Gemini Omni Flash API for Conversational Video Editing
يجلب Gemini Omni API إلى بنيتك التقنية نموذج التوليد والتحرير متعدد الوسائط للفيديو من Google DeepMind، الذي أُعلن عنه في Google I/O 2026. يدمج Gemini Omni محرك الاستدلال في Gemini مع الوسائط التوليدية، ويقبل أي مزيج من النصوص والصور والفيديو والصوت لإنتاج مخرجات متسقة ومستندة إلى المعرفة. حسّن النتائج عبر محادثة طبيعية: استبدل العناصر، وأعد كتابة المشاهد، وغيّر الأنماط، مع بقاء الفيزياء والشخصيات والاستمرارية سليمة دون أي خلل. توفر Atlas Cloud تشكيلة Gemini Omni Flash الكاملة — تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو مع ما يصل إلى 7 صور مرجعية، وتحويل المرجع إلى فيديو — عبر واجهة API موحدة بتسعير شفاف لكل ثانية يبدأ من $0.112 ومن دون اشتراك. ابدأ البناء اليوم.
استكشف النماذج الرائدة
يوفر لك Atlas Cloud أحدث النماذج الإبداعية الرائدة في الصناعة.







أربع طرق للتوليد باستخدام Gemini Omni Flash API
اختر نقطة نهاية Gemini Omni Flash API التي تناسب المهمة، بدءًا من تحويل النص إلى فيديو والصورة إلى فيديو، وصولاً إلى التوليد القائم على المراجع والتحرير الحواري.
| النمط | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | هل لديك موجه نصي فقط؟ تعمل Gemini Omni Flash Text-to-Video API على تحويله إلى مقطع فيديو بدقة 720 بكسل مع صوت متزامن في خطوة واحدة، مع اتباع توجيه قائم على الاستدلال للمشهد والحركة والكاميرا لمقاطع تصل مدتها إلى 10 ثوانٍ. |
| Gemini Omni Flash Image-to-Video API (I2V) | تقوم واجهة برمجة تطبيقات Image-to-Video من Gemini Omni Flash بتحريك صورة ثابتة، مع تثبيت المصدر كإطار افتتاحي. وبفضل الحركة الطبيعية والصوت المتزامن، فإنها تبث الحياة في لقطات المنتجات والصور الشخصية والمفاهيم بدقة 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | قم