
كشفت MiniMax للتو عن تسريع في سرعة فك التشفير بمقدار 15.6 ضعفاً عند سياق 1 مليون رمز (Token). إذا ثبتت صحة هذا الرقم، فإن تكلفة تشغيل سياق بمليون رمز ستنخفض بمقدار يقارب رتبة مقدارية كاملة — كما سيصبح توليد النصوص أسرع، وليس أبطأ، أثناء القيام بذلك.
بالنسبة لأي شخص يبني تطبيقاته على هذه النماذج، فإن هذا يعيد تعريف ما يمكن اعتباره "ميسور التكلفة". فمهام العمل التي لم تكن مجدية اقتصادياً بالأمس تبدأ في أن تصبح كذلك: تزويد وكيل برمجي بقاعدة التعليمات البرمجية بالكامل بدلاً من أجزاء منها، وتشغيل وكلاء لعدة ساعات مع تراكم سجلات ضخمة، وإجراء عمليات استرجاع عبر مجموعات مستندات كاملة بدلاً من مقتطفات مجزأة. السؤال الذي تواجهه كل الفرق — ما هو مقدار البيانات التي يمكنني حشرها في نافذة السياق قبل أن تقتل الفاتورة أو زمن الاستجابة المنتج؟ — أصبح له سقف أعلى بكثير.
الآلية المستخدمة هي الانتباه المتناثر (Sparse Attention)، وMiniMax ليست وحدها في هذا. فقد طرحت DeepSeek هذه التقنية عبر ثلاثة خطوط من نماذجها، ولدى Qwen نسختها الخاصة، والآن تأتي MiniMax. الاتجاه العام أصبح واضحاً. ما يتغير هو العواقب: عندما تتمكن كل نماذج المواجهة (Frontier models) من تشغيل سياق طويل بتكلفة زهيدة، يتوقف النموذج عن كونه الميزة التنافسية (الخندق) — وهذا هو الجزء الذي يستحق اهتمامك، وهو ما سنعود إليه في الختام.
بدايةً، هناك تنبيهان صريحان لأنها مهمة لأي شخص يخطط لنشر هذه التقنية فعلياً:
- هذه الأرقام هي تقديرات MiniMax الخاصة، من مخطط تشويقي وحيد لنموذج لم يُطرح بعد، وعلى بيئتهم الخاصة. إنها إشارة قوية على التوجه، وليست تقييماً من طرف ثالث. تعامل معها كـ "ما تدعيه MiniMax"، وأعد الاختبار على حمل عملك الخاص بمجرد توفر الأوزان.
- نموذج M3 ليس متاحاً للجمهور بعد. نتوقع توفيره في Atlas Cloud مع دخول في اليوم الأول (day-zero access) عند إطلاقه — المزيد حول هذا في النهاية.
فكيف تحقق MiniMax ذلك؟ في 26 مايو، نشر "سكايلر مياو"، رئيس البحث والتطوير في MiniMax، مخططاً واحداً على منصة X — يتميز بلوحة ألوان هادئة ومحتوى مكثف — بعنوان MiniMax Sparse Attention، مع منحنيين يحملان الأرقام التي لفتت انتباه الجميع: تسريع 9.7 ضعفاً في مرحلة التعبئة المسبقة (Prefill)، وتسريع 15.6 ضعفاً في مرحلة فك التشفير (Decode) عند 1 مليون رمز. تعامل المجتمع التقني مع هذا المنشور بالإجماع تقريباً على أنه تشويق لـ M3. قمنا بتفكيك المخطط لفهم الهندسة المعمارية خلف هذه الأرقام.
