في أوائل شهر أبريل، ظهر فجأة نموذج يحمل اسم "HappyHorse-1.0". وقد تصدّر أربع فئات على لوحة صدارة الفيديو في Artificial Analysis، متفوقاً بشكل ملحوظ وبفارق كبير على نموذجي Seedance 2.0 و Kling التابعين لشركة ByteDance.
لم تكن هناك بيانات صحفية، ولا تدوينات، وكان اسم الشركة غامضاً، حيث اكتفت صفحة النموذج بعبارة "قريباً".
وفي 10 أبريل، أكد قسم ATH في شركة علي بابا (Alibaba) صحة المشروع، موضحاً أن HappyHorse هو مشروع بحث وتطوير داخلي من وحدة الابتكار التابعة لـ ATH، وهو حالياً في مرحلة الاختبار التجريبي الخاص. ومن المقرر إطلاق واجهة برمجة التطبيقات (API) في 30 أبريل.
علاوة على ذلك، من المقرر أن يكون HappyHorse-1.0 مفتوح المصدر بالكامل، ويُروج له كأول نموذج فيديو مفتوح المصدر يولد الصوت والفيديو معاً بشكل أصلي.
أصبح هذا "الإطلاق الهادئ" المتبوع بـ "إعلان مبهر" توجهاً سائداً بين شركات الذكاء الاصطناعي الصينية. فقد قامت Xiaomi بذلك مع مشروع يحمل الاسم الرمزي "Hunter Alpha"، واستخدمت Zhipu اسم "Pony Alpha" لنموذج GLM الجديد الخاص بها.
في هذا المقال، نكشف الحقائق المعروفة عن HappyHorse وما يعنيه هذا التطور.
موقع HappyHorse على لوحة الصدارة