بتوجيه عملية التوليد باستخدام ما يصل إلى سبع صور مرجعية وثلاثة مقاطع فيديو قصيرة باستخدام Gemini Omni Flash Reference-to-Video API. فهي تحافظ على اتساق الشخصية والأسلوب والمشهد عبر المقطع، مما يجعلها مثالية للمحتوى ذي العلامة التجارية وسلاسل الحلقات. |
| Gemini Omni Flash Video Edit API | عندما يحتاج المقطع إلى تعديلات، تُطبق Gemini Omni Flash Video Edit API تعليمات اللغة الطبيعية من خلال Interactions API ذات حالة. فهي تستبدل العناصر وتضبط الإضاءة وتعيد تصميم المشاهد، مع الحفاظ على بقية اللقطات سليمة عبر جولات التفاعل المتعددة. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
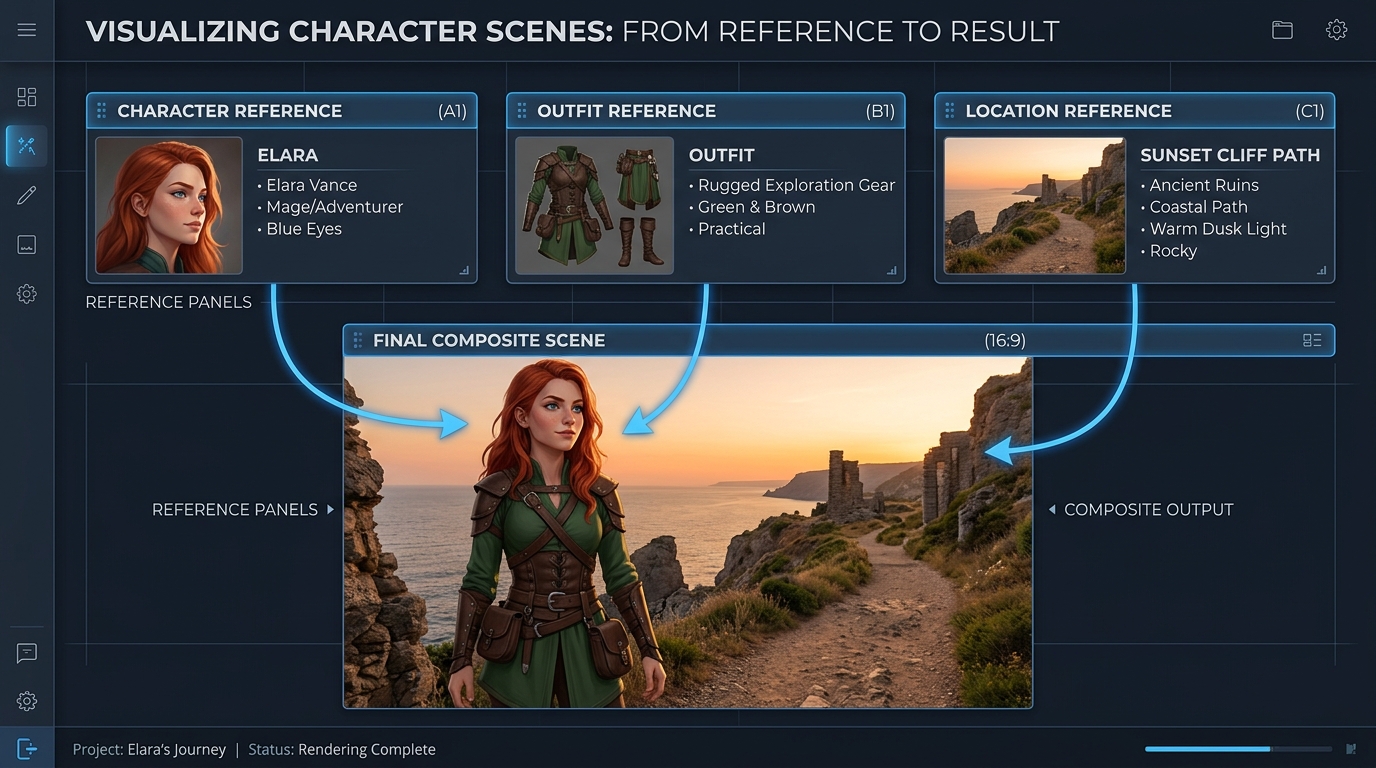
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
مقارنة Gemini Omni Flash API
شاهد كيف تتقارن نماذج مختلف المزودين — قارن الأداء والأسعار ونقاط القوة الفريدة لاتخاذ قرار مدروس.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | تحرير الفيديو النهائي من خلال المحادثة | Yes | نعم، يحتفظ بالحالة | النص، الصورة، الفيديو، الصوت |
| Veo 3.1 | مقاطع سينمائية مع توسيع المشهد | Yes | No | نص، صورة، مرجع |
| Seedance 2.0 | فيديو فائق الجودة يتم التحكم فيه بالمرجع | Yes | No | نص، صورة، فيديو، صوت |
| Kling 3.0 | سرد قصصي متعدد اللقطات بإخراج الذكاء الاصطناعي | Yes | No | نص، صورة، مرجع |
كيفية استخدام Gemini Omni Flash على Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
إنشاء حساب Atlas Cloud
سجّل في atlascloud.ai وأكمل التحقق. يحصل المستخدمون الجدد على رصيد مجاني لاستكشاف المنصة واختبار النماذج.
لماذا تستخدم Gemini Omni Flash على Atlas Cloud
دمج نماذج Gemini Omni Flash المتقدمة مع منصة Atlas Cloud المسرّعة بـ GPU يوفر أداءً لا مثيل له وقابلية للتوسع وتجربة مطور استثنائية.
