
总结
TileLang 的精妙之处在于,复杂的逻辑判断保留在你的脑海中,而不是转化为大量的样板代码。你决定如何拆分线程束、分配缓冲区以及设置流水线深度——剩下的寄存器布局、swizzle 逻辑和复杂的生产者/消费者同步由布局推导自动完成。你只需选择策略并编写数学逻辑,这正是它能让 80 行的 MLA 内核与手写 CUTLASS 内核同台竞技的原因。






