
ChatGPT API for Frontier GPT 5.6 Reasoning
توفّر ChatGPT API على Atlas Cloud أحدث عائلة GPT 5.6 من OpenAI ضمن تكامل واحد، لتشمل Sol للاستدلال المتقدم والعميق، وTerra لأعباء عمل الإنتاج المستندة إلى معطيات موثوقة، وLuna للمحادثة الطبيعية وإنشاء المحتوى. وجّه كل نموذج عبر مفتاح واحد متوافق مع OpenAI، واعتمد على جاهزية بمستوى الإنتاج، وادفع وفق أسعار شفافة بنظام الدفع حسب الاستخدام تبدأ من $1 لكل مليون رمز إدخال. ابدأ البناء اليوم.
استكشف النماذج الرائدة
يوفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.
اختر نموذج ChatGPT API المناسب: مقارنة بين كل Endpoint
خمسة Endpoints لتوليد النصوص تمتد من الاستدلال المتقدم إلى المحادثات الاقتصادية، وكلها متاحة عبر مفتاح واحد متوافق مع OpenAI مع تسعير شفاف بنظام الدفع حسب الاستخدام.
| النمط | الوصف |
|---|---|
| GPT 5.6 Sol API (نص إلى نص) | صُمّم GPT 5.6 Sol لأعباء عمل الذكاء الاصطناعي المتقدمة؛ إذ يحوّل المطالبات النصية المعقدة إلى مخرجات استدلال عميقة متعددة الخطوات لحل المشكلات الطموحة. يبلغ السعر القياسي $5 لكل مليون رمز إدخال و$30 لكل مليون رمز إخراج، ما يجعله الخيار الرئيسي عندما تكون جودة الإجابة أهم من التكلفة. |
| GPT 5.6 Terra API (نص إلى نص) | هل تحتاج إلى خيار إنتاج افتراضي موثوق؟ يحوّل GPT 5.6 Terra المطالبات إلى نصوص عملية ومرتكزة على الواقع لسير العمل الفعلي ومسارات التحليل بسعر $2.50 للإدخال و$15 للإخراج لكل مليون رمز. تعتمده الفرق في التطبيقات الموجهة للعملاء عندما يكون الاتساق أهم من العمق التجريبي. |
| GPT 5.6 Luna API (نص إلى نص) | وجّه زيارات المحادثة والإبداع إلى GPT 5.6 Luna، وهو نموذج نصي مضبوط للحوار الطبيعي، وتوليد المحتوى، وتجارب الذكاء الاصطناعي المخصصة. بسعر $1 للإدخال و$6 للإخراج لكل مليون رمز، يُعد نقطة الدخول الأكثر توفيرًا ضمن هذه المجموعة من ChatGPT API، ومناسبًا جدًا لمنتجات الدردشة وتوليد النصوص التسويقية بكميات كبيرة. |
| GPT 5.4 API (نص إلى نص) | يعالج GPT 5.4 التعليمات النصية ليقدّم تعليمات برمجية موثوقة، ومحتوى طويلًا، ومخرجات منظمة لحل المشكلات بدقة عالية. وبصفته نموذجًا متعدد الوسائط متقدمًا من حيث التصميم، يأتي بتسعير من الفئة المتوسطة يبلغ $2.50 للإدخال و$15 للإخراج لكل مليون رمز، ما يجعله مناسبًا عمليًا لمساعدي البرمجة ومنصات المحتوى. |
| GPT 5.5 API (نص إلى نص) | عندما تبرر المشكلات الصعبة إنفاقًا أعلى، يقدّم GPT 5.5 استدلالًا متقدمًا، وبرمجة، وتوليد محتوى من Endpoint نصي واحد. وبسعر $5 للإدخال و$30 للإخراج لكل مليون رمز، يستهدف أعباء العمل المعقدة والحساسة للموثوقية، مثل تنسيق الوكلاء والتحليل التقني. |
واجهة ChatGPT API: مستويات GPT 5.x والأوزان المفتوحة
استخدم تشكيلة GPT 5.x الكاملة ونموذج GPT OSS 120B ذي الأوزان المفتوحة عبر ChatGPT API واحدة، واضبط جهد الاستدلال من low إلى xhigh، وامزج النصوص والصور والملفات في استدعاء واحد، واستدعِ الأدوات الأصلية مع بحث ويب مباشر باستخدام مفتاح واحد متوافق مع OpenAI.
النصوص والصور والملفات في استدعاء ChatGPT API واحد
يمكن لطلب ChatGPT API واحد أن يجمع النص العادي وروابط الصور وملفات المستندات في رسالة واحدة. يزيل ذلك الحاجة إلى خدمات OCR أو الرؤية المنفصلة، بحيث يمكنك تلخيص العقود الممسوحة ضوئيًا أو قراءة لقطات الشاشة في مرور واحد.
