Your prompt hit a refusal wall. Not because it was harmful, but because a keyword triggered a filter.
Developers in the Ollama community describe this as "refusal vectors": keyword-triggered blocks that have nothing to do with actual harm. Malware reverse engineering for security research, medical case study documentation, adult content creation, dark fiction writing. Mainstream AI blocks all of these. This list ranks the best uncensored AI models 2026 by real community data, not marketing copy. It covers three categories: uncensored llm models for text and code, the best uncensored local ai models 2026 for private hardware deployment, and uncensored ai models 2026 for image and video generation via API. Every number is sourced and datestamped to May 2026.
For an introduction to the broader tooling landscape, readers new to this space will find the uncensored AI image generator guide a useful starting point before selecting a specific model.
How We Ranked the Best Uncensored AI Models 2026
In 2026, community download counts from Ollama provide a more reliable ranking signal than benchmark scores, which can be selected for press releases rather than real-world performance (Ollama, uncensored model search, 2026). Millions of pulls represent thousands of hardware setups and prompt types. That's harder to game than a curated eval set.
Three ranking signals are used throughout this article. For Ollama uncensored models, the primary signal is pull count from ollama.com, retrieved May 2026. For OpenRouter models, ranking goes by parameter count and context window, since pull counts aren't publicly available on that platform. For image and video models, ranking goes by price-per-output, with lower costs listed first within each group.
Most uncensored ai models 2026 fall into two technical categories: fine-tuned and abliterated. Fine-tuned models like the Dolphin series are trained on datasets that don't reinforce refusal behavior. Abliterated models have their refusal weights removed surgically. The community consistently finds fine-tuned models more stable across diverse prompt types.
In practice, download counts also correlate with model stability. A model that reaches 1M+ pulls has been tested across a wide range of hardware configurations, surfacing bugs and instability that smaller test groups miss entirely.
What Are the Top 5 Most Downloaded Ollama Uncensored Models?
In 2026, the five most downloaded ollama uncensored models collectively account for over 9.2M pulls, with llama2-uncensored leading at 2.6M (Ollama, uncensored model search, 2026). These are the best uncensored Ollama models 2026 by community validation, not by any benchmark. Hardware is the primary filter most users apply first: VRAM requirements range from under 4GB to 40GB across this group.
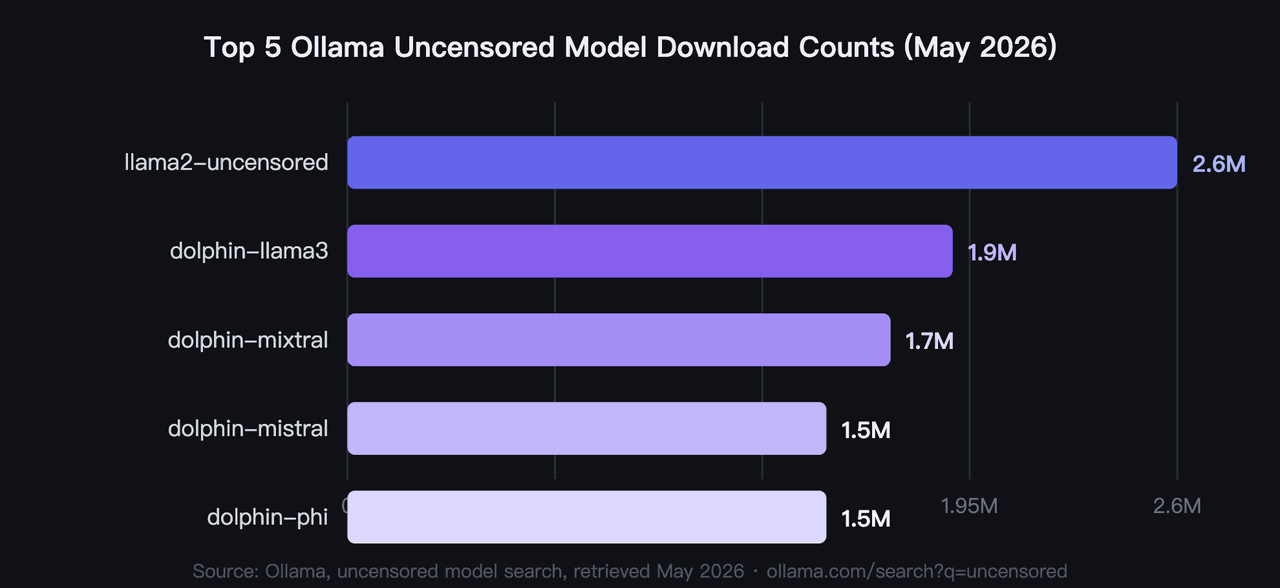
1. llama2-uncensored: Most Downloaded Uncensored AI Model on Ollama
The original community benchmark for uncensored local AI. George Sung and Jarrad Hope released this fine-tune to remove Llama 2's refusal behavior without degrading general capability. It's the model most developers start with, and its 2.6M pull count reflects over two years of real-world use. No single uncensored LLM has matched that download volume.
