MiniMax M3 is out, and here's the short version: use it if you need an open-weight model that takes image and video natively, holds a million tokens of context cheaply, and runs long coding-and-agent loops without resetting. That's the adoption case and if you have agents to run autonomously while you sleep, we recommend you test it! M3 is live on Atlas Cloud now.
If you don't have long-running agents, M3 is still worth knowing for the direction MiniMax took to get there. They kept 1M context affordable with a sparse-attention architecture (MiniMax Sparse Attention, or MSA) that cuts per-token compute to roughly 1/20 of the previous generation at full context — and they did it by choosing the cheapest path that runs on today's serving stack, not the most exotic one. We expect that to be the default direction for every major provider: cheap long context through sparse or compressed attention. That turns a 1M window from a differentiator into table stakes, and pushes the real competition up a layer — to how well you route across models, not which single one you bet on.
MiniMax announced M3 on June 1, 2026. The API is available now, and the company says it will publish the technical report and weights within about 10 days of the announcement.
If you are using another frontier model today
M3 is worth testing when the job needs a larger working set, visual context, or a longer agent loop than your current default handles well. The column that matters is the last one: what M3 actually adds over the specific model you already run.
| If you use this today | For this job | What M3 actually adds |
|---|---|---|
| GPT-5.5 or GPT-5.5 Pro | Agentic coding, computer use, research, data analysis, and knowledge-work automation | Native video input and an announced open-weight path — a second agent route with a different cost curve that you can self-host later. (GPT-5.5 already has image vision, so test video and economics, not image support.) |
| Claude Opus 4.8 | Long-running coding agents, retrieval-heavy knowledge work, and tool use | A lower-cost, open-weight alternative to A/B on full-repo coding and cost per completed task. Opus 4.8 already offers a 1M context window and vision, so the real test is price, video input, and task economics — not window size. |
| Qwen3.7-Plus (multimodal) | Vision and GUI agents, screenshot-to-code, browser and desktop automation | Comparable multimodality with stronger coding/agentic positioning and an open-weight path. (Qwen3.7-Plus is proprietary, API-only.) |
| Qwen3.7-Max (text-only flagship) | Text reasoning, long-horizon agents, office automation | Native image and video input in the same context. Qwen3.7-Max is text-only — for vision you would otherwise switch to Plus. |
| DeepSeek-V4-Pro or DeepSeek-V4-Flash | Cost-sensitive reasoning, coding, tool calls, and long-context API workloads | Native multimodality (image and video) on top of long context. DeepSeek-V4 is text-only, so M3 is the multimodal alternative when a workload carries a visual signal. |
The practical test is simple. Try M3 if you are trying to:
- keep the repo, task history, logs, and current plan in one working context
- let an agent continue after dozens of tool calls instead of resetting the conversation
- reason across code, text, screenshots, charts, PDFs, and video frames in one pass
- reduce handoffs between a text model, a vision model, and a separate retrieval layer
- compare long-context cost per completed task, not just price per million tokens
Do not switch because a launch chart looks good. Switch when M3 completes a task your current routing stack drops, truncates, overpays for, or splits across too many models.
