Kimi K2.6 مقابل GLM 5.1 مقابل Qwen 3.6 Plus مقابل MiniMax M2.7: أي نموذج مفتوح المصدر هو الأفضل للبرمجة في عام 2026

الإجابة المختصرة
إذا كنت تبني وكيل برمجة ذاتي التشغيل (Autonomous Coding Agent) يعمل لساعات دون تدخل: Kimi K2.6. فقد حقق 66.7% في اختبار Terminal-Bench 2.0، ونجح في إجراء أكثر من 4,000 استدعاء للأدوات (tool calls) خلال جلسة متواصلة استمرت 13 ساعة في الاختبارات المنشورة — وهو مستوى ثبات لا يصل إليه أي نموذج مفتوح آخر في هذه المقارنة.
إذا كنت بحاجة إلى أفضل نموذج لتطوير الواجهات الأمامية (Front-end Agent): GLM 5.1. حيث يعكس تصنيفه المستقل في Code Arena Elo بـ 1,530 نقطة (الثالث عالمياً في تطوير الويب الوكيلي) تفضيل المطورين الفعلي في المقارنات المباشرة، وليس فقط نتائج الاختبارات الآلية.
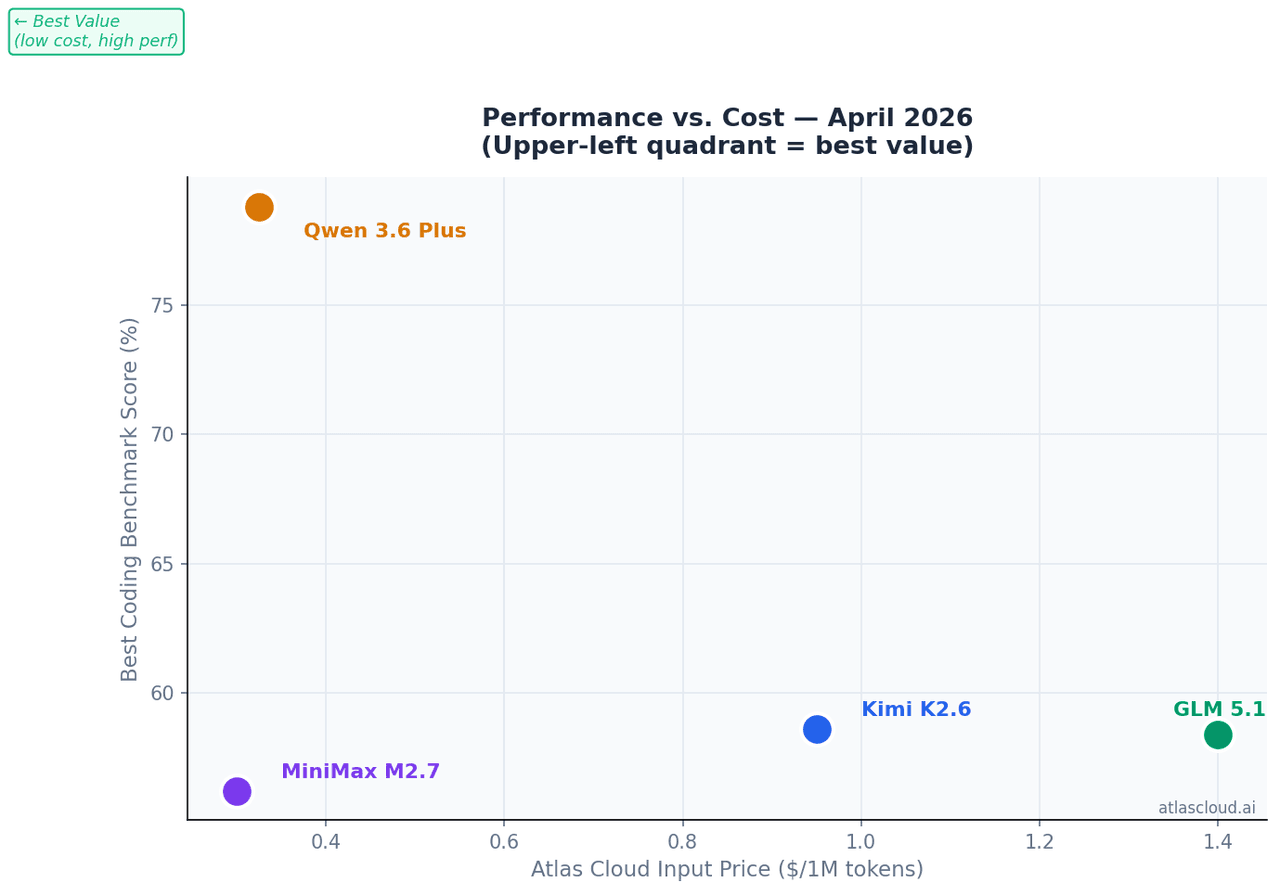
إذا كانت التكلفة لكل توكن هي العامل الحاسم: MiniMax M2.7 بتكلفة USD0.30 لكل مليون توكن مدخل على Atlas Cloud، يحقق 56.22% في اختبار SWE-Bench Pro مع 10 مليار معامل نشط فقط — أي 94% من أداء GLM-5.1 بنحو خُمس التكلفة.
