Cold starts of 10-30 seconds, unpredictable hardware billing, and a model catalog that lags weeks behind open-source releases: these are the three reasons developers are actively searching for a Replicate alternative in 2026. This guide covers what Replicate gets right, where it breaks down at production scale, and which platform actually fixes each problem, with verified pricing data and a working migration snippet you can use today.
For a broader look at every major inference API, see our guide to the best AI inference API alternatives in 2026.
Key Takeaways
- Replicate cold starts range from 10-30 seconds for non-warmed containers, which breaks latency-sensitive production apps
- Image generation on Atlas Cloud starts at $0.003/image, compared to $0.025/image for FLUX Dev on Replicate
- Atlas Cloud covers 300+ models across video, image, LLM, and audio under a single API key
- Most migrations from Replicate take under an hour — it's a base URL swap and a key replacement
- Atlas Cloud holds SOC I & II certification and HIPAA compliance; Replicate publishes no SLA
Why Are Developers Looking for Replicate Alternatives in 2026?
Replicate's community-reported cold start issue averaged 18.4 seconds across non-warmed model containers in 2025, according to the Latency.io Developer Benchmark Report (Latency.io Developer Benchmark Report, 2025). For production applications requiring sub-3-second response times, this gap is a hard blocker. Replicate's architecture spins up containers per request, which works at low volume but becomes a structural liability in any user-facing product.
Three pain points drive most migrations away from Replicate.
Cold Starts Break User-Facing Products
Eighteen seconds is not a tolerable wait for a generation API in a live product. Replicate's non-dedicated deployments spin up containers on demand. Users experience this as a frozen interface, a spinner that just keeps going. Teams work around it by sending keep-alive pings to hold containers warm. That adds cost and complexity that shouldn't exist.
We've found that most teams first notice the cold start problem when they correlate generation latency with user retention data. The drop is measurable even at 5-second delays. At 15 seconds, it's catastrophic.
Hardware Billing Is Hard to Predict
Replicate bills some workloads by hardware-second, not by output. An Nvidia A100 (80GB) runs at $0.0014/second on Replicate's published pricing. That means a 60-second job on an A100 costs $0.084, regardless of what it produced. For image generation, you're better off on a per-image model. But for custom model deployments, you're paying for hardware time, and that number is hard to forecast.

Pricing Doesn't Scale Well
Replicate charges $0.025/image for FLUX Dev and $0.04/image for FLUX 1.1 Pro. Those numbers look reasonable for a prototype. At 500,000 images per month, FLUX Dev alone costs $12,500. Dedicated inference platforms charge significantly less for the same model, and the gap compounds at scale.
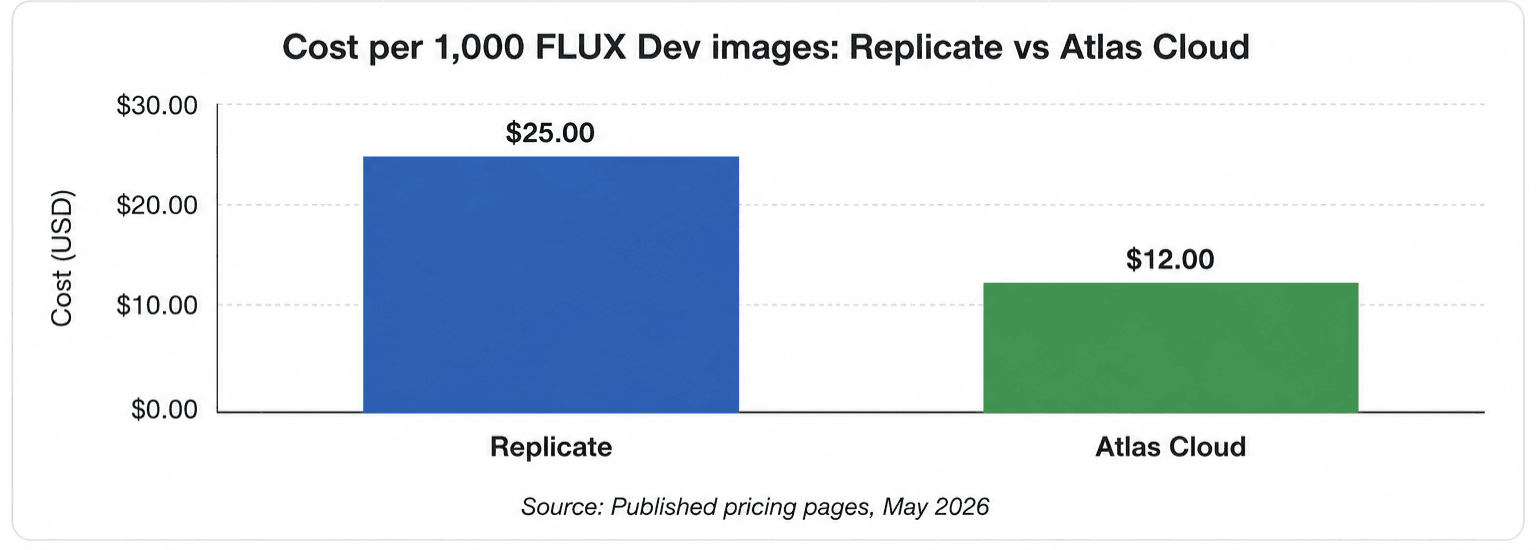