Where M3 helps
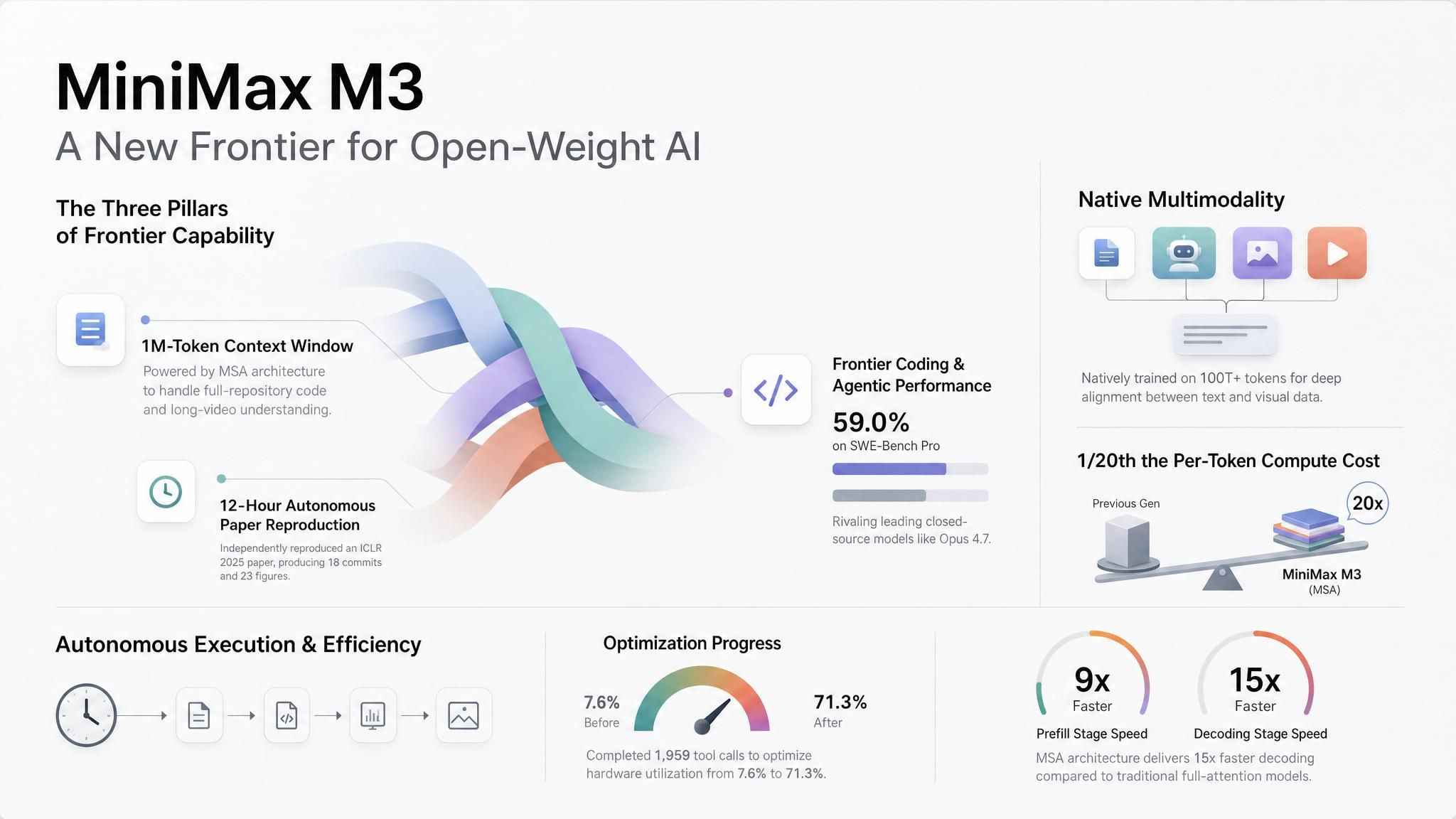
Agents with room to work. MiniMax's launch examples push past the usual chat-demo pattern. In one test, M3 reproduced the core experiments from an ICLR 2025 Outstanding Paper after running for almost 12 hours. It produced 18 commits and 23 experimental figures. In another, it worked for about 24 hours on an FP8 GEMM CUDA kernel, made 147 benchmark submissions and 1,959 tool calls, and moved hardware utilization from 7.6% to 71.3%.
Do not read those examples as proof that a day-long agent will work on your first prompt. They do show why M3 belongs on the shortlist for workflows where the model needs to plan, run tools, inspect results, revise, and continue after an early attempt fails.
Repository-scale and document-scale context. M3 supports up to 1M tokens through the API, with MiniMax describing 512K as the guaranteed minimum. At a 1M-token context length, MiniMax reports per-token compute at 1/20 of the previous generation, with more than 9x faster prefill and more than 15x faster decoding.
That changes product design. A coding agent can see more of the repo. A research assistant can carry a longer evidence trail. A contract-review tool can keep the source material and the analysis in the same working set. Retrieval still has a place, but the model no longer has to start from a tiny slice of the problem.
Visual context in the same request. MiniMax trained M3 with multimodal data from the start. The model accepts image and video input, and MiniMax says it can handle interleaved text, images, and video in one context.
That reduces handoffs between models. A support workflow can read the user's message and inspect the screenshot. A research workflow can reason over charts inside a paper. A computer-use agent can look at the screen and decide the next action without shipping the visual step to a separate model first.
Hosted access now, weights soon. MiniMax is treating M3 as an open-weight release, but the first launch path is hosted API access. That gives teams a useful sequence: test the hosted model now, then decide whether the later weight release fits private deployment, fine-tuning, or internal evaluation.