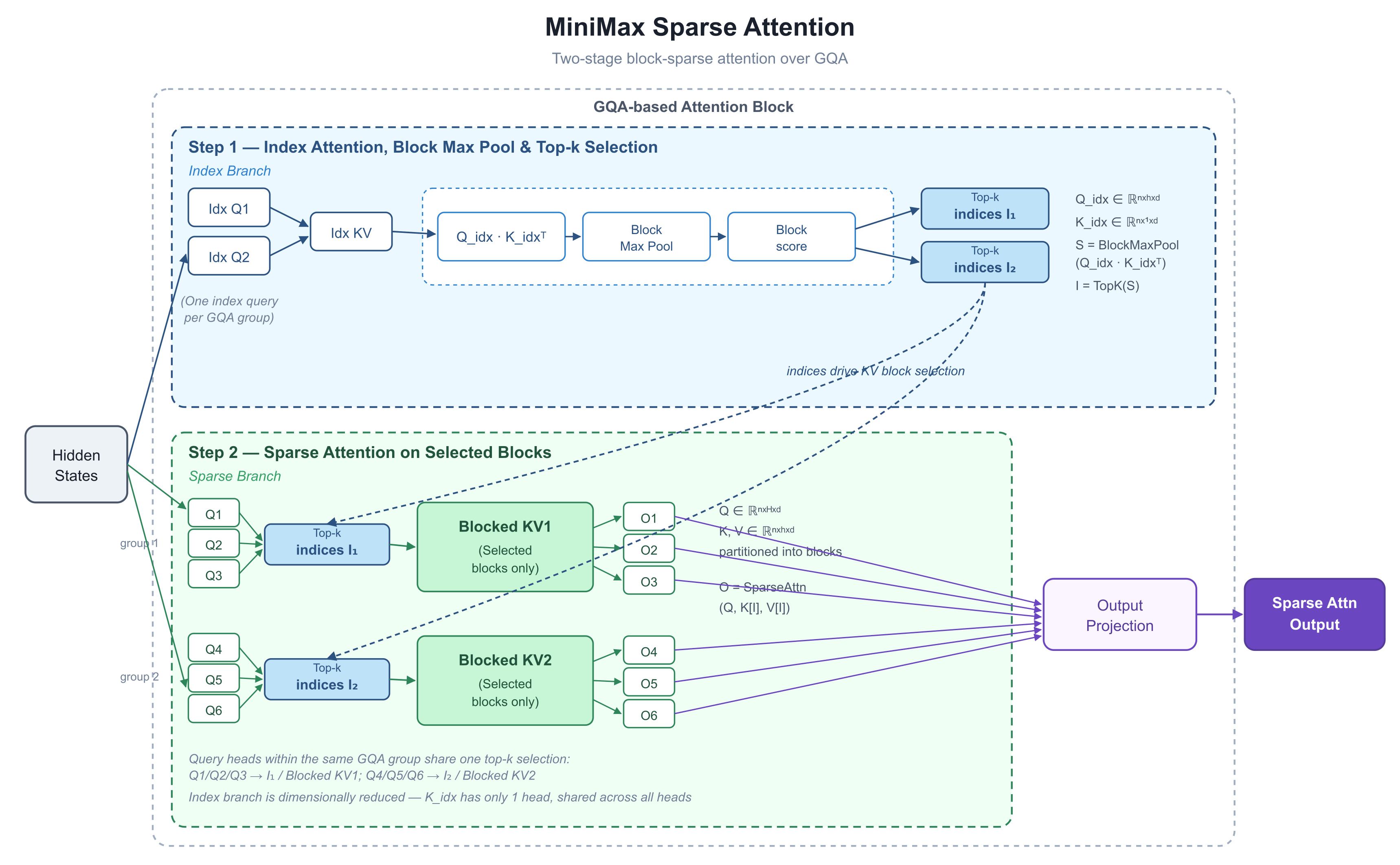
قليل من التأسيس قبل التفكيك. ثلاثة مصطلحات تلخص القصة بأكملها:
- التعبئة المسبقة (Prefill) هي المرحلة التي يقرأ فيها النموذج مدخلاتك دفعة واحدة.
- فك التشفير (Decode) هو المرحلة الأبطأ، رمزاً تلو الآخر، حيث يكتب النموذج المخرجات — وفي حالة السياق الطويل، تعد هذه المرحلة هي الأكثر تكلفة، لأن كل رمز جديد ينظر إلى كل ما سبقه.
