Lanzamiento preliminar de DeepSeek-V4: 1M de tokens de contexto, mejoras en agentes y pesos de código abierto
Hoy (24 de abril), DeepSeek lanza oficialmente y libera bajo código abierto la versión preliminar de DeepSeek-V4, su nueva serie de modelos.
DeepSeek-V4 admite hasta un millón de tokens de contexto y alcanza un rendimiento líder entre los modelos nacionales y de código abierto en capacidades agentes, conocimiento general y razonamiento. La serie cuenta con dos tamaños:
- DeepSeek-V4-Pro: el modelo insignia, es un modelo MoE (Mixtura de Expertos) masivo con 1.6 billones de parámetros totales, pero solo 49B activados por paso hacia adelante; esta es la clave de su eficiencia.
- DeepSeek-V4-Flash: la opción más rápida y económica. Sigue el mismo diseño MoE a una escala mucho menor (284B total / 13B activos), lo que permite una inferencia más rápida y barata.
- Ambos modelos comparten la misma ventana de contexto de 1M de tokens y son de código abierto con acceso mediante API.
| Modelo | Parámetros | Activación | Datos de preentrenamiento | Longitud de contexto | Código abierto | Servicio API | Modo de acceso Web/App |
|---|---|---|---|---|---|---|---|
| deepseek-v4-pro | 1.6T | 49B | 33T | 1M | ✓ | ✓ | Modo Experto |
| deepseek-v4-flash | 284B | 13B | 32T | 1M | ✓ | ✓ | Modo Rápido |
Desde hoy, puedes chatear con DeepSeek-V4 en chat.deepseek.com o a través de la aplicación oficial. La API también está disponible: simplemente configura model_name como deepseek-v4-pro o deepseek-v4-flash para comenzar.
Ya habíamos informado sobre las especulaciones y análisis previos (consulta nuestra guía de expectativas de DeepSeek V4 y nuestro análisis técnico profundo); ahora tenemos los detalles oficiales confirmados directamente de la fuente. A continuación, cubrimos exactamente qué se ha lanzado, qué hay de nuevo y qué significa si estás desarrollando o evaluando modelos de IA hoy.