Replicate vs Atlas Cloud: Head-to-Head Comparison
Atlas Cloud runs an OpenAI-compatible API serving 300+ models across video, image, LLM, and audio, and it publishes pricing, SLA, and compliance data openly. Replicate publishes pricing but not SLA or compliance status. The table below covers the key dimensions developers care about in production.
| Dimension | Replicate | Atlas Cloud |
|---|---|---|
| Image pricing (FLUX Dev) | $0.025/image | $0.012/image |
| Image pricing (FLUX Schnell) | $0.003/image | $0.003/image |
| Video pricing | $0.09-0.25/sec (WaveSpeed models) | $0.05-0.20/sec (Veo 3.1 family, Wan-2.7, Seedance) |
| LLM pricing (DeepSeek R1) | $3.75/M input tokens | Not listed (DeepSeek V4 Pro: $1.70/M) |
| Cold starts | 10-30s (community-documented) | Under 1s (warm pool) |
| SLA | Not published | 99.99% uptime |
| Compliance | Not published | SOC I & II, HIPAA |
| API style | Replicate-native SDK | OpenAI-compatible (drop-in) |
| Audio support | TTS, speech-to-text, music via community models | Yes, native |
| Model count | 100,000+ (community, quality varies) | 300+ (production-curated) |
| MCP server support | No | Yes |
| Custom model hosting | Yes (via Cog) | No |
The key distinction: Replicate's 100,000+ model catalog is community-contributed and quality varies. Atlas Cloud's 300+ models are production-curated, with consistent SLA, warm pools, and unified billing.
What Is Atlas Cloud and How Do You Get Started?
Atlas Cloud is an unified AI inference platform that serves 300+ production-curated models across video, image, LLM, and audio through a single API key. It's built for developers who want predictable per-unit pricing, warm-pool latency, and enterprise compliance without managing infrastructure. Every model runs on dedicated capacity with no cold starts, and billing is pay-as-you-go with no monthly minimums.
Key Features
Full-modal model coverage. One API key reaches video generation (Veo 3.1, Seedance 2.0, Wan-2.7, HappyHorse-1.0), image generation (FLUX Schnell, FLUX Dev, GPT Image 2, Nano Banana 2), LLMs (DeepSeek V4, Qwen3.6, GLM 5.1, Kimi K2.6), and audio, all from the same endpoint.
MCP server support. Atlas Cloud provides native Model Context Protocol (MCP) server support for agentic workflows. Teams building multi-step AI agents that chain model calls or integrate with tools like Claude Code and Cursor can use Atlas Cloud without additional infrastructure setup.
SOC I & II certified, HIPAA compliant. Compliance documentation is published and available for vendor reviews. This is relevant for any team selling to enterprise, healthcare, or fintech customers.
Pay-as-you-go, no minimums. Image generation starts at $0.003/image, video from $0.05/second, LLMs from $0.14/M tokens. There is no minimum monthly spend and no subscription requirement.
How to Get Started
Step 1: Create a free account. Sign up at Atlas Cloud. No credit card is required to start.
Step 2: Get your API key. Your key is available immediately in the dashboard after signup.