إذا كان حجم قاعدة الأكواد الخاصة بك أكبر من نافذة السياق التي تبلغ 262 ألف توكن: Qwen 3.6 Plus، وهو النموذج الوحيد هنا الذي يدعم سياقاً يصل إلى مليون توكن، كما أنه يتصدر مجموعة Terminal-Bench 2.0 بنسبة 61.6%.
نظرة سريعة على أهم الاختبارات
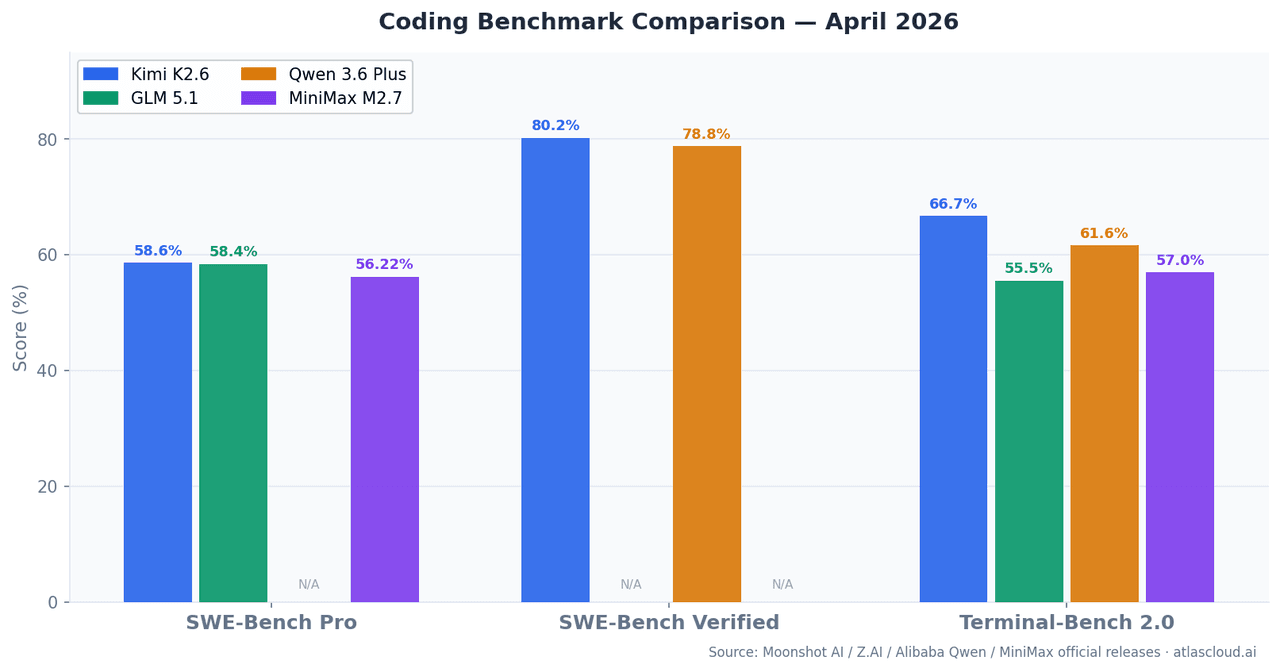
| النموذج | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | نافذة السياق | المعاملات النشطة |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | Hybrid MoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
يقيس SWE-Bench Pro القدرة على حل مشكلات GitHub الحقيقية التي تم طرحها بعد تاريخ قطع بيانات التدريب، مما يقلل من مخاطر تلوث البيانات مقارنة بـ SWE-Bench Verified. بينما يختبر Terminal-Bench 2.0 مهام سطر الأوامر (CLI) والمهام الصدفية (shell) في بيئات طرفية حقيقية، وهو ما يقترب أكثر مما تفعله الوكلاء في بيئات الإنتاج الفعلية.
Kimi K2.6: مصمم للوكلاء طويلي الأمد
أطلقت شركة Moonshot AI نموذج Kimi K2.6 في أبريل 2026 كترقية لنموذج K2.5، مع تحسينات رئيسية في استقرار الوكلاء خلال الجلسات الممتدة. بنسبة 80.2% في اختبار SWE-Bench Verified، يأتي النموذج مباشرة تحت Claude Opus 4.6 (80.8%)، ويتصدر النماذج الأربعة في اختبار SWE-Bench Pro بنسبة 58.6%.
