
إذا كنت تكتب أنوية (kernels) لوحدة معالجة الرسوميات (GPU)، فأنت تقع في مكان ما ضمن طيف معين. في أحد طرفيه يوجد Triton: سريع الكتابة، لكن المترجم (compiler) يتخذ معظم قرارات التخطيط والذاكرة المشتركة نيابةً عنك. وفي الطرف الآخر يوجد CUTLASS / CuTe: تحكم كامل، مقابل الكثير من تعقيدات القوالب (template machinery). أما TileLang فيقع في المنتصف. أنت تكتب بلغة Python، لكنك تحدد بوضوح ما يوضع في الذاكرة المشتركة، وكيفية تنظيم خط المعالجة (pipeline)، وكيفية تقسيم مجموعات العمل (warps) للمهام — بينما تتولى عملية "استنتاج التخطيط" (layout inference) ملء التفاصيل المتبقية.
في هذه المقالة، سنغطي النموذج الذهني، وسنكتب عملية GEMM، ثم ننتقل لبناء نواة إنتاجية حقيقية: وهي فك ترميز MLA الخاص بـ DeepSeek، حيث تظهر القرارات المهمة فعلياً. الهدف ليس الإحاطة بكل شيء، بل إظهار كيفية تفكيرك في "البلاطات" (tiles)، وأين يقوم TileLang بتنفيذ الأجزاء الصعبة بهدوء نيابةً عنك. سنختتم بقصة أكثر نموذجية من بيئة الإنتاج — نواة لم يكن المكسب فيها السرعة على الإطلاق.
النموذج الذهني
إليك الفكرة بالكامل في ثلاث نقاط:
- البلاطة (Tile) ككائن من الدرجة الأولى. كتلة بيانات ذات شكل محدد (مثل block_M × block_K) يتم امتلاكها ومعالجتها بواسطة كتلة خيوط (thread block)، أو مجموعة خيوط (warp)، أو خيط واحد (thread). تتوقف عن التفكير حصرياً على مستوى كتلة الخيوط كما في Triton، وتتوقف عن الإدارة اليدوية لكل خيط على حدة كما في CUDA.
- أنت تضع المخازن المؤقتة في تسلسل الذاكرة الهرمي بنفسك. أنت تحدد ما يذهب إلى الذاكرة المشتركة (T.alloc_shared)، وما يذهب إلى السجلات (T.alloc_fragment)، وما هو محلي لكل خيط. هذا هو الفرق الأكبر عن Triton، الذي يخفي تخصيص الذاكرة المشتركة وتنظيمها داخل المترجم.
- المترجم يستنتج تعيين الخيوط. بمجرد تحديد مكان وجود البلاطة والعملية التي تجري عليها (نسخ، ضرب مصفوفات، اختزال)، تقوم عملية استنتاج التخطيط بموازنتها عبر الخيوط وحساب تخطيطات السجلات والذاكرة المشتركة. يمكنك تجاوز ذلك عند الحاجة، لكنك غالباً لن تحتاج لذلك. هذه العملية هي الميزة الأساسية — وبحلول الوقت الذي نصل فيه إلى MLA، ستدرك السبب.
إذا كنت قادماً من Triton، فإليك التعيين التقريبي:
| Triton | TileLang | |
|---|---|---|
| الحبيبية (Granularity) | كتلة خيوط + توجيه ضمني | بلاطة (block / warp / thread) |
| الذاكرة المشتركة | مدارة بواسطة المترجم | explicit alloc_shared + copy |
| التخطيط (Layout) | المترجم يقرر | مُستنتج، ولكن يمكنك إضافة ملاحظات |
| خط المعالجة (Pipelining) | tl.range + المترجم | explicit T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm مع سياسة warp قابلة للاختيار |
| المنصات المدعومة | NVIDIA (أساساً) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL، بالإضافة إلى Ascend و MUSA |
باختصار: إذا كنت تريد تحكماً دقيقاً في التجزئة (blocking)، وعمق خط المعالجة، وتقسيم الـ warp دون كتابة CUTLASS، فإن TileLang هو الخيار الأمثل. بالنسبة للعمليات البسيطة أو الدمج الخفيف، لا يزال Triton أسرع في الاستخدام.