تدير Artificial Analysis أربع لوحات صدارة: تحويل النص إلى فيديو بدون صوت، وتحويل الصورة إلى فيديو بدون صوت، وتحويل النص إلى فيديو مع صوت، وتحويل الصورة إلى فيديو مع صوت.
البيانات حتى ظهر يوم 13 أبريل هي كالتالي:
- تحويل النص إلى فيديو (بدون صوت): 1384 نقطة Elo، متفوقاً بـ 111 نقطة على Seedance 2.0.
- تحويل الصورة إلى فيديو (بدون صوت): 1413 نقطة Elo، وهو أعلى تقييم تم تسجيله على المنصة حتى الآن.
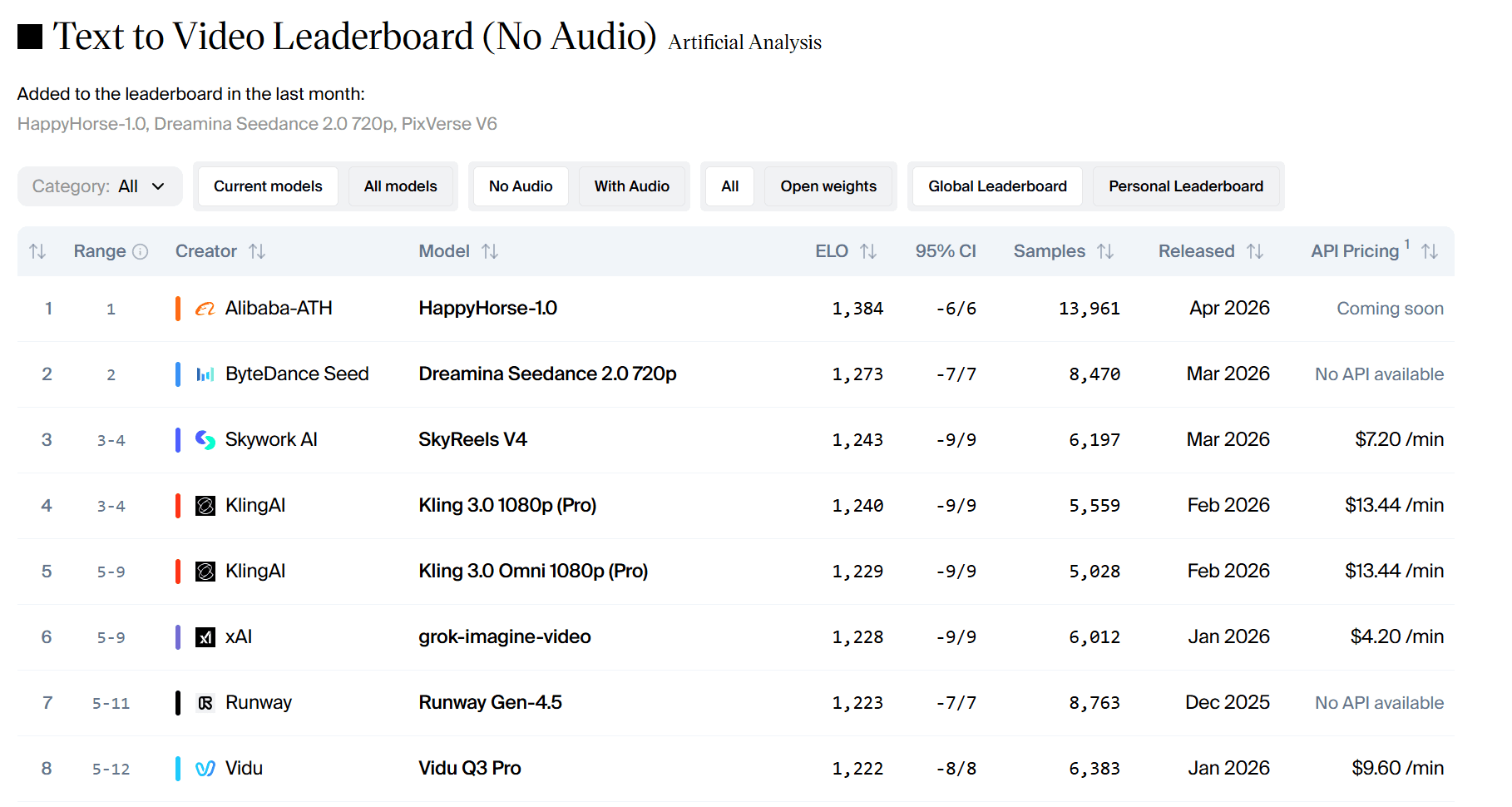
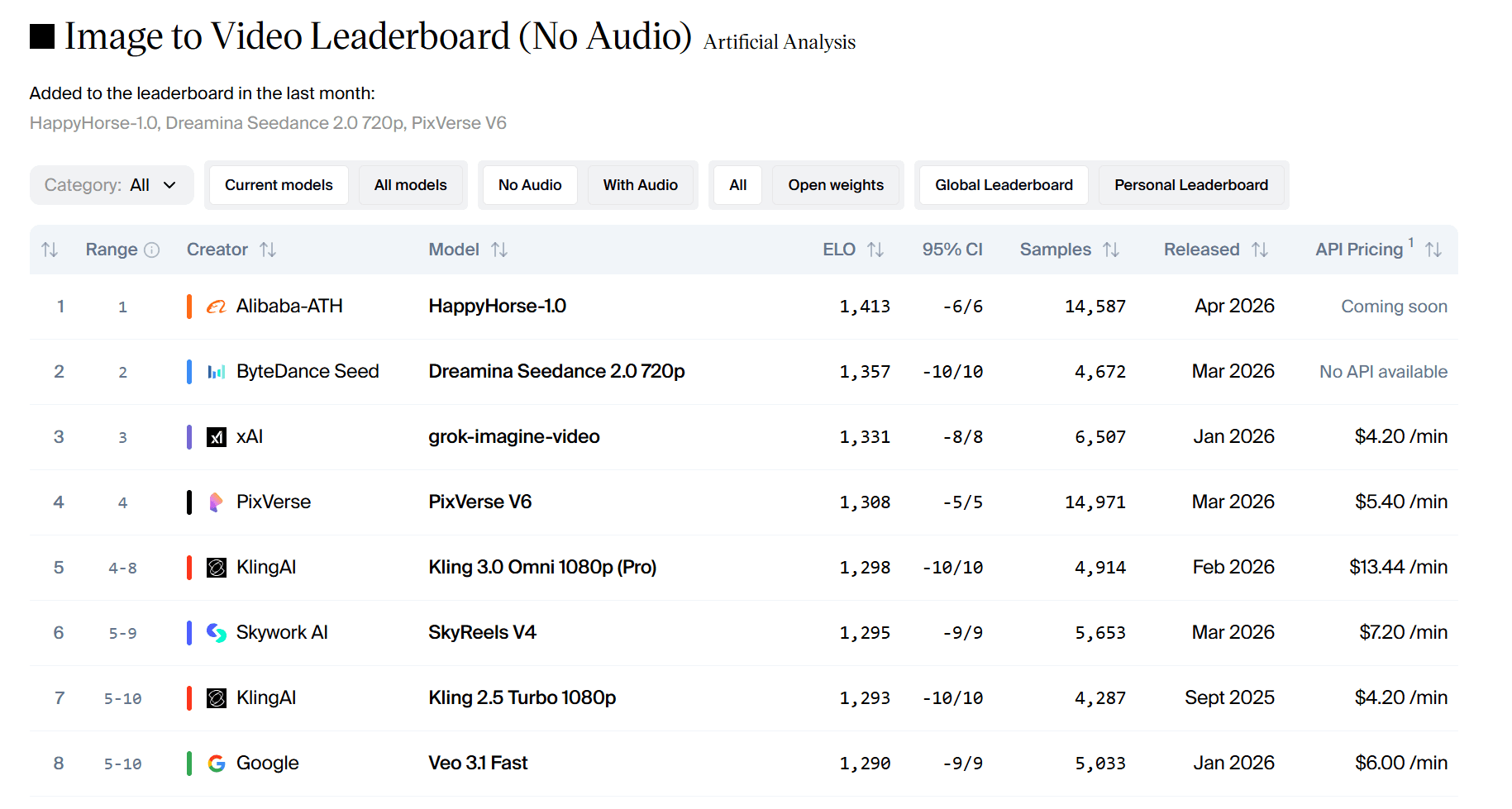
في تقييمات Elo، يشير الفارق الذي يتجاوز 60 نقطة إلى تفضيل واضح. أما فارق الـ 111 نقطة فيشير إلى أن المستخدمين اختاروا HappyHorse بأغلبية ساحقة في الاختبارات العمياء.
ومع ذلك، يتغير الوضع عند إدراج الصوت، حيث يتقلص الفارق إلى 1-2 نقطة فقط، وهو ما يعتبر تعادلاً فعلياً. وهذا يظهر أن مزامنة الصوت والصورة وجودة الصوت في HappyHorse ليست متفوقة بشكل كبير، بل هي على قدم المساواة مع Seedance في هذا الجانب.
مقارنة بين HappyHorse و Seedance 2.0
| وجه المقارنة | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| طبيعة النموذج | مفتوح المصدر | نظام تجاري مغلق |
| البنية | محول موحد (Unified Transformer) | محول انتشار ثنائي الاتجاه (DB-DiT) |