- Parameters: 7B or 70B
- VRAM: ~6GB (7B); ~40GB (70B)
- Best for: General-purpose unrestricted chat and content generation
- Platform: Ollama
2. dolphin-llama3: Best Uncensored Llama 3 LLM Model for Agentic Workflows
Eric Hartford's Dolphin on a Llama 3 base is the most-downloaded uncensored model built on a modern architecture, with 1.9M pulls (Ollama, dolphin-llama3 model page, 2026). It supports function calling and a context window that extends from 8K to 256K tokens depending on configuration. The 8B version weighs 4.7GB, fitting on most mid-range consumer GPUs.
- Parameters: 8B or 70B
- VRAM: ~5GB (8B); ~40GB (70B)
- Best for: Coding, agentic workflows, and function calling
- Platform: Ollama
3. dolphin-mixtral 8x7B: Uncensored MoE AI Model for Complex Reasoning
A mixture-of-experts architecture routes each token through a subset of its 8 expert layers. This produces near-70B reasoning quality at lower inference cost than a dense model of equivalent total parameter count. Eric Hartford's uncensored fine-tune keeps a strong coding emphasis throughout.
- Parameters: 8x7B (active parameters per inference pass are far lower than total)
- VRAM: ~12-16GB with quantization
- Best for: Complex coding tasks, technical reasoning, and longer instruction chains
- Platform: Ollama
4. dolphin-mistral: Uncensored 7B Local AI Model for Fast Responses
Lighter and faster than dolphin-mixtral on CPU-constrained hardware. It draws 1.5M pulls from developers who want a responsive local model for code completion without needing a high-end GPU. The Mistral base architecture gives it a strong performance-to-size ratio for a 7B model.
- Parameters: 7B
- VRAM: ~5-6GB
- Best for: Lightweight coding assistance and fast chat responses
- Platform: Ollama
5. dolphin-phi 2.7B: Lightest Uncensored Local AI Model
Microsoft's Phi base architecture packs capable reasoning into a 2.7B parameter count. Eric Hartford's uncensored fine-tune preserves that efficiency. At under 4GB VRAM, it runs on most consumer laptops with a discrete GPU, making it the accessible entry point for the best uncensored local ai models 2026.
- Parameters: 2.7B
- VRAM: Under 4GB
- Best for: Laptop deployment, quick testing, and hardware-constrained environments
- Platform: Ollama
Best Uncensored LLM Models 6-10: Coding, Roleplay, and Long Context
In 2026, the Dolphin series accounts for 5 of the top 10 spots in Ollama's uncensored catalog by download count, a concentration that reflects Eric Hartford's consistent fine-tuning methodology applied across different base architectures (Ollama, hermes3 model page, 2026). Models 6 through 10 cover roleplay, general conversation, developer tooling, instruction following, and extended context: the use cases where mainstream AI refusals are most disruptive.