الإعداد
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # حزمة جاهزة، الطريق الأسهل
إذا كنت ستعدل في عمليات المترجم، فقم بالبناء من المصدر بدلاً من ذلك (ستحتاج إلى سلسلة أدوات LLVM/CUDA محلية):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
لنكتب عملية GEMM
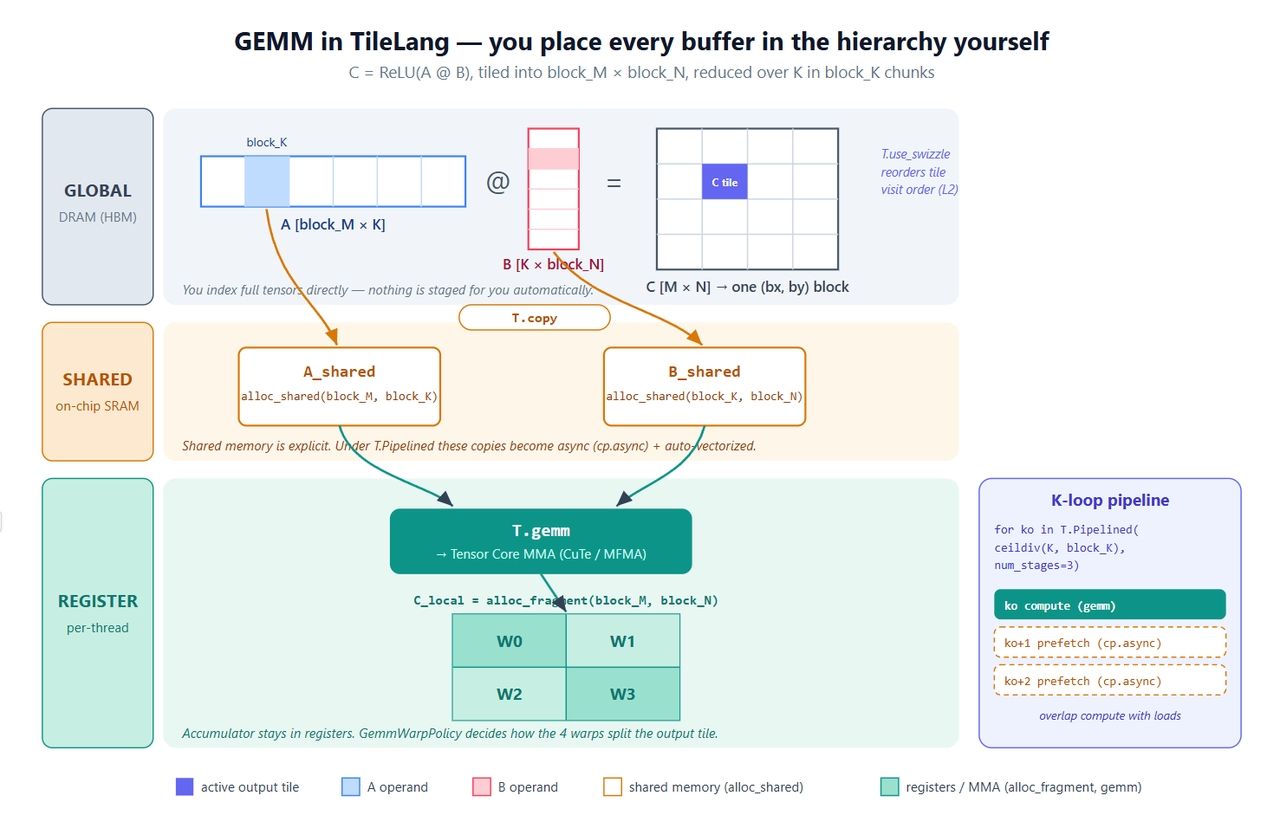
سنبدأ بالنواة التي يبدأ بها الجميع: C = ReLU(A @ B). إنها صغيرة، لكنها تلمس كل العناصر الأساسية — المخازن المؤقتة الصريحة، النسخ المتوازي، خط معالجة البرمجيات، استدعاء Tensor Core، وL2 swizzle.
python1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # أبعاد الشبكة: (#كتل على طول N، #كتل على طول M)؛ 128 خيط لكل كتلة 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # حدد مكان كل بلاطة بوضوح 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # ذاكرة مشتركة 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # تراكمي في السجلات 23 24 T.use_swizzle(panel_size=4, order="col") # اختياري: إعادة استخدام أفضل لـ L2 25 T.clear(C_local) # تصفير التراكمي 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # من الذاكرة العامة -> إلى المشتركة 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # MMA على مستوى البلاطة 31 32 for i, j in T.Parallel(block_M, block_N): # دمج ReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # كتابة النتيجة 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
إليك ما يفعله كل جزء:
- ثلاثة مخازن مؤقتة، ثلاثة مستويات. تعيش A_shared و B_shared في الذاكرة المشتركة؛ بينما يعيش C_local في السجلات. التراكم في السجلات، والمتغيرات تُنظم عبر الذاكرة المشتركة — هذه هي وصفة GEMM القياسية، باستثناء أنك هنا أنت من يكتبها. هذا هو الفرق الكامل عن Triton في سطر واحد.