- الانتباه المتناثر (Sparse attention) هو الحل: بدلاً من جعل كل رمز ينتبه لكل الرموز الأخرى (وهو الوضع الافتراضي الذي تزداد تكلفته بتربيع طول التسلسل)، ينتبه النموذج إلى مجموعة فرعية مختارة بعناية — مما يحافظ على معظم الجودة بجزء بسيط من القوة الحسابية. الطريقة التي تختار بها هذه المجموعة الفرعية هي ما يميز كل مختبر عن الآخر.
والسبب في أن هذا التشويق يحمل وزناً: في أكتوبر الماضي، نشرت MiniMax مقالاً بعنوان لماذا انتهى الأمر بـ M2 كنموذج انتباه كامل (Full Attention)؟ — حيث شرحت بصراحة غير معتادة أن M2 تجاوز تقنية "Lightning Attention" الفعالة الخاصة بـ M1 لأنها لم تكن جاهزة للإنتاج بعد. بعد ستة أشهر، يظهر M3 مع الانتباه المتناثر في المقدمة. الرسالة الضمنية هي جملة واحدة: هذه المرة، التقنية جاهزة.
1. ماذا يظهر المخطط: مرحلتان — اختر قبل أن تحسب
المخطط هو تفكيك داخلي لكتلة انتباه واحدة. حركته الرئيسية هي فصل "أي الرموز يجب النظر إليها" عن "كيفية حساب الانتباه فوقها" إلى خطوتين منفصلتين بوضوح.
ملاحظة حول الركيزة الأساسية، لأنها تتكرر في كل مكان: M3 مبني على GQA — انتباه الاستعلام المجمع (Grouped-Query Attention). في طبقة الانتباه القياسية، يحمل كل "رأس استعلام" مجموعة خاصة به من المفاتيح والقيم، وهو أمر معبر ولكنه يضخم ذاكرة التخزين المؤقت للمفاتيح والقيم (KV cache) (مفاتيح وقيم الرموز السابقة التي يتم تخزينها حتى لا يعاد حسابها في كل خطوة). تقوم GQA بتقسيم رؤوس الاستعلام إلى مجموعات، وتتشارك كل مجموعة في مجموعة واحدة من المفاتيح والقيم. إنه التصميم السائد الموفر للذاكرة والمستخدم عبر معظم النماذج الإنتاجية اليوم. احتفظ بهذه المعلومة — فهي أساس التصميم بأكمله.
الخطوة 1: فرع الفهرس — سجل كل شيء بتكلفة زهيدة
النصف العلوي هو فرع الفهرس. يعمل هذا الفرع بجانب المسار الرئيسي وله مهمة واحدة: إخبار باقي الكتلة بكتل الرموز التي تستحق النظر إليها.
تتشارك كل مجموعة GQA في استعلام فهرس واحد (يوضح المخطط ستة رؤوس حقيقية مقترنة باستعلامي فهرس، "Idx Q" — واحد لكل مجموعة). جانب المفاتيح في هذا الفرع مبسط عمداً:

لاحظ أن K_idx يحتوي على رأس واحد فقط — كل رأس يتشارك في نفس مفتاح الفهرس. هذا يجعل تكلفة خطوة التسجيل (Q_idx · K_idxᵀ) شبه معدومة.
ثم يقوم Block Max Pool بضغط تلك الدرجات على مستوى الرموز إلى درجات على مستوى الكتلة (يقوم بتقسيم التسلسل إلى كتل ذات حجم ثابت ويحتفظ بأعلى درجة في كل منها):

وأخيراً، TopK — "احتفظ بأعلى k عناصر تسجيلاً" — يقرر أي كتل KV ستبقى لهذه الطبقة وهذه المجموعة. المخرج هو قائمة قصيرة من المؤشرات: I₁، I₂.