A clear pricing boundary. MiniMax says API calls at or below 512K input tokens use the standard rate. Higher long-context pricing starts above 512K, where teams are usually running full-repo, full-document, or long-video workloads. M3 also supports a thinking toggle at the same price, so teams can use reasoning mode for harder agent work and a faster mode for latency-sensitive completion.
What the operating cost looks like
MiniMax M3 on Atlas Cloud is priced at $0.30/M input tokens and $1.20/M output tokens. Claude Opus 4.7 is $5/M input and $25/M output, while GPT-5.5 is $5/M input and $30/M output.
That makes M3:
- 94% cheaper on input than both Opus 4.7 and GPT-5.5
- 95.2% cheaper on output than Opus 4.7
- 96% cheaper on output than GPT-5.5
Token price only matters after you map it to the shape of the workload. A coding agent with a large repo in context spends most of its money on input. A research or drafting workflow with long explanations spends more on output. A multimodal GUI agent also pays for visual context, and the token conversion depends on the provider.
Use the table below as a rate-card translation, not a benchmark. It assumes USD pricing, no cache hits, no batch discounts, no regional premiums, no tool-call fees, and no retries. For GPT-5.5, OpenAI says prompts above 272K input tokens are priced at 2x input and 1.5x output for the full session, so the long-context example uses that higher effective rate.
| Model | Rate used | 100K input + 5K output | 500K input + 20K output | Cost read |
|---|---|---|---|---|
| MiniMax M3 on Atlas Cloud | $0.30 / $1.20 | $0.04 | $0.17 | Low-cost multimodal route. More expensive than DeepSeek Flash, but far below closed frontier pricing. |
| DeepSeek V4 Flash | $0.14 / $0.28 | $0.02 | $0.08 | Cheapest named route for text-only high-volume work. Use it when visual input is not part of the task. |
| DeepSeek V4 Pro | $0.435 / $0.87 | $0.05 | $0.23 | Close to M3 on pure token cost, but text-only. Better comparison for reasoning and coding without visual context. |
| Qwen3.7-Plus | $0.40 / $1.60 up to 256K; $1.20 / $4.80 above 256K | $0.05 | $0.70 | Competitive for shorter multimodal calls. Long-context pricing changes the economics above 256K. |
| Qwen3.7-Max | $2.50 / $7.50 | $0.29 | $1.40 | Cheaper than GPT and Claude, but not a bulk default unless it wins the task. |
| Claude Opus 4.8 | $5 / $25 | $0.63 | $3.00 | Premium route for high-stakes coding, tool use, and long-context reliability. |
| GPT-5.5 | $5 / $30 standard; $10 / $45 above 272K input | $0.65 | $5.90 | Use when the model's tool use, computer-use behavior, or token efficiency repays the premium. |
| GPT-5.5 Pro | $30 / $180 | $3.90 | $18.60 | Reserve for the hardest work. The rate puts it in a different budget class. |
The cost read: M3 is not the cheapest text model in the list. DeepSeek V4 Flash still wins if the workload is text-only, high-volume, and tolerant of the Flash capability tier. M3's cost argument is different: it puts native image and video input, long working context, and agentic coding into a price band that sits near DeepSeek V4 Pro and far below GPT-5.5, GPT-5.5 Pro, and Claude Opus 4.8.
For a 500K-input, 20K-output agent turn, M3 is roughly 17x cheaper than Claude Opus 4.8 and about 34x cheaper than GPT-5.5 once OpenAI's long-context multiplier applies. It is about 4x cheaper than Qwen3.7-Plus at that request size and about 8x cheaper than Qwen3.7-Max. Against DeepSeek, the answer depends on modality: DeepSeek V4 Flash is still cheaper, while V4 Pro lands in the same broad range. If the task has screenshots, charts, UI state, or video frames, M3 can avoid the extra routing step to a separate vision model.
At monthly scale, the spread is clearer. A workload with 10M input tokens and 1M output tokens costs about $4.20 on M3, $1.68 on DeepSeek V4 Flash, $5.22 on DeepSeek V4 Pro, $75 on Claude Opus 4.8, $80 on GPT-5.5 at standard rates, and $480 on GPT-5.5 Pro. Qwen3.7-Plus sits between $5.60 and $16.80 depending on whether each request stays below or above its 256K pricing boundary; Qwen3.7-Max lands around $32.50.