| القدرات متعددة الوسائط | توليد متزامن للصوت والفيديو (One-pass) | مدخلات متعددة الوسائط (نص، صورة، فيديو، صوت) |
| نمط توليد الفيديو | توليد بمرة واحدة (One-pass) | توليد قائم على خط المعالجة (Pipeline) |
| طول توليد الفيديو | حوالي 5-10 ثوانٍ (1080p) | يصل إلى حوالي 60 ثانية (2K) |
يمثل النموذجان فلسفتين مختلفتين.
HappyHorse-1.0: مفتوح المصدر، يعتمد على بنية المحول الموحد، ويولد الصوت والفيديو في وقت واحد، ويدعم مزامنة الشفاه الأصلية لـ 7 لغات. يضم 15 مليار معلمة، ويستغرق 38 ثانية لتوليد فيديو بدقة 1080p ومدته 5 ثوانٍ في بيئة H100.
Seedance 2.0: نظام تجاري مغلق، يعتمد على بنية DB-DiT، ويدعم مدخلات متعددة الوسائط، ويمكنه توليد فيديوهات بدقة 2K لمدة 60 ثانية، مع دعم مزامنة الشفاه لأكثر من 8 لغات.
فيما يتعلق بالجودة البصرية البحتة، يُفضل HappyHorse بوضوح في الاختبارات العمياء. أما من حيث مزامنة الصوت والصورة والجودة، فكلاهما متكافئ تقريباً. ومن حيث سهولة الاستخدام، توفر Seedance بالفعل واجهة برمجة تطبيقات ناضجة عبر خدمات مثل Volcano Engine، في حين من المقرر إصدار واجهة برمجة تطبيقات HappyHorse في 30 أبريل، ولا يزال أداؤها في الاختبار التجريبي قيد التحقق.