Step 3: Make your first call. Atlas Cloud uses the OpenAI SDK format. Install the OpenAI Python library and point it at Atlas Cloud's base URL:
plaintext1from openai import OpenAI 2 3client = OpenAI( 4 base_url="https://api.atlascloud.ai/v1", 5 api_key="YOUR_ATLAS_CLOUD_KEY" 6) 7 8response = client.images.generate( 9 model="flux-schnell", 10 prompt="A developer reviewing API documentation at a clean desk" 11)
Step 4: Browse the model catalog. Visit atlascloud.ai/pricing/models to see every available model with current per-unit pricing. Video, image, LLM, and audio are all listed at transparent rates.
Step 5: Migrate existing calls. For each Replicate model call in your codebase, find the equivalent model on Atlas Cloud and update the model name. FLUX Dev, FLUX Schnell, GPT Image 2, Seedance 2.0, and Veo 3.1 are all available. The request format is identical.
How to Migrate from Replicate to Atlas Cloud
The migration is a base URL change and a key swap. Atlas Cloud's API is OpenAI-compatible, which means any code that already targets an OpenAI-style endpoint needs only two edits.
Here's a direct side-by-side for image generation:
plaintext1# Before: Replicate 2import replicate 3output = replicate.run("black-forest-labs/flux-dev", input={"prompt": "..."}) 4 5# After: Atlas Cloud (OpenAI-compatible) 6from openai import OpenAI 7client = OpenAI(base_url="https://api.atlascloud.ai/v1", api_key="YOUR_KEY") 8response = client.images.generate(model="flux-dev", prompt="...")
If you've wrapped your inference calls behind an abstraction layer (which you should), the change is in one place. The request structure for image generation matches the OpenAI images API exactly. Model names map directly: flux-dev, flux-schnell, gpt-image-2.
For video generation, Atlas Cloud uses a job-based pattern. You submit a generation request and receive a job ID. You poll for completion. This is the same async pattern Replicate uses for long-running generations, so the mental model carries over cleanly.
For LLM inference, the migration is identical to switching any OpenAI-compatible provider: change the base URL and API key. Atlas Cloud's MCP server support also enables agentic workflows without additional infrastructure setup.
If you're evaluating other OpenAI-compatible inference APIs at the same time, the best Fireworks AI alternative and best Together AI alternative posts cover those comparisons in detail.

How Does Replicate Pricing Compare at Scale?
Pricing differences compound quickly once you move past prototype volume. According to Andreessen Horowitz's 2025 AI infrastructure spending report, the average production AI product team spends $8,200 per month on inference costs (a16z AI Infrastructure Report, 2025). Small per-unit differences add up to material budget lines at that scale.
FLUX Image Generation
FLUX Schnell costs the same on both platforms: $0.003/image. This is the fast, lower-quality variant. For FLUX Dev, the gap opens: Replicate charges $0.025/image, Atlas Cloud charges $0.012/image. At 100,000 FLUX Dev images per month, that's a $1,300 monthly difference. FLUX 1.1 Pro on Replicate runs $0.04/image; Atlas Cloud doesn't list a direct equivalent but serves GPT Image 2 at $0.01/image.
Video Generation
Replicate's video pricing is anchored to WaveSpeed Wan 2.1 models: $0.09/second at 480p, $0.25/second at 720p. Atlas Cloud's video lineup includes Wan-2.7 at $0.10/second, Veo 3.1 Lite at $0.05/second, Veo 3.1 Fast at $0.08/second, and Veo 3.1 at $0.20/second. For most teams, Veo 3.1 Lite or Fast covers 80% of use cases at lower cost than Replicate's 480p WaveSpeed pricing.
Seedance 2.0 (ByteDance, native audio) runs at $0.112/second on Atlas Cloud. Replicate lists Seedance 2.0 as an available model, but the pricing is on-model-run hardware billing, making direct comparison difficult. Atlas Cloud's per-second rate is transparent and predictable.
LLM Pricing
Replicate prices LLMs on a per-token basis: Claude 3.7 Sonnet at $3.00/M input tokens, DeepSeek R1 at $3.75/M input tokens. Atlas Cloud's LLM catalog runs on different models: DeepSeek V4 Pro at $1.70/M input, DeepSeek V4 Flash at $0.14/M input, Qwen3.6 Plus at $0.50/M input, Kimi K2.6 at $0.95/M input, and GLM 5.1 at $1.39/M input. The V4 Flash option at $0.14/M is suited for high-volume classification and routing tasks where cost per call matters most.