6. hermes3: Uncensored AI Model for Roleplay and Agentic Tasks
Nous Research built hermes3 for roleplay depth and structured tool use. It's available in four sizes from 3B to 405B, the widest size range of any model in this list. At 1.3M pulls, the 8B variant sits in a practical spot for creative writing and agentic planning workflows (Ollama, hermes3 model page, 2026).
- Parameters: 3B, 8B, 70B, or 405B
- VRAM: ~2GB (3B); ~5GB (8B); ~40GB (70B)
- Best for: Roleplay, creative fiction, and agentic task planning
- Platform: Ollama
7. wizard-vicuna-uncensored: Uncensored Multi-Size AI Model for General Use
An older but proven model built on Llama 2, available in three sizes up to 30B. Its 1.2M pulls come from users who want a reliable uncensored option with a wider parameter range. It doesn't match the context window capabilities of dolphin-llama3, but handles general conversation and creative content consistently.
- Parameters: 7B, 13B, or 30B
- VRAM: ~5GB (7B); ~9GB (13B); ~20GB (30B)
- Best for: General-purpose conversation and creative content at multiple size options
- Platform: Ollama
8. dolphincoder: Uncensored AI Coding Model on StarCoder2 Base
StarCoder2 as the base makes dolphincoder a genuine specialist. Where other Dolphin models are generalists with uncensored fine-tuning, this one targets software development specifically. Its 943K pulls come almost entirely from developers, not creative users. The 15B variant handles larger codebases than the 7B can manage.
- Parameters: 7B or 15B
- VRAM: ~5GB (7B); ~10GB (15B)
- Best for: Code generation, debugging, and technical documentation
- Platform: Ollama
9. wizardlm-uncensored: Uncensored Instruction-Following LLM for Research Workflows
A 13B instruction-following model with 610K pulls. Its strength is following complex multi-step instructions without hedging or refusing sub-tasks. In research workflows where one refusal breaks a long chain, that reliability has direct productivity value. It doesn't have the modern base architecture of dolphin-llama3, but it does the instruction job consistently.
- Parameters: 13B
- VRAM: ~9GB
- Best for: Complex multi-step instruction chains and research workflows
- Platform: Ollama
10. everythinglm: Uncensored LLM with 16K Context Window
The standout feature here is the 16K context window on a Llama 2 base. Most 7B models top out at 4K or 8K tokens. That extra context lets everythinglm process full codebases, long documents, or extended conversation histories without truncation. Its 536K pulls are modest by this list's standards, but it fills a gap no other model here covers at this size.
- Parameters: 13B
- VRAM: ~9GB
- Best for: Long-document analysis, extended context chat, and full-codebase review
- Platform: Ollama
The Dolphin series' dominance in Ollama download counts reflects a pattern the community has documented: fine-tuned uncensored models from a single author with a consistent methodology outperform one-off abliteration attempts. Abliteration removes refusal weights from a single model. Fine-tuning builds stable uncensored behavior across diverse prompt types. That consistency is why 5 of the top 10 spots belong to Eric Hartford's work, not to any single base architecture.
How Do You Set Up Ollama Uncensored Models Locally?
In 2026, three commands install any Ollama model on Mac, Linux, or Windows: install Ollama from ollama.com, run ollama pull [model-name], then ollama run [model-name] (Ollama documentation, 2026). No API key is required. No external content moderation applies. Your prompt never leaves your hardware.
For dolphin-llama3 as a concrete example: ollama pull dolphin-llama3 downloads the 4.7GB 8B file. ollama run dolphin-llama3 opens an interactive prompt. The entire inference process runs on your local GPU or CPU.
LM Studio provides a desktop GUI for users who prefer not to work in the terminal. It uses the same GGUF model files that Ollama uses, with a visual interface for model selection and parameter adjustment. llama.cpp is the underlying inference engine behind both tools, and it supports direct command-line use when you need more control over quantization levels and context length settings.
Developers who want specific hardware requirements and quantization settings for running the best uncensored local ai models 2026 on consumer GPUs will find the complete local setup guide covers minimum VRAM configurations and common setup errors in detail.
What OpenRouter Uncensored Models Are Available Without a Local GPU?