Our recommendation: Treat the expensive models as routes that need to earn their place. If GPT-5.5 or Opus 4.8 finishes a hard task in one run while M3 needs three retries and a human patch, the cheap call was not cheap. If the task is long-context multimodal analysis, repo-scale coding triage, support-ticket automation with screenshots, or document work where M3 clears the quality bar, its economics make it a serious routing candidate rather than a launch-week curiosity.
Read the benchmarks as vendor data
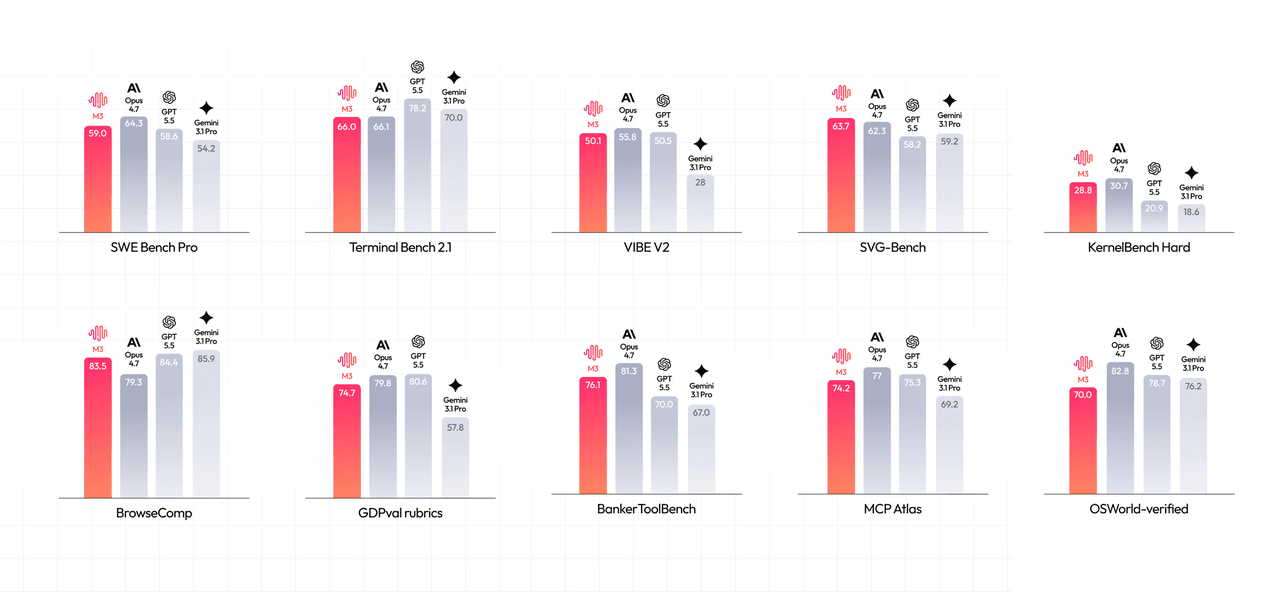
MiniMax reports strong scores across coding and agentic tasks:
- SWE-Bench Pro: 59.0%
- Terminal-Bench 2.1: 66.0%
- SWE-fficiency: 34.8%
- KernelBench Hard: 28.8%
- MCP-Atlas (a third-party MCP tool-use benchmark — unrelated to Atlas Cloud): 74.2%
- BrowseComp: 83.5, compared with 79.3 for Claude Opus 4.7 in MiniMax's comparison
One note on that last line: MiniMax benchmarks M3 against Opus 4.7, but Opus 4.8 shipped on May 28, four days before M3 launched. The launch comparison was already a version behind on day one — a small detail, but a preview of the larger point below.
On PostTrainBench, which asks a model to synthesize data, train, evaluate, and iterate on four base models inside a 12-hour window, MiniMax reports M3 at 0.37 in the release post, equivalent to the 37.1 score shown on its model page. That ranks behind Opus 4.7 at 0.42 and GPT-5.5 at 0.39, but ahead of the rest of the reported field.
Those scores are useful for triage. They are not enough for a production decision. MiniMax ran many of the tests on its own infrastructure, and several evaluations used specific scaffolding. Before a team uses a score in a sales deck or architecture decision, it should rerun the task against its own code, documents, prompts, latency targets, and budget.
How to evaluate M3 against current frontier models
Use M3 as an eval candidate, not a default. A 1M-token window can hide bad architecture if you fill it with irrelevant files, stale logs, or every message the user has ever sent.