الالتزام بالتعليمات على ChatGPT API
يلتزم GPT OSS 120B بمطالبات النظام متعددة الطبقات، ويحافظ على استقرار التنسيقات والقيود والنبرة عبر المخرجات دون انحراف. تجعل هذه الموثوقية النموذج مناسبًا للوكلاء المستقلين، والاستخراج المنظم، ومسارات الإنتاج التي يجب أن تلتزم مخرجاتها بالقواعد.
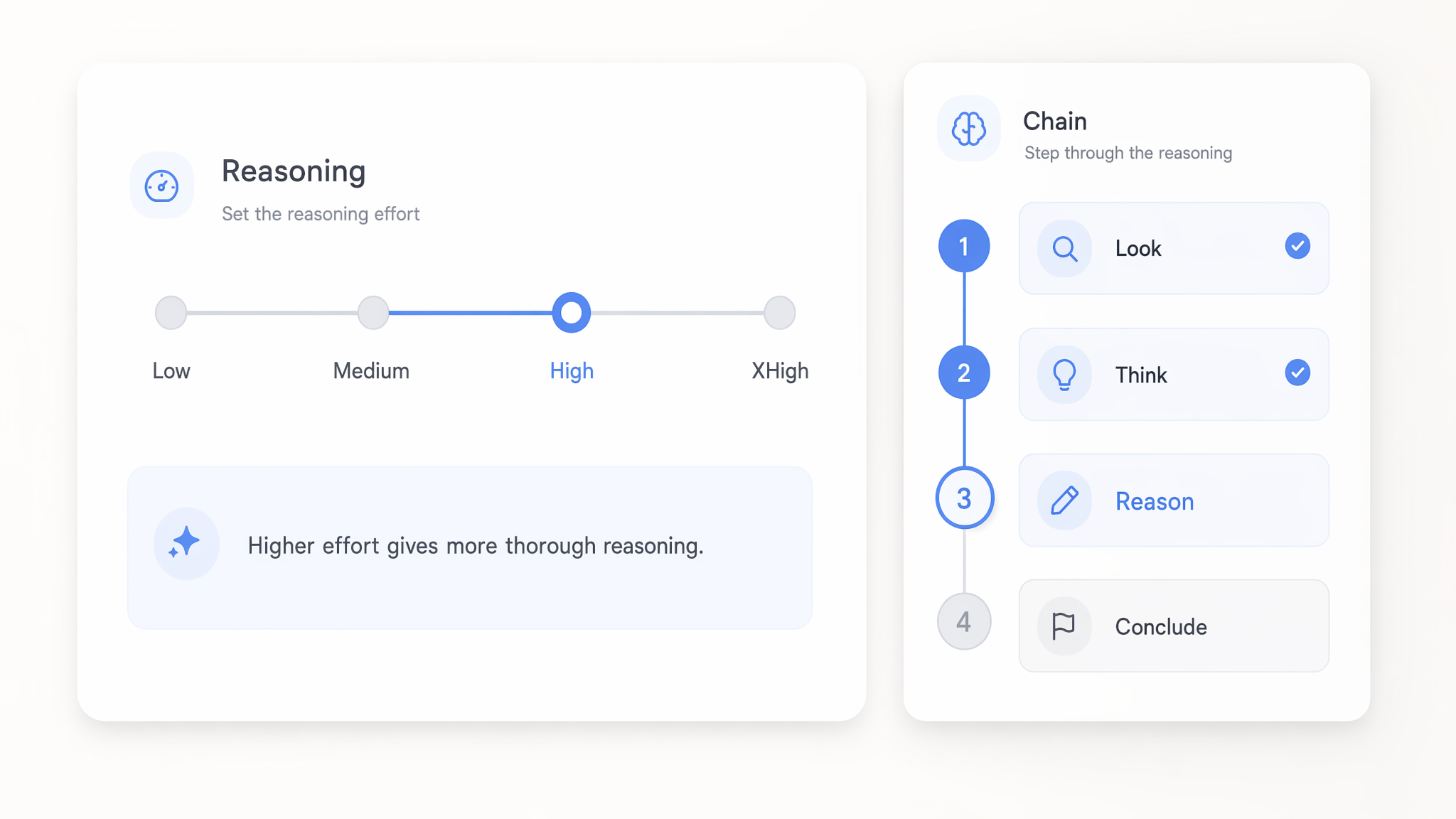
اضبط جهد الاستدلال من Low إلى xHigh
اضبط جهد الاستدلال في نماذج GPT 5.x من low حتى xhigh للتحكم في عمق التفكير قبل الإجابة. الإعدادات المنخفضة تجيب عن الاستدعاءات البسيطة بسرعة وبتكلفة أقل، بينما يخصص xhigh قدرة حوسبة أكبر للمنطق الصعب متعدد الخطوات.
أوزان Apache 2.0 تملكها بالكامل
بما أنه موزع بموجب ترخيص Apache 2.0، يتيح GPT OSS 120B الاستخدام التجاري والضبط الدقيق الخاص على GPU واحد بسعة 80GB. يمكنك استضافته محليًا للحفاظ على البيانات المملوكة داخل المؤسسة وتجنب رسوم كل رمز بالكامل.