In 2026, OpenRouter hosts uncensored LLMs via API, removing the GPU requirement entirely. The venice/uncensored model is available as a free-tier model at $0 per million input and output tokens (OpenRouter, venice/uncensored model page, 2026). This makes OpenRouter uncensored models the practical entry point for users without dedicated hardware.
The trade-off is straightforward: OpenRouter routes your prompt through their infrastructure, so the conversation is not private in the way a local model is. Local Ollama models keep everything on your device. Neither approach is universally better. The right choice depends on your threat model and hardware availability.
11. venice/uncensored: Free Uncensored OpenRouter Model
The Venice Uncensored model on OpenRouter's free tier. A 24B Mistral-Small base, fine-tuned for uncensored output by Cognitive Computations in collaboration with Venice.ai. 32K context window, $0 per million tokens. OpenRouter's free tier applies a platform-wide limit of 200 requests per day across free models.
- Parameters: 24B
- VRAM: None required (cloud-hosted)
- Best for: Testing uncensored LLMs without local hardware; free within platform rate limits
- Platform: OpenRouter
12. Sao10K: Llama 3.3 Euryale 70B: Large Uncensored Model via OpenRouter
70B creative roleplay and instruction-following model from Sao10k, fine-tuned for uncensored output. Based on Llama 3.3 70B with 131K context. Actively maintained with real usage on OpenRouter, and searchable by name in the platform's global search.
- Parameters: 70B
- VRAM: None required (cloud-hosted)
- Best for: Complex creative writing, roleplay, and long instruction chains without local hardware
- Platform: OpenRouter
13. Sao10K: Llama 3 8B Lunaris: Lightweight Uncensored Model via OpenRouter
Lunaris 8B is a versatile generalist and roleplay model from Sao10k, based on Llama 3 8B. It is a strategic merge of multiple models designed to balance creativity with improved logic and general knowledge, offering an improved experience over Stheno v3.2 with enhanced creativity and reasoning. The lowest-cost uncensored option on OpenRouter at $0.04/$0.05 per million tokens, with over 6 billion tokens of real usage on the platform.
- Parameters: 8B
- VRAM: None required (cloud-hosted)
- Best for: Lightweight uncensored conversation and creative writing at minimal cost
- Platform: OpenRouter
14. TheDrummer: Cydonia 24B V4.1: Uncensored Creative Writing Model via OpenRouter
Cydonia 24B V4.1 is an uncensored creative writing model from TheDrummer, based on Mistral Small 3.2 24B, with good recall, prompt adherence, and intelligence. 131K context window. Actively maintained and directly searchable by name in OpenRouter's global search.
- Parameters: 24B
- VRAM: None required (cloud-hosted)
- Best for: Uncensored creative writing and roleplay without local hardware
- Platform: OpenRouter
How to Access Uncensored Image and Video Models via Atlas Cloud
In 2026, most uncensored image and video models require either local GPU hardware or a dedicated API platform, because mainstream cloud providers apply content filters that block NSFW output at the inference level. Atlas Cloud is a model API platform built specifically to remove that constraint, covering 300+ curated models across text, image, video, and audio.
Getting started takes three steps:
- Create an account at atlascloud.ai
- Generate an API key from the dashboard
- Call the model endpoint using the key — image and video models use their own REST format; LLM endpoints follow the OpenAI Chat Completions format
What makes Atlas Cloud relevant for uncensored use cases specifically:
- The platform's privacy policy states: "Your generated content is never used for training and never reviewed by anyone." This is a published, explicit commitment, not a default assumption.
- No daily generation cap applies to any model in the catalog.
- The uncensored image catalog covers 33 text-to-image models starting at $0.003 per image.
- The uncensored video catalog covers 10+ NSFW video models starting at $0.01/sec.
The full uncensored model catalog is browsable at Uncensored AI. Models #15 through #20 in this list are all accessible through a single Atlas Cloud API key.
What Are the Best Uncensored AI Image Models for NSFW and Adult Content Generation?
