In early April, a model named "HappyHorse-1.0" suddenly appeared. It topped four categories on the Artificial Analysis video leaderboard, soundly beating ByteDance's Seedance 2.0 and Kling by a wide margin.
There were no press releases, no blog posts, and the company name was obscured. The model page simply read "coming soon."
On April 10, Alibaba's ATH division acknowledged the project. HappyHorse is an internal R&D project from ATH's innovation unit and is currently in private beta. The API will be released on April 30.
Furthermore, HappyHorse-1.0 is set to be fully open-source. It is touted as the first open-source video model to natively generate audio and video simultaneously.
This "quiet launch" followed by a "spectacular announcement" is becoming a trend among Chinese AI companies. Xiaomi did this with a codename "Hunter Alpha," and Zhipu used "Pony Alpha" for their new GLM model.
In this article, we unravel the known facts about HappyHorse and what it means.
HappyHorse's Position on the Leaderboard
Artificial Analysis operates four leaderboards: Text-to-Video without audio, Image-to-Video without audio, Text-to-Video with audio, and Image-to-Video with audio.
Data as of noon on April 13 is as follows:
- Text-to-Video (no audio): 1384 Elo. It is 111 points ahead of Seedance 2.0.
- Image-to-Video (no audio): 1413 Elo. This is the highest score recorded on the platform.
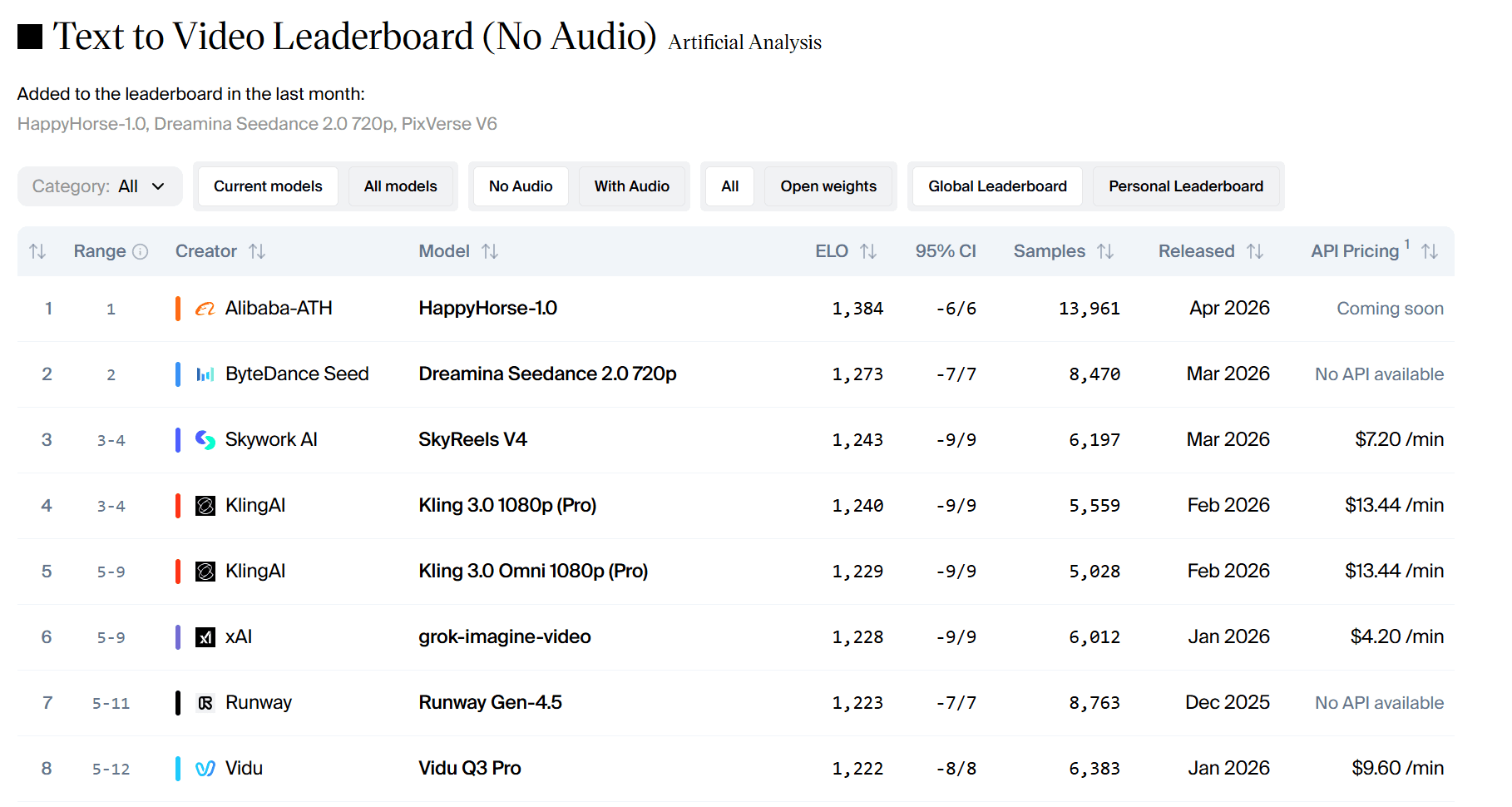
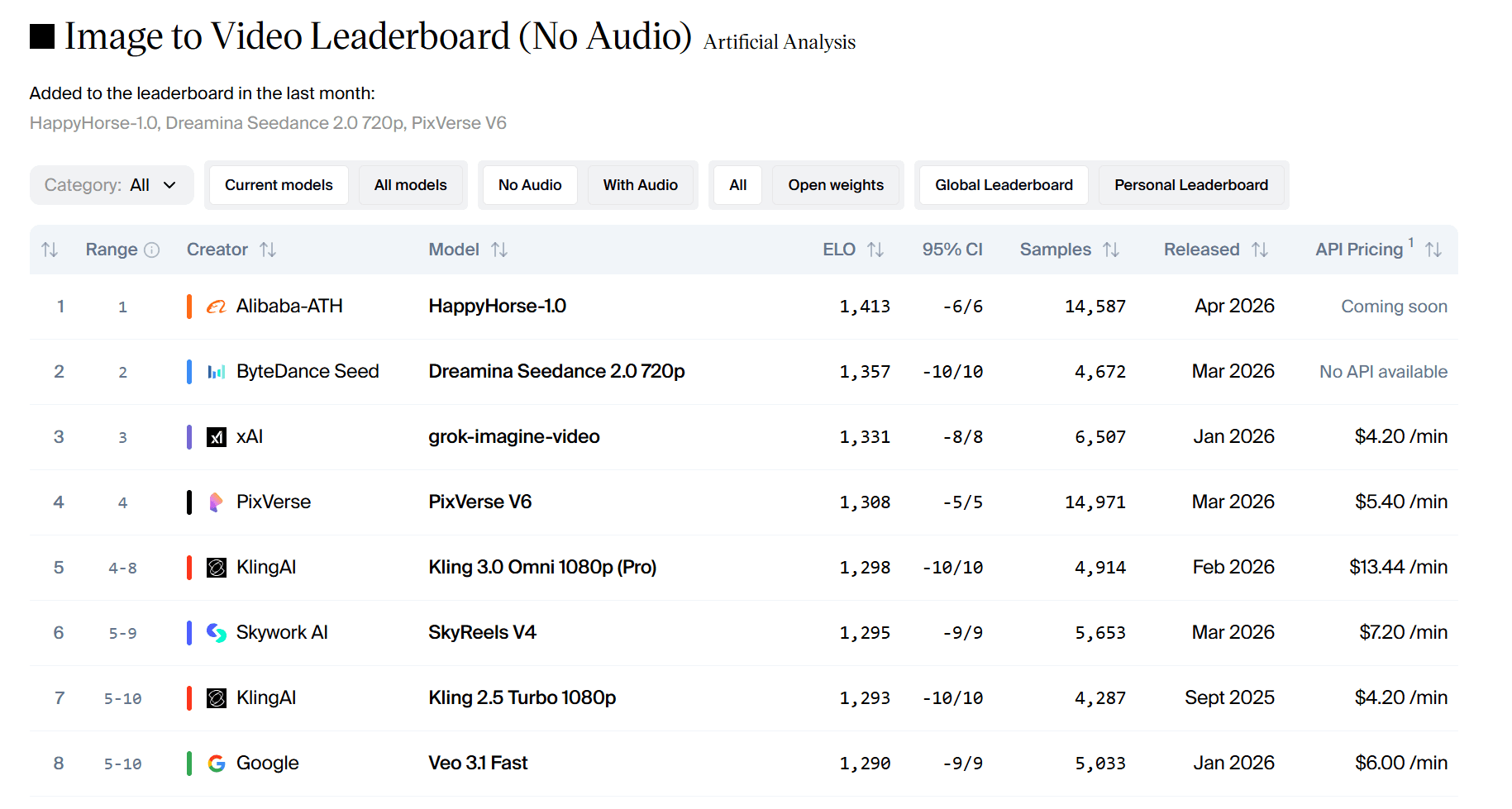
In Elo scores, a difference of more than 60 points indicates a clear preference. A 111-point difference indicates that users overwhelmingly chose HappyHorse in blind tests.
However, the situation changes when audio is included. The difference shrinks to a mere 1–2 points, effectively a draw. This shows that HappyHorse's audiovisual synchronization and sound quality are not dramatically superior. In this regard, it is roughly on par with Seedance.
