Google launched Gemini Omni at I/O 2026 — a multimodal model that edits video through plain-English conversation, not timelines or keyframes. The viral demos (bubble sculpture, liquid mirror, violinist) prove the real shift: it's not just text-to-video, it's text-to-edit-the-video-you-already-have. This is the iPhone-camera moment for video creation. Speech, audio editing, and a Pro tier are notably absent — and that's deliberate.
It's 1 AM. You're four hours into editing a 30-second clip. Your project file has 47 layers. You've dragged keyframes until your wrist hurts. The client just messaged: "can we try it with the lighting warmer?" And you, the professional, are about to start over.
That was the gig. That was the gig.
On May 19, 2026, Google quietly retired it.
At I/O 2026, the company announced Gemini Omni — a multimodal model that turns video editing into something most of us thought was still a decade away: a normal conversation.
The Core Promise: Stop Operating Video. Start Talking to It.
Here's the entire pitch in one sentence: you don't operate video anymore — you tell it what you want.
Google's announcement puts it without dressing: "Every instruction builds on the last. Your characters stay consistent, the physics hold up and the scene remembers what came before."
This isn't a Veo update. Google DeepMind's product page gives the cleaner framing: "Think of Gemini Omni like Nano Banana, but for video." Last year, Nano Banana made photo editing as easy as typing what you wanted. Now Omni does it for moving images.
The first model in the family — Gemini Omni Flash — is already live in the Gemini app, Google Flow, and YouTube Shorts.
And here's the line that should reframe how you think about this entire category: in TechCrunch's interview with the DeepMind team, research engineer Gabe Barth-Maron described what people are making with Omni as "personalized memes."
That's the thesis. Video creation just slid from craft to expression — the same migration photography made when iPhones killed the DSLR moat.
The Demos That Are Breaking Twitter
You can read marketing copy all day. What sold this launch were the demos. Three are everywhere right now:
- The bubble sculpture. Feed Omni a clip of a stone sculpture, type "Make the sculpture out of bubbles," and the next render keeps the same composition, the same lighting, the same shadows — but the sculpture is now translucent soap, catching ambient light.
- The liquid mirror. A hand touches a mirror; the prompt asks Omni to "make the mirror ripple beautifully like liquid, and the person's arm turns into reflective mirror material."As Windows Report documented, the ripples propagate physically outward and the arm's chrome reflects the actual room.
- The chained edits. Google's violinist demo shows a single subject across three rounds: stage → transported environment → over-the-shoulder camera angle. Three edits. One person. Face, posture, instrument grip — all consistent.

This isn't text-to-video. It's text-to-edit-the-video-you-already-have. The distinction looks small. It changes everything.
Why Creators Are Losing Their Minds
The reason this lands harder than other model launches is simple: Omni kills the worst loop in generative video.
Old loop: generate → hate it → rewrite the entire prompt → wait 90 seconds → still bad → repeat.
New loop: generate → "change the lighting to golden hour" → done → "now slow the camera push" → done.
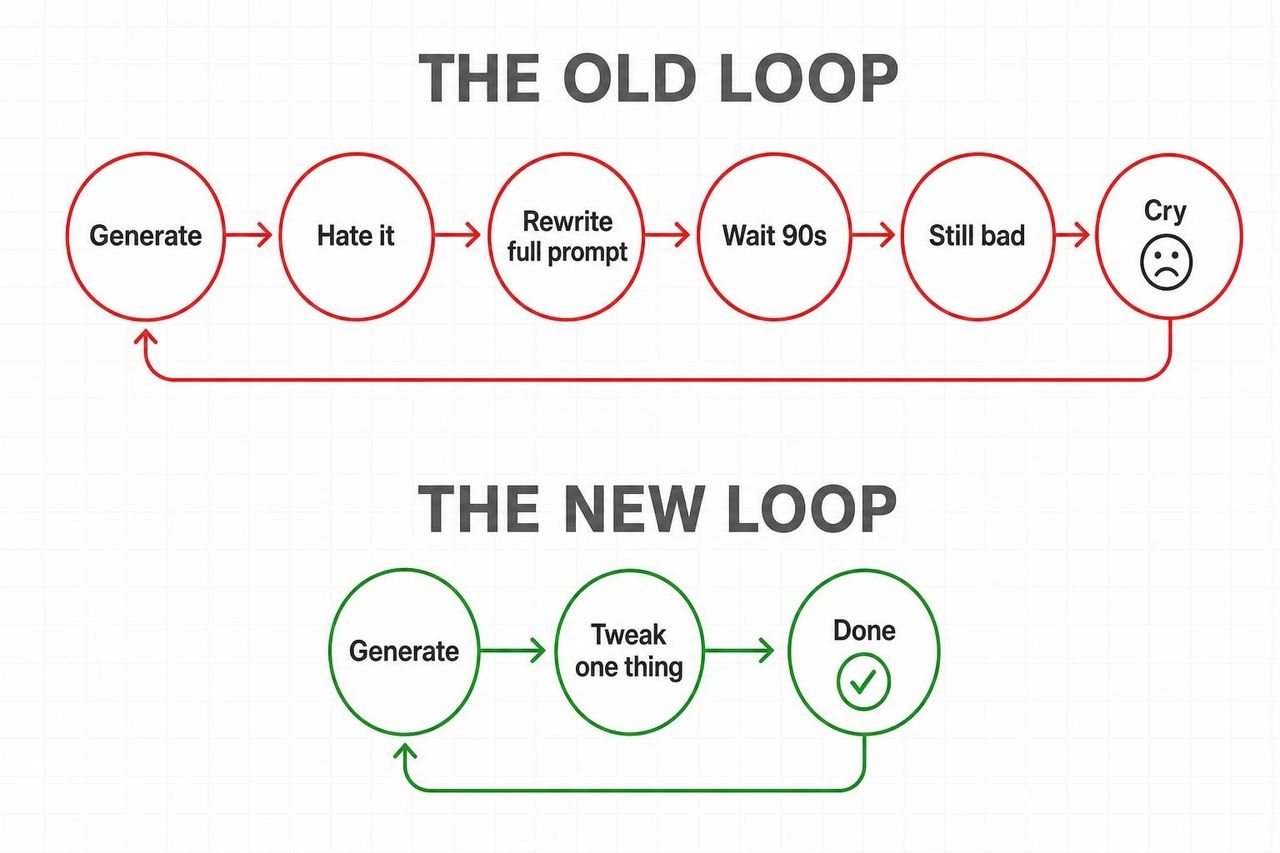
Android Central didn't soften the verdict: "Gemini Omni could make traditional video editing apps feel ancient." TechRadar made the same point with more nuance, noting that motion now stays coherent across edits instead of resetting every prompt.
