لقد تم إطلاق نموذج MiniMax M3، وخلاصة القول هي: استخدمه إذا كنت بحاجة إلى نموذج مفتوح الأوزان يدعم الصور والفيديو بشكل أصلي (natively)، ويحتفظ بمليون رمز (token) في سياق العمل بتكلفة منخفضة، ويعمل في حلقات برمجية ووكلاء طويلة دون الحاجة لإعادة التعيين. هذه هي حالة الاستخدام المثالية، وإذا كان لديك وكلاء يعملون بشكل مستقل أثناء نومك، فإننا نوصي بتجربته! M3 متاح الآن على Atlas Cloud.
حتى وإن لم تكن لديك وكلاء تعمل لفترات طويلة، فمن الجدير معرفة M3 بسبب التوجه الذي اتخذته MiniMax للوصول إلى هذه المرحلة. لقد حافظوا على سياق بمليون رمز بتكلفة معقولة بفضل بنية الانتباه المتناثر (MiniMax Sparse Attention أو MSA)، والتي تقلل من تكلفة الحوسبة لكل رمز إلى حوالي 1/20 من الجيل السابق عند سياق كامل؛ وقد حققوا ذلك باختيار المسار الأقل تكلفة الذي يعمل على بنية الخوادم الحالية، وليس المسار الأكثر تعقيداً. نتوقع أن يكون هذا هو التوجه الافتراضي لكل مزود رئيسي: سياق طويل رخيص من خلال انتباه متناثر أو مضغوط. هذا يحول نافذة المليون رمز من ميزة تنافسية إلى معيار أساسي، وينقل المنافسة الحقيقية إلى مستوى أعلى، وهو: مدى كفاءتك في توجيه المهام عبر النماذج، وليس الرهان على نموذج واحد بعينه.
أعلنت MiniMax عن M3 في 1 يونيو 2026. واجهة برمجة التطبيقات (API) متاحة الآن، وتذكر الشركة أنها ستنشر التقرير التقني والأوزان في غضون 10 أيام تقريباً من الإعلان.
إذا كنت تستخدم نموذجاً ريادياً آخر حالياً
يستحق M3 التجربة عندما تتطلب المهمة مساحة عمل أكبر، أو سياقاً مرئياً، أو حلقة عمل للوكيل أطول مما يدعمه نموذجك الافتراضي الحالي. العمود الذي يهم هو الأخير: ما الذي يضيفه M3 فعلياً مقارنة بالنموذج الذي تستخدمه حالياً.
| إذا كنت تستخدم حالياً | لهذه المهمة | ما يضيفه M3 فعلياً |
|---|---|---|
| GPT-5.5 أو GPT-5.5 Pro | البرمجة الوكالية، استخدام الحاسوب، البحث، تحليل البيانات، وأتمتة العمل المعرفي | مدخلات فيديو أصلية ومسار مفتوح الأوزان معلن — مسار وكيل ثانٍ بمنحنى تكلفة مختلف يمكنك استضافته ذاتياً لاحقاً. (GPT-5.5 لديه رؤية للصور بالفعل، لذا اختبر الفيديو والاقتصاديات، وليس دعم الصور.) |
| Claude Opus 4.8 | وكلاء البرمجة طويلة الأمد، العمل المعرفي الكثيف، واستخدام الأدوات | بديل مفتوح الأوزان وأقل تكلفة للمقارنة (A/B) في برمجة المستودعات الكاملة والتكلفة لكل مهمة مكتملة. Opus 4.8 يوفر بالفعل نافذة سياق بمليون رمز ورؤية، لذا الاختبار الحقيقي هو السعر، مدخلات الفيديو، واقتصاديات المهمة — وليس حجم النافذة. |
| Qwen3.7-Plus (متعدد الوسائط) | وكلاء الرؤية وواجهة المستخدم الرسومية، تحويل لقطات الشاشة إلى كود، وأتمتة المتصفح وسطح المكتب | تعدد وسائط مشابه مع تموضع أقوى في البرمجة/الوكالة ومسار مفتوح الأوزان. (Qwen3.7-Plus مملوك للشركة، ومتاح عبر API فقط.) |
| Qwen3.7-Max (الرائد للنصوص فقط) | الاستدلال النصي، الوكلاء ذوو الأفق الطويل، وأتمتة المكاتب | مدخلات صور وفيديو أصلية في نفس السياق. Qwen3.7-Max للنصوص فقط — للرؤية، ستضطر للتحويل إلى إصدار Plus. |
| DeepSeek-V4-Pro أو DeepSeek-V4-Flash | الاستدلال الحساس للتكلفة، البرمجة، استدعاءات الأدوات، وأحمال عمل API طويلة السياق | تعدد وسائط أصلي (صور وفيديو) فوق سياق طويل. DeepSeek-V4 للنصوص فقط، لذا M3 هو البديل متعدد الوسائط عندما تتضمن المهمة إشارة مرئية. |
الاختبار العملي بسيط. جرب M3 إذا كنت تحاول:
- الاحتفاظ بالمستودع، وسجل المهام، والسجلات، والخطة الحالية في سياق عمل واحد.