الأداء والمرونة
زمن انتقال منخفض:
استدلال محسّن لـ GPU للاستجابة في الوقت الفعلي.
API موحد:
قم بتشغيل Gemini Omni Flash و GPT و Gemini و DeepSeek من خلال تكامل واحد.
تسعير شفاف:
فواتير يمكن التنبؤ بها لكل رمز مع خيارات بدون خادم.
المؤسسات والتوسع
تجربة المطور:
SDKs والتحليلات وأدوات الضبط الدقيق والقوالب.
الموثوقية:
وقت تشغيل 99.99%، RBAC، وتسجيل جاهز للامتثال.
الأمان والامتثال:
SOC 2 Type II، توافق HIPAA، سيادة البيانات في الولايات المتحدة.
الأسئلة الشائعة حول Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
استكشف المزيد من العائلات
Seedance 2.0
تمنحك واجهة برمجة تطبيقات Seedance 2.0 وصولاً إنتاجيًا إلى نموذج الفيديو متعدد الوسائط من ByteDance — إدخالات رباعية الوسائط (نص، صورة، فيديو، صوت) ونظام "Universal Reference" الرائد في الصناعة والذي يثبت التكوين وحركة الكاميرا وإجراءات الشخصيات عبر اللقطات. قم بدمج تحكم على مستوى المخرج من خلال استدعاء API واحد، بسعر ثابت قدره 0.09 دولار/ثانية، ومفتاح فوري، وبدون قائمة انتظار — مدعومًا بوقت تشغيل وامتثال على مستوى المؤسسات. Seedance 2.0 Native 4K متاح الآن!
Grok Imagine
توفر Grok Imagine API للمطورين إمكانية إنشاء الصور ومقاطع الفيديو والصوت من xAI في حزمة واحدة. وتنتج صورًا بدقة تصل إلى 2K مع عرض نص متعدد اللغات، بالإضافة إلى مقاطع فيديو تصل مدتها إلى 15 ثانية مع صوت أصلي متزامن وتحرير قائم على المراجع. على Atlas Cloud، يقوم مفتاح واحد بتشغيل كل وضع من أوضاع Grok Imagine، لذا يمكنك التنقل بين الصور والفيديو والصوت دون إعدادات منفصلة، بدءًا من 0.02 دولار لكل صورة و0.05 دولار لكل ثانية.
Gemini Omni Flash
يجلب Gemini Omni API إلى بنيتك التقنية نموذج التوليد والتحرير متعدد الوسائط للفيديو من Google DeepMind، الذي أُعلن عنه في Google I/O 2026. يدمج Gemini Omni محرك الاستدلال في Gemini مع الوسائط التوليدية، ويقبل أي مزيج من النصوص والصور والفيديو والصوت لإنتاج مخرجات متسقة ومستندة إلى المعرفة. حسّن النتائج عبر محادثة طبيعية: استبدل العناصر، وأعد كتابة المشاهد، وغيّر الأنماط، مع بقاء الفيزياء والشخصيات والاستمرارية سليمة دون أي خلل. توفر Atlas Cloud تشكيلة Gemini Omni Flash الكاملة — تحويل النص إلى فيديو، وتحويل الصورة إلى فيديو مع ما يصل إلى 7 صور مرجعية، وتحويل المرجع إلى فيديو — عبر واجهة API موحدة بتسعير شفاف لكل ثانية يبدأ من $0.112 ومن دون اشتراك. ابدأ البناء اليوم.
GPT Image 2
توفر واجهة برمجة تطبيقات GPT Image 2 للمطورين إمكانية الوصول إلى أحدث نموذج صور من OpenAI، وهو خليفة GPT Image 1.5. يقوم النموذج بإنشاء الصور وتعديلها مع عرض دقيق للنصوص عبر الحروف اللاتينية ونصوص CJK، بالإضافة إلى تكوين قوي للملصقات والنماذج المبدئية والرسوم البيانية (الإنفوجرافيك). على Atlas Cloud، يمكنك الوصول إليه من خلال واجهة برمجة تطبيقات موحدة بجانب أكثر من 300 نموذج، مع أرصدة مجانية، ووقت تشغيل بنسبة 99.99%، وبدون الحاجة إلى التحقق من مؤسسة OpenAI.