مقارنة بين أمثلة التوليد لنموذجي HappyHorse-1.0 و Dreamina Seedance 2.0 (تحويل النص إلى فيديو مع صوت) بواسطة Artificial Analysis:
المطالبة (Prompt): رسم متحرك قصير بأسلوب بيكسار عن قمع مرور صغير خجول يحلم بأن يكون القمع عند خط النهاية في سباق كبير. تضحك الأقماع الأخرى على طموحه. يضعه عامل بناء بالصدفة عند خط نهاية ماراثون. وبينما يمر المتسابقون، يتغير تعبير القمع المرسوم من الخوف إلى الفرح. تتساقط القصاصات الملونة من الأعلى. تشاهده الأقماع الأخرى على التلفاز وتستلهم منه. الصوت: من ضجيج المرور إلى هتافات الجمهور، ثم موسيقى مبهجة.
حول البنية التقنية
يتبع HappyHorse نهجاً غير مألوف؛ فهو يضم 15 مليار معلمة ويستخدم محول انتباه ذاتي موحد (unified self-attention) مكون من 40 طبقة. يتم تغذية رموز النص والفيديو والصوت في نفس التسلسل ونمذجتها بشكل مشترك، وهذا يختلف جوهرياً عن المسار المعتاد المتمثل في "توليد الفيديو أولاً ثم إضافة الصوت". هنا، يوجد الصوت والمشهد في نفس المساحة الدلالية منذ البداية.
يستخدم هذا النموذج تقنية تقطير DMD-2 وتحسين الرسم البياني الكامل عبر MagiCompiler. على معالج رسومي H100 واحد، يستغرق الأمر حوالي 38 ثانية لتوليد فيديو بدقة 1080p ومدته 5 ثوانٍ.
يدعم النموذج مزامنة الشفاه الأصلية لـ 7 لغات: الإنجليزية، الماندرين، الكانتونية، اليابانية، الكورية، الألمانية، والفرنسية. ويعد معدل الخطأ في الكلمات (WER) الخاص به من بين الأدنى لأي نموذج مفتوح المصدر.
يشير المشاركون في اختبار Artificial Analysis الأعمى إلى أن HappyHorse يتفوق بشكل خاص في تصوير الشخصيات؛ حيث إن ملمس الجلد وسلاسة الحركة متفوقان. وحقيقة أن أكثر من 60% من عينات الاختبار كانت صوراً شخصية أو مقاطع لأشخاص يتحدثون كانت عاملاً دفع بهذا النموذج إلى القمة.
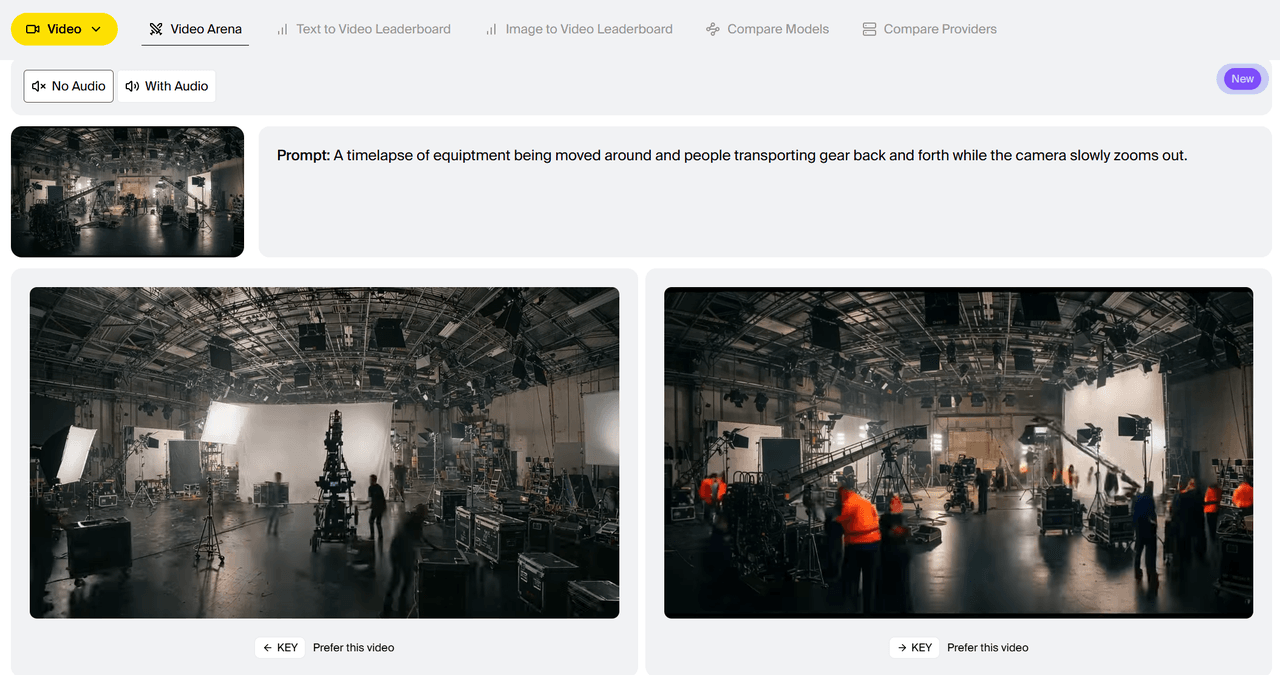
ومع ذلك، هناك انتقادات؛ حيث أشارت الفيديوهات المسربة إلى وجود تموجات غير طبيعية، وتشوهات في الأجسام سريعة الحركة، وتدهور في جودة الصورة عند عرضها على شاشات كبيرة.