In 2026, FLUX architecture powers the majority of high-quality uncensored image generation, available via the Atlas Cloud API across price and quality tiers (Atlas Cloud, text-to-image model list, 2026). Atlas Cloud's catalog covers 33 text-to-image models in total. Use cases include fine art, character design, uncensored lingerie models and adult portrait generation, game asset creation, and batch illustration at volume.
Atlas Cloud's homepage states "300+ curated models across text, image, video, and audio," and the platform's privacy policy for its uncensored catalog reads: "Your generated content is never used for training and never reviewed by anyone."
For a full breakdown of browser-based and API uncensored image tools, the best uncensored NSFW AI image generators guide covers both categories with capability comparisons. Developers focused specifically on FLUX architecture can read the FLUX uncensored image generator guide for fine-tuning and workflow details.
For workflows that start from an existing image rather than a text prompt, the uncensored AI image-to-image guide and the best uncensored AI image editors guide cover transformation and editing pipelines respectively. Teams focused on anime-style or illustrated character output will find specialized options in the uncensored anime AI image generators guide.
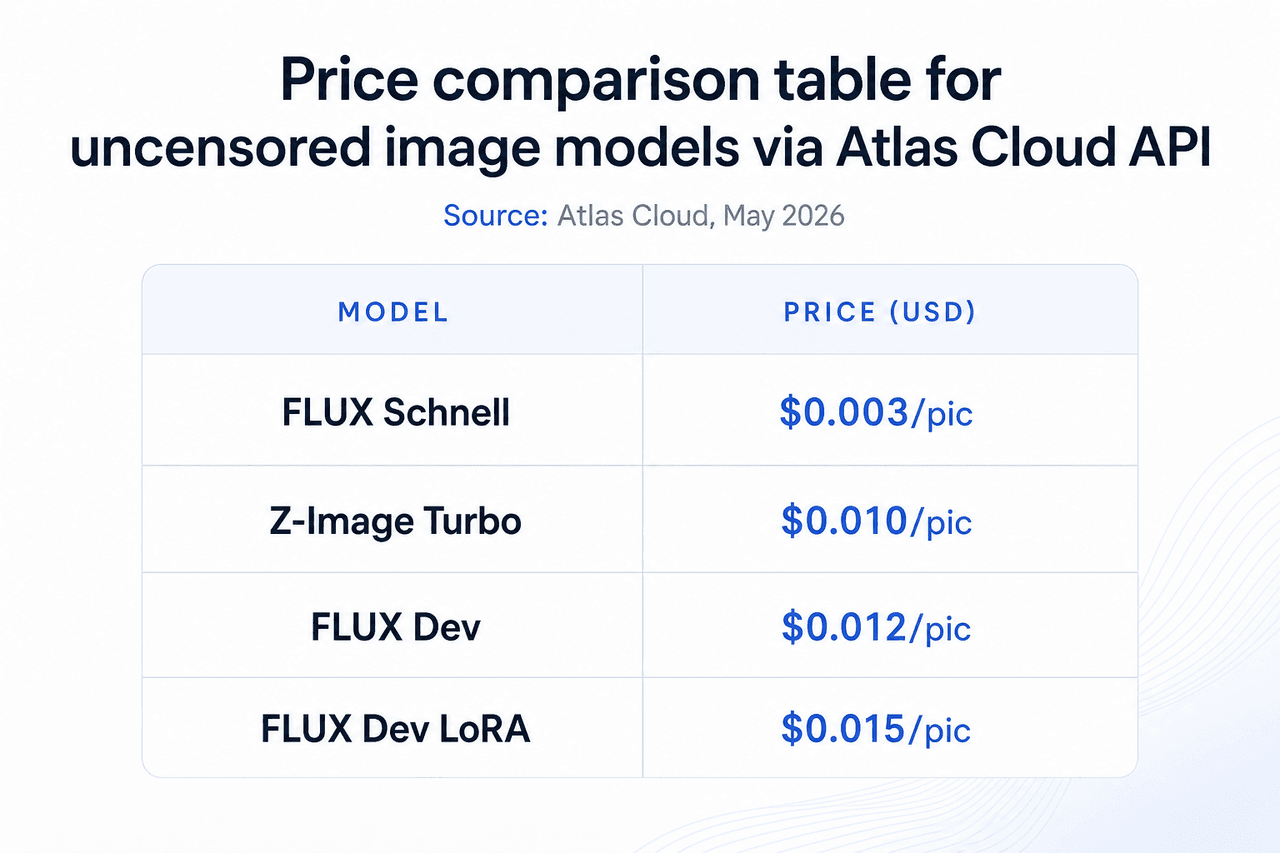
15. FLUX Schnell: Fastest Uncensored AI Image Model for Batch Generation
The lowest-cost option in the Atlas Cloud image catalog. At $0.003 per image, it's the right tool for batch generation workflows where speed and volume matter more than fine detail. No daily cap applies, and no content is stored for training.
