
You know the feeling.
It's late. You're four revisions deep into a brand campaign. The AI just generated perfect lighting on the hero shot — but your model's face has subtly changed for the third time tonight. Same outfit. Different person. You can't ship it. You can't fix it. You start over.
By midnight, you're not editing a video anymore. You're playing roulette.
For anyone trying to build narrative continuity — a product demo with the same model across shots, a tutorial with the same teacher across scenes, a music video with the same singer across cuts — character drift has been the silent killer of every AI video tool. It's why AI video has lived in "neat demos" purgatory instead of going commercial.

On May 19 at I/O 2026, Google's Gemini Omni made the case that this era is ending.
The entire promise distills to one line on Google's DeepMind product page: "Every edit you make builds on the one before — maintaining a consistent, coherent scene."
The Three-Step Violinist Demo That Quietly Made History
The most consequential moment of the I/O announcement wasn't the rolling marble. It wasn't the bubble sculpture. It was a violinist.
Here's the exact sequence Google showed on stage and posted to their blog:
- Step one: A baseline video of a violinist playing a song on stage.
- Step two: Prompt — "Transport the violinist to the image environment." Result: the player is moved to a new background, but face, posture, bow grip, and even wrist angle remain identical.
- Step three: Another prompt — "Change the camera angle to be over the violinist's shoulder." Result: new framing. Same violinist. Same identity. Same performance.
Three turns. One subject. Zero drift.
If you've spent any meaningful time with current AI video tools, this looks like cheating. It isn't. It's the first public proof that multi-turn refinement — the workflow filmmakers, advertisers, and educators have been waiting for — is technically real and shippable.
Why Multi-Turn Consistency Has Been AI Video's Open Wound
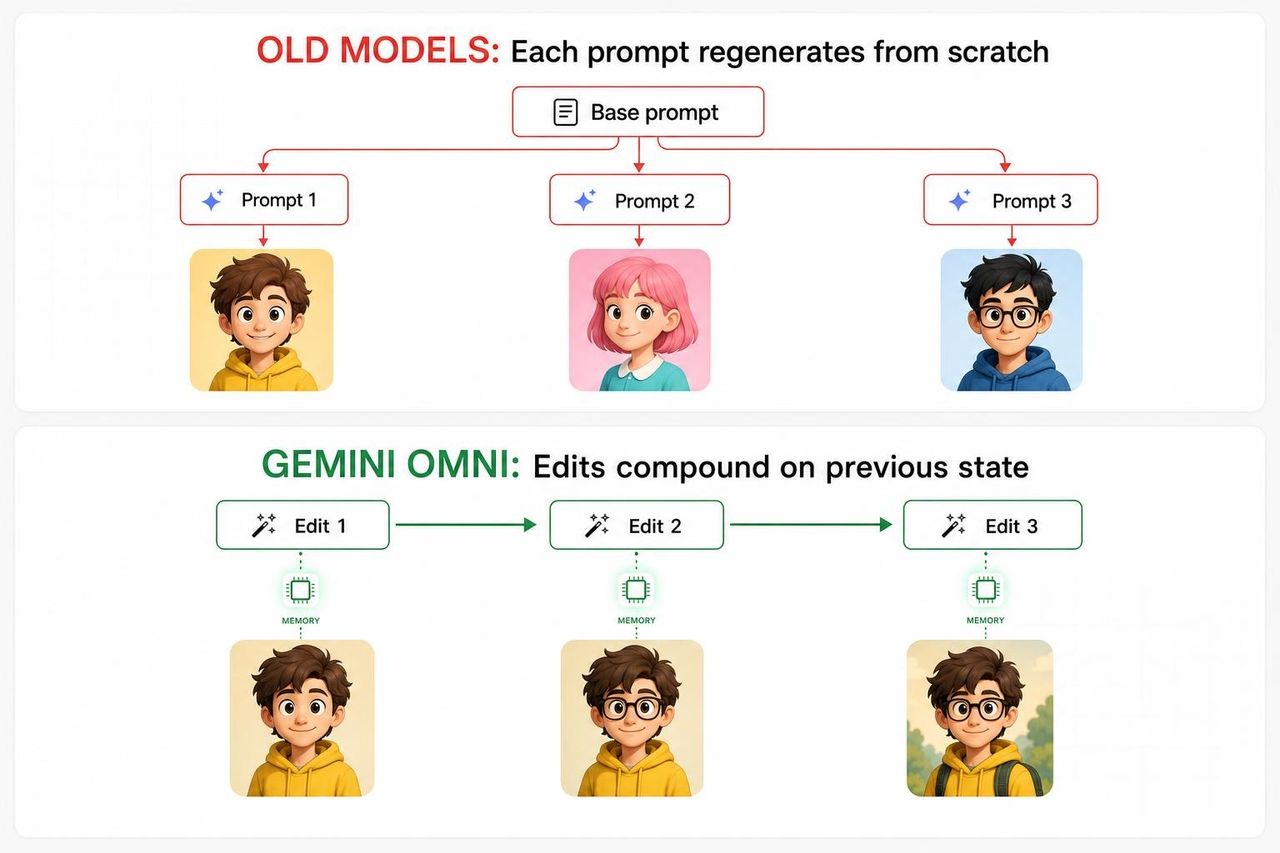
To understand why the violinist demo matters, you need to understand what every other AI video model has been failing at.
In traditional generative video pipelines, each new prompt essentially regenerates the scene from scratch — using the original prompt plus the new prompt as combined inputs. The model has no real internal continuity between turns. Faces drift. Background props vanish. Lighting changes. By turn three, the result has wandered so far from the original vision that creators give up and restart.
The root cause is architectural. Most video models were trained as one-shot generators, not multi-turn agents. They were optimized to produce a single best output from a prompt — not to remember what they produced last time and refine from there. Asking them to "edit" was effectively asking them to start over with extra context, and the math of that operation produced compounded drift, not compounded refinement.