Comparison between HappyHorse and Seedance 2.0
| Item | HappyHorse-1.0 | Seedance 2.0 |
|---|---|---|
| Model Nature | Open Source | Closed Commercial System |
| Architecture | Unified Transformer | Bidirectional Diffusion Transformer (DB-DiT) |
| Multimodal Capability | Simultaneous Audio/Video Generation (One-pass) | Multimodal Input (Text, Image, Video, Audio) |
| Video Generation Mode | One-pass Generation | Pipeline-based Generation |
| Video Generation Length | Approx. 5–10 seconds (1080p) | Up to approx. 60 seconds (2K) |
The two represent different philosophies.
HappyHorse‑1.0: Open source. Unified Transformer. Simultaneous audio/video generation. One-pass processing. Native lip-sync support for 7 languages. 15 billion parameters. It takes 38 seconds to generate a 5-second 1080p video in an H100 environment.
Seedance 2.0: Closed commercial system. Bidirectional Diffusion Transformer (DB‑DiT). Multimodal input. Capable of generating 60-second 2K videos. Supports lip-sync for 8+ languages.
Regarding pure visual quality, HappyHorse is clearly preferred in blind tests. Regarding audiovisual synchronization and sound quality, both are roughly equal. Regarding usability, Seedance already provides a mature API through services like Volcano Engine. The HappyHorse API is scheduled for release on April 30, and performance in private beta is still being verified.
Comparison of generation examples between HappyHorse-1.0 and Dreamina Seedance 2.0 (Text-to-Video with audio) by Artificial Analysis:
Prompt: A Pixar-style short animation about a timid little traffic cone that dreams of being the pylon at the finish line of a big race. The other cones laugh at its ambition. A construction worker accidentally sets it up at the finish line of a marathon. As the runners pass by, the cone's painted expression changes from fear to joy. Confetti rains down overhead. The other cones watch it on TV and are inspired. Audio: From traffic noise to crowd cheers, and then uplifting music.
About the Architecture
HappyHorse takes an unusual approach.
It has 15 billion parameters and uses a 40-layer unified self-attention Transformer. Text, video, and audio tokens are all fed into the same sequence and modeled jointly. This is significantly different from the common pipeline of "generating the video first and then adding audio." Here, sound and scene exist in the same semantic space from the start.
This model uses DMD-2 distillation and full graph optimization via MagiCompiler. On a single H100 GPU, it takes about 38 seconds to generate a 5-second 1080p video.
It supports native lip-sync for 7 languages: English, Mandarin, Cantonese, Japanese, Korean, German, and French. Its Word Error Rate (WER) is among the lowest of any open-source model.
Participants in the Artificial Analysis blind test state that HappyHorse excels particularly in character depiction. The skin texture and smoothness of movement are superior. The fact that over 60% of test samples were portraits or talking-head clips was a factor that propelled this model to the top.
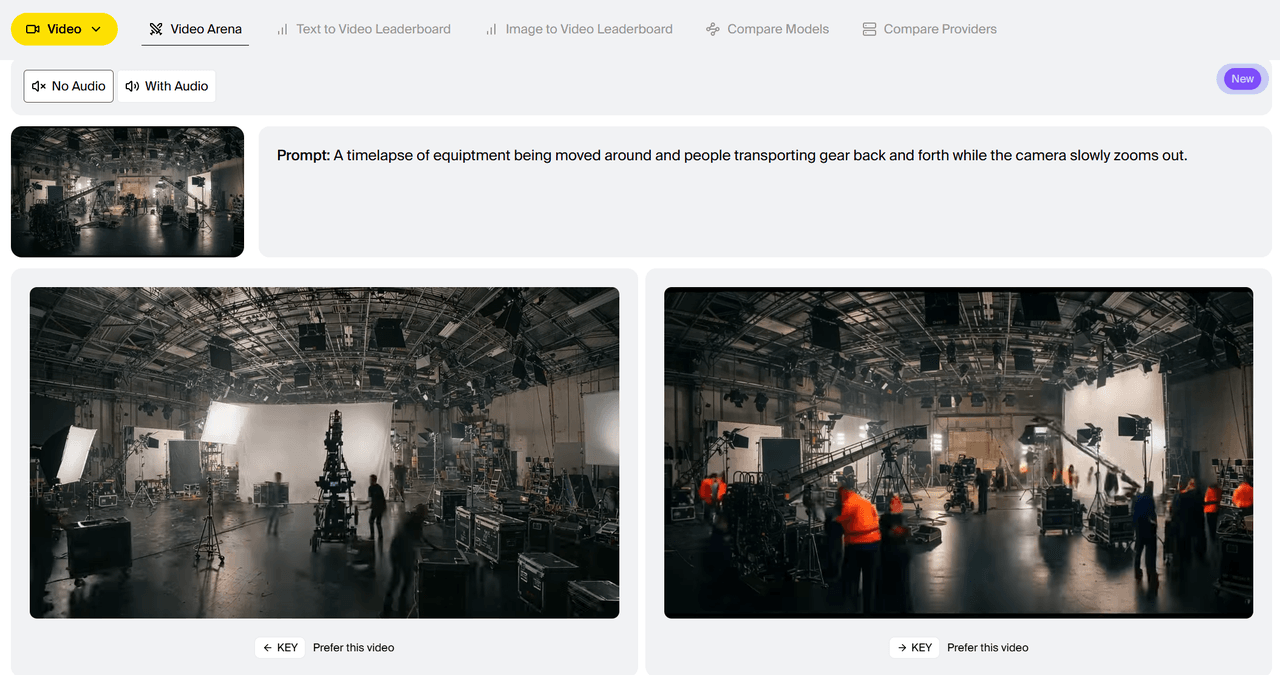
However, there are criticisms. Leaked videos have pointed out unnatural ripples, stripe artifacts in fast-moving subjects, and image quality degradation on large screens.