- Price: $0.003/pic
- VRAM: None required (API access)
- Best for: Batch image generation, rapid prototyping, and high-volume uncensored output
- Platform: Atlas Cloud API
At $0.003 per image, a budget of $3.00 produces 1,000 images. That cost per output is lower than cloud storage fees for the resulting files at most providers. That flips the economics for studios that previously ran expensive local GPU rigs overnight for batch generation: the API approach is now both cheaper and faster for volume work.
16. FLUX Dev: Highest Quality Uncensored AI Image Model for Final Production
Four times the cost of FLUX Schnell, with noticeably better anatomy, lighting, and texture detail. For final-quality output where individual images matter, the $0.012 price point is a practical step up. It suits portfolio pieces, commercial adult content, and production assets where quality is the primary constraint.
- Price: $0.012/pic
- VRAM: None required (API access)
- Best for: High-quality single images, portfolio pieces, and final production assets
- Platform: Atlas Cloud API
17. FLUX Dev LoRA: Uncensored Image Model with Custom Style Training
LoRA fine-tuning injects a custom style, character appearance, or subject into the FLUX Dev base. This is the model to use when you need consistent character appearance across a batch or want a house style applied to every image in a set. Atlas Cloud handles the LoRA loading server-side.
- Price: $0.015/pic
- VRAM: None required (API access)
- Best for: Character consistency, custom style training, and branded image series
- Platform: Atlas Cloud API
18. Z-Image Turbo: Budget Uncensored AI Image Model at Mid-Tier Quality
Positioned between FLUX Schnell and FLUX Dev on the price-quality curve. At $0.01 per image, Z-Image Turbo offers a different architecture optimized for speed without the image simplification that Schnell makes at its lower price point. The practical choice when Schnell quality isn't sufficient and FLUX Dev cost is too high for the volume needed.
- Price: $0.01/pic
- VRAM: None required (API access)
- Best for: Moderate-volume generation where quality and cost need to balance
- Platform: Atlas Cloud API
What Are the Best Uncensored AI Video Models for NSFW Animation in 2026?
In 2026, uncensored video generation requires a separate pipeline from image generation because mainstream video platforms apply identical content filters and refuse to animate NSFW content even when the source image was generated elsewhere (Atlas Cloud, uncensored model catalog, 2026). Atlas Cloud's uncensored video page carries the headline "Unrestricted Creative Freedom. No Filters. No Limits." and covers 10+ NSFW video models, with the full catalog also including Wan 2.6, Wan 2.5, and Van series variants.
19. Wan 2.2 Turbo Spicy Infinite I2V: Lowest-Cost Uncensored Video Model
The entry-level option for NSFW animation from a still image. At $0.01/sec it's the most cost-efficient way to animate a static image into NSFW video content. Resolution reaches 1080p with variable clip duration, making it the right starting point for budget-conscious production pipelines.
- Price: $0.01/sec
- Resolution: 1080p
- Duration: Variable
- Best for: Cost-efficient NSFW animation and previewing motion concepts
- Platform: Atlas Cloud API
20. Seedance v1.5 Spicy: Highest Quality Uncensored Video Model for Final Output
The cinematic-quality option in the catalog. At $0.049/sec it costs roughly 2.5 times more than Wan 2.2 Turbo Spicy Infinite, but produces smoother motion, better subject coherence across frames, and more natural transitions. For final-quality NSFW video output where visual fidelity is the primary concern, this is the top option in the Atlas Cloud uncensored video lineup.