- T.copy هي اختصار لعملية نسخ متوازية. تتوسع لتصبح حركة بنمط T.Parallel، ويشتق المترجم منها عملية نقل متجهة ومدمجة من الذاكرة العامة إلى المشتركة. عندما توضع عملية النسخ داخل T.Pipelined، تتحول تلقائياً إلى cp.async.
- T.Pipelined(extent, num_stages=N) هو خط معالجة برمجي. num_stages=3 تعني التخزين المؤقت الثلاثي — بينما تحسب البلاطة ko، تكون عمليات التحميل لـ ko+1 و ko+2 قيد التنفيذ بالفعل. في Triton، هذا خيار مترجم؛ هنا هو مجرد حلقة (loop)، مما يسهل فهم المنطق.
- T.gemm(A, B, C) هو ضرب المصفوفات على مستوى البلاطة. يتم خفضه إلى CuTe/MMA على NVIDIA وما يعادله على AMD. كما يقبل وسائط مثل transpose_A / transpose_B وسياسة warp التي تتحكم في كيفية تقسيم الـ warps للبلاطة الناتجة. احتفظ بوسيط السياسة هذا — فهو أساس القصة عندما نصل إلى MLA.
- T.use_swizzle يعيد ترتيب كيفية جدولة كتل الخيوط بحيث تعمل الكتل المتجاورة في L2 بالقرب من بعضها في الوقت المناسب. عادة ما يوفر بضعة بالمائة من النطاق الترددي.
الشكل أدناه يعين كل هذا على العتاد (Hardware). يجدر بك قراءته مع الكود، لأن النقاط المحددة هي بالضبط الأماكن التي يمنحك فيها TileLang تحكماً يحتفظ به Triton لنفسه.
بعض الأصول الأساسية التي ستحتاجها
يمكنك كتابة معظم الأنوية بمفردات بسيطة:
- التخصيص: T.alloc_shared، T.alloc_fragment (سجلات)، T.alloc_local.
- النقل والتهيئة: T.copy(src, dst) بين أي مستويين؛ T.clear، T.fill.
- الحساب: T.gemm(...)؛ T.Parallel(d0, d1, ...) لحلقات العمليات الحسابية (نقطة الدخول لاستنتاج التخطيط)؛ T.reduce_max / T.reduce_sum؛ الدوال الحسابية مثل T.exp، T.exp2، T.max.
- الجدولة: T.Pipelined(...)، T.use_swizzle(...)، T.annotate_layout(...) عند الحاجة لتخطيط محدد.
- الأشكال الديناميكية: M = T.dynamic("m") بحيث لا تحتاج لإعادة التجميع لكل شكل.
التحقق من عملك
شيئان ستحتاجهما كثيراً. لرؤية ما أصدره المترجم فعلياً:
plaintext1print(kernel.get_kernel_source()) # كود CUDA / HIP المولد
ولقياس الوقت:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
يقوم T.print(buf) بطباعة بلاطة من داخل النواة، وتقوم أمثلة المستودع برسم تخطيط الذاكرة، وهو أمر مفيد عند تتبع تعارض في الذاكرة.
الآن ننتقل إلى مثال حقيقي: MLA decode
يوضح مثال GEMM الآليات. يوضح هذا المثال التالي سبب أهميتها. سنتجول في نواة فك ترميز MLA الخاصة بـ DeepSeek، لأنها أوضح مثال على استحقاق TileLang للاهتمام. يصل أداء TileLang إلى أداء FlashMLA على H100 (تم قياسه عند دفعات 64/128 بنمط fp16، متفوقاً بسهولة على Triton و FlashInfer) في حوالي 80 سطراً من Python. السؤال المثير للاهتمام هو كيف، لأن الجزء الصعب في MLA ليس الرياضيات — بل ضغط السجلات.
دعنا نراجع الحلقة التي يعرفها الجميع. كل نواة من عائلة FlashAttention لها نفس الشكل. لكل كتلة استعلام (query block)، تقوم ببث كتل المفاتيح/القيم (key/value blocks) وتحتفظ بحد أقصى وقاسم تراكمي، بحيث لا تظهر مصفوفة النتائج الكاملة في الذاكرة أبداً.