- السماح للوكيل بالاستمرار بعد عشرات استدعاءات الأدوات بدلاً من إعادة تعيين المحادثة.
- الاستدلال عبر الكود، والنصوص، ولقطات الشاشة، والرسوم البيانية، وملفات PDF، وإطارات الفيديو في تمريرة واحدة.
- تقليل عمليات التسليم بين نموذج نصي، ونموذج رؤية، وطبقة استرجاع منفصلة.
- مقارنة تكلفة السياق الطويل لكل مهمة مكتملة، وليس فقط السعر لكل مليون رمز.
لا تقم بالتبديل لأن مخطط الإطلاق يبدو جيداً. قم بالتبديل عندما يكمل M3 مهمة تفشل فيها حزمة التوجيه الحالية، أو تقتطعها، أو تبالغ في تكلفتها، أو تقسمها عبر الكثير من النماذج.
أين يساعد M3
وكلاء بمساحة كافية للعمل. تتجاوز أمثلة إطلاق MiniMax نمط عرض المحادثة المعتاد. في اختبار واحد، أعاد M3 إنتاج التجارب الأساسية من ورقة بحثية بارزة في مؤتمر ICLR 2025 بعد العمل لمدة 12 ساعة تقريباً. أنتج 18 التزاماً برمجياً (commits) و23 شكلاً تجريبياً. وفي اختبار آخر، عمل لمدة 24 ساعة تقريباً على نواة FP8 GEMM CUDA، وأجرى 147 مشاركة قياسية و1,959 استدعاءً للأدوات، ورفع استغلال الأجهزة من 7.6% إلى 71.3%.
لا تقرأ تلك الأمثلة كدليل على أن وكيلاً يعمل ليوم كامل سينجح في أول مطالبة (prompt) لك. إنها تظهر لماذا ينتمي M3 إلى القائمة المختصرة لسير العمل حيث يحتاج النموذج إلى التخطيط، وتشغيل الأدوات، وفحص النتائج، والمراجعة، والاستمرار بعد فشل محاولة مبكرة.
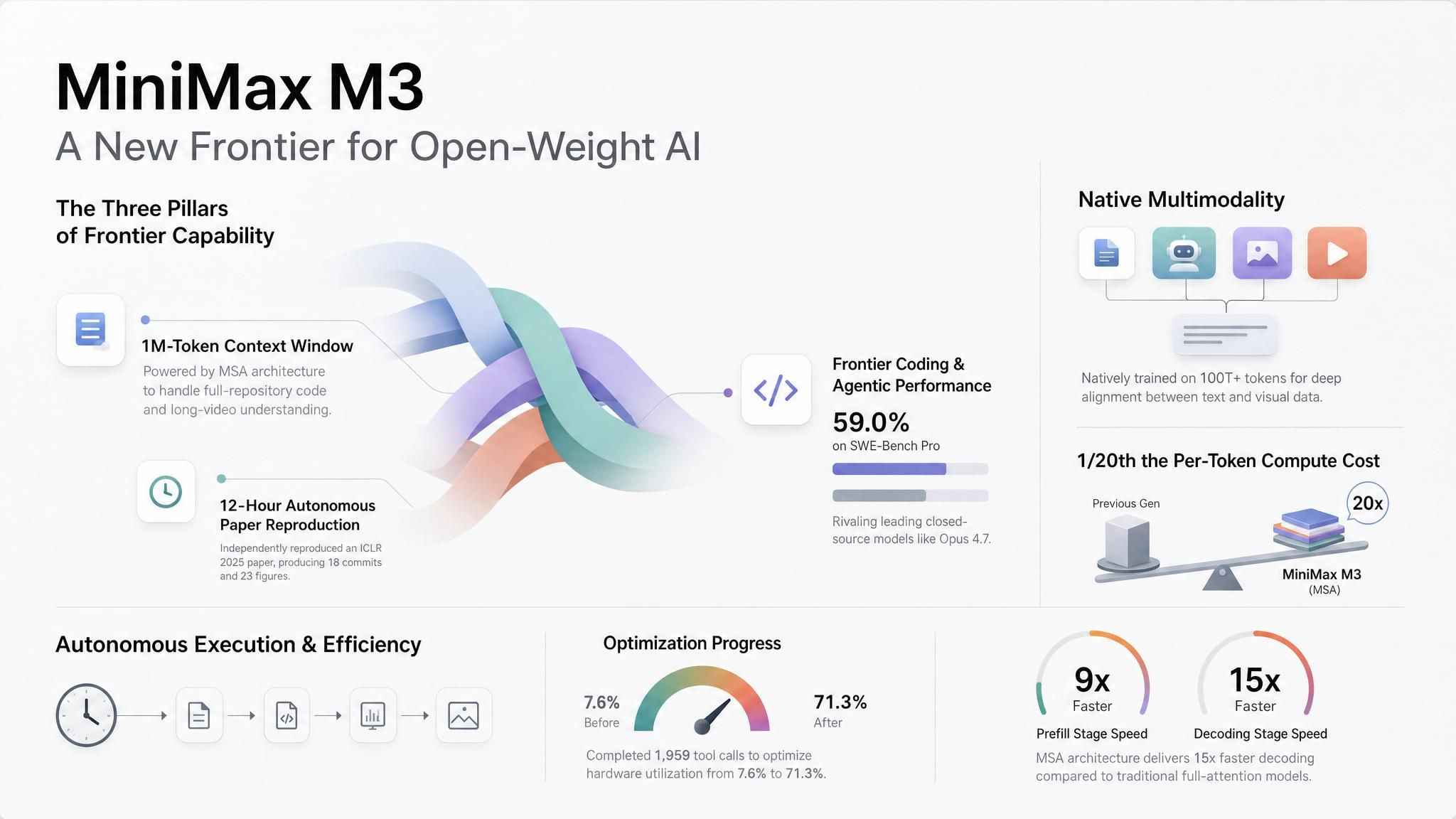
سياق على مستوى المستودع والمستند. يدعم M3 ما يصل إلى مليون رمز عبر API، مع وصف MiniMax لـ 512 ألف رمز كحد أدنى مضمون. عند طول سياق يصل إلى مليون رمز، تذكر MiniMax أن حوسبة كل رمز تبلغ 1/20 من الجيل السابق، مع سرعة تعبئة أولية (prefill) أسرع بأكثر من 9 مرات وسرعة فك ترميز أسرع بأكثر من 15 مرة.
هذا يغير تصميم المنتج. يمكن لوكيل البرمجة رؤية المزيد من المستودع. يمكن لمساعد البحث حمل أثر أدلة أطول. يمكن لأداة مراجعة العقود الاحتفاظ بالمادة المصدر والتحليل في نفس مجموعة العمل. لا يزال للاسترجاع مكان، ولكن لم يعد النموذج مضطراً للبدء من شريحة صغيرة من المشكلة.