الرقم الأكثر أهمية هو 66.7% في Terminal-Bench 2.0. يختلف هذا الاختبار عن SWE-Bench في جوهره: حيث ينفذ المهام داخل بيئات طرفية حقيقية، مما يتطلب من النموذج قراءة المخرجات، التعامل مع الأخطاء، التكيف، والتكرار — وليس فقط إنشاء رقع برمجية (patches). إن حفاظ Kimi K2.6 على أدائه عبر أكثر من 4,000 استدعاء للأدوات في جلسة واحدة استمرت 13 ساعة ليس مجرد نتاج مختبري، بل هو سلوك موثق في الإصدار التقني لشركة Moonshot.
ميزة أخرى لم يتم تسليط الضوء عليها كثيراً: التعميم عبر اللغات. يظهر Kimi K2.6 أداءً متسقاً عبر لغات Rust وGo وPython ومهام تطوير الواجهات وعمليات التطوير (DevOps). معظم تقييمات الاختبارات تركز بشكل كبير على Python، فإذا كان مكدس الإنتاج الخاص بك متعدد اللغات، فهذا الأمر مهم جداً.
متى لا يكون هو الخيار الأفضل: بتكلفة USD0.95 لكل مليون توكن مدخل على Atlas Cloud، يُعد K2.6 أغلى نموذج في هذه المجموعة من حيث المدخلات. بالنسبة لمهام المعالجة الجماعية (Batch processing) التي تتطلب إرسال العديد من الطلبات بسياقات كبيرة دون الحاجة إلى استقرار جلسة لمدة 12 ساعة، ستتراكم التكلفة بسرعة أكبر مقارنة بـ MiniMax M2.7 أو Qwen 3.6 Plus.
GLM 5.1: الأبرز في تطوير الواجهات الأمامية (Front-End)
أطلقت Z.AI نموذج GLM-5.1 في 7 أبريل 2026. بـ 754 مليار معامل مع تقنية توجيه MoE، هو النموذج الأكبر في هذه القائمة من حيث عدد المعاملات الخام. في اختبار SWE-Bench Pro، حقق 58.4%، وهي نتيجة متقاربة إحصائياً مع 58.6% الخاصة بـ Kimi K2.6.
عامل التميز هو تصنيف 1,530 في Code Arena Elo، الذي تم التحقق منه بشكل مستقل من قبل Arena.ai في 10 أبريل 2026، مما يضعه في المركز الثالث عالمياً على قائمة المتصدرين لتطوير الويب الوكيلي. هذه مقارنة مباشرة وحية حيث يصوت مطورون حقيقيون على المخرجات. تتركز ميزة هذا النموذج في توليد واجهات المستخدم (UI)، وهيكلة المكدس الكامل (full-stack)، وإنشاء مكونات React/Vue، وتقنية NL2Repo (توليد هياكل مستودعات كاملة من اللغة الطبيعية).
شرط الحدود الذي يجب معرفته: تفوق GLM-5.1 في الواجهات الأمامية حقيقي. أما بالنسبة للمسائل الخوارزمية البحتة في HumanEval وMBPP، فإنه لا يمتلك ميزة قابلة للقياس على Kimi K2.6. تتقلص الفجوة في لوحة الصدارة إلى ما يقرب من الصفر في المشكلات غير المتعلقة بواجهة المستخدم أو الويب. سيكون من الخطأ اختيار GLM-5.1 بناءً فقط على ترتيبه العام دون النظر إلى طبيعة المهام.
الأسعار على Atlas Cloud: تبدأ من USD1.40 لكل مليون توكن مدخل — وهي الأعلى بين الأربعة. وهذا مبرر عندما تؤثر جودة توليد الواجهات الأمامية بشكل مباشر على مخرجاتك.
Qwen 3.6 Plus: عندما يكون حجم السياق هو العائق الحقيقي
أطلقت Alibaba نموذج Qwen 3.6 Plus في أواخر مارس 2026. وهو يتصدر Terminal-Bench 2.0 في المقارنات المباشرة ضد Claude Opus 4.6 (61.6% مقابل 59.3%) ويحقق 78.8% في SWE-Bench Verified.
نافذة سياق بمليون توكن هي ما يميزه. بالنسبة لغالبية مهام البرمجة الإنتاجية التي تقل عن 100 ألف توكن، تمتلك جميع النماذج الأربعة سياقاً كافياً وتصبح الفجوة غير ذات أهمية. ولكن يصبح Qwen 3.6 Plus الخيار الوحيد القابل للتطبيق في الحالات التالية: تحليل المستودعات الضخمة (Monorepo) عبر مئات الملفات، إعادة هيكلة قواعد الأكواد القديمة واسعة النطاق، أو تدفقات عمل "المستند إلى كود" التي لا يمكن استيعابها في 262 ألف توكن.