DeepSeek-V4-Pro: rivalizando con los principales modelos de código cerrado
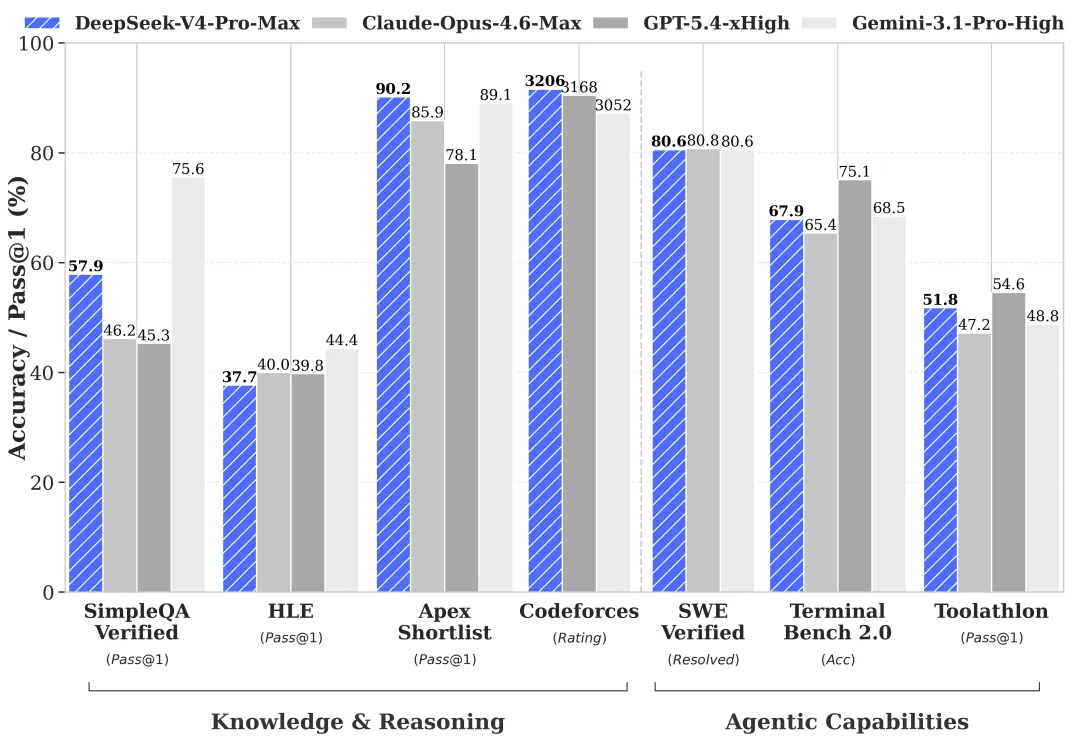
Capacidades agentes significativamente mejoradas. En comparación con su predecesor, DeepSeek-V4-Pro muestra una mejora drástica en tareas de agentes. En los benchmarks de codificación agente, V4-Pro lidera ahora entre todos los modelos de código abierto. DeepSeek también ha desplegado V4-Pro internamente como el agente de codificación preferido de la empresa; la retroalimentación de los empleados indica que la experiencia supera a Claude Sonnet 4.5, con una calidad de salida que se acerca a Claude Opus 4.6 en modo sin pensamiento (non-thinking), aunque todavía por detrás del modo de pensamiento de Opus 4.6.
Amplio conocimiento general. DeepSeek-V4-Pro supera significativamente a otros modelos de código abierto en benchmarks de conocimiento general, quedando solo ligeramente por debajo del mejor modelo de código cerrado, Gemini Pro 3.1.
Razonamiento de clase mundial. En evaluaciones de matemáticas, STEM y programación competitiva, DeepSeek-V4-Pro supera a todos los modelos de código abierto evaluados anteriormente y alcanza el rendimiento de los principales modelos de código cerrado del mundo.
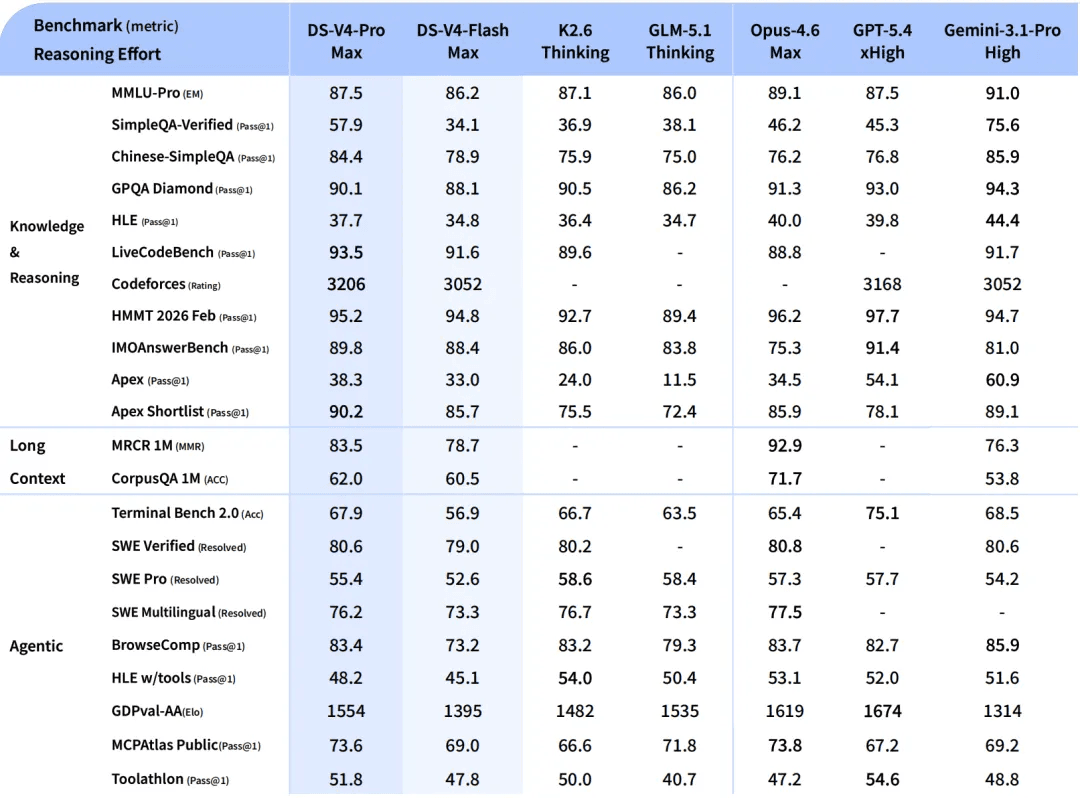
DeepSeek-V4-Flash: la opción rápida y asequible
En comparación con V4-Pro, DeepSeek-V4-Flash se queda ligeramente atrás en conocimiento general, pero ofrece un rendimiento de razonamiento comparable. Gracias a su menor número de parámetros y menores costes de activación, V4-Flash proporciona tiempos de respuesta más rápidos y precios de API más económicos.