الخطوة 2: الفرع المتناثر — حيث يتم حساب الانتباه فعلياً
النصف السفلي هو الحساب الحقيقي. لا تزال الاستعلامات والمفاتيح والقيم في شكل GQA القياسي. باستخدام I₁ و I₂ من الخطوة الأولى، تسحب الكتلة المجموعات الفرعية المختارة فقط من المفاتيح والقيم الكاملة، وتجري الانتباه عليها فقط:

أهم خيار في التصميم: كل رأس استعلام في المجموعة يتشارك في اختيار واحد من نوع top-k. في المخطط، تستخدم Q1/Q2/Q3 جميعاً I₁؛ وتستخدم Q4/Q5/Q6 جميعاً I₂. هذا هو مبدأ مواءمة الأجهزة الذي تؤكد عليه ورقة NSA الخاصة بـ DeepSeek — مجموعة واحدة من الاستعلامات تحمل مجموعة واحدة من كتل KV، تلك المجموعة تناسب ذاكرة SRAM (ذاكرة الرقاقة الصغيرة وفائقة السرعة في وحدة معالجة الرسوميات) في تمريرة واحدة، ويمكن إعادة استخدام نوى (kernels) FlashAttention القياسية (وهي التقنية المهيمنة والمحسنة للانتباه) دون تغيير.
2. ثلاث عمليات طرح متعمدة مقارنة بعائلة DeepSeek
قام المجتمع التقني فوراً بمقارنة هذا بتصاميم الانتباه المتناثر الثلاثة لـ DeepSeek:
- NSA — Native Sparse Attention: "Native" تعني أن التناثر مدمج منذ بداية التدريب المسبق، وليس مضافاً لاحقاً. ثلاثة مسارات متوازية (ضغط + اختيار + نافذة منزلقة) بالإضافة إلى بوابة متعلمة.
- DSA — DeepSeek Sparse Attention: النسخة التي تم طرحها في DeepSeek V3.2؛ اختيار على مستوى الرمز مع مفهرس خفيف جداً.
- CSA — اختصار مجتمعي للتوجه على مستوى الكتلة المرتبط بـ DeepSeek V4. (هذه التسمية أقل توحيداً من NSA/DSA، لذا تعامل معها كاسم عملي وليس مصطلحاً رسمياً).
الخلاصة المجتمعية المختصرة: M3 يستخدم GQA بدلاً من MLA، واختياراً على مستوى الكتلة بروح CSA، لكنه يحسب الانتباه على المفاتيح والقيم الحقيقية.
موسعاً في جدول:
| البعد | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (مستنتج) |
|---|---|---|---|---|
| ركيزة KV | MLA (كامنة) | GQA | MLA | GQA |
| دقة الاختيار | مستوى الرمز | مستوى الكتلة | مستوى الكتلة | مستوى الكتلة |
| المسارات المتوازية | 1 (مفهرس + اختيار) | 3 (ضغط + اختيار + انزلاق) | 1 | 1 (اختيار فقط) |
| أين يعمل الانتباه | K/V حقيقية | دمج ثلاثي الاتجاه | KV مضغوطة | K/V حقيقية |
| تكلفة المفهرس | مفهرس Lightning | فرع الضغط | ملخصات الكتلة | K أحادي الرأس + Block Max Pool |
| البوابة (Gating) | لا يوجد | بوابة متعلمة | لا يوجد | لا يوجد |
هذا الجدول يخفي اختصاراً آخر يستحق التعريف: MLA — Multi-head Latent Attention، خدعة DeepSeek المميزة. بدلاً من تخزين مفاتيح وقيم كاملة، يقوم MLA بضغطها في متجه "كامن" مشترك صغير، وتخزينه، وفكه عند الحاجة. تتقلص ذاكرة KV بشكل كبير — لكن الرياضيات لم تعد تطابق الانتباه القياسي، لذا فهي تحتاج إلى نوى مخصصة. هذا التباين يقود إلى أول المقايضات الثلاث في M3.