Omni's approach is different. It's been built as a stateful editor — meaning each turn updates a persistent representation of the scene rather than regenerating it from scratch.
What "The Scene Remembers" Actually Means
The English tech press has been converging on the same realization, in their own words.
Decrypt described the breakthrough most plainly: "Google says Omni can keep the same characters, backgrounds, and movement consistent even after users make changes to a video — something many AI video models struggle with."
Android Central pulled out the key technical detail: "The company also says the model recalls previous commands during multi-step revisions, which could make iterative editing feel far less chaotic."
TechRadar framed it cinematically: "Characters stay recognizable. Scenes maintain continuity. Motion remains coherent instead of resetting every time a prompt changes."
And Phandroid compressed the entire capability into five words: "The scene remembers what came before."
That's the punchline. The scene remembers. That single property is the difference between AI video as toy and AI video as tool.
How Omni Stacks Up Against Sora, Veo, and Seedance on Consistency
Here's how the leading AI video models compare specifically on multi-turn consistency as of May 2026:
| Model | Multi-Turn Editing | Conversational Refinement | Character Consistency (Medium Review) | Current Status |
| Gemini Omni Flash | Stateful, multi-turn | Native chat-based | (3/5) | Live May 19, 2026 |
| Sora 2 (OpenAI) | One-shot regeneration | Limited | Discontinued | Sora App shut down; API sunset Sept 2026 |
| Veo 3.1 (Google) | Partial | Text + image only | Lower than Omni | Live, being deprecated by Omni |
| Seedance 2.0 (ByteDance) | Reference-based, not iterative | Limited | (4/5) | Live; ranked #1 on Artificial Analysis Video Arena |
The honest reading: Omni is the only model with truly stateful multi-turn editing. Seedance scores higher on raw character consistency (per the Medium reviewer) by leveraging up to 9 reference images per generation — but it can't carry that consistency across an editing session. Sora is exiting consumer. Veo is being absorbed.
From "Reroll" to "Refine" — What This Workflow Shift Unlocks

The real value here isn't the demo. It's the workflow transformation.
Blockchain.news framed the commercial implication best: "Batch editing enables simultaneous modifications across multiple video segments to accelerate production while maintaining quality standards in AI generated content. Film, advertising, and educational content creators gain significant advantages through reduced costs and improved narrative reliability."