تتوفر أقوى النماذج الإبداعية من Google بالكامل على Atlas Cloud. يقدم Veo 3.1 توليد فيديو سينمائي، ويدعم Nano Banana 2 إنشاء صور عالية الدقة، ويجلب Gemini ذكاءً متعدد الوسائط لكل سير عمل. يمكنك الوصول إلى مجموعة نماذج Google الكاملة من خلال مفتاح API key واحد مع توفر Day-0 وتسعير الدفع حسب الاستخدام (pay-as-you-go).
Seedance 2.0 Mini
يجلب Seedance 2.0 Mini إنشاء مقاطع الفيديو متعددة الوسائط من ByteDance إلى مسارات العمل حيث تعتبر السرعة والتكلفة الأكثر أهمية. إنه يوفر القدرات الأساسية لـ Seedance 2.0 ببصمة أخف — إنشاء أسرع، وتكلفة أقل لكل مقطع فيديو، ونفس تكامل API الذي تستخدمه بالفعل. بالنسبة للفرق التي تدير مسارات عمل ذات حجم كبير أو تقوم بالنماذج الأولية على نطاق واسع، فإن Mini هو الخيار الافتراضي العملي.
ByteDance
من إنشاء مقاطع الفيديو السينمائية إلى توليد الصور عالية الدقة، أصبحت أقوى نماذج ByteDance متاحة الآن على Atlas Cloud. يمكنك تشغيل Seedance و Seedream على نطاق واسع بأقل أسعار للاستدلال وبدون أي أعباء إضافية للبنية التحتية.
Alibaba
تجمع Atlas Cloud مجموعة نماذج Alibaba الكاملة ضمن API واحد: Qwen لمهام اللغة والصورة، و Wan لإنشاء مقاطع الفيديو بدقة تصل إلى 1080p. يمكنك الوصول إلى كل نموذج بنظام الدفع حسب الاستخدام (pay-as-you-go) دون أي اشتراكات. تتوفر Alibaba API عبر عنوان URL أساسي واحد باستخدام عميلك الحالي المتوافق مع OpenAI.
OpenAI
تمنحك Atlas Cloud إمكانية الوصول إلى مجموعة API الكاملة من OpenAI، بدءًا من GPT Image 2 لتوليد الصور وحتى Sora 2 للفيديو. يتوفر كل نموذج بنظام الدفع حسب الاستخدام بدون أي التزام شهري. يمكنك الربط بسهولة عن طريق تبديل عنوان URL الأساسي باستخدام الـ API المتوافق مع OpenAI.
xAI
قم ببناء مسارات عمل كاملة للصور والفيديو باستخدام xAI API على Atlas Cloud. قم بالتوليد بدقة 2K، والتحرير باستخدام صور مرجعية، وتحريك الصور إلى مقاطع متزامنة مع الصوت.
Kwaivgi
واجهة برمجة تطبيقات Kwaivgi (API) بسعر أقل بنسبة 15% من السعر القياسي. توفر Atlas Cloud وصولاً من اليوم الأول (Day-0) إلى إصدارات Kling الجديدة مع تسعير الدفع حسب الاستخدام وبدون حدود لعدد المقاعد. حساب واحد، مفتاح واحد، وكل نماذج Kling من المستوى القياسي إلى المستوى الرئيسي (master).
Seedream 5.0 Pro
يوفر واجهة برمجة التطبيقات Seedream 5.0 Pro API للمطورين نموذج تحرير الصور القابل للتحكم من ByteDance على Atlas Cloud. وهو يضع التعديلات بدقة باستخدام نقاط الإرساء والإحداثيات، ويفصل الصور إلى طبقات قابلة للتحرير، ويدمج مراجع متعددة، ويطابق الألوان والمواد الدقيقة، مع نص متعدد اللغات بدقة 2K و 3K. على Atlas Cloud، يمكنك الوصول إليه من خلال مفتاح واحد!