سياق مرئي في نفس الطلب. قامت MiniMax بتدريب M3 ببيانات متعددة الوسائط منذ البداية. يقبل النموذج مدخلات الصور والفيديو، وتقول MiniMax إنه يمكنه التعامل مع النصوص والصور والفيديو المتداخلة في سياق واحد.
هذا يقلل عمليات التسليم بين النماذج. يمكن لسير عمل الدعم قراءة رسالة المستخدم وفحص لقطة الشاشة. يمكن لسير عمل البحث الاستدلال على الرسوم البيانية داخل ورقة بحثية. يمكن لوكيل استخدام الحاسوب النظر إلى الشاشة واتخاذ الإجراء التالي دون إرسال الخطوة المرئية إلى نموذج منفصل أولاً.
وصول مستضاف الآن، وأوزان قريباً. تتعامل MiniMax مع M3 كإصدار مفتوح الأوزان، لكن مسار الإطلاق الأول هو وصول مستضاف عبر API. يمنح ذلك الفرق تسلسلاً مفيداً: اختبر النموذج المستضاف الآن، ثم قرر ما إذا كان إصدار الأوزان اللاحق يناسب النشر الخاص، أو الضبط الدقيق، أو التقييم الداخلي.
حد سعر واضح. تقول MiniMax إن استدعاءات API التي تصل إلى 512 ألف رمز مدخل أو أقل تستخدم السعر القياسي. تبدأ تسعيرة السياق الطويل الأعلى فوق 512 ألف رمز، حيث تقوم الفرق عادةً بتشغيل أحمال عمل كاملة المستودع، أو كاملة المستند، أو فيديو طويل. يدعم M3 أيضاً خيار التفكير (thinking toggle) بنفس السعر، بحيث يمكن للفرق استخدام وضع الاستدلال للمهام الأكثر صعوبة، ووضع أسرع للإكمال الحساس لزمن الاستجابة.
كيف تبدو تكلفة التشغيل
يتم تسعير MiniMax M3 على Atlas Cloud بـ USD0.30 لكل مليون رمز مدخل وUSD1.20 لكل مليون رمز مخرج. Claude Opus 4.7 بسعر USD5 لكل مليون مدخل وUSD25 لكل مليون مخرج، بينما GPT-5.5 بسعر USD5 لكل مليون مدخل وUSD30 لكل مليون مخرج.
هذا يجعل M3:
- أرخص بنسبة 94% في المدخلات مقارنة بكل من Opus 4.7 وGPT-5.5
- أرخص بنسبة 95.2% في المخرجات مقارنة بـ Opus 4.7
- أرخص بنسبة 96% في المخرجات مقارنة بـ GPT-5.5
سعر الرمز لا يهم إلا بعد ربطه بشكل حمل العمل. وكيل البرمجة الذي لديه مستودع كبير في السياق ينفق معظم أمواله على المدخلات. سير عمل البحث أو الصياغة مع تفسيرات طويلة ينفق المزيد على المخرجات. وكيل الواجهة الرسومية متعدد الوسائط يدفع أيضاً مقابل السياق المرئي، ويعتمد تحويل الرمز على المزود.