خمسة مستويات GPT عبر ChatGPT API واحدة
تخدم ChatGPT API واحدة تشكيلة GPT 5.x الكاملة، بتسعير يبدأ من Luna بسعر $1 إلى Sol بسعر $5 لكل مليون رمز إدخال. طابق كل استدعاء مع المستوى المناسب لتكلفته ومتطلبات ذكائه، دون أي تغييرات في نقاط النهاية.
استدلال مضبوط من أجل Vibecoding
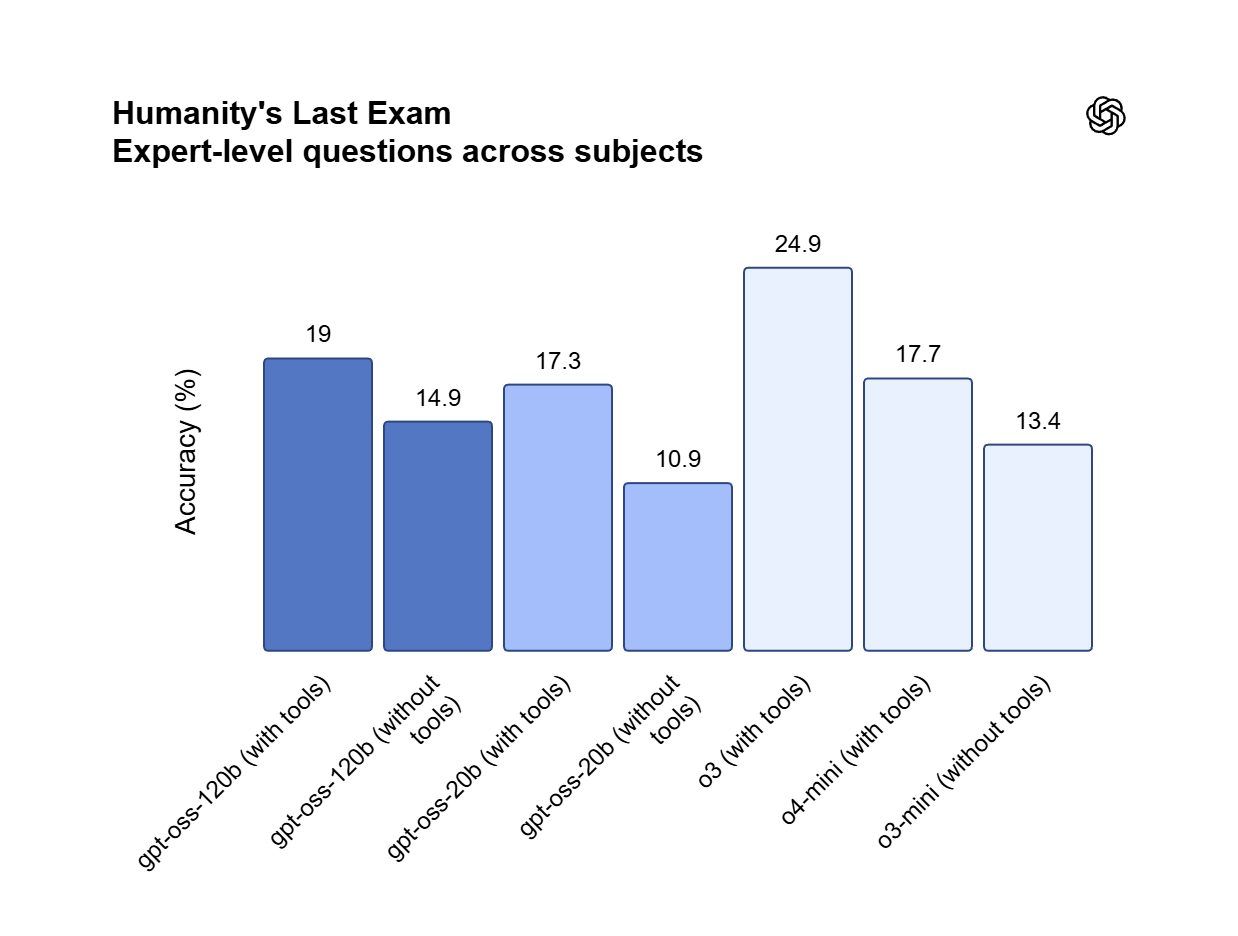
بفضل التقارب شبه الكامل مع OpenAI o4-mini، يستطيع GPT OSS 120B التعامل مع تركيب الشيفرة متعدد الخطوات والبراهين الرياضية. حوّل الأفكار المكتوبة بلغة طبيعية إلى تطبيقات ويب عاملة، وصحح المنطق المتداخل، ونسّق تدفقات جدولة المهام المعقدة.