خطة المصدر المفتوح والوصول
في 9 أبريل، أعلن HappyHorse-1.0 عن تحوله إلى المصدر المفتوح بالكامل. مستودع GitHub متاح الآن، والأوزان مفتوحة تماماً، ولا توجد قيود تجارية.
يوفر الموقع الرسمي عروضاً تجريبية عبر الإنترنت لتحويل النص إلى فيديو والصورة إلى فيديو. ووفقاً لشركة علي بابا ATH، من المقرر إطلاق واجهة برمجة التطبيقات للجمهور في 30 أبريل.
ومع ذلك، تجدر الإشارة إلى تحذير الفريق الرسمي من أن معظم "المواقع الرسمية" المتداولة عبر الإنترنت مزيفة، فالموقع الحقيقي لم يعمل بكامل طاقته بعد.
التأثير السوقي والأهمية
ظهر HappyHorse بعد أسبوعين من إيقاف OpenAI لتطوير Sora. كان يُنظر إلى حركته كعلامة على الركود في مجال فيديو الذكاء الاصطناعي، لكن النموذج الصيني التقط الشعلة.
تفاعل السوق بسرعة؛ حيث ارتفع سعر سهم علي بابا بأكثر من 7% بعد التأكيد وواصل صعوده. وعند إغلاق التداول في 10 أبريل، ارتفع بأكثر من 3% ليصل إلى 126.6 دولار هونج كونج.
على المستوى الاستراتيجي، يظهر HappyHorse أن ATH تمتلك فريقاً ثانياً قادراً على بناء نماذج متعددة الوسائط من الدرجة الأولى. يتمتع هذا الفريق بخلفية تجارية ويفهم احتياجات المستخدمين والسيناريوهات التجارية، مما خلق هيكلاً مزدوج المحرك: مختبر Tongyi (يركز على الأبحاث الأساسية) ووحدة الابتكار (بناء تطبيقات من تحديات تجارية حقيقية).
بالنظر إلى الجدول الزمني، استقال لين جونيانغ في أوائل مارس، وتأسست ATH في 16 مارس. وفي 2 أبريل، احتل نموذج Qwen 3.6 Plus المرتبة الأولى في حجم المكالمات العالمية على OpenRouter، وفي 8 أبريل تصدر HappyHorse قائمة Artificial Analysis. وفي غضون شهر واحد فقط، حققت علي بابا نتائج قوية في كل من نماذج اللغة والفيديو.
خلفية الفريق: تشانغ دي وشركة علي بابا ATH
خلف HappyHorse يقف تشانغ دي (Zhang Di)، وهو شخصية ثقيلة الوزن في هذا المجال.