That last phrase — narrative reliability — is the part that should matter to anyone working in content.
Until now, AI video could deliver one good clip. It couldn't deliver a campaign — a series of clips with the same protagonist, the same brand assets, the same visual language across multiple deliverables. Every edit was a coin flip. Now, edits compound.
TechTimes summarized the publicly demonstrated capability set as "editing actions and objects in user-shot footage, style transfer between realistic and animated looks, multi-turn refinement, and explainer-style generation."
And DataCamp's hands-on review confirmed the multi-turn behavior held up in practice: "Omni supports multi-turn editing, so you can refine details, environments, and camera angles step by step while keeping the scene consistent."
The workflow shift looks small on paper. In practice, it's enormous: generate → regenerate → regenerate → give up becomes generate → refine → refine → ship.
Builders are noticing. On the Chinese developer forum V2EX, one engineer who tested Omni on launch day wrote: "Generation speed and consistency exceeded my expectations."
When AI engineers and frontline creators land on the same observation within hours of launch, you're looking at an actual capability shift — not marketing.
The Honest Skepticism — Omni Isn't Perfect Yet
Before anyone declares the consistency problem solved, here's the cold-water take.
A reviewer at AI Analytics Diaries on Medium ran Omni against ByteDance's Seedance 2.0 and gave Omni's character consistency a 3 out of 5.
The line worth pinning to every AI video product manager's monitor: "Both models struggle with character consistency across multiple cuts — this remains AI video's open wound."
Translation: Omni is materially better than every other public model at multi-turn refinement within a single editing session. It isn't a solved problem across the broader category yet.
Where's the remaining gap?
- Single-scene multi-turn consistency works extremely well (the violinist demo)
- Cross-cut consistency (same character, different scenes, different lighting setups, different framing) is still imperfect
- Subtle features — fine facial details, hand articulation, specific clothing textures — can still drift across many edits
- The current 10-second clip limit on Omni Flash means multi-turn consistency hasn't been publicly stress-tested in long-form narrative work yet
For 80% of use cases — single-scene refinement, social-media-length content, marketing assets — Omni is already good enough to ship. For the remaining 20% — the cinematic-grade work where character continuity has to survive a 30-shot sequence — there's still an editorial cleanup pass required.
What This Actually Changes — Industry by Industry
If multi-turn consistency is now solved (or near-solved within a single session), here's what unlocks:
For brand advertisers: Campaign continuity. A fashion brand can finally generate ten variations of the same hero model across ten settings — without re-shooting, without finding new talent, without paying for ten manual touch-ups. The math on social-first creative production changes by an order of magnitude.
For educators and tutorial creators: Series consistency. A single AI-generated presenter can host an entire course — episode one through episode twelve — without the audience noticing they're synthetic. The "consistent face across content" problem killed AI educators for two years. It just got fixed.
For filmmakers: Previsualization at scale. Same actor across multiple scene proposals, multiple lighting setups, multiple camera angles — all generated in a single session, all refinable iteratively. The gap between "I have an idea" and "I can show the director" collapses from days to minutes.
For e-commerce teams: Product hero shots that match across listing variations. Same model, six outfits, lifestyle shots, studio shots, in-environment shots — all consistent, all shippable, all generated from the same multi-turn session.
For game developers: NPCs that look like the same NPC across cutscenes. The Achilles' heel of in-game AI cinematics has been that the protagonist subtly morphed between scenes. Omni's stateful editing makes character locking commercially feasible.
The Provenance Tension — Consistent Fakes Get Harder to Detect
There's a darker implication to this breakthrough worth naming directly.
Better multi-turn consistency means harder-to-detect fakes. The classic "tells" that something was AI-generated — a face morphing across cuts, hands changing shape, hair drifting in color — are exactly what consistency fixes. As Omni and its successors get better at internal continuity, the gap between "obviously synthetic" and "indistinguishable from real" closes fast.
This is precisely why every Omni-generated clip ships with Google's invisible SynthID watermark and C2PA Content Credentials baked in at generation time. Verifiable inside the Gemini app, Chrome, and Search. Not optional. Not a feature you can turn off.
