
Quick Answer
A GitHub AI Video Generator Skill connects your code to AI video models. In 2026, the choice between open-source (free, self-hosted) and paid APIs (cloud, instant) depends on four variables: VRAM availability, data privacy requirements, quality ceiling needed, and monthly generation volume. For production-scale workflows needing multiple SOTA models, Atlas Cloud (atlascloud.ai) provides access to 300+ models — including Kling v3.0, Seedance 2.0, Vidu 3.0, Veo, and Sora — through a single API key with transparent pay-per-use pricing.
-
What Is an AI Video Generator Skill? {#what-is-a-skill}
In the context of GitHub repositories, an AI Video Generator Skill is a reusable module, wrapper, or integration layer that connects an application to an AI video generation backend — either a self-hosted open-source model or a cloud API.
Think of it as the abstraction between your application logic and the actual inference engine. A skill might be:
- A Python class wrapping the
Wan 2.2model pipeline for text-to-video generation - A ComfyUI custom node connecting to the Atlas Cloud API for Kling v3.0 generation
- An n8n workflow node that triggers Seedance 2.0 via REST and returns a video URL
- A LangChain tool or MCP Server skill that calls a video generation endpoint on demand
The core question every developer faces when building one: should the backend be open-source weights running locally, or a paid cloud API?
Real 2026 data. Not theory.
-
GitHub open source in 2026 {#open-source-landscape}
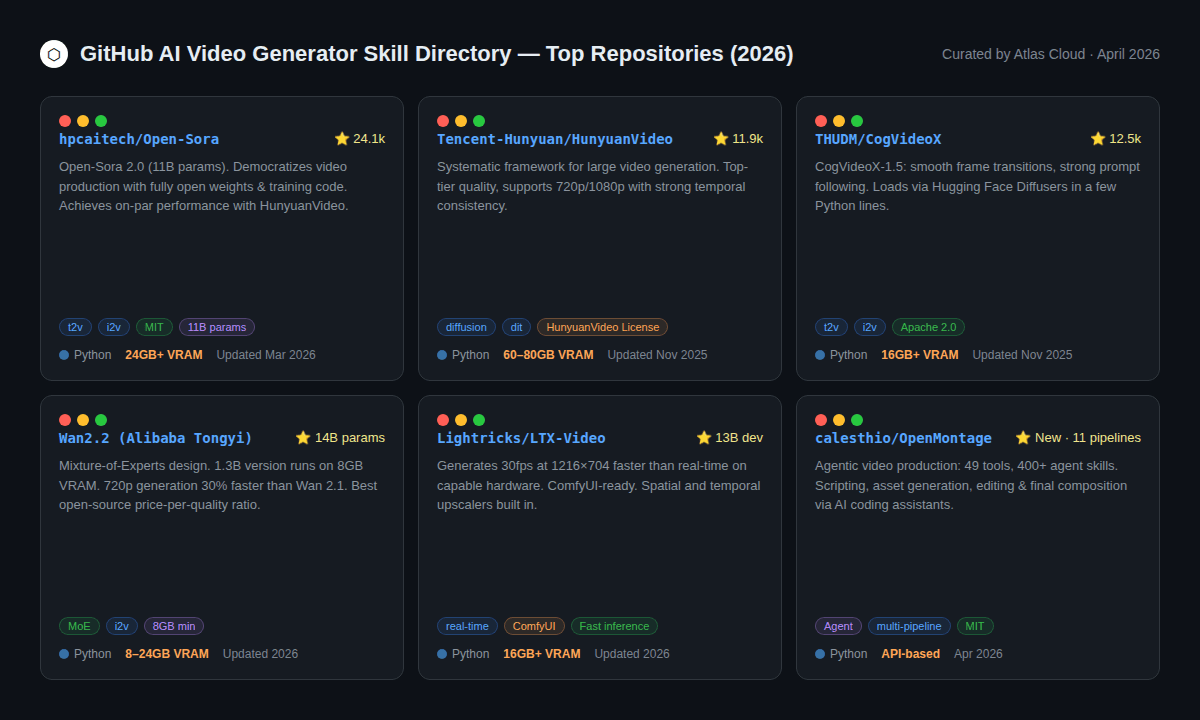
The open-source video generation ecosystem has matured significantly. Some repos are now genuine alternatives to paid APIs — at least for certain tasks.