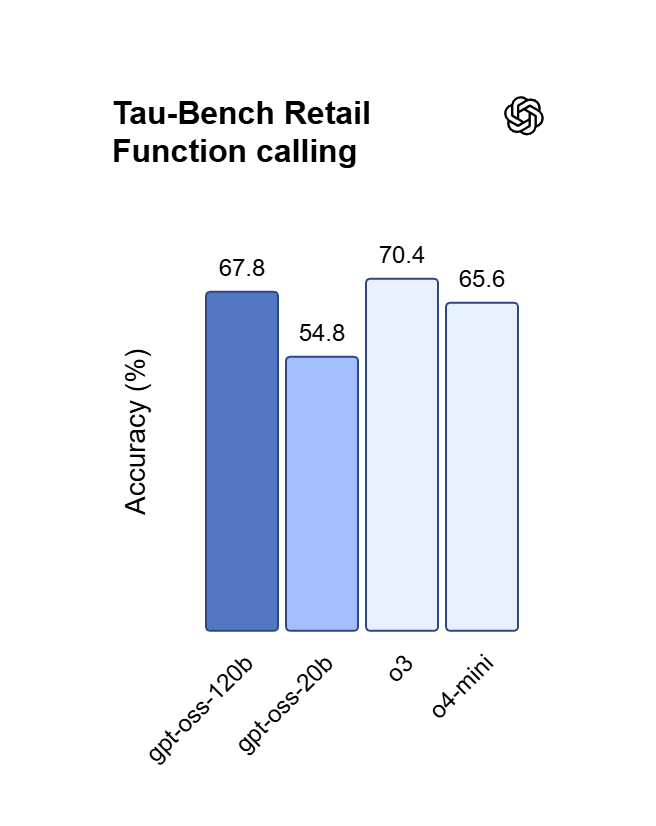
استدعاءات الدوال مع بحث ويب مباشر
تدعم نماذج GPT 5.x استدعاء الدوال مع اختيار تلقائي للأدوات، إضافة إلى بحث ويب مدمج يجلب النتائج الحالية. يمكنك بث الردود كأحداث مرسلة من الخادم، بينما يخفض التخزين المؤقت للمطالبات تكلفة إدخال GPT 5.6 Sol المخزن مؤقتًا إلى $0.5 لكل مليون رمز.
مطالبة واحدة، ثلاثة منافسين: مواجهة مباشرة عبر ChatGPT API
أرسلنا تعليمات البناء نفسها تمامًا إلى النماذج عبر ChatGPT API وإلى نموذجين رائدين منافسين، ثم عرضنا كل استجابة HTML خام كما هي من دون تعديل، لتتمكن من مقارنة عمق الاستدلال وجودة الكود والذائقة التصميمية جنبًا إلى جنب.
أنشئ ملف HTML واحدًا مكتفيًا بذاته (CSS وJavaScript مضمّنان فقط — من دون أي مكتبات خارجية إطلاقًا، ولا CDNs، ولا أطر عمل، ولا خطوط، ولا روابط صور) يفتح مباشرة في أي متصفح حديث ويشغّل محاكيًا حيًا ذاتي النمو لمنظومة دفيئة زجاجية، مرسومًا بالكامل كتصميم متجهي مسطح باستخدام Canvas/SVG. المشهد بملء الشاشة لدفيئة فيكتورية مقببة: تمتد قبة زجاجية منحنية عبر الأعلى كعنصر تأطير، وتُرسم ألواحها كمضلعات شفافة بلون أخضر يشمي مع لمعات انعكاسية ناعمة وحدود رفيعة للفواصل، ويمتد شريط من تربة زراعة داكنة على طول الأسفل. الاتجاه الفني هو رسم متجهي نظيف — أوراق وسيقان بخطوط عروق واضحة وتعبئات طبقية شبه شفافة، ولوحة ألوان ترتكز على أخضر الميرمية الضبابي وبني الطحالب مع ضوء شمس كهرماني ولمسات زجاج يشمي؛ بلا واقعية فوتوغرافية، ولا استخدام للتدرجات كخامات، مع الحفاظ على طابع رسومي ومرسوم يدويًا. التفاعل الأساسي: النقر في أي مكان على التربة يزرع بذرة في ذلك الموضع، وينمو النبات في الزمن الحقيقي باستخدام L-system فعلي — نفّذ قواعد إعادة كتابة تكرارية (axiom مع production rules تتضمن أقواس تفرّع واهتزازًا عشوائيًا في الزاوية/الطول لكل نسخة بحيث لا يتطابق نباتان) وحرّك الاشتقاق بحيث تتمدد الفروع، وتتفرع، وتنفرد الأوراق تدريجيًا خلال بضع ثوانٍ بدل أن تظهر مكتملة فجأة. يجب أن تنحني السرخسيات الاستوائية والكروم المتسلقة وتلتف ضوئيًا نحو شمس قابلة للسحب: اعرض قرص شمس كهرمانيًا متوهجًا يمكن للمستخدم الإمساك به وسحبه إلى أي مكان في السماء، ويجب أن يعيد كل طرف نامٍ توجيه اتجاه نموه باستمرار نحو موضع الشمس الحالي، بحيث يغيّر سحب الشمس بوضوح ميل الحديقة كلها وتسلقها. تنفرد الشتلات بحركة easing، وتتشكل قطرات تكاثف على الزجاج وتنزلق ببطء إلى الأسفل في حلقة مستمرة. حرّك كل شيء بدورة ليل ونهار مرتبطة بموضع الشمس: ينتقل الضوء المحيط وغسل السماء بسلاسة على تدرج من الذهبي الدافئ إلى الأزرق البارد، ويحدد موقع الشمس اتجاه وطول ظلال النباتات الناعمة الملقاة على الأرض وبقع الضوء العائمة عبر الزجاج، وعند الغسق تظهر اليراعات تدريجيًا كنقاط ضوء صغيرة نابضة تنجرف بين الأوراق. يجب أن يشع نمو النباتات من القاعدة صعودًا نحو المركز، محصورًا بقوس القبة. استخدم requestAnimationFrame لحلقة تحريك مستمرة تتنفس بهدوء؛ وحافظ على أداء