- Price: $0.049/sec
- Resolution: 720p
- Duration: 5s
- Best for: Final-quality NSFW video, professional adult content, and delivery-ready output
- Platform: Atlas Cloud API
The best uncensored AI image-to-video generators guide covers the full catalog of Wan 2.7 and Wan 2.2 Spicy series variants with all duration and resolution options.
Uncensored AI Model Quick Selection Guide
| Need | Recommended |
|---|---|
| Best overall uncensored LLM | llama2-uncensored or dolphin-llama3 |
| Coding tasks | dolphin-mixtral 8x7B or dolphincoder |
| Roleplay and creative writing | hermes3 |
| Under 4GB VRAM | dolphin-phi 2.7B |
| Uncensored image generation | FLUX Schnell via Atlas Cloud ($0.003/pic) |
| NSFW video from image | Wan 2.2 Turbo Spicy Infinite via Atlas Cloud ($0.01/sec) |
Uncensored AI Models FAQ
What is the most uncensored AI model in 2026?
By Ollama download count, llama2-uncensored leads at 2.6M pulls, making it the most community-validated option among uncensored ai models 2026 (Ollama, uncensored model search, 2026). By raw capability, dolphin-llama3 offers more: function calling, up to 256K context, and a Llama 3 base architecture. The answer depends on whether proven stability or modern capability matters more for your use case.
Which uncensored models run on Ollama?
Ten models from this list run as ollama uncensored models: llama2-uncensored, dolphin-llama3, dolphin-mixtral, dolphin-mistral, dolphin-phi, hermes3, wizard-vicuna-uncensored, dolphincoder, wizardlm-uncensored, and everythinglm. The community model jaahas/qwen3.5-uncensored also runs on Ollama for multilingual use. All install with ollama pull [model-name].
What uncensored models are available on OpenRouter?
In 2026, OpenRouter hosts uncensored LLMs via API, removing the GPU requirement entirely. Options include the free-tier venice/uncensored model at $0 per million tokens (200 requests per day), plus paid models including Sao10K Euryale 70B, Lunaris 8B, and TheDrummer Cydonia 24B (OpenRouter, venice/uncensored model page, 2026). These OpenRouter uncensored models require no local GPU and no hardware investment to start.
What is the difference between an abliterated and a fine-tuned uncensored model?
Abliteration removes refusal weights from a model surgically at the weight level. Fine-tuned uncensored models like the Dolphin series are trained on datasets that don't reinforce refusal behavior in the first place. The community consistently finds fine-tuned models more stable: abliteration can introduce inconsistent output across diverse prompt types, while fine-tuning produces reliable results, which explains why Dolphin models dominate the Ollama uncensored download counts.
Can I run uncensored AI models locally on a laptop?
Yes. dolphin-phi 2.7B runs under 4GB VRAM, making it the entry point for laptop deployment with a discrete GPU. With 6-8GB VRAM you can run any 7B model in this list. Integrated graphics won't work. The local setup guide for uncensored AI models covers minimum hardware configurations and quantization settings in detail.
Conclusion
The best uncensored AI model in 2026 depends entirely on your use case. For general LLM work, dolphin-llama3 is the most capable Ollama option. For laptops, dolphin-phi covers the sub-4GB VRAM requirement. For cloud LLM access with no hardware, venice/uncensored on OpenRouter's free tier is the practical starting point at $0 per million tokens. For uncensored image generation at scale, FLUX Schnell via the Atlas Cloud API produces output at $0.003 per image with no daily cap. For NSFW video, the Atlas Cloud catalog starts at $0.01/sec with a verified no-training, no-review policy.
Readers looking for a complete overview of uncensored AI tools across images, video, and editors will find the uncensored AI image generator guide covers the full landscape.