كما توفر البنية الهجينة (الانتباه الخطي + توجيه MoE المتناثر) إنتاجية استدلال أفضل من نماذج المحولات الكثيفة (dense transformers) عند معالجة سياقات كبيرة جداً، مما يعني أن قدرة المليون توكن تأتي بتكلفة زمن استجابة (latency) منخفضة نسبياً مقارنة بالتوسع التقليدي.
الأسعار على Atlas Cloud: تبدأ من USD0.325 لكل مليون توكن مدخل. بالنسبة لمهام السياق الكبير، يعد هذا أفضل سعر مقابل قيمة توكن في هذه المجموعة.
MiniMax M2.7: حالة استثنائية من حيث الكفاءة
أصدرت MiniMax نموذج M2.7 في مارس 2026. مع 10 مليار معامل نشط فقط، يحقق 56.22% في اختبار SWE-Bench Pro — أي 94% من درجة GLM-5.1 بنحو خُمس التكلفة لكل توكن.
هذه نتيجة غير بديهية في هذه المقارنة. نموذج يقوم بتنشيط 10 مليار معامل عند الاستدلال يصل إلى أداء برمجي يقترب من النماذج الرائدة، لأن بنية MoE الخاصة به توجه المهام إلى شبكات فرعية متخصصة بدلاً من تشغيل كامل أوزان النموذج. النتيجة هي زمن استجابة أقل، تكلفة أقل، وجودة مخرجات تتجاوز ما يمكن أن يتوقعه المرء بناءً على عدد المعاملات وحده.
الفئة التي يتفوق فيها M2.7 على نقطة سعره هي: مهام هندسة تعلم الآلة. فقد سجل معدل ميداليات 66.6% في اختبار MLE-Bench Lite (22 مسابقة في تعلم الآلة)، ليأتي في المرتبة الثانية بعد النماذج الرائدة مغلقة المصدر. كتابة منطق تراكم التدرج الصحيح، تنفيذ طبقات PyTorch مخصصة، وتصحيح منحنيات الخسارة — يتعامل M2.7 مع هذه المهام بدقة لا تتناسب مع تكلفته.
ما يجب الحذر منه: مع نافذة سياق تبلغ 196 ألف توكن، يمتلك M2.7 أصغر نافذة في هذه المجموعة. المهام التي تتطلب تحليلاً عميقاً عبر الملفات في مستودعات ضخمة قد تصطدم بحدود يتجاوزها Qwen 3.6 Plus بسهولة.
الأسعار على Atlas Cloud: USD0.30 لكل مليون توكن مدخل، وUSD1.20 لكل مليون توكن مخرج — الخيار الأكثر بأسعار معقولة لأعباء العمل البرمجية ذات الإنتاجية العالية.
حالات اختبار برمجية واقعية
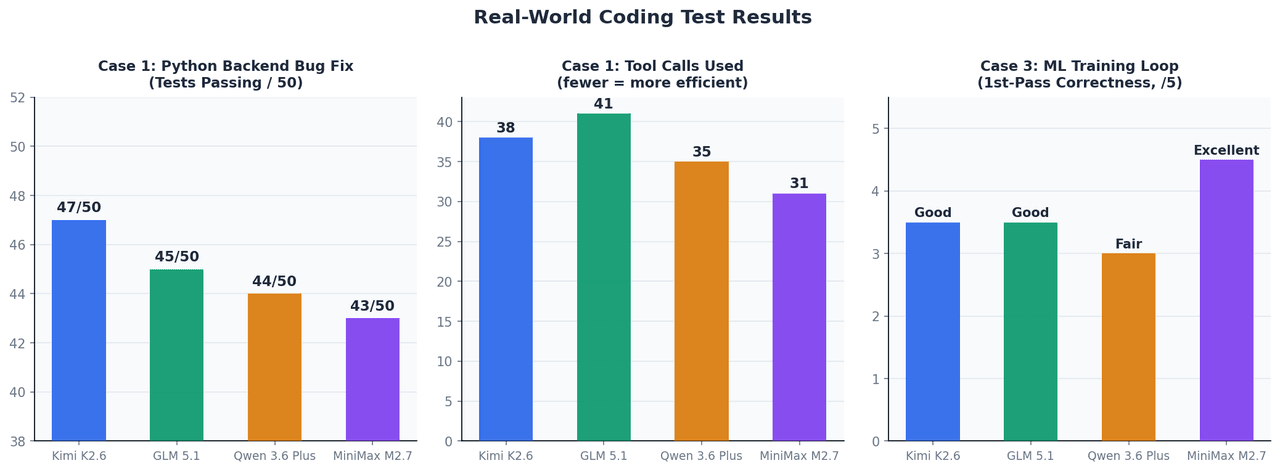
الحالة 1: إصلاح أخطاء ذاتي في خلفية (Backend) بلغة Python
الإعداد: تطبيق FastAPI مكون من 12 ملفاً، مع مجموعة اختبارات فاشلة (50 اختباراً)، ونافذة سياق تبلغ حوالي 45 ألف توكن. لا يُسمح بأي تدخل يدوي بعد التوجيه الأولي.