Tier 1: Production-Grade Open-Source Models
HunyuanVideo (Tencent, 11.9k ⭐) — One of the better open-source video generators out there. Handles 720p and 1080p. The primary limitation is its hardware requirement: 60–80GB VRAM for the full model, making it accessible only to teams with enterprise GPU access. The community license permits commercial use with attribution.
CogVideoX-1.5 (THUDM/CogVideo, 12.5k ⭐) Released under Apache 2.0, this is one of the most developer-friendly open models. It loads natively via Hugging Face Diffusers in a few lines of Python. Frame transitions are smooth, and prompt following is strong. Needs 16GB VRAM minimum. Solid pick if your team already lives on Hugging Face.
Open-Sora 2.0 (hpcaitech, 24.1k ⭐) The most-starred open-source video generation project on GitHub. Version 2.0 (11B parameters) achieves performance comparable to HunyuanVideo on VBench benchmarks, and the training cost was reported at approximately $200,000 — a remarkable figure for a model of this caliber. Text-to-video, image-to-video, and infinite-length generation.
Tier 2: Lighter open-source options (lower VRAM)
Wan 2.2 (Alibaba Tongyi) The accessibility story here is compelling: the 1.3B variant runs on 8GB VRAM, and the 14B variant on 24GB. The Mixture-of-Experts (MoE) architecture delivers better detail at lower compute cost, and version 2.2 is 30% faster at 720p than its predecessor. For developers running a single consumer GPU, Wan 2.2 is the strongest open-source option.
LTX-Video (Lightricks) Designed for speed above all else. Generates 30fps at 1216×704 resolution faster than real-time on capable hardware. The ComfyUI integration is mature, and spatial and temporal upscalers are built in.
Tier 3: Agentic Pipelines
OpenMontage (calesthio, new April 2026) A genuinely novel category: an agentic video production system with 11 pipelines, 49 tools, and 400+ agent skills. Works with AI coding assistants like Claude Code, Cursor, and Copilot. Handles the full pipeline — research, scripting, assets, editing — start to finish without manual steps. Built for teams wiring together multiple AI tools into one workflow.
-
Paid API Directory: SOTA Models Available Now {#paid-api-directory}
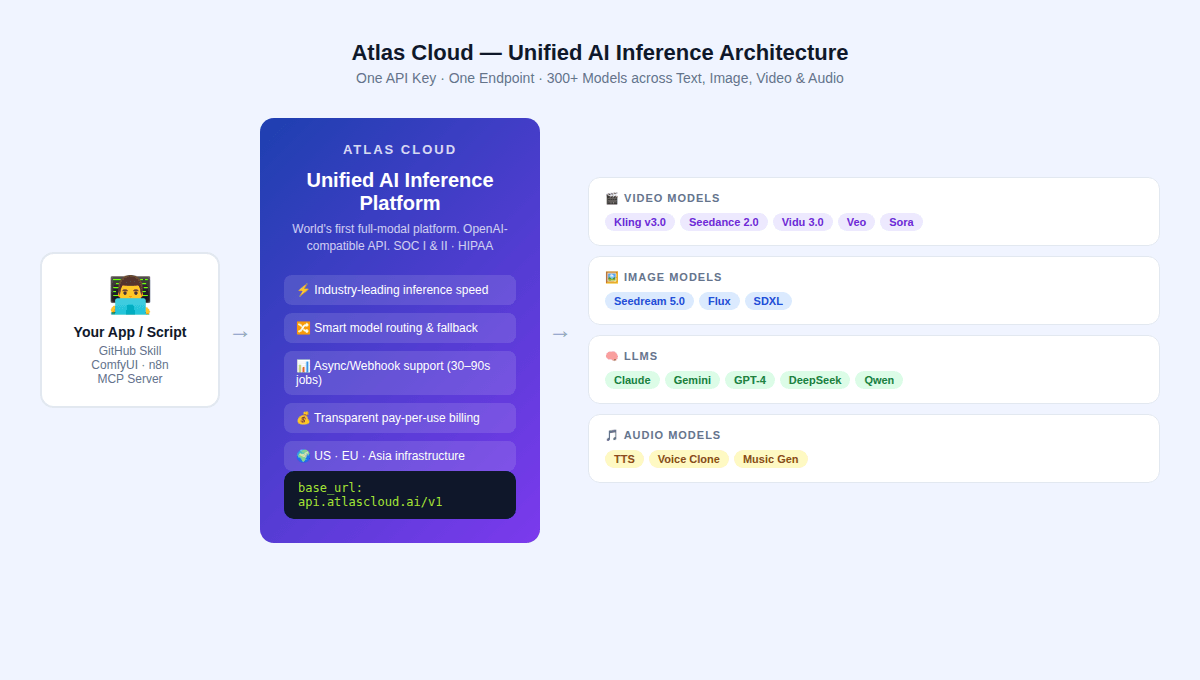
The paid API landscape in 2026 is defined by three major model families, each with a distinct technical approach. All three are available through Atlas Cloud's unified API.