Open Source and Access Plan
On April 9, HappyHorse‑1.0 announced it would be fully open-sourced. The GitHub repository is live, the weights are completely open, and there are no commercial restrictions.
The official website provides online demos for text-to-video and image-to-video. According to Alibaba ATH, the API is scheduled to be released to the public on April 30.
However, a word of caution: according to the official team, most of the "official websites" circulating online are fake. The real one is not yet fully operational.
Market Impact and Significance
HappyHorse appeared two weeks after OpenAI halted development of Sora. Its movement was seen as a sign of stagnation in the AI video field, but a Chinese model has picked up the baton.
The market reacted quickly. Alibaba's stock price surged more than 7% after the confirmation and continued to rise. At the close of trading on April 10, it was up over 3% to HK$126.6.
At a strategic level, HappyHorse shows that ATH possesses a second team capable of building top-tier multimodal models. This team has a business background and understands user needs and commercial scenarios. This created a dual-engine structure: Tongyi Lab (focused on basic research) and the Innovation Unit (building applications from real business challenges).
Let's look at the timeline. Lin Junyang resigned in early March, and ATH was established on March 16. On April 2, Qwen 3.6 Plus took first place in OpenRouter's global call volume, and on April 8, HappyHorse topped the Artificial Analysis list. In just one month, Alibaba produced powerful results in both language and video models.
Team Background: Zhang Di and Alibaba ATH
Behind HappyHorse is the heavyweight Zhang Di.
He was originally a Vice President at Kuaishou and served as the technical leader for Kling AI. He is known as the "father of Kling." He left Kuaishou in November 2025 and took over as head of Alibaba's "Future Life Lab," reporting directly to Chief Scientist Zheng Bo.
Five months later, his team built HappyHorse‑1.0 and beat Kling and ByteDance's Seedance 2.0.
This team was initially part of Taobao's Future Life Lab, but was moved to the AI Innovation Unit of the ATH business group following Alibaba's latest reorganization.
ATH stands for "Alibaba Token Hub," established by CEO Wu Yongming on March 16, who leads it personally. Its mission is "creation, provision, and application of tokens," and it integrates Tongyi Lab, the MaaS business line, the Qianwen department, the Wukong department, and the AI Innovation Unit.
FAQ
What kind of GPU is required to run HappyHorse locally?
This model has 15 billion parameters and is by no means small. In a single H100 environment, it takes about 38 seconds to generate a 5-second 1080p video. Consumer GPUs like the RTX 4090 (24GB VRAM) will require quantization or offloading. It is likely to exceed 24GB for FP16 inference. Some users have reported success with 4-bit quantization, but quality is reduced. For serious use, a cloud GPU with 40GB+ VRAM is recommended. Alternatively, it is wise to wait for the API release on April 30.
Can I fine-tune HappyHorse with my own data?
Yes, under the license. There are no commercial usage restrictions. However, fine-tuning a 15-billion-parameter video model is not easy. It requires an H100 or A100 cluster, a large dataset of video-audio pairs, and significant engineering resources. The GitHub repository does not currently contain fine-tuning scripts and only supports inference. The team has hinted at releasing training code in the future, but no date has been set.
Are there Discord or WeChat community groups?
There are, but they are unofficial. Several AI communities have started threads on Discord and WeChat. The official team has not yet opened formal community channels. If you join a group, beware of fake links and phishing scams. It is best to check the GitHub repository and official announcements from Alibaba ATH for the latest information.
Is this model available on Hugging Face?
Not as of this writing. The team has stated they are working on a release on Hugging Face, but it is not yet complete. Currently, the weights are only on GitHub. Community members have started uploading converted checkpoints to Hugging Face, but these are unofficial. To be safe, please use the GitHub source until the official Hugging Face page appears.