| النموذج | الاختبارات الناجحة بعد الإصلاح | استدعاءات الأدوات المستخدمة | وقت الإكمال |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 دقائق |
| GLM 5.1 | 45 / 50 | 41 | ~5 دقائق |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 دقائق |
| MiniMax M2.7 | 43 / 50 | 31 | ~3.5 دقائق |
عند هذا الحجم من السياق، تؤدي جميع النماذج الأربعة بشكل متقارب جداً. تفوق Kimi K2.6 في أصعب الأخطاء الطرفية — وتحديداً قضايا دورة حياة مدير سياق async (async context manager) وتضييق حدود TypeVar، والتي تتطلب الحفاظ على حالة الاستدلال عبر دورات تصحيح أخطاء متعددة.
الحالة 2: لوحة تحكم (Dashboard) بلغة React بناءً على مواصفات
الإعداد: إنشاء لوحة تحكم كاملة ومتجاوبة مع أربعة أنواع من الرسوم البيانية، ووضع ليلي، وأنواع TypeScript من مواصفات مكتوبة باللغة الإنجليزية.
نجح GLM-5.1 في إنتاج مكونات مكتوبة بـ TypeScript مع فئات Tailwind صحيحة من المحاولة الأولى. تطلب Kimi K2.6 تكراراً واحداً لحل أخطاء النوع. أنتج Qwen 3.6 Plus كود JSX صحيحاً وظيفياً ولكنه أقل اصطلاحية. كان MiniMax M2.7 هو الأسرع لكنه استخدم بعض أنماط React القديمة (deprecated) التي تتطلب تنظيفاً يدوياً.
الفجوة بين GLM-5.1 والآخرين كانت أكثر وضوحاً في هيكلية المكونات — حيث طبق GLM-5.1 أنماط التركيب وفصل الاهتمامات بشكل تلقائي ومميز.
الحالة 3: تنفيذ حلقة تدريب تعلم الآلة
الإعداد: تنفيذ حلقة تدريب PyTorch مع تراكم التدرج، والدقة المختلطة (AMP)، والإيقاف المبكر لنموذج Vision Transformer. الهدف: التشغيل بشكل صحيح من المحاولة الأولى دون دورات تصحيح أخطاء.
كان MiniMax M2.7 هو الأفضل — حيث وضع scaler.step() وscaler.update() بشكل صحيح بالنسبة لخطوة المحسن (optimizer step)، وهو تفصيل تضعه معظم النماذج بشكل خاطئ في المرة الأولى. كما تم التعامل مع تحجيم تراكم التدرج loss / accumulation_steps بشكل صحيح. وهذا يتماشى مباشرة مع معدل ميداليات 66.6% في MLE-Bench Lite.
مقارنة أسعار Atlas Cloud (أبريل 2026)
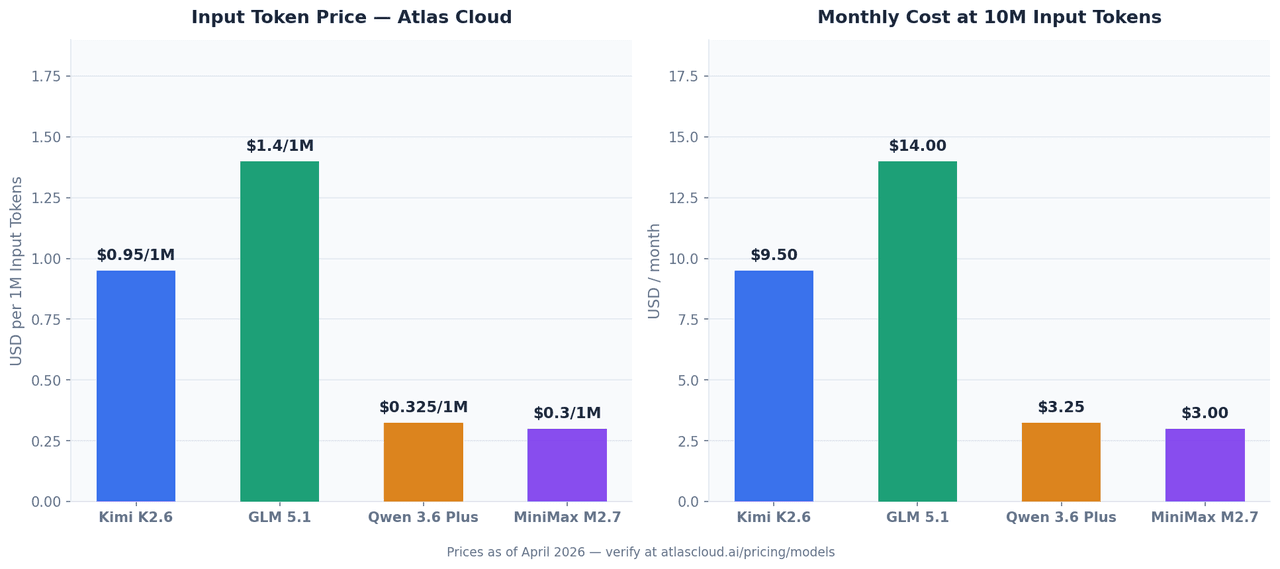
تتوفر جميع النماذج الأربعة عبر واجهة برمجة تطبيقات (API) موحدة على Atlas Cloud. الأسعار أدناه سارية اعتباراً من أبريل 2026 وقد تتغير — يرجى التأكد من الأسعار الحالية على atlascloud.ai.