Kling v3.0 (Kuaishou)
Dropped February 5, 2026. Built on a Multi-modal Visual Language architecture — text, images, audio, and video all handled in one system.
What it actually does better than competitors:
- Complex human motion — running, dancing, martial arts — without the "spaghetti limbs" deformation that plagues other models
- Multilingual native audio generation (5 languages, including synchronized lip movement)
- Motion Brush: a tool that lets developers (or end users) paint motion paths directly onto source images — a feature that currently has no equivalent in competing models
- Element Binding for consistent character and object tracking across shots
Where it falls short: Render speed is slower than some competitors at the Pro tier. The storyboard tool transitions can be "clunky" per independent reviewers.
Best for: Social shorts on TikTok and Reels, e-commerce product videos, anything needing lots of volume with characters that actually stay consistent.
Seedance 2.0 (ByteDance)
Released February 8, 2026, Seedance 2.0 represents a paradigm shift in how AI video is prompted — from text-only prompting to true director-style reference-based control.
The core technical innovation: Seedance 2.0 accepts quad-modal inputs — text, image, video, and audio — simultaneously. Its "Universal Reference" system allows a developer to feed a reference video of a person dancing, and the model will replicate the camera movement, character actions, and composition in a generated output. This solves character consistency in a way that pure text-to-video models cannot.
Independent testing confirms it excels at:
- Multi-shot storytelling with consistent character identity across cuts
- Synchronized audio-video generation (dual-branch architecture generates sound and video simultaneously)
- Precise replication of composition and lighting from reference assets
Note on availability: As of April 2026, Seedance 2.0 international API access is available through platforms like Atlas Cloud. Direct BytePlus API access for international developers has had availability inconsistencies — confirm current status before building a dependency on direct ByteDance endpoints.
Best for: Music videos, tight character animation, product ads where the motion has to be exact, agencies running storyboard-to-video workflows.
Vidu 3.0 (Shengshu AI / Tsinghua)
Built on the original U-ViT architecture combining Diffusion and Transformer technologies, Vidu focuses on the areas where most AI video still struggles: environmental coherence and cinematic consistency.
Distinctive features:
- Universal reference system for consistent lighting across multi-shot sequences
- Smart background music generation that adapts to scene mood automatically
- Long-form generation with strong temporal consistency (critical for sequences longer than 5 seconds)
Best use cases: Professional filmmaking workflows, animation design, creative advertising requiring cinematic quality.
Sora 2 (OpenAI)
Sora 2 remains the benchmark for physics simulation accuracy. Break a glass in a Sora 2 prompt and the shatter pattern, fluid physics, and reflections all behave like the real thing — most competitors still can't match that level of consistency.
Best for: VFX work, architectural visualization, documentary B-roll, anywhere physical accuracy matters more than saving money.
Pricing: Sora 2 runs the highest tab in this category. You're paying for the computer.