سلس مع وجود الكثير من النباتات على الشاشة في الوقت نفسه. أضف عناصر تحكم خفيفة وغير مشتتة (مثل منزلق أو مفتاح تبديل للتقدم التلقائي لوقت اليوم، وزر إعادة ضبط/مسح) بتصميم ينسجم مع الطابع المرسوم، إلى جانب تلميح من سطر واحد يخبر المستخدم بالنقر على التربة للزراعة وسحب الشمس لتوجيه النمو. اجعله متجاوبًا مع أي حجم نافذة، واجعل النبرة الشعورية هادئة، ساكنة، وحية — كأول ضوء صباح مائل يدخل بينما تتفتح البراعم الغضة معًا. هذا محاكاة توليدية، وليس لعبة أو لوحة معلومات: أعطِ الأولوية لخوارزمية النمو التكرارية الحقيقية، وحلقة التحريك، وفيزياء الضوء/الظل/الانتحاء الضوئي.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
أنشئ صفحة HTML كاملة في ملف واحد تحتوي على لوحة معلومات تفاعلية عالمية لتمويل الشركات الناشئة، ببيانات خيالية لكنها متسقة داخليًا لـ 8 قطاعات صناعية عبر 5 سنوات. يجب أن تكون كل CSS وJavaScript مضمّنة من دون أي اعتماديات خارجية، ولا مكتبات رسوم بيانية، ولا CDNs، ولا صور. اعرض ثلاث تصورات بيانية مكتوبة يدويًا على canvas أو SVG: مخطط أعمدة متحرك يعيد الترتيب باستخدام easing عندما يختار المستخدم سنة من منزلق، ومخطط خطي مع تلميحات hover تعرض القيم الدقيقة ودليل تتبع عمودي، ومخطط donut تتمدد مقاطعه عند hover بحركة spring. أضف UI حديثة داكنة بلوحة لمسات من البنفسجي إلى الأخضر المزرق، وعدادات أرقام متحركة في أربع بطاقات إحصائية KPI، وصفًا لفلاتر القطاعات على شكل رقائق تبديل تحدّث كل الرسوم فورًا، ومفتاح تبديل بين الوضع الفاتح/الداكن مع انتقالات ألوان سلسة. يجب أن يكون التخطيط متجاوبًا، وينهار إلى عمود واحد تحت 768px، وأن يستجيب كل تفاعل في الزمن الحقيقي من دون إعادة تحميل الصفحة.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
كل أعباء العمل التي يمكن أن يشغّلها ChatGPT API
من البرمجة الوكيلية والاستخراج المنظم إلى دردشة الدعم المستندة إلى مصادر والمحتوى عالي الحجم، يوجّه ChatGPT API على Atlas Cloud كل مهمة إلى فئة GPT 5.6 المناسبة عبر مفتاح واحد متوافق مع OpenAI.

أطلق أدوات برمجة وكيلية باستخدام ChatGPT API
وجّه عمليات إعادة الهيكلة المعقدة وتوليد الأكواد عبر ملفات متعددة إلى GPT 5.6 Sol، فئة الاستدلال العميق في العائلة والمصممة لأعباء عمل هندسية متقدمة. تحصل الفرق التي تبني مساعدي برمجة، وروبوتات مراجعة آلية، ومولدات اختبارات على منطق جاهز للإنتاج.

توليد محتوى متوافق مع هوية العلامة على نطاق واسع
يصوغ GPT 5.6 Luna، الفئة الإبداعية في العائلة، منشورات المدونات، وأوصاف المنتجات، والنصوص المترجمة بنبرة طبيعية ومخرجات مخصصة. تتمكن فرق المحتوى ومنصات التجارة الإلكترونية من إنتاج نصوص بكميات كبيرة دون التفريط في صوت العلامة التجارية.

شغّل مساعدي الدعم عبر ChatGPT API
تحتاج إلى روبوت دردشة يلتزم بالنص؟ يقدم GPT 5.6 Terra ردودًا موثوقة ومستندة إلى سياق، ومصممة لمحادثات الإنتاج، بحيث تستطيع فرق الدعم ومنتجات SaaS أتمتة التذاكر وتقليل الاستفسارات المتكررة بثقة.