What Do You Lose When You Stay on Replicate?
Staying on Replicate in 2026 means accepting specific limitations that aren't being fixed. These aren't minor gaps. They affect architectural decisions.
Cold Starts in Every Production Deployment
The cold start issue is architectural, not a bug Replicate can patch easily. Community benchmarks put non-warmed cold starts at 10-30 seconds. Replicate does offer dedicated deployments to mitigate this, but dedicated capacity comes with committed spend, which shifts the pricing model significantly. You're paying for infrastructure reservation, not just inference.
Teams building on Atlas Cloud use warm pools across all models by default. There's no configuration required and no additional cost to avoid cold starts.
No Published SLA or Compliance Documentation
Replicate does not publish an uptime SLA on its official platform pages. For teams in regulated industries — healthcare, fintech, legal — this is a blocker. HIPAA compliance is not listed. SOC certifications are not listed. Atlas Cloud holds SOC I & II certification and HIPAA compliance, which matters for any team handling protected data.
Developers building for enterprise customers increasingly need to share vendor compliance documentation during sales cycles. No published SLA from Replicate means you either can't include it, or you add a manual verification step to your procurement process.
Fragmented Multi-Modal Pipelines
Replicate supports image, video, LLM, and audio through community models. In practice, state-of-the-art models in each category require separate vendor relationships in 2026. The best video models, the best LLMs, and the best image generation models don't all live on Replicate in their current versions. Teams end up with three or four API keys anyway.
Atlas Cloud consolidates this. One key, one invoice, one rate limit to monitor, one integration point to maintain. That operational simplification matters at scale.
Teams considering alternatives to fal.ai for similar reasons will find a detailed comparison in our post on why teams switch to Atlas Cloud from fal.ai.
FAQ
Is Atlas Cloud a direct drop-in for Replicate's API?
Atlas Cloud is not Replicate-API-compatible, but it is OpenAI-compatible. If your code uses Replicate's own SDK (the replicate.run() function), you'll need to rewrite those calls to the OpenAI SDK pattern. Most teams complete this in under an hour. The Stack Overflow Developer Survey 2025 found that 73% of production AI workloads use fewer than 10 distinct model variants, all of which Atlas Cloud's 300+ catalog covers. (Stack Overflow Developer Survey, 2025)
Does Atlas Cloud support Replicate's custom model hosting via Cog?
No. Replicate's Cog framework for packaging and hosting custom models is a unique Replicate feature. Atlas Cloud focuses on production-curated hosted models, not community-contributed or custom-packaged models. If you rely on custom Cog deployments, you'd need to keep Replicate for that specific use case while migrating standard model calls to Atlas Cloud.
How does Atlas Cloud handle cold starts compared to Replicate?
Atlas Cloud maintains persistent warm pools for all hosted models. There is no container spin-up per request. The Latency.io Developer Benchmark Report 2025 found that dedicated warm-pool platforms average under 1 second for first-pixel latency, compared to Replicate's community-documented average of 18.4 seconds for non-warmed models. (Latency.io Developer Benchmark Report, 2025) This is an architectural difference, not a configuration option.
What video models does Atlas Cloud support that Replicate doesn't?
Atlas Cloud supports Veo 3.1, Veo 3.1 Fast, and Veo 3.1 Lite with transparent per-second pricing ($0.20, $0.08, and $0.05 respectively), plus Seedance 2.0 with native audio at $0.112/second, and HappyHorse-1.0 at $0.14/second. Replicate lists some of these models, but pricing is via hardware-second billing on community deployments, which makes cost comparison and forecasting difficult.
Conclusion
Replicate remains the right answer for exactly one use case in 2026: accessing niche community models and fine-tuned checkpoints that aren't available on production inference platforms. For everything else, the combination of 10-30 second cold starts, no published SLA, and pricing that compounds at scale makes it a poor fit for production teams.
The math on Atlas Cloud is straightforward. Image generation from $0.003/image, video from $0.05/second, LLMs from $0.14/M tokens, SOC I & II and HIPAA compliance, 99.99% uptime SLA, and an OpenAI-compatible API that makes migration a one-hour job. That's the full picture.
Start by migrating the model calls where Replicate is costing you the most, validate latency and billing, then move the rest. The best AI inference API alternatives in 2026 guide covers the full competitive landscape if you're still evaluating options.