استخدم الجدول أدناه كترجمة لقائمة الأسعار، وليس كمعيار قياسي. يفترض أسعار بالدولار الأمريكي، ولا توجد ضربات ذاكرة مؤقتة (cache hits)، ولا خصومات دفعات، ولا أقساط إقليمية، ولا رسوم استدعاء أدوات، ولا عمليات إعادة محاولة. بالنسبة لـ GPT-5.5، تقول OpenAI إن المطالبات التي تتجاوز 272 ألف رمز مدخل يتم تسعيرها بـ 2x للمدخلات و1.5x للمخرجات للجلسة بأكملها، لذا يستخدم مثال السياق الطويل هذا السعر الفعلي الأعلى.
| النموذج | السعر المستخدم | 100 ألف مدخل + 5 آلاف مخرج | 500 ألف مدخل + 20 ألف مخرج | قراءة التكلفة |
|---|---|---|---|---|
| MiniMax M3 على Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | مسار متعدد الوسائط منخفض التكلفة. أغلى من DeepSeek Flash، لكنه أقل بكثير من تسعير النماذج الريادية المغلقة. |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | أرخص مسار مسمى للعمل عالي الحجم للنصوص فقط. استخدمه عندما لا تكون المدخلات المرئية جزءاً من المهمة. |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | قريب من M3 في تكلفة الرمز الصافي، لكنه للنصوص فقط. مقارنة أفضل للاستدلال والبرمجة بدون سياق مرئي. |
| Qwen3.7-Plus | $0.40 / $1.60 حتى 256 ألف; $1.20 / $4.80 فوق 256 ألف | $0.05 | $0.70 | تنافسي لاستدعاءات تعدد الوسائط الأقصر. تسعير السياق الطويل يغير الاقتصاديات فوق 256 ألف. |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | أرخص من GPT وClaude، لكنه ليس خياراً افتراضياً للحجم الكبير ما لم يفز بالمهمة. |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | مسار متميز للبرمجة عالية المخاطر، واستخدام الأدوات، وموثوقية السياق الطويل. |
| GPT-5.5 | $5 / $30 قياسي; $10 / $45 فوق 272 ألف مدخل | $0.65 | $5.90 | استخدمه عندما يعوض استخدام النموذج للأدوات، أو سلوك استخدام الحاسوب، أو كفاءة الرموز عن القسط الإضافي. |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | احتفظ به لأصعب الأعمال. السعر يضعه في فئة ميزانية مختلفة. |
قراءة التكلفة: M3 ليس أرخص نموذج نصي في القائمة. لا يزال DeepSeek V4 Flash يفوز إذا كان حمل العمل نصياً فقط، وعالي الحجم، ومتحملاً لفئة قدرات Flash. حجة تكلفة M3 مختلفة: فهي تضع مدخلات الصور والفيديو الأصلية، وسياق العمل الطويل، والبرمجة الوكالية في نطاق سعري قريب من DeepSeek V4 Pro وأقل بكثير من GPT-5.5 وGPT-5.5 Pro وClaude Opus 4.8.
بالنسبة لدورة وكيل بـ 500 ألف مدخل و20 ألف مخرج، فإن M3 أرخص بحوالي 17 مرة من Claude Opus 4.8 وحوالي 34 مرة أرخص من GPT-5.5 بمجرد تطبيق مضاعف السياق الطويل لـ OpenAI. إنه أرخص بحوالي 4 مرات من Qwen3.7-Plus عند هذا الحجم من الطلب وحوالي 8 مرات أرخص من Qwen3.7-Max. مقابل DeepSeek، تعتمد الإجابة على الوسائط: DeepSeek V4 Flash لا يزال أرخص، بينما يقع V4 Pro في نفس النطاق الواسع. إذا كانت المهمة تحتوي على لقطات شاشة، أو رسوم بيانية، أو حالة واجهة مستخدم، أو إطارات فيديو، يمكن لـ M3 تجنب خطوة التوجيه الإضافية إلى نموذج رؤية منفصل.
على المستوى الشهري، يكون الفارق أوضح. حمل عمل بـ 10 ملايين رمز مدخل ومليون رمز مخرج يكلف حوالي 4.20 دولار على M3، و1.68 دولار على DeepSeek V4 Flash، و5.22 دولار على DeepSeek V4 Pro، و75 دولار على Claude Opus 4.8، و80 دولار على GPT-5.5 بالأسعار القياسية، و480 دولار على GPT-5.5 Pro. يقع Qwen3.7-Plus بين 5.60 دولار و16.80 دولار اعتماداً على ما إذا كان كل طلب يبقى أقل أو أعلى من حد تسعير 256 ألف؛ ويصل Qwen3.7-Max إلى حوالي 32.50 دولار.