هنا يصبح الأمر صعباً. أبعاد رأس MLA كبيرة: الاستعلام والمفتاح بعرض 576، والقيمة بعرض 512. لذا فإن acc_o = [block_M, 512]، ويجب أن يبقى مقيماً في السجلات عبر حلقة KV بالكامل.
الآن أدخل العتاد في الحساب. على بنية Hopper، المسار السريع هو wgmma.mma_async، الذي يربط 4 مجموعات خيوط (128 خيطاً) في مجموعة واحدة (warpgroup) ويتطلب حداً أدنى لـ M يساوي 64. إذن أصغر M يمكن لمجموعة واحدة امتلاكها هو 64، مما يعني أن مجموعة واحدة ستمتلك تراكمياً بحجم 64 × 512. هذا كبير جداً لملف سجلات مجموعة واحدة. سيحدث تسريب (spill)، وينهار الأداء.
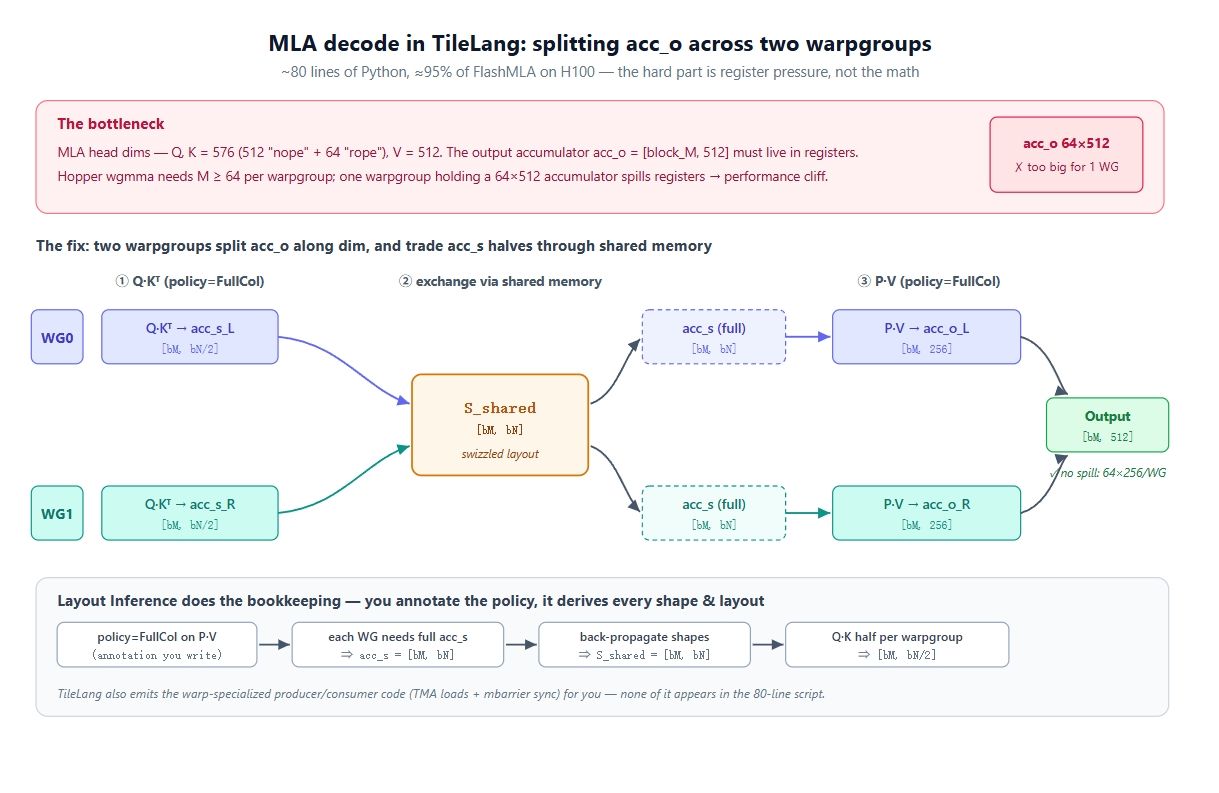
الحل هو تقسيم المخرجات عبر مجموعتي warpgroups. لا يمكنك تقليل M أقل من 64، لذا فإن المحور الوحيد المتبقي هو البعد (dim). استخدم مجموعتي warpgroups: حيث تمتلك WG0 الجزء acc_o[:, :256]، وتمتلك WG1 الجزء acc_o[:, 256:]. الآن تمتلك كل منهما تراكمياً بحجم 64 × 256، وهو ما يتناسب مع الذاكرة. يخلق هذا مشكلة ثانية: خطوة P @ V تحتاج إلى acc_s الكاملة، ولكن في Q @ K حساب كل مجموعة نصفها فقط. الحل هو تبادل عبر الذاكرة المشتركة.