En los benchmarks de agentes, V4-Flash iguala a V4-Pro en tareas más sencillas, aunque persiste una brecha en las más complejas.
Innovación arquitectónica y eficiencia extrema de contexto
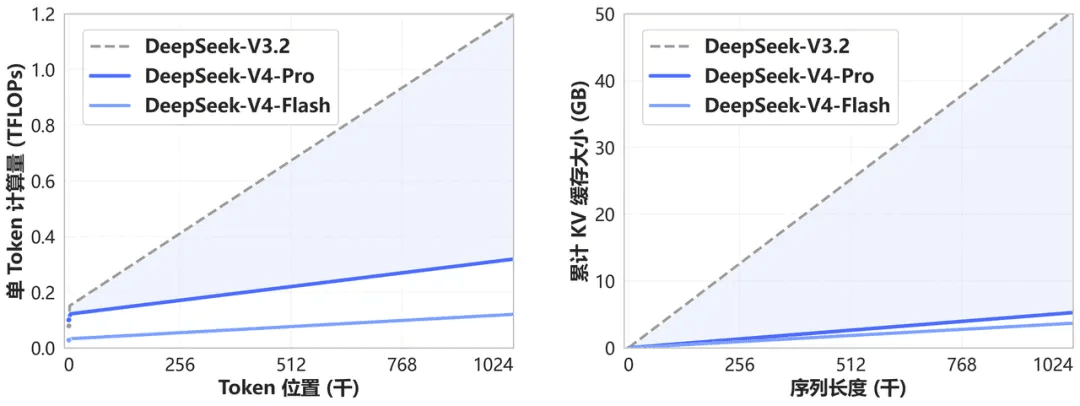
DeepSeek-V4 introduce un novedoso mecanismo de atención que realiza la compresión a lo largo de la dimensión del token. Combinado con DSA (DeepSeek Sparse Attention), este diseño logra un rendimiento de contexto largo líder en el mundo, reduciendo drásticamente los requisitos computacionales y de memoria en comparación con los enfoques convencionales.
De ahora en adelante, el contexto de 1M (un millón) de tokens es el estándar para todos los servicios oficiales de DeepSeek.
Optimización especializada para casos de uso de agentes
DeepSeek-V4 ha sido ajustado y optimizado para productos de agentes populares, incluyendo Claude Code, OpenClaw, OpenCode y CodeBuddy. Se han observado mejoras de rendimiento en la generación de código, la creación de documentos y otras tareas impulsadas por agentes.
Este tipo de ajuste específico para marcos de trabajo importa más en la práctica de lo que parece. Un modelo que funciona bien de forma aislada pero se comporta de manera inconsistente dentro de un bucle de agentes estructurado es difícil de desplegar de forma fiable. La decisión de tratar los principales marcos de agentes como objetivos de optimización de primer nivel refleja cómo ha evolucionado el uso de la IA en producción.
Acceso a la API de DeepSeek-V4
Tanto V4-Pro como V4-Flash ya están disponibles a través de la API de DeepSeek, con soporte tanto para la interfaz OpenAI ChatCompletions como para la interfaz Anthropic, lo que significa que las integraciones existentes pueden apuntar a los modelos V4 con cambios mínimos en el código. La base_url permanece sin cambios; simplemente actualiza el parámetro del modelo a deepseek-v4-pro o deepseek-v4-flash.