| النموذج | المدخلات (لكل 1 مليون توكن) | المخرجات (لكل 1 مليون توكن) | معرف النموذج على Atlas Cloud |
|---|---|---|---|
| Kimi K2.6 | USD0.95 | USD4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | من USD1.40 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | من USD0.325 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | USD0.30 | USD1.20 | minimaxai/minimax-m2.7 |
بمعدل 10 مليون توكن مدخل شهرياً — وهو حجم واقعي لمساعد برمجة على مستوى الفريق:
| النموذج | تكلفة المدخلات الشهرية (10 مليون توكن) |
|---|---|
| GLM 5.1 | USD14.00 |
| Kimi K2.6 | USD9.50 |
| Qwen 3.6 Plus | USD3.25 |
| MiniMax M2.7 | USD3.00 |
استدعاء النماذج الأربعة باستخدام مفتاح API واحد
تشترك جميع النماذج الأربعة في نفس نقطة النهاية المتوافقة مع OpenAI على Atlas Cloud. التبديل بينها يتطلب تغيير سطر واحد فقط:
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# غير هذا السطر الوحيد للتبديل بين النماذج 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
هذا الهيكل المتوافق مع OpenAI يعني أن التكاملات الحالية المبنية على OpenAI SDK تعمل مع Atlas Cloud دون تعديل — فقط يتغير base_url وapi_key.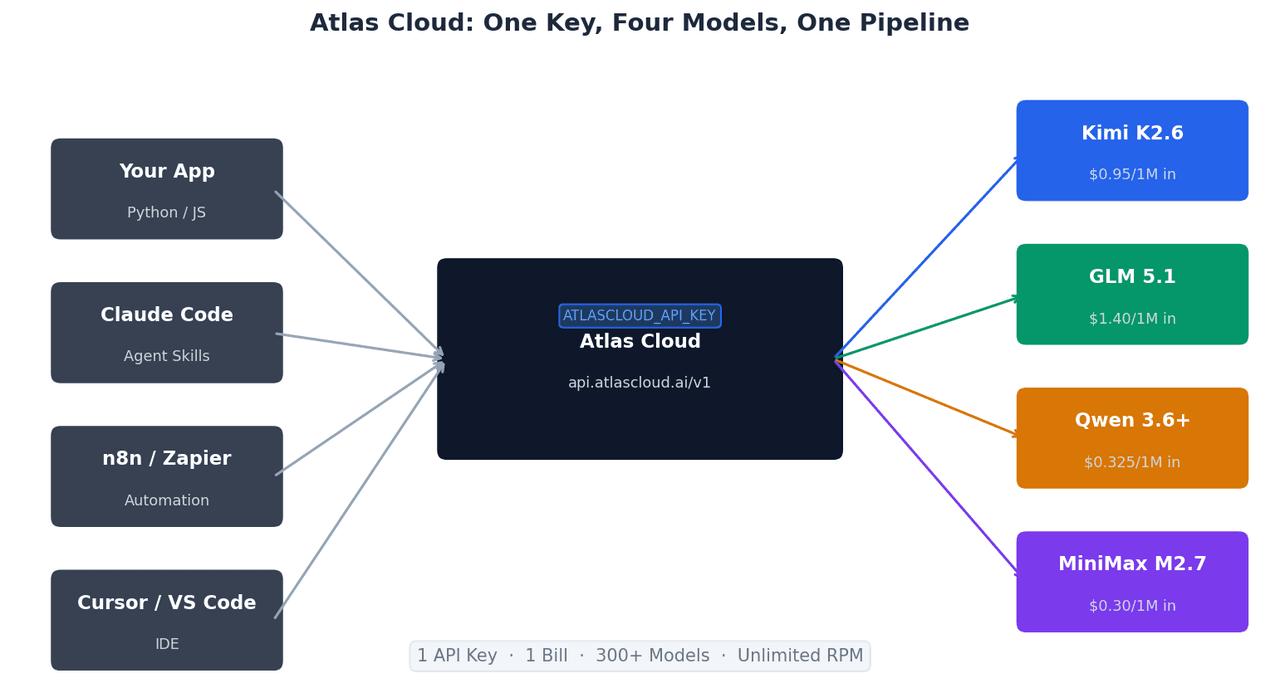