في CuTe، ستحتاج لكتابة التخطيطات، والـ swizzles، ومزامنة المنتج/المستهلك يدوياً. السبب في تقلص ذلك إلى ~80 سطراً هنا هو "استنتاج التخطيط".
لنحلل ما يفعله استنتاج التخطيط. أنت تضيف ملاحظات حول القصد على استدعاءات T.gemm، وهو ينشر القيود عبر البرنامج نيابة عنك. النقطة الجوهرية هي أنك لا تكتب أياً من هذه الأشكال. أنت تختار سياسة الـ warp وتكتب الرياضيات؛ أما الأشكال، والتخطيطات، وكود المنتج/المستهلك، كلها تنتج عن الاستنتاج.
تحسينات إضافية
- Threadblock swizzling: لزيادة إعادة استخدام L2.
- Shared-memory swizzling: لتجنب تعارضات البنوك.
- Warp specialization: يتم خفض الكود إلى مجموعة منتجة (TMA loads) ومجموعات مستهلكة، مع توليد كل عمليات مزامنة mbarrier.
- Pipelining: لزيادة التداخل بين التحميل والحساب.
- Split-KV: عند صغر الدفعة (batch)، يتم تقسيم سياق KV عبر معالجات SM ودمجه.
إن كل ما كان سيستغرق مئات السطور الهشة في CuTe هو الآن مجرد استنتاج وتوليد كود. هذا هو جوهر الأمر، وهو سبب قدرة نواة MLA من 80 سطراً على العمل بجانب نواة CUTLASS مضبوطة يدوياً.
مثال من عملنا: RMSNorm كبديل مباشر في AtlasCloud
المثال الأخير من إنتاجنا في AtlasCloud، لنظام Wan لتوليد الفيديو. إنه يوضح شيئاً آخر يتفوق فيه TileLang: تغطية تكوين لا تستطيع النواة المضبوطة يدوياً الوصول إليه.
السيناريو. لدينا نواة RMSNorm + SiLU مضبوطة يدوياً، وهي سريعة، لكنها مجمعة فقط للأبعاد المخفية D التي يستخدمها نموذج معين. يحتاج تكوين أحدث إلى عروض قنوات أخرى، وهنا لا تعمل النواة المضبوطة يدوياً. كتبنا بديلاً بـ TileLang لتغطية هذه الفجوة بالضبط.
ما الذي كسبناه؟ مكسب حقيقي — حيث ارتفع الأداء في العمليات التي لم تكن مدعومة، مع تحسن في سرعة العمليات المشتركة بمرتين تقريباً، وأصبحت النواة تغطي تكوينات لم تكن ممكنة سابقاً دون لمس الأكواد المحسنة يدوياً الحالية.
أين يتألق TileLang؟
- تحكم دقيق في التجزئة، وخطوط المعالجة، وتقسيم الـ warp، دون كتابة CUTLASS/CuTe.
- الأنوية المعقدة هيكلياً والحساسة للتخطيط: متغيرات GEMM، عائلة FlashAttention، MLA، وMoE.
- تغطية العمليات التي لا تصل إليها الأكواد المضبوطة يدوياً.
- كود موحد عبر المنصات (NVIDIA / AMD).
- مجموعة أدوات التحسين بالكامل عبارة عن استدعاء واحد بسيط، مع التعامل مع التخفيض البرمجي (lowering) نيابة عنك.
الخاتمة
الجزء الرائع في TileLang هو أن التفكير المنطقي الصعب يظل في عقلك، لا في الأكواد النمطية (boilerplate). أنت تقرر كيفية تقسيم العمل، ومكان وضع المخازن المؤقتة، وعمق خط المعالجة — ثم يقوم "استنتاج التخطيط" بتحويل ذلك إلى تفاصيل الذاكرة والسجلات التي كانت ستستغرق مئات السطور في CuTe. أنت تختار السياسة وتكتب الرياضيات. هذا هو العرض بالكامل، ولهذا السبب يمكن لنواة MLA من 80 سطراً أن توجد جنباً إلى جنب مع نواة CUTLASS مضبوطة يدوياً.