عملية الطرح الأولى: GQA كركيزة، وليس MLA. بما أن M3 يظل على GQA البسيط، فإن حزمة الخدمة القياسية — vLLM و SGLang (خوادم الاستدلال مفتوحة المصدر والأكثر استخداماً) بالإضافة إلى FlashAttention — تعمل مع تعديلات بسيطة أو بدونها. لا حاجة لأي هندسة للالتفاف حول ذاكرة KV الكامنة في MLA. بالنسبة لمختبر يستهدف "الجاهزية للإنتاج"، فهو المسار الأقل مخاطرة. هذه هي الفكرة الأكثر وضوحاً تجارياً في التصميم بأكمله: قامت MiniMax بالتحسين لما يعمل فوراً على الأجهزة والبرمجيات التي يمتلكها الجميع بالفعل.
عملية الطرح الثانية: اختيار على مستوى الكتلة، لكن الانتباه يعمل على المفاتيح والقيم الحقيقية. على عكس CSA، الذي يحسب الانتباه فوق KV مضغوطة، يحتفظ M3 بالقوة التعبيرية الكاملة لانتباه softmax القياسي. التكلفة: لا تتقلص ذاكرة KV مع التناثر — لكن مقايضة بعض الذاكرة مقابل الحفاظ على الجودة هي صفقة معقولة.
عملية الطرح الثالثة: ذهبت المسارات الأخرى في NSA. يعمل NSA بثلاثة مسارات متوازية (ضغط + اختيار + نافذة منزلقة) بالإضافة إلى بوابة متعلمة. يحتفظ M3 بالاختيار فقط. وصفه أحد ملخصات المجتمع بأنه NSA مبسط وانسيابي. باختصار: الهندسة أولاً. ومن بين المسارين المحذوفين، من المرجح أن النافذة المنزلقة قد تم استبدالها بـ RoPE (تضمين الموضع الدوراني — الطريقة القياسية التي ترمز بها النماذج لموضع الرموز) بالإضافة إلى "بالوعة انتباه" (attention sink)، أو ببساطة عن طريق الانتباه الكثيف كخيار احتياطي لكل طبقة، كما تفعل Gemma 3 و Qwen3-Next. أما فرع الضغط فقد تم امتصاصه في ذلك الحد الأدنى "K أحادي الرأس + Block Max Pool".
3. كيف تقرأ الأرقام
| المرحلة | التسريع عند 1 مليون | ماذا يعني ذلك |
|---|---|---|
| التعبئة المسبقة | 9.7 ضعفاً | معالجة 1 مليون رمز من المدخلات في تمريرة واحدة |
| فك التشفير | 15.6 ضعفاً | توليد رمزاً تلو الآخر |
تفوق فك التشفير على التعبئة المسبقة أمر منطقي. خلال التعبئة المسبقة، لا يزال فرع الفهرس بحاجة إلى مسح طول الإدخال الكامل، لذا يقتصر التوفير على الانتباه الرئيسي. خلال فك التشفير، يتفاعل كل رمز جديد فقط مع كتل KV المختارة الخاصة به، وتنخفض ضغوط النطاق الترددي للذاكرة على ذاكرة KV بمقدار رتبة مقدارية — وهو المكان الذي تكمن فيه تكلفة وقت فك التشفير بدقة.
بالعودة إلى نسبة الاختيار: لنفترض حجم كتلة قدره 64 رمزاً، لذا فإن 1 مليون رمز تعادل ~16,000 كتلة. تسريع فك التشفير بمقدار 15.6 ضعفاً يعني أن كل استعلام يلمس فعلياً حوالي 6-7% فقط من الكتل — أي حقل استقبال فعال يتراوح بين 60 ألف و 70 ألف رمز. تقع هذه النسبة تقريباً بالضبط على معدل التناثر الذي تذكره ورقة NSA (6-10%). ليست مصادفة — إنها النقطة المثالية لهذا النوع من التصميم عند مقياس 1 مليون.