Builders are already moving. On developer board V2EX, one Chinese dev tested it the day of launch and posted: "chat-based modification of objects inside a video — this kind of interaction is clearly the future direction. Speed and consistency exceeded my expectations." On X, immunologist and AI commentator Dr. Derya Unutmaz tweeted within minutes of the keynote: "Wow! Google DeepMind just dropped an amazing new AI multimodal called Gemini Omni. The videos look super good! Must try ASAP!"
When the AI Twitter intelligentsia and Chinese dev forums hit the same note within hours, you're looking at a real inflection.
Where Google Is Quietly Holding Back
It would be irresponsible to write a love letter without the asterisks.

Engadget flagged the elephant in the room: "the main problem with Veo 3.1 and other video generator apps is that the video has an 'uncanny valley' look, and is often hated by end users. It'll be interesting to see if the output quality matches Google's breathless claims."
And DataCamp's hands-on testing already surfaced a real physics bug — a trebuchet that launched its payload backwards. The reviewer noted the model also still lacks published benchmark scores, so independent verification is weeks away.
There's also a deliberate omission: speech and audio editing inside existing videos. As Google itself acknowledged, the company is "still working to test this and better understand how we can bring this capability to users responsibly." Translation: the deepfake risk is real and they're holding the most dangerous capability behind the curtain.
Every Omni clip ships with Google's invisible SynthID watermark plus C2PA Content Credentials — provenance verifiable inside the Gemini app, Chrome, and Search. That's not optional. That's table stakes now.
What This Actually Means For Your Workflow
Strip the hype and you're left with something genuinely new:
- The tool is the conversation. No timeline, no layers, no keyframes. Just words.
- The feedback loop collapses. What used to be 90-second regenerations becomes 10-second tweaks.
- The professional moat shrinks. When anyone with taste can iterate on video as fast as they iterate on a Slack message, the bottleneck moves from execution to ideas.
For marketing teams, indie creators, educators, anyone who's ever needed "just a quick 10-second clip" — this is the inflection point. Not because the model is perfect. Because the interaction pattern is finally right.
Future video editing won't need software. It'll need vocabulary.
One Unified API for Production Video Generation
While Google rolls out Gemini Omni Flash inside the Gemini app and Google Flow for end-users, developers and product teams who want to embed the same multimodal video engine into their own workflows need a stable, predictable API layer.
Atlas Cloud serves Gemini Omni Flash through a unified, OpenAI-compatible API, alongside 300+ other image, video, and LLM models — so you can integrate Google's native multimodal model without juggling separate vendor accounts, billing portals, or SDKs.
Both Gemini Omni Flash variants are live on Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variant | Best For | Inputs | Resolution | Duration | Starting Price |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | Pure prompt-driven cinematic generation | Text (up to 20,000 chars) | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
| Gemini Omni Flash Image-to-Video (Developer) | Subject-consistent video from real references | Text + up to 7 reference images | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
Quick Start — Generate a Gemini Omni Flash video in 5 lines:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
The API returns a prediction ID immediately — poll /api/v1/model/prediction/{id} for the rendered MP4 URL. Full schema, code samples in 7 languages, and a no-code Playground are available on the model pages linked above.
One Last Thing — For Anyone Actually Building With This Stuff
Here's the awkward reality behind every model launch like this one: by next quarter, three more "best video model in the world" announcements will land. Each one will have a different SDK, a different auth flow, a different rate-limit dance, a different pricing model. Your team will lose a week onboarding each one. Then a week deprecating the last.
That's the exact problem Atlas Cloud solves.
We give developers one endpoint with access to 300+ models — every major foundation model, the leading open-source releases, and the fast-moving specialists across image, video, and reasoning. Switch models with a single line of code. Run side-by-side benchmarks without re-integrating SDKs. Ship the model that's hot today, swap to whatever's hot next month — without rewriting anything.
Because the only thing certain about AI right now is that the leaderboard changes every Tuesday. Build for that.