Run the same test set against GPT-5.5, Claude Opus 4.8, Qwen3.7-Plus or Max, DeepSeek-V4-Pro or Flash, and M3. Then compare results by task, not by provider reputation.
Start with six tests:
- Full-repo coding: Give each model the same issue, repo slice, tool access, and timeout. Score patch quality, test pass rate, diff size, and unnecessary edits.
- Long-context retrieval: Put relevant details in the beginning, middle, and end of the context. Add similar distractors. Check whether each model retrieves the right instance, not just any matching phrase.
- Tool-loop endurance: Run a task that needs 30, 60, and 100+ tool calls. Watch whether each model keeps a stable plan, repeats itself, loses earlier constraints, or stops before the task is done.
- Visual-agent work: Give each multimodal model a support ticket plus screenshots, a paper plus charts, or a product spec plus UI captures. For text-only or weaker-vision routes, measure the extra handoff cost to a separate vision model.
- Latency under real context: Compare time to first token and total completion time at 128K, 512K, and 1M input tokens. Do not accept a 1M-window claim without latency data.
- Cost per completed task: Measure input tokens, output tokens, retries, tool calls, cache hits, latency, and human correction. A cheaper model call can still cost more if it needs three retries.
This is where most teams get the model question wrong. They ask which model has the best launch benchmark. The production question is narrower: which model completes this workflow at the quality, latency, and cost your product can tolerate?
How MSA keeps long context usable
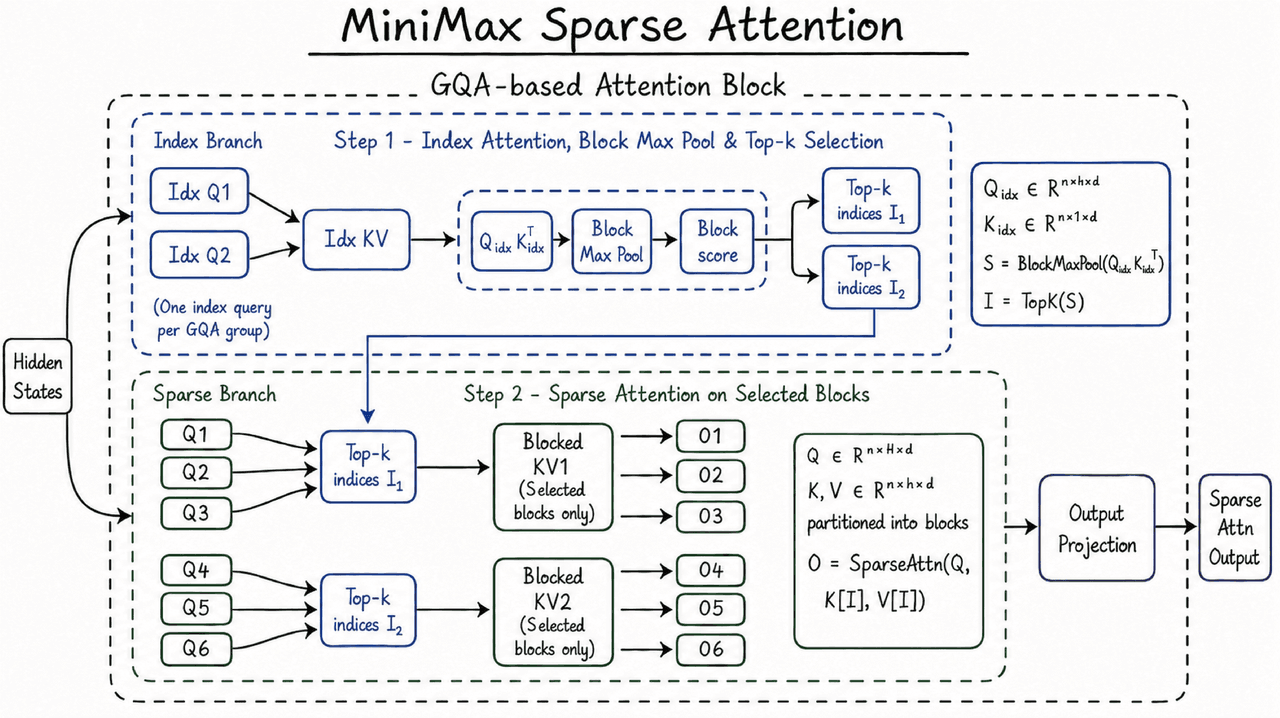
M3's context window depends on MiniMax Sparse Attention, or MSA.