أنظمة معرفة معززة بالاسترجاع
أدخل أدلة سياسات كاملة أو أرشيفات بحثية في نموذج طويل السياق واحصل على إجابات مستندة إلى مصادر مع الحفاظ على دقة الإحالات. تحصل فرق الشؤون القانونية والطبية والبحث الداخلي على محرك موثوق للإجابة عن الأسئلة المعززة بالاسترجاع.

استخراج بيانات منظمة عبر ChatGPT API
تتحول الفواتير ورسائل البريد الإلكتروني وملفات PDF غير المرتبة إلى JSON نظيف يمكن للأنظمة اللاحقة الوثوق به. يحافظ اتباع التعليمات الموثوق على سلامة المخططات، مما يخدم خطوط أنابيب البيانات، وأتمتة CRM، وسير عمل التحليلات التي لا تحتمل الانحراف.

طابق كل مهمة مع فئة النموذج المناسبة
عندما تكون الميزانية وزمن الاستجابة مهمين، انتقل بين Sol وTerra وLuna عبر مفتاح واحد متوافق مع OpenAI. تنشئ الشركات الناشئة والمطورون المستقلون نماذج أولية بسرعة بتسعير الدفع حسب الاستخدام، ثم يوسعون التكامل نفسه إلى الإنتاج.
| النموذج | السياق | الحد الأقصى للإخراج | الإدخال | التموضع |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | نص | نموذج LLM للاستدلال عالي الكفاءة |
| GLM-5 | 202.75K | 202.75K | نص | نموذج تأسيسي رائد |
| DeepSeek V3.2 | 163.84K | 163.84K | نص | نموذج عام رائد |
| MiniMax-M2.5 | 204.8K | 196.6K | نص | SOTA في البرمجة الوكيلية |
كيفية استخدام ChatGPT على Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
إنشاء حساب Atlas Cloud
سجّل في atlascloud.ai وأكمل التحقق. يحصل المستخدمون الجدد على رصيد مجاني لاستكشاف المنصة واختبار النماذج.
لماذا تستخدم ChatGPT على Atlas Cloud
دمج نماذج ChatGPT المتقدمة مع منصة Atlas Cloud المسرّعة بـ GPU يوفر أداءً لا مثيل له وقابلية للتوسع وتجربة مطور استثنائية.
الأداء والمرونة
زمن انتقال منخفض:
استدلال محسّن لـ GPU للاستجابة في الوقت الفعلي.
API موحد:
قم بتشغيل ChatGPT و GPT و Gemini و DeepSeek من خلال تكامل واحد.
تسعير شفاف:
فواتير يمكن التنبؤ بها لكل رمز مع خيارات بدون خادم.
المؤسسات والتوسع
تجربة المطور:
SDKs والتحليلات وأدوات الضبط الدقيق والقوالب.
الموثوقية:
وقت تشغيل 99.99%، RBAC، وتسجيل جاهز للامتثال.
الأمان والامتثال:
SOC 2 Type II، توافق HIPAA، سيادة البيانات في الولايات المتحدة.
ChatGPT API: إجابات عن أسئلة المطورين
تتيح ChatGPT API للمطورين إرسال المطالبات إلى نماذج GPT من OpenAI وتلقي الإكمالات برمجيًا بدلًا من استخدام واجهة الدردشة. على Atlas Cloud يمكنك الوصول إلى تشكيلة GPT 5.6 الكاملة، إلى جانب GPT 5.4 وGPT 5.5، عبر endpoint واحد متوافق مع OpenAI. تُحتسب تكلفة كل استدعاء حسب عدد الرموز وفق تسعير شفاف بنظام الدفع حسب الاستخدام، لذا لا تدفع إلا مقابل ما تولّده.
تغطي خمسة نماذج نطاقًا يمتد من الاستدلال العميق إلى الدردشة اليومية. يستهدف GPT 5.6 Sol حلّ المشكلات الطموحة وأعباء العمل المتقدمة، ويتولى GPT 5.6 Terra سير عمل الإنتاج الموثوق، أما GPT 5.6 Luna فهو مضبوط للمحادثة الطبيعية وتوليد المحتوى. ويضيف GPT 5.4 وGPT 5.5 قدرات الاستدلال متعدد الوسائط والبرمجة للفرق التي تريد أداءً عامًا مثبتًا.
أنشئ مفتاح API واحدًا، واجعل عنوان base URL يشير إلى https://api.atlascloud.ai/v1، وحدد model ID مثل openai/gpt-5.6-terra. وبما أن ChatGPT API هنا متوافقة بالكامل مع OpenAI، فإن كود OpenAI SDK الحالي يعمل بعد تغيير base URL والمفتاح فقط. لا توجد قائمة انتظار ولا اشتراك، وتصل الإصدارات الجديدة مع وصول Day-0، لذا يمكنك إرسال أول طلب في اليوم نفسه.