It's also why Google deliberately held back speech and audio editing in existing videos: "We are still working to test this and better understand how we can bring this capability to users responsibly." Translation: the deepfake risk of a consistent face + a modified voice is too high to ship without safeguards in place.
For brands and creators, the calculus is shifting. As human-eye detection of "fake" content becomes unreliable, cryptographic provenance becomes the new standard for content authenticity. Every consistency win comes paired with a provenance obligation.
The New Bottleneck Isn't Quality. It's Model Sprawl.
Here's what this means strategically for anyone building products on top of AI video.
The capability gap between leading models is closing fast — and fragmenting fast at the same time. As of mid-2026:
- Gemini Omni leads on multi-turn consistency and conversational editing
- Seedance 2.0 leads on cinematic motion and stylized animation, with stronger reference-based character consistency
- Other specialists lead on long-form generation, fine-grained character control, audio sync, or low-cost batch processing
The model best at consistency this quarter probably isn't the model best at cinematic motion this quarter. The model with the strongest physics today isn't the one with the best audio sync six months from now. And every single one of them ships with its own SDK, auth flow, pricing tier, rate-limit quirks, and contract terms. Your team can easily burn an engineering sprint per integration — and another sprint per deprecation.
This is exactly the fragmentation problem Atlas Cloud was built to solve. We give developers a single unified endpoint to access 300+ models — every major foundation model, leading open-source releases, and the fast-moving specialists across image, video, audio, and reasoning. Gemini Omni access is coming to Atlas Cloud in the next few weeks, so the moment you're ready to swap your stack to test it, the integration is already done for you.
What that means in practice for your team:
- Switch models with a single line of code — no rewriting SDK integrations every time a new SOTA drops
- Run side-by-side evaluations on identical prompts — find out which model actually wins for your specific use case before committing budget
- Ship the strongest model for each capability — the multi-turn consistency leader today, the cinematic motion leader tomorrow, the cost-efficiency leader next quarter
- One dashboard for billing, observability, and rate limits — instead of twelve separate accounts to manage
For builders shipping AI video products in 2026, the smart architectural call isn't "bet on Omni." It's "build on an abstraction layer that lets you swap to whatever wins next." When Gemini Omni lands on Atlas Cloud, you'll be able to test it against Seedance, against the next breakthrough model, against whatever comes after that — without changing a single line of integration code.
In a market where consistency, physics, cinematic motion, and audio fidelity are each led by a different model, locking into any one of them is the worst possible technical debt to take on. Atlas Cloud is the abstraction layer that turns that fragmentation from a tax into a tailwind.
One Unified API for Production Video Generation
While Google rolls out Gemini Omni Flash inside the Gemini app and Google Flow for end-users, developers and product teams who want to embed the same multimodal video engine into their own workflows need a stable, predictable API layer.
Atlas Cloud serves Gemini Omni Flash through a unified, OpenAI-compatible API, alongside 300+ other image, video, and LLM models — so you can integrate Google's native multimodal model without juggling separate vendor accounts, billing portals, or SDKs.
Both Gemini Omni Flash variants are live on Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variant | Best For | Inputs | Resolution | Duration | Starting Price |
| Gemini Omni Flash Text-to-Video (Developer) | Pure prompt-driven cinematic generation | Text (up to 20,000 chars) | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
| Gemini Omni Flash Image-to-Video (Developer) | Subject-consistent video from real references | Text + up to 7 reference images | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
Quick Start — Generate a Gemini Omni Flash video in 5 lines:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
The API returns a prediction ID immediately — poll /api/v1/model/prediction/{id} for the rendered MP4 URL. Full schema, code samples in 7 languages, and a no-code Playground are available on the model pages linked above.
Core Insights
The reason multi-turn consistency matters isn't the demo. It's the unlock.
For five years, every conversation about "when will AI video go commercial?" hit the same wall: the moment models can keep a character consistent across edits. That wall just moved.
The violinist demo isn't a stunt. It's the first time a major lab has put a real, working multi-turn editing workflow on stage. The next time a marketing team asks an AI video tool to produce six clips of the same product hero across six scenarios, they should expect six usable outputs — not six unrelated faces.