توصيتنا: تعامل مع النماذج باهظة الثمن كمسارات تحتاج إلى كسب مكانتها. إذا أنهى GPT-5.5 أو Opus 4.8 مهمة صعبة في تشغيل واحد بينما يحتاج M3 إلى ثلاث عمليات إعادة محاولة وتصحيح بشري، فإن الاستدعاء الرخيص لم يكن رخيصاً. إذا كانت المهمة عبارة عن تحليل متعدد الوسائط طويل السياق، أو تصنيف برمجي على مستوى المستودع، أو أتمتة تذاكر الدعم بلقطات الشاشة، أو عمل مستندات حيث يتجاوز M3 حاجز الجودة، فإن اقتصادياته تجعله مرشحاً جاداً للتوجيه بدلاً من كونه مجرد فضول أسبوع إطلاق.
اقرأ المعايير القياسية كبيانات من المورد
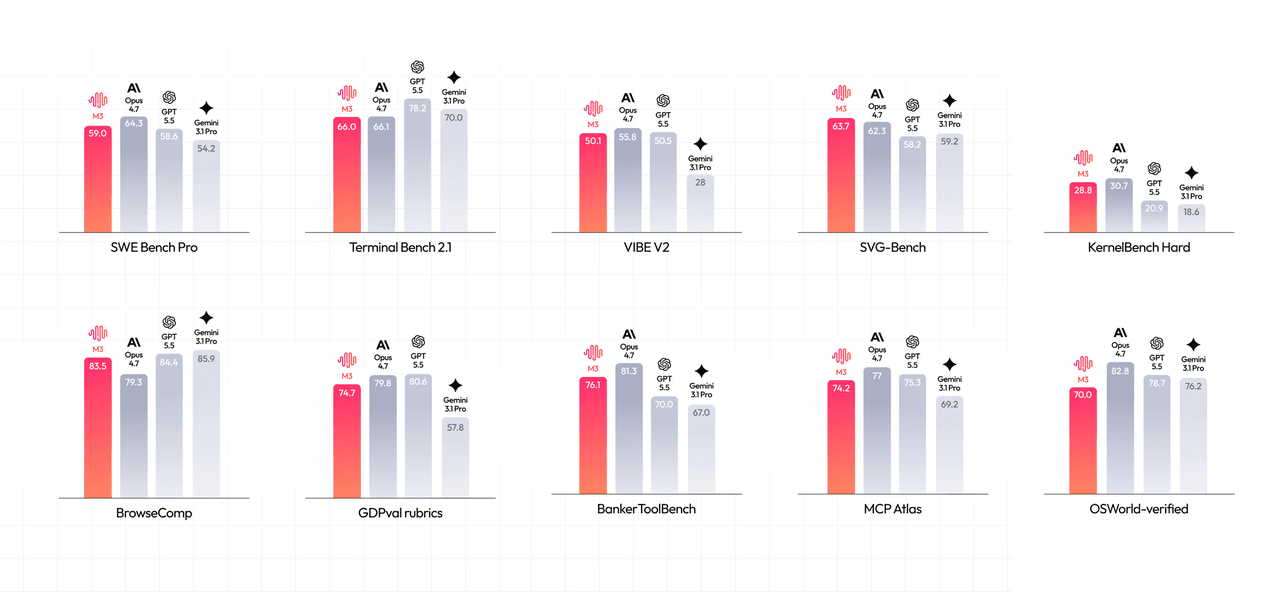
تشير MiniMax إلى نتائج قوية عبر مهام البرمجة والمهام الوكالية:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas (معيار قياسي لاستخدام أدوات MCP من طرف ثالث — لا علاقة له بـ Atlas Cloud): 74.2%
- BrowseComp: 83.5، مقارنة بـ 79.3 لـ Claude Opus 4.7 في مقارنة MiniMax
ملاحظة واحدة على السطر الأخير: تقارن MiniMax نموذج M3 بـ Opus 4.7، لكن Opus 4.8 تم إطلاقه في 28 مايو، قبل أربعة أيام من إطلاق M3. كانت مقارنة الإطلاق متأخرة بالفعل بإصدار واحد في اليوم الأول — تفصيل صغير، ولكنه معاينة للنقطة الأكبر أدناه.
في PostTrainBench، الذي يطلب من النموذج تصنيع بيانات، وتدريب، وتقييم، وتكرار أربعة نماذج أساسية في غضون 12 ساعة، تشير MiniMax إلى M3 عند 0.37 في منشور الإصدار، وهو ما يعادل النتيجة 37.1 المعروضة على صفحة النموذج الخاصة به. هذا الترتيب خلف Opus 4.7 عند 0.42 وGPT-5.5 عند 0.39، ولكنه يتقدم على بقية المجال المبلغ عنه.