Ambos modelos admiten una longitud máxima de contexto de 1M de tokens y ofrecen modos sin pensamiento (non-thinking) y con pensamiento (thinking). En el modo con pensamiento, se puede configurar un parámetro reasoning_effort en "high" o "max". Para flujos de trabajo de agentes complejos, se recomienda el modo con pensamiento con intensidad máxima. Documentación para el acceso a la API: https://api-docs.deepseek.com/zh-cn/guides/thinking_mode
⚠️ Aviso de obsolescencia: Los nombres de modelo antiguos
deepseek-chatydeepseek-reasonerse retirarán en tres meses (24 de julio de 2026). Durante el período de transición, se asignan a los modos sin pensamiento y con pensamiento dedeepseek-v4-flash, respectivamente. Si estás utilizando cualquiera de estos nombres en producción, planifica tu migración ahora.
Pesos de código abierto y despliegue local
- Pesos del modelo:Hugging Face | ModelScope
- Informe técnico:PDF de DeepSeek-V4
Para los equipos que consideran el despliegue local o en las instalaciones (on-premise), vale la pena señalar que los modelos a esta escala de parámetros, particularmente V4-Pro con 1.6T de parámetros totales, exigen mucho del hardware. La disponibilidad de código abierto es una ventaja significativa para el cumplimiento empresarial y casos de uso de personalización, pero la mayoría de los equipos encontrarán que el acceso a la API en la nube es el punto de partida más práctico.
Qué significa realmente este lanzamiento de DeepSeek-V4
Tres cosas destacan de este lanzamiento.
Primero, el compromiso de 1M de contexto es más significativo de lo que parece. DeepSeek no lo ofrece como un nivel premium; es el estándar para todos los servicios oficiales. Es una señal de hacia dónde se dirige la frontera del código abierto y ejerce una presión silenciosa sobre todos los demás proveedores para que sigan sus pasos.
Segundo, el trabajo de optimización centrado en agentes —específicamente adaptando V4 para Claude Code, OpenCode y otros— refleja una madurez en cómo DeepSeek piensa en el despliegue. El rendimiento en benchmarks es solo el punto de partida; lo que importa para la producción es el comportamiento dentro de las herramientas que los desarrolladores realmente usan.
Tercero, el posicionamiento competitivo honesto en relación con Claude Opus 4.6 es notable. En lugar de afirmar una superioridad absoluta, DeepSeek ofrece una evaluación escalonada: mejor que Sonnet 4.5, acercándose a Opus 4.6 sin pensamiento, por detrás del modo de pensamiento de Opus 4.6. Esa especificidad hace que las afirmaciones sean más creíbles, no menos.
Para los desarrolladores que evalúan modelos para flujos de trabajo de agentes, procesamiento de documentos largos o tareas de razonamiento complejo, DeepSeek-V4-Pro es ahora un competidor serio de código abierto. Para los procesos optimizados por costes o sensibles a la latencia, V4-Flash ofrece una alternativa más ligera y creíble.
Prueba DeepSeek-V4 en Atlas Cloud
Atlas Cloud es una plataforma de IA de nivel de producción diseñada para desarrolladores y equipos que desean un acceso fiable y rentable a los principales modelos de IA del mundo sin gestionar la infraestructura. Con una API unificada, precios transparentes y cumplimiento de nivel empresarial (alineado con SOC 2, listo para HIPAA), Atlas Cloud te permite centrarte en construir, no en las operaciones.
DeepSeek en Atlas Cloud. Ya apoyamos a la familia de modelos DeepSeek, incluyendo DeepSeek V3.2, V3.2 Fast, V3.2 Speciale y V3.2 Exp, disponibles hoy a través de un único endpoint de API a precios competitivos. Los modelos de DeepSeek en Atlas Cloud están optimizados para cargas de trabajo de contexto largo y flujos de trabajo de agentes, con soporte total para la ventana de contexto y sin pérdida por cuantización. Más allá de DeepSeek, Atlas Cloud te da acceso a más de 300 modelos en todo el panorama LLM.
DeepSeek-V4 llegará a Atlas Cloud. Estamos trabajando activamente en la integración de DeepSeek-V4-Pro y V4-Flash. Mantente atento al anuncio de lanzamiento y, mientras tanto, explora todo lo que ya está disponible en la plataforma.