4. استنتاج بقية خصائص M3
بالاستقراء من كتلة الانتباه هذه إلى النموذج الكامل — الذي تم تصنيفه بوضوح كاستدلال، نظراً لأن المخطط لا يظهر الكثير:
- من المرجح أن يظل العمود الفقري MoE.MoE — خليط الخبراء — هو العمود الفقري للنموذج (منفصل عن الانتباه): بدلاً من توجيه كل رمز عبر شبكة عملاقة واحدة، يرسل الموجه كل رمز إلى بضع شبكات فرعية متخصصة "للخبراء"، بحيث تحصل على جودة نموذج كبير عند حساب نشط لنموذج صغير. تم طرح M2 بـ 230 مليار معيار إجمالي / ~10 مليار معيار نشط / توجيه Top-2؛ وقد دفع M2.7 عدد الخبراء بالفعل إلى 256. لا يوجد سبب يدعو M3 للتخلي عن هذا — التغيير المحتمل هو أن يصبح أعمق وأوسع.
- استبدال حزمة الانتباه الكامل بـ GQA متناثر الكتل. من غير المرجح أن تعود Lightning Attention الخاصة بـ M1. لا تراهن M3 على الانتباه الخطي؛ بل تسلك طريق "تعبيرية softmax + اختيار كتل top-k" — تكلفة أقل من تربيعية مع الحفاظ على الجودة.
- على الأرجح تناثر مدرب أصلاً. هذا هو الدرس المركزي لورقة NSA: يجب أن يدخل نمط التناثر في التدرجات أثناء التدريب المسبق، وإلا فإن سلوك الاسترجاع في النموذج سيضطرب. لدى MiniMax خط بحث خاص بها حول رؤوس الاسترجاع، لذا لا ينبغي أن تقع في هذا الفخ.
- ساحة المعركة هي سياق 1 مليون+. تم تدريب M1 عند 1 مليون وتم استقراؤه إلى 4 مليون في الاستدلال. يبدو M3 مستعداً لتثبيت ذلك مع خفض تكلفة الاستدلال — إيقاع منتج طبيعي جداً.
5. وضع M3 في مساحة تصميم 2026
عبر 2025-2026، تباعدت تصاميم الانتباه المتناثر بسرعة:
- DeepSeek V3.2 DSA: MLA + اختيار top-k على مستوى الرمز، مفهرس خفيف جداً؛ أكثر جودة استقراراً، ولكن هندسة نوى ثقيلة.
- DeepSeek NSA: GQA، ثلاثة فروع + بوابة؛ أعلى سقف للجودة، وأكثر تعقيداً في التنفيذ.
- Qwen3-Next: مزيج على مستوى الطبقة من الانتباه الكثيف والخطي؛ قوي ولكنه متحفظ نسبياً.
- MiniMax M3: GQA + اختيار كتلة بفرع واحد؛ بسيط، مستفيداً من رياح التغيير في الأجهزة.
الرسالة الضمنية لتصميم M3 واضحة لا لبس فيها: لا تطارد الانتباه الأمثل نظرياً — طارد ذلك الذي يعمل فوراً، ويعمل بسرعة، ويسمح بإعادة استخدام النوى الموجودة. إنه جزء من القرار بالتراجع إلى الانتباه الكامل في M2: استقرار الجودة بالأساليب السائدة أولاً، ثم الاستبدال بشكل نظيف بمجرد أن تنضج التكنولوجيا حقاً.
6. ماذا يعني هذا إذا كنت تبني الموجة القادمة من تطبيقات الذكاء الاصطناعي
تراجع خطوة عن الهندسة المعمارية وستجد نمطاً أكبر. يقوم كل مختبر جاد الآن بطرح نسخة من الانتباه المتناثر المدرب — DeepSeek عبر ثلاثة خطوط، Qwen بمزيجها على مستوى الطبقات، والآن MiniMax. الاتجاه حُسم، والنتيجة مباشرة: عندما تستطيع كل نماذج المواجهة تشغيل سياق طويل بتكلفة زهيدة، يتوقف النموذج نفسه عن كونه الميزة التنافسية. تنضغط تكلفة الاستدلال الخام نحو السلعة (Commodity). ينتقل التمايز إلى مستوى أعلى — إلى أي نموذج تشغله لأي عبء عمل، وكيف توجّه بينها، ومدى سرعة تبنيك للنموذج التالي عندما يصل بعد ستة أسابيع.