تلك النتائج مفيدة للتصنيف (triage). إنها ليست كافية لاتخاذ قرار إنتاجي. قامت MiniMax بتشغيل العديد من الاختبارات على بنيتها التحتية الخاصة، واستخدمت العديد من التقييمات سقالات (scaffolding) محددة. قبل أن يستخدم فريق نتيجة في عرض مبيعات أو قرار معماري، يجب عليه إعادة تشغيل المهمة مقابل الكود الخاص به، والمستندات، والمطالبات، وأهداف زمن الاستجابة، والميزانية.
كيفية تقييم M3 مقابل النماذج الريادية الحالية
استخدم M3 كمرشح للتقييم، وليس كخيار افتراضي. يمكن لنافذة بحجم مليون رمز إخفاء بنية سيئة إذا قمت بملئها بملفات غير ذات صلة، أو سجلات قديمة، أو كل رسالة أرسلها المستخدم على الإطلاق.
قم بتشغيل نفس مجموعة الاختبار مقابل GPT-5.5 وClaude Opus 4.8 وQwen3.7-Plus أو Max وDeepSeek-V4-Pro أو Flash وM3. ثم قارن النتائج حسب المهمة، وليس حسب سمعة المزود.
ابدأ بستة اختبارات:
- البرمجة كاملة المستودع: امنح كل نموذج نفس المشكلة، وشريحة المستودع، والوصول إلى الأدوات، والمهلة الزمنية. سجل جودة التصحيح، ومعدل تمرير الاختبار، وحجم الاختلاف (diff)، والتعديلات غير الضرورية.
- استرجاع السياق الطويل: ضع تفاصيل ذات صلة في بداية ونهاية السياق. أضف مشتتات متشابهة. تحقق مما إذا كان كل نموذج يسترجع المثيل الصحيح، وليس مجرد أي عبارة مطابقة.
- تحمل حلقة الأدوات: قم بتشغيل مهمة تحتاج إلى 30، 60، وأكثر من 100 استدعاء للأدوات. راقب ما إذا كان كل نموذج يحافظ على خطة مستقرة، أو يكرر نفسه، أو يفقد قيوداً سابقة، أو يتوقف قبل اكتمال المهمة.
- عمل الوكيل المرئي: امنح كل نموذج متعدد الوسائط تذكرة دعم بالإضافة إلى لقطات شاشة، أو ورقة بحثية بالإضافة إلى رسوم بيانية، أو مواصفات منتج بالإضافة إلى لقطات واجهة المستخدم. بالنسبة لمسارات النصوص فقط أو الرؤية الأضعف، قم بقياس تكلفة التسليم الإضافية إلى نموذج رؤية منفصل.
- زمن الاستجابة تحت سياق حقيقي: قارن الوقت للرمز الأول وإجمالي وقت الإكمال عند 128 ألف، و512 ألف، ومليون رمز مدخل. لا تقبل ادعاء نافذة المليون رمز بدون بيانات زمن الاستجابة.
- التكلفة لكل مهمة مكتملة: قم بقياس رموز المدخلات، ورموز المخرجات، وإعادة المحاولات، واستدعاءات الأدوات، وضربات الذاكرة المؤقتة، وزمن الاستجابة، والتصحيح البشري. يمكن أن يكلف استدعاء نموذج أرخص أكثر إذا كان يحتاج إلى ثلاث عمليات إعادة محاولة.
هذا هو المكان الذي تخطئ فيه معظم الفرق في مسألة النموذج. إنهم يسألون أي نموذج لديه أفضل معيار قياسي للإطلاق. سؤال الإنتاج أضيق: أي نموذج يكمل سير العمل هذا بالجودة وزمن الاستجابة والتكلفة التي يمكن لمنتجك تحملها؟