يتدرج التسعير حسب النموذج الذي تختاره. يُعد GPT 5.6 Luna الأكثر توفيرًا بسعر $1 لكل مليون رمز إدخال و$6 لكل مليون رمز إخراج، ويبلغ سعر GPT 5.6 Terra $2.5 و$15، بينما يبلغ سعر GPT 5.6 Sol $5 و$30. يقلل تخزين المطالبات مؤقتًا تكلفة الإدخالات المتكررة، وتبقى الفوترة بنظام الدفع حسب الاستخدام بحيث تُحاسب فقط على الرموز التي تستخدمها.
نعم. يتبع endpoint تنسيق OpenAI Chat Completions، لذلك تعمل حِزم OpenAI SDK الرسمية وLangChain ومعظم المكتبات المتوافقة مع OpenAI بمجرد تبديل base URL والمفتاح. وهذا يعني أن تكامل ChatGPT API الحالي يمكن نقله دون إعادة كتابة منطق الطلبات لديك.
يعمل كل من البث واستدعاء الدوال دون تغيير عن تطبيق OpenAI، لذا تضبط stream على true للحصول على إخراج رمزًا برمز، وتمرر مصفوفة tools لتشغيل استدعاءات الدوال. وتتبع استجابات JSON المهيكلة تنسيق الطلب نفسه المتوافق مع OpenAI، ما يحافظ على قابلية التنبؤ في تنسيق الوكلاء وخطوط استخراج البيانات.
تقبل هذه النماذج مطالبات كبيرة لسير عمل المستندات الطويلة والمستودعات الكاملة. يُقسّم التسعير عند علامة 272,000 رمز، بسعر قياسي للمطالبات الأقل من ذلك وسعر ثانٍ للمطالبات التي تتجاوز 272,000 رمز. لذلك يمكنك تمرير سياق واسع في طلب واحد ومعرفة كيفية تغيّر السعر بدقة مع نمو المطالبة.
طابق النموذج مع المهمة. اختر GPT 5.6 Sol عندما تحتاج إلى استدلال متقدم وحلّ مشكلات طموح، واختر GPT 5.6 Terra للتحليل المتزن المناسب للإنتاج، واستخدم GPT 5.6 Luna للأعمال الحوارية أو الإبداعية عندما تكون التكلفة هي الأهم. ويظل GPT 5.4 وGPT 5.5 خيارين قويين متعددَي الوسائط للبرمجة والاستدلال العام.
تشغّل Atlas Cloud ChatGPT API على بنية تحتية مُدارة تتوسع مع حركة المرور لديك، وبذلك تتجنب توفير GPU وتنسيق العقد في الاستضافة الذاتية. تصل إصدارات النماذج الجديدة مع وصول Day-0، ما يبقيك محدثًا دون أعمال ترحيل. وإذا زادت احتياجاتك، فإن مفتاح OpenAI-compatible نفسه يغطي كل نموذج في العائلة، لذا لا يعني التوسع أبدًا إنشاء تكامل جديد.
استكشف المزيد من العائلات
Seedance 2.0
تمنحك واجهة برمجة تطبيقات Seedance 2.0 وصولاً إنتاجيًا إلى نموذج الفيديو متعدد الوسائط من ByteDance — إدخالات رباعية الوسائط (نص، صورة، فيديو، صوت) ونظام "Universal Reference" الرائد في الصناعة والذي يثبت التكوين وحركة الكاميرا وإجراءات الشخصيات عبر اللقطات. قم بدمج تحكم على مستوى المخرج من خلال استدعاء API واحد، بسعر ثابت قدره 0.09 دولار/ثانية، ومفتاح فوري، وبدون قائمة انتظار — مدعومًا بوقت تشغيل وامتثال على مستوى المؤسسات. Seedance 2.0 Native 4K متاح الآن!
Grok Imagine
توفر Grok Imagine API للمطورين إمكانية إنشاء الصور ومقاطع الفيديو والصوت من xAI في حزمة واحدة. وتنتج صورًا بدقة تصل إلى 2K مع عرض نص متعدد اللغات، بالإضافة إلى مقاطع فيديو تصل مدتها إلى 15 ثانية مع صوت أصلي متزامن وتحرير قائم على المراجع. على Atlas Cloud، يقوم مفتاح واحد بتشغيل كل وضع من أوضاع Grok Imagine، لذا يمكنك التنقل بين الصور والفيديو والصوت دون إعدادات منفصلة، بدءًا من 0.02 دولار لكل صورة و0.05 دولار لكل ثانية.
Gemini Omni Flash
يجلب Gemini Omni API إلى بنيتك التقنية نموذج التوليد والتحرير متعدد الوسائط للفيديو من Google DeepMind، الذي أُعلن عنه في Google I/O 2026. يدمج Gemini Omni محرك الاستدلال في Gemini مع الوسائط التوليدية، ويقبل أي مزيج من النصوص والصور والفيديو والصوت لإنتاج مخرجات متسقة ومستندة إلى المعرفة. حسّن النتائج عبر محادثة طبيعية: استبدل العناصر، وأعد كتابة المشاهد، وغيّر الأنماط، مع بقاء الفيزياء والشخصيات والاستمرارية سليمة دون أي خلل. توفر Atlas Cloud تشكيلة Gemini Omni Flash الكاملة — تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو مع ما يصل إلى 7 صور مرجعية، وتحويل المرجع إلى فيديو — عبر واجهة API موحدة بتسعير شفاف لكل ثانية يبدأ من $0.112 ومن دون اشتراك. ابدأ البناء اليوم.