لماذا تستخدم Atlas Cloud لهذه النماذج
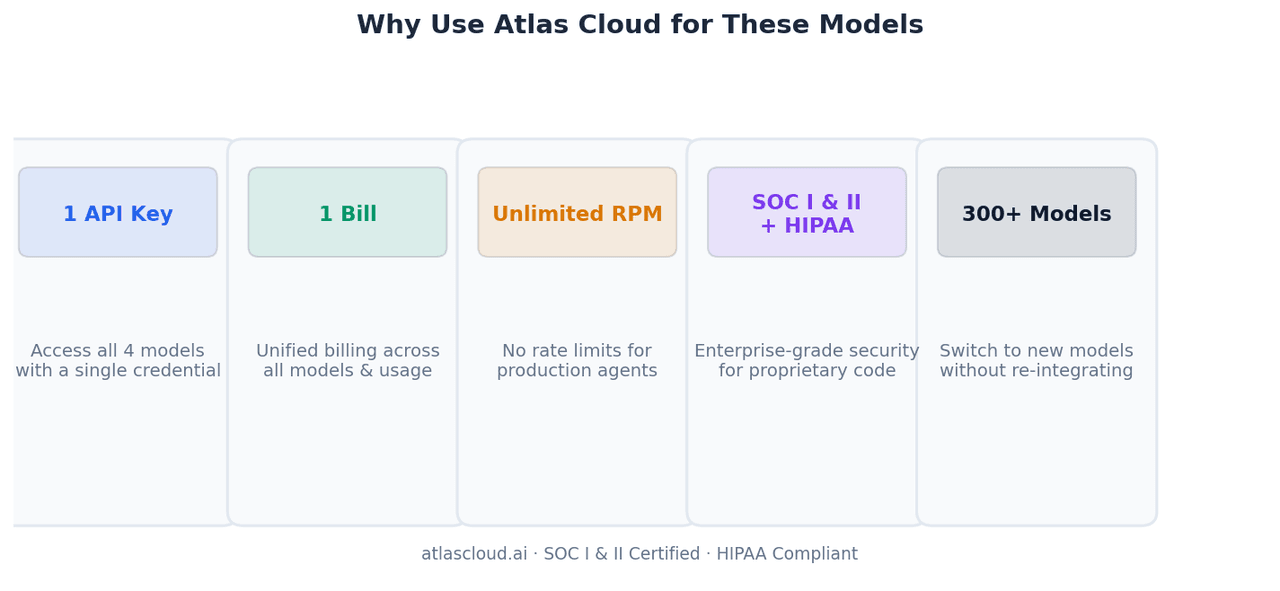
مفتاح API واحد، أربعة نماذج، فاتورة واحدة. يتطلب تشغيل منطق توجيه النماذج — إرسال مهام الواجهة الأمامية إلى GLM-5.1، وتحليل الدفعات إلى MiniMax M2.7، والوكلاء طويلي الأمد إلى Kimi K2.6 — إدارة بيانات اعتماد واحدة بدلاً من أربعة. التسوية الشهرية تتم بفاتورة واحدة.
عدد طلبات غير محدود (Unlimited RPM). يطلق وكلاء البرمجة الإنتاجيون استدعاءات متوازية للأدوات. يمكن أن تؤدي حدود المعدل (Rate limits) في واجهات برمجة التطبيقات المباشرة للمزودين إلى خنق خطوط أنابيب الوكلاء المتعددين. بينما تزيل Atlas Cloud هذا السقف.
حاصلة على شهادتي SOC I & II، ومتوافقة مع HIPAA. تحتاج الفرق التي تعالج كوداً برمجياً خاصاً عبر هذه النماذج إلى بنية تحتية قابلة للتدقيق. شهادات الامتثال الخاصة بـ Atlas Cloud تعني أن الكود الخاص بك لا يمر عبر نقاط نهاية غير موثقة.
أكثر من 300 نموذج، نفس نمط التكامل. عندما يتم إصدار النسخة التالية من أي من هذه النماذج، أو عندما يتفوق نموذج جديد عليها في عبء عملك الخاص، فإن إضافته إلى منطق التوجيه الخاص بك يتطلب تغيير سلسلة نصية واحدة — وليس تكامل SDK جديد.