كيف يحافظ MSA على قابلية استخدام السياق الطويل
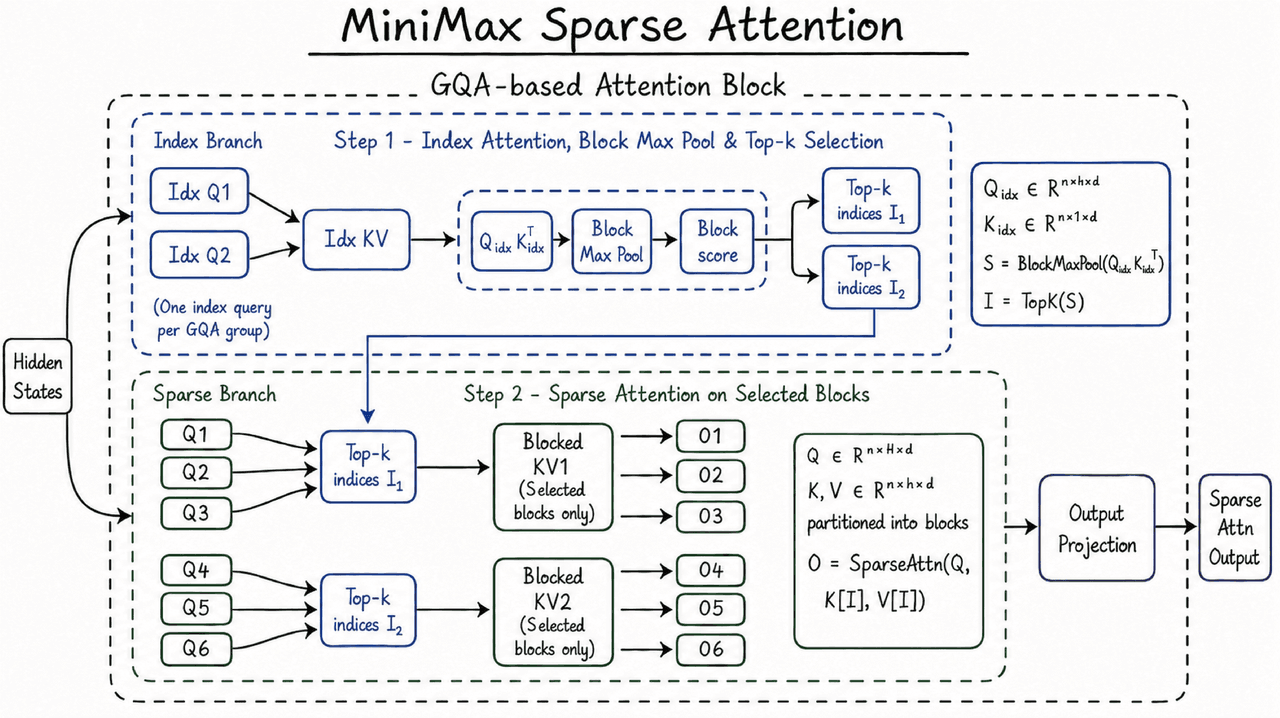
تعتمد نافذة سياق M3 على MiniMax Sparse Attention أو MSA.
يتيح الانتباه الكامل لكل رمز الانتباه لكل رمز آخر. مع زيادة طول التسلسل، ينمو العمل مع مربع طول التسلسل. يضيف الانتباه المتناثر خطوة اختيار، ثم يقوم بتشغيل الانتباه على أجزاء السياق السابق التي تهم أكثر من غيرها.
تقول MiniMax إن MSA تقسم ذاكرة التخزين المؤقت KV إلى كتل وتختار على مستوى الكتلة. تخزن ذاكرة التخزين المؤقت KV متجهات المفاتيح والقيم من الرموز السابقة، وهي تقود حصة كبيرة من حركة مرور الذاكرة في استدلال السياق الطويل. تصف MiniMax أيضاً تصميم عامل يسمى "KV outer gather Q": تصبح كتل KV هي الحلقة الخارجية، يتم تجميع الاستعلامات التي تصيب كتلة إليها، وتتم قراءة كل كتلة مرة واحدة، ويبقى الوصول إلى الذاكرة متصلاً.
في منشور إصدار MiniMax، يعمل هذا التصميم أسرع بأكثر من 4 مرات من Flash-Sparse-Attention مفتوح المصدر وflash-moba تحت تكوين رأس M3. تقول MiniMax أيضاً إن MSA طابق الانتباه الكامل في الغالبية العظمى من عمليات الاستئصال (ablations).
الادعاء الهندسي مهم لأن نافذة المليون رمز لا قيمة لها إذا لم تستطع الفرق تحمل تكلفة استخدامها. MSA هو السبب الذي يجعل MiniMax قادرة على القول إن السياق الطويل جزء من نموذج التشغيل العادي لـ M3، وليس وضع عرض لمرة واحدة. كما أنه ليس فريداً: تشحن DeepSeek V4 هجيناً من Compressed Sparse Attention وHeavily Compressed Attention لنفس السبب. أصبح السياق الطويل الرخيص معياراً معمارياً افتراضياً.
الاتجاه الأكبر: عمليات إطلاق النماذج أصبحت أحداث توجيه
M3 ليس إصداراً معزولاً. إنه يناسب نمطاً يتنامى عبر السوق.
الاتجاه الأكثر وضوحاً هو التقويم. في حوالي ستة أسابيع، تم شحن أربعة نماذج بسياق مليون رمز:
- DeepSeek V4-Pro وV4-Flash — 24 أبريل، مفتوح الأوزان، سياق مليون رمز، أوضاع تفكير/عدم تفكير
- Qwen3.7-Max — 20 مايو، نموذج رائد للاستدلال للنصوص فقط، سياق مليون رمز (تبعته Qwen3.7-Plus متعددة الوسائط في أوائل يونيو)
- Claude Opus 4.8 — 28 مايو، مع نافذة سياق بمليون رمز لعائلة Opus
- MiniMax M3 — 1 يونيو، سياق مليون رمز بالإضافة إلى تعدد وسائط أصلي ومسار مفتوح الأوزان
انتقلت نافذة المليون رمز من ميزة تنافسية إلى معيار أساسي في ربع واحد. يحدث الشيء نفسه للانتباه المتناثر، ومفاتيح التفكير، ومعايير الوكلاء، وتسعير السياق الطويل المتدرج. توقع أن تستمر صفحات النماذج في التقارب على نفس الميزات الرئيسية.