GPT Image 2
توفر واجهة برمجة تطبيقات GPT Image 2 للمطورين إمكانية الوصول إلى أحدث نموذج صور من OpenAI، وهو خليفة GPT Image 1.5. يقوم النموذج بإنشاء الصور وتعديلها مع عرض دقيق للنصوص عبر الحروف اللاتينية ونصوص CJK، بالإضافة إلى تكوين قوي للملصقات والنماذج المبدئية والرسوم البيانية (الإنفوجرافيك). على Atlas Cloud، يمكنك الوصول إليه من خلال واجهة برمجة تطبيقات موحدة بجانب أكثر من 300 نموذج، مع أرصدة مجانية، ووقت تشغيل بنسبة 99.99%، وبدون الحاجة إلى التحقق من مؤسسة OpenAI.
تتوفر أقوى النماذج الإبداعية من Google بالكامل على Atlas Cloud. يقدم Veo 3.1 توليد فيديو سينمائي، ويدعم Nano Banana 2 إنشاء صور عالية الدقة، ويجلب Gemini ذكاءً متعدد الوسائط لكل سير عمل. يمكنك الوصول إلى مجموعة نماذج Google الكاملة من خلال مفتاح API key واحد مع توفر Day-0 وتسعير الدفع حسب الاستخدام (pay-as-you-go).
Seedance 2.0 Mini
يجلب Seedance 2.0 Mini إنشاء مقاطع الفيديو متعددة الوسائط من ByteDance إلى مسارات العمل حيث تعتبر السرعة والتكلفة الأكثر أهمية. إنه يوفر القدرات الأساسية لـ Seedance 2.0 ببصمة أخف — إنشاء أسرع، وتكلفة أقل لكل مقطع فيديو، ونفس تكامل API الذي تستخدمه بالفعل. بالنسبة للفرق التي تدير مسارات عمل ذات حجم كبير أو تقوم بالنماذج الأولية على نطاق واسع، فإن Mini هو الخيار الافتراضي العملي.
ByteDance
من إنشاء مقاطع الفيديو السينمائية إلى توليد الصور عالية الدقة، أصبحت أقوى نماذج ByteDance متاحة الآن على Atlas Cloud. يمكنك تشغيل Seedance و Seedream على نطاق واسع بأقل أسعار للاستدلال وبدون أي أعباء إضافية للبنية التحتية.
Alibaba
تجمع Atlas Cloud مجموعة نماذج Alibaba الكاملة ضمن API واحد: Qwen لمهام اللغة والصورة، و Wan لإنشاء مقاطع الفيديو بدقة تصل إلى 1080p. يمكنك الوصول إلى كل نموذج بنظام الدفع حسب الاستخدام (pay-as-you-go) دون أي اشتراكات. تتوفر Alibaba API عبر عنوان URL أساسي واحد باستخدام عميلك الحالي المتوافق مع OpenAI.
OpenAI
تمنحك Atlas Cloud إمكانية الوصول إلى مجموعة API الكاملة من OpenAI، بدءًا من GPT Image 2 لتوليد الصور وحتى Sora 2 للفيديو. يتوفر كل نموذج بنظام الدفع حسب الاستخدام بدون أي التزام شهري. يمكنك الربط بسهولة عن طريق تبديل عنوان URL الأساسي باستخدام الـ API المتوافق مع OpenAI.
xAI
قم ببناء مسارات عمل كاملة للصور والفيديو باستخدام xAI API على Atlas Cloud. قم بالتوليد بدقة 2K، والتحرير باستخدام صور مرجعية، وتحريك الصور إلى مقاطع متزامنة مع الصوت.
Kwaivgi
واجهة برمجة تطبيقات Kwaivgi (API) بسعر أقل بنسبة 15% من السعر القياسي. توفر Atlas Cloud وصولاً من اليوم الأول (Day-0) إلى إصدارات Kling الجديدة مع تسعير الدفع حسب الاستخدام وبدون حدود لعدد المقاعد. حساب واحد، مفتاح واحد، وكل نماذج Kling من المستوى القياسي إلى المستوى الرئيسي (master).
Seedream 5.0 Pro
يوفر واجهة برمجة التطبيقات Seedream 5.0 Pro API للمطورين نموذج تحرير الصور القابل للتحكم من ByteDance على Atlas Cloud. وهو يضع التعديلات بدقة باستخدام نقاط الإرساء والإحداثيات، ويفصل الصور إلى طبقات قابلة للتحرير، ويدمج مراجع متعددة، ويطابق الألوان والمواد الدقيقة، مع نص متعدد اللغات بدقة 2K و 3K. على Atlas Cloud، يمكنك الوصول إليه من خلال مفتاح واحد!