تلك مشكلة أصعب من "العثور على أرخص نقطة نهاية". الفريق الذي يدير تطبيقاً إنتاجياً يوازن بين أربعة أشياء في وقت واحد — الجودة، وزمن الاستجابة، والتكلفة، والنتيجة التجارية التي تحققها الميزة فعلياً — وتختلف الإجابة الصحيحة حسب عبء العمل وتتغير مع كل دورة إصدار. M2 كان بانتباه كامل في أكتوبر؛ M3 متناثر الكتل بحلول مايو. أي شيء قمت بربطه في الربع الماضي أصبح بالفعل خطوة متأخرة.
لم يعد اختيار أرخص نموذج استراتيجية رابحة للمطورين. بدلاً من ذلك، سيكون المطورون الذين بنوا على طبقة تسمح لهم بالاختيار والتوجيه وتبديل النماذج دون إعادة التكامل في كل مرة تتحرك فيها المواجهة — والذين ينفقون ميزانيتهم الهندسية على منتجهم الخاص بدلاً من مطاردة ملاحظات الإصدار كل بضعة أسابيع.
هذه هي الطبقة التي تعمل فيها Atlas Cloud: واجهة برمجة تطبيقات واحدة عبر أكثر من 300 نموذج تشمل LLM، والفيديو، والصورة، والصوت، مع توجيه ذكي ودخول في اليوم الأول للإطلاقات الجديدة. نفس العدسة التي استخدمناها لتفكيك هذا المخطط هي التي نستخدمها لتقرير ما يجب استخدامه وكيفية توجيهه. M3 ليس عاماً بعد — عندما يُفتح، نتوقع جلبه إلى Atlas مع دخول في اليوم الأول، حتى تتمكن الفرق التي تبني معنا بالفعل من وضعه أمام مستخدميها في يوم إطلاقه، وليس بعد ربع سنة.
أفكار ختامية
لا يمكن تأكيد الكثير من مخطط واحد: ما إذا كان نمط التناثر مختلطاً طبقة تلو الأخرى، ما إذا كان هناك خيار احتياطي كثيف، ما إذا كان فرع الفهرس يتشارك التضمينات (Embeddings) مع الشبكة الرئيسية، ما إذا كان اختيار top-k أثناء التدريب صلباً أم مرناً، كيف تمت صياغة خسارة فرع الفهرس. كل ذلك ينتظر الورقة الرسمية أو الأوزان.
لكن هناك شيء واحد قد حُسم: بعد DeepSeek، قام مختبر رئيسي آخر بجمع الانتباه المتناثر + سياق طويل + أوزان مفتوحة في حزمة عمل. في النصف الثاني من 2026، من المحتمل أن يتحول سياق 1 مليون في المصدر المفتوح من نقطة بيع إلى أساس — وهذا، في حد ذاته، يهم أكثر من أي تقييم فردي.
المراجع
- سكايلر مياو (رئيس البحث والتطوير في MiniMax)، المنشور الأصلي على X: شيء كبير قادم — https://x.com/SkylerMiao7/status/2059285750458544561
- ملخص المجتمع: MiniMax توضح هندسة الانتباه المتناثر لنموذج M3 — https://digg.com/ai/78gnmbpg
- مدونة MiniMax: لماذا انتهى الأمر بـ M2 كنموذج انتباه كامل؟ — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- ورقة DeepSeek NSA: الانتباه المتناثر الأصلي: انتباه متناثر متوافق مع الأجهزة وقابل للتدريب بشكل أصلي — https://arxiv.org/pdf/2502.11089
- مقال عن DeepSeek V3.2 DSA: الكفاءة المعمارية في النماذج اللغوية الكبيرة: DeepSeek-V3.2-Exp و DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- سيباستيان راشكة: جولة تقنية في نماذج DeepSeek من V3 إلى V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- التقرير التقني لـ MiniMax-01: توسيع نماذج الأساس مع Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