كما أن الوتيرة تتجاوز التسويق. تقارن معايير إطلاق M3 الخاصة بـ MiniMax النموذج بـ Opus 4.7، لكن Opus 4.8 تم شحنه قبل أربعة أيام. النموذج الذي قمت بالقياس ضده الأسبوع الماضي ليس هو النموذج الذي يقوم منافسك بتشغيله هذا الأسبوع. هذا هو عالم أحداث التوجيه في مثال واحد.
هذا لا يجعل M3 غير ذي صلة، لكنه يغير ما يجب على البنائين تحسينه.
ستتضاءل ميزة النموذج بشكل أسرع من عمل التكامل حوله. إذا قام فريق ببرمجة مزود واحد في حزمة الوكيل الخاصة به، يصبح كل إصدار رئيسي مشروع ترحيل. إذا قام فريق بالتوجيه حسب المهمة، والسعر، وزمن الاستجابة، والوسائط، ونتائج التقييم، يصبح كل إصدار رئيسي تحديثاً للتوجيه.
الفائز ليس الفريق الذي يختار نموذجاً واحداً ويدافع عنه لمدة عام. الفائز هو الفريق الذي يمكنه اختبار M3 اليوم، ومقارنته بـ GPT-5.5 وClaude Opus 4.8 وQwen3.7 وDeepSeek-V4 غداً، ونقل حركة المرور عندما تقول الأرقام ذلك.
ما يمكن للمزودين الآخرين نسخه، وما لا يمكنهم نسخه
يمكن للمزودين نسخ مساحة السطح أولاً:
- نوافذ سياق أطول
- متغيرات الانتباه المتناثر
- أوضاع التفكير تشغيل/إيقاف
- صفحات معايير وكلاء البرمجة
- عروض إطلاق متعددة الوسائط
- مراسلات مفتوحة الأوزان أو قريبة من مفتوحة الأوزان
الأجزاء الأكثر صعوبة تستغرق وقتاً أطول:
- خدمة سياق طويل مستقرة تحت تزامن حقيقي
- جودة عميقة في السياق، خاصة مع المشتتات
- موثوقية الوكيل بعد العديد من استدعاءات الأدوات
- محاذاة متعددة الوسائط عبر النصوص، والصور، والرسوم البيانية، والفيديو
- تسعير يصمد عندما يستخدم العملاء النافذة بأكملها
- معرفات نموذج واضحة، وإصدارات، ونسخ احتياطية يمكن لفرق الإنتاج الوثوق بها
تلك الفجوة هي حيث يجب على البنائين قضاء وقت التقييم الخاص بهم. لا تسأل فقط عما إذا كان بإمكان مزود آخر الإعلان عن نافذة مليون رمز. اسأل عما إذا كان النموذج لا يزال يتبع التعليمات المدفونة في الرمز 750,000، وما إذا كان بإمكانه مقارنة لقطتي شاشة متشابهتين دون انحراف، وما إذا كان زمن الاستجابة يظل مقبولاً، وما إذا كانت الاقتصاديات تصمد أمام حركة المرور الفعلية للمستخدم.
لماذا تقوم بتشغيله عبر Atlas Cloud
تمنح Atlas Cloud الفرق مفتاح API واحداً لأكثر من 300 نموذج عبر أحمال عمل LLM، والصور، والفيديو، والصوت. هذا يهم أكثر مع تقارب إصدارات النماذج على نفس الميزات الرئيسية.
يمكنك اختبار M3 مقابل النماذج الموجودة بالفعل في حزمتك، وتوجيه حركة المرور إلى حيث يعمل بشكل أفضل، والحفاظ على استقرار سطح التكامل مع وصول إصدارات جديدة. يمكنك الاحتفاظ بـ GPT-5.5 حيث يفوز في أعمال استخدام الحاسوب، والاحتفاظ بـ Claude Opus 4.8 حيث يفوز في وكلاء البرمجة طويلة الأمد، واستخدام Qwen3.7-Plus حيث يفوز وكلاء الواجهة الرسومية متعدد الوسائط، واستخدام DeepSeek-V4 حيث يفوز السعر/الأداء، وإضافة M3 حيث يغير السياق الطويل بالإضافة إلى تعدد الوسائط الأصلي النتيجة.
استخدم M3 حيث يؤتي سياقه الطويل وتعدد وسائطه ثمارهما. احتفظ بالنماذج الأخرى حيث لا تزال تفوز. قم بالتبديل بناءً على التقييمات، وليس ضجيج أسبوع الإطلاق.
[CTA - نوايا الباني: تشغيل M3 على Atlas Cloud -> atlascloud.ai/models | الحصول على مفتاح API -> console.atlascloud.ai]