Full attention lets each token attend to each other token. As the sequence gets longer, the work grows with sequence length squared. Sparse attention adds a selection step, then runs attention over the parts of the prior context that matter most.
MiniMax says MSA partitions the KV cache into blocks and selects at the block level. The KV cache stores the key and value vectors from earlier tokens, and it drives a large share of memory traffic in long-context inference. MiniMax also describes an operator design called "KV outer gather Q": KV blocks become the outer loop, queries that hit a block get gathered to it, each block gets read once, and memory access stays contiguous.
In MiniMax's release post, that design runs more than 4x faster than open-source Flash-Sparse-Attention and flash-moba under M3's head configuration. MiniMax also says MSA matched full attention on the large majority of ablations.
The engineering claim matters because a 1M-token window has no value if teams cannot afford to use it. MSA is the reason MiniMax can argue that long context is part of M3's normal operating model, not a one-off demo mode. It is also not unique: DeepSeek's V4 ships a hybrid of Compressed Sparse Attention and Heavily Compressed Attention for the same reason. Cheap long context is becoming an architectural default.
The larger trend: model launches are becoming routing events
M3 is not an isolated release. It fits a pattern that has been building across the market.
The clearest trend is the calendar. In roughly six weeks, four 1M-context models shipped:
- DeepSeek V4-Pro and V4-Flash — April 24, open-weight, 1M context, thinking/non-thinking modes
- Qwen3.7-Max — May 20, text-only reasoning flagship, 1M context (the multimodal Qwen3.7-Plus followed in early June)
- Claude Opus 4.8 — May 28, with a 1M context window for the Opus family
- MiniMax M3 — June 1, 1M context plus native multimodality and an open-weight path
A million-token window has gone from differentiator to table stakes in a single quarter. The same is happening to sparse attention, thinking toggles, agent benchmarks, and tiered long-context pricing. Expect model pages to keep converging on the same headline features.
The pace also outruns the marketing. MiniMax's own M3 launch benchmarks against Opus 4.7, but Opus 4.8 shipped four days earlier. The model you benchmarked against last week is not the model your competitor is running this week. That is the routing-events world in one example.
That does not make M3 irrelevant, but it changes what builders should optimize for.
The model advantage will decay faster than the integration work around it. If a team hard-codes one provider into its agent stack, every major release becomes a migration project. If a team routes by task, price, latency, modality, and eval result, every major release becomes a routing update.
The winner is not the team that picks one model and defends it for a year. The winner is the team that can test M3 today, compare it against GPT-5.5, Claude Opus 4.8, Qwen3.7, and DeepSeek-V4 tomorrow, and move traffic when the numbers say to move.
What other providers can copy, and what they cannot
Providers can copy the surface area first:
- longer context windows
- sparse-attention variants
- thinking on/off modes
- coding-agent benchmark pages
- multimodal launch demos
- open-weight or open-weight-adjacent messaging
The harder parts take longer:
- stable long-context serving under real concurrency
- quality deep in context, especially with distractors
- agent reliability after many tool calls
- multimodal alignment across text, images, charts, and video
- pricing that holds when customers use the whole window
- clear model IDs, versioning, and fallbacks that production teams can trust
That gap is where builders should spend their eval time. Do not ask only whether another provider can advertise a 1M window. Ask whether the model still follows the instruction buried at token 750,000, whether it can compare two similar screenshots without drifting, whether latency stays acceptable, and whether the economics survive real user traffic.
Why run it through Atlas Cloud
Atlas Cloud gives teams one API key for 300+ models across LLM, image, video, and audio workloads. That matters more as model releases converge on the same headline features.
You can test M3 against the models already in your stack, route traffic where it performs, and keep the integration surface stable as new releases land. You can keep GPT-5.5 where it wins on computer-use work, keep Claude Opus 4.8 where it wins on long-running coding agents, use Qwen3.7-Plus where multimodal GUI agents win, use DeepSeek-V4 where price/performance wins, and add M3 where long context plus native multimodality changes the result.
Use M3 where its long context and multimodality pay for themselves. Keep other models where they still win. Swap based on evals, not launch-week hype.
[CTA - builder intent: Run M3 on Atlas Cloud -> atlascloud.ai/models | Get an API key -> console.atlascloud.ai]