كان في الأصل نائباً لرئيس Kuaishou وشغل منصب القائد التقني لـ Kling AI، ويُعرف بلقب "أبو Kling". غادر Kuaishou في نوفمبر 2025 وتولى رئاسة "مختبر الحياة المستقبلية" (Future Life Lab) في علي بابا، ليقدم تقاريره مباشرة إلى كبير العلماء تشنغ بو.
بعد خمسة أشهر، بنى فريقه HappyHorse-1.0 وتفوق على Kling و Seedance 2.0 من ByteDance.
كان هذا الفريق في البداية جزءاً من مختبر الحياة المستقبلية في Taobao، ولكن تم نقله إلى وحدة الابتكار في الذكاء الاصطناعي التابعة لمجموعة أعمال ATH بعد إعادة التنظيم الأخيرة في علي بابا.
يرمز ATH إلى "Alibaba Token Hub"، الذي أسسه الرئيس التنفيذي وو يونغمينغ في 16 مارس، والذي يقوده بنفسه. وتتمثل مهمته في "إنشاء الرموز وتوفيرها وتطبيقها"، وهو يدمج مختبر Tongyi، وخط أعمال MaaS، وقسم Qianwen، وقسم Wukong، ووحدة الابتكار في الذكاء الاصطناعي.
الأسئلة الشائعة
ما نوع وحدة معالجة الرسوميات (GPU) المطلوبة لتشغيل HappyHorse محلياً؟
يحتوي هذا النموذج على 15 مليار معلمة وهو ليس صغيراً بأي حال من الأحوال. في بيئة H100 واحدة، يستغرق الأمر حوالي 38 ثانية لتوليد فيديو بدقة 1080p ومدته 5 ثوانٍ. ستحتاج وحدات معالجة الرسوميات الاستهلاكية مثل RTX 4090 (بذاكرة فيديو 24 جيجابايت) إلى تقنيات الكمية (Quantization) أو التفريغ (Offloading)، ومن المحتمل أن يتجاوز النموذج سعة 24 جيجابايت للاستدلال بدقة FP16. أفاد بعض المستخدمين بنجاحهم مع كمية 4-بت، لكن الجودة تنخفض. للاستخدام الجاد، يُنصح باستخدام GPU سحابي بذاكرة فيديو تزيد عن 40 جيجابايت، أو انتظار إصدار واجهة برمجة التطبيقات في 30 أبريل.
هل يمكنني ضبط HappyHorse (Fine-tuning) باستخدام بياناتي الخاصة؟
نعم، بموجب الترخيص، لا توجد قيود على الاستخدام التجاري. ومع ذلك، فإن ضبط نموذج فيديو بـ 15 مليار معلمة ليس بالأمر السهل. فهو يتطلب مجموعة خوادم H100 أو A100، ومجموعة بيانات كبيرة من أزواج الفيديو والصوت، وموارد هندسية كبيرة. لا يحتوي مستودع GitHub حالياً على نصوص برمجية للضبط ويدعم الاستدلال فقط. وقد لمح الفريق إلى إمكانية إصدار تعليمات برمجية للتدريب في المستقبل، ولكن لم يتم تحديد تاريخ لذلك.
هل توجد مجموعات مجتمعية على Discord أو WeChat؟
توجد، لكنها غير رسمية. بدأت العديد من مجتمعات الذكاء الاصطناعي في إنشاء نقاشات على Discord وWeChat. لم يفتح الفريق الرسمي قنوات مجتمعية رسمية بعد. إذا انضممت إلى مجموعة، فاحذر من الروابط المزيفة وعمليات الاحتيال. من الأفضل مراجعة مستودع GitHub والإعلانات الرسمية من Alibaba ATH للحصول على أحدث المعلومات.
هل هذا النموذج متاح على Hugging Face؟
ليس في وقت كتابة هذا التقرير. صرح الفريق بأنهم يعملون على إصدار نسخة على Hugging Face، لكنها لم تكتمل بعد. حالياً، الأوزان موجودة فقط على GitHub. بدأ أعضاء المجتمع في تحميل نقاط فحص (checkpoints) محولة إلى Hugging Face، لكنها غير رسمية. للسلامة، يرجى استخدام مصدر GitHub حتى تظهر الصفحة الرسمية على Hugging Face.