أي نموذج لأي مهمة
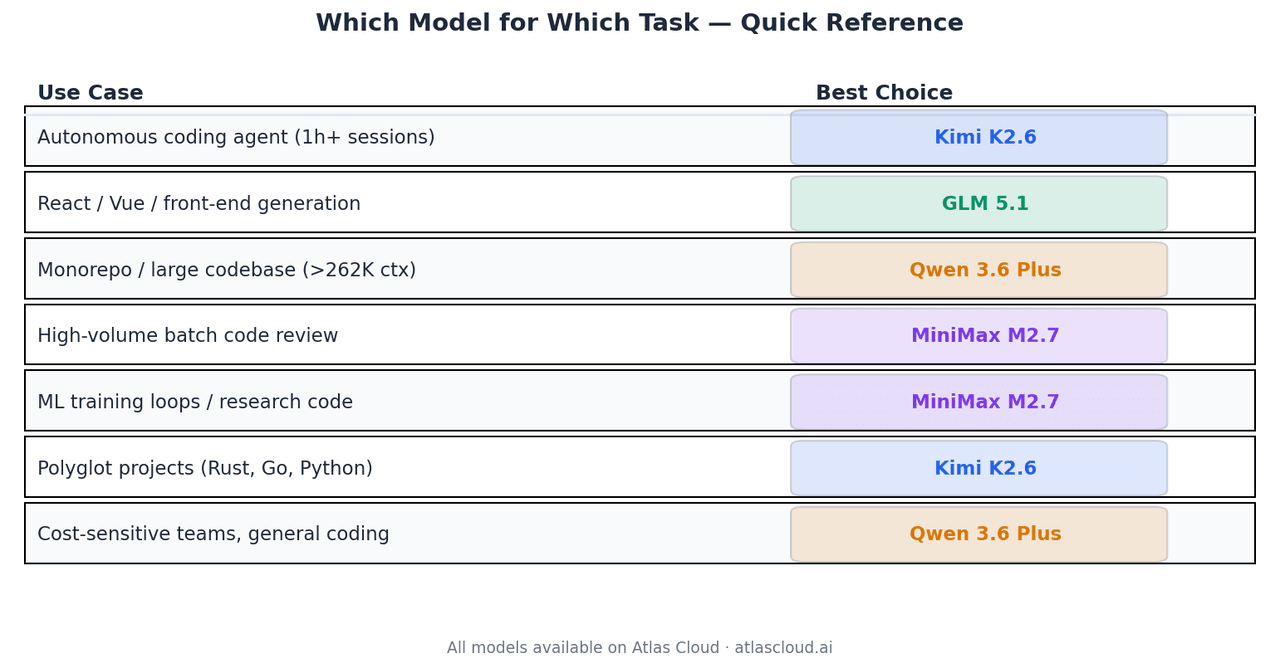
| حالة الاستخدام | الخيار الأفضل | لماذا |
| وكيل برمجة ذاتي، جلسات أكثر من ساعة | Kimi K2.6 | 66.7% في Terminal-Bench 2.0، استقرار لأكثر من 4 آلاف استدعاء أداة |
| توليد الواجهات الأمامية (React/Vue) | GLM 5.1 | Code Arena Elo 1,530، ضمن أفضل 3 عالمياً |
| تحليل المستودعات الضخمة | Qwen 3.6 Plus | النموذج الوحيد هنا بنافذة سياق 1 مليون توكن |
| مراجعة الكود الجماعية ذات الحجم الكبير | MiniMax M2.7 | USD0.30 للمدخلات، جودة تعادل 94% من GLM-5.1 |
| حلقات تدريب ML، كود البحث | MiniMax M2.7 | معدل ميداليات 66.6% في MLE-Bench Lite |
| مشاريع متعددة اللغات (Rust, Go, Python) | Kimi K2.6 | تعميم موثق عبر اللغات |
| فرق حساسة للتكلفة، برمجة عامة | Qwen 3.6 Plus | USD0.325 للمدخلات، أداء قوي عبر جميع الفئات |
ملخص
تتفصل هذه النماذج الأربعة بهوامش ضيقة في الاختبارات المعيارية. تظهر الفروق الجوهرية في ظروف محددة.
يعد Kimi K2.6 هو الإجابة الصحيحة للوكلاء ذاتيي التشغيل طويلي الأمد. ويقود GLM 5.1 مهام الوكيل للواجهة الأمامية. ويبقى Qwen 3.6 Plus الخيار الوحيد عندما يتجاوز السياق 262 ألف توكن. بينما يعتبر MiniMax M2.7 الخيار الافتراضي الأكثر كفاءة للفرق التي تشغل نماذج برمجة على نطاق واسع.
جميع النماذج الأربعة متاحة على Atlas Cloud عبر atlascloud.ai تحت مفتاح API واحد، مع تسعير "الدفع لكل توكن" وبدون التزام حد أدنى.
تم الحصول على بيانات الاختبارات المعيارية من المدونة التقنية لشركة Moonshot AI، ووثائق مطوري Z.AI، ومنشور إصدار فريق Alibaba Qwen، وصفحة نموذج MiniMax الرسمية، والتقييمات المستقلة من Arena.ai. جميع الاختبارات بناءً على بيانات أبريل 2026. أسعار Atlas Cloud المذكورة صحيحة وقت النشر — يرجى التحقق من الأسعار الحالية قبل النشر في بيئة الإنتاج.