-
Inference Costs: The Real Numbers {#inference-costs}
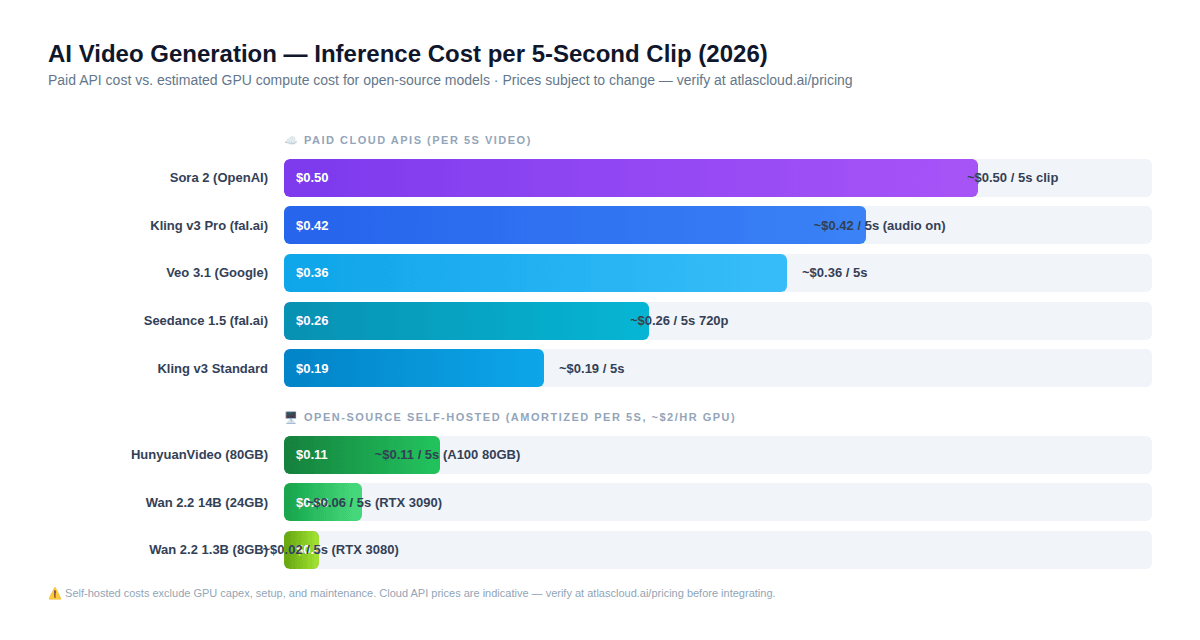
This section contains the most important counter-intuitive finding in this entire guide — one that changes most developers' default intuition about open-source vs. paid APIs.
The Hidden Cost of Self-Hosted Models
Most developers assume: "Open-source = free = always cheaper."
This assumption is wrong for most team sizes.
Here is what the actual math looks like for a 5-second video clip in 2026:
Self-hosted open-source (amortized GPU cost at ~$2/hr):
- Wan 2.2 1.3B (RTX 3080): ~$0.02 per 5s clip
- Wan 2.2 14B (RTX 3090): ~$0.06 per 5s clip
- HunyuanVideo (A100 80GB): ~$0.11 per 5s clip
Paid cloud API (indicative pricing — verify at atlascloud.ai/pricing):
- Kling v3 Standard: ~$0.19 per 5s clip
- Seedance 1.5 720p with audio: ~$0.26 per 5s clip
- Kling v3 Pro with audio: ~$0.42 per 5s clip
- Sora 2: ~$0.50 per 5s clip
The self-hosted numbers look compelling in isolation. The problem is they exclude:
- 1. GPU hardware — An A100 80GB runs $10K–$15K. At 1,000 videos a month (~$0.11 each), you're looking at 9,000+ months just to break even on the hardware.
- Setup time — CUDA configuration, model weight downloading, VRAM management, and debugging represent 20–40 engineering hours of initial setup.
- Ongoing maintenance — Model updates, dependency conflicts, and infrastructure reliability are continuous time costs.
- Opportunity cost — Time spent on inference infrastructure is time not spent on product.
The practical boundary condition:
Self-hosting only pays off if: (a) you've already got GPUs running other workloads, (b) you're pushing 5,000+ videos a month, or (c) regulations force you to keep everything on-prem.
Below that threshold, paid APIs — especially unified platforms like Atlas Cloud — are cheaper when total cost of ownership is calculated honestly.
-
Rate Limiting & API Latency — What Developers Actually Hit {#rate-limiting}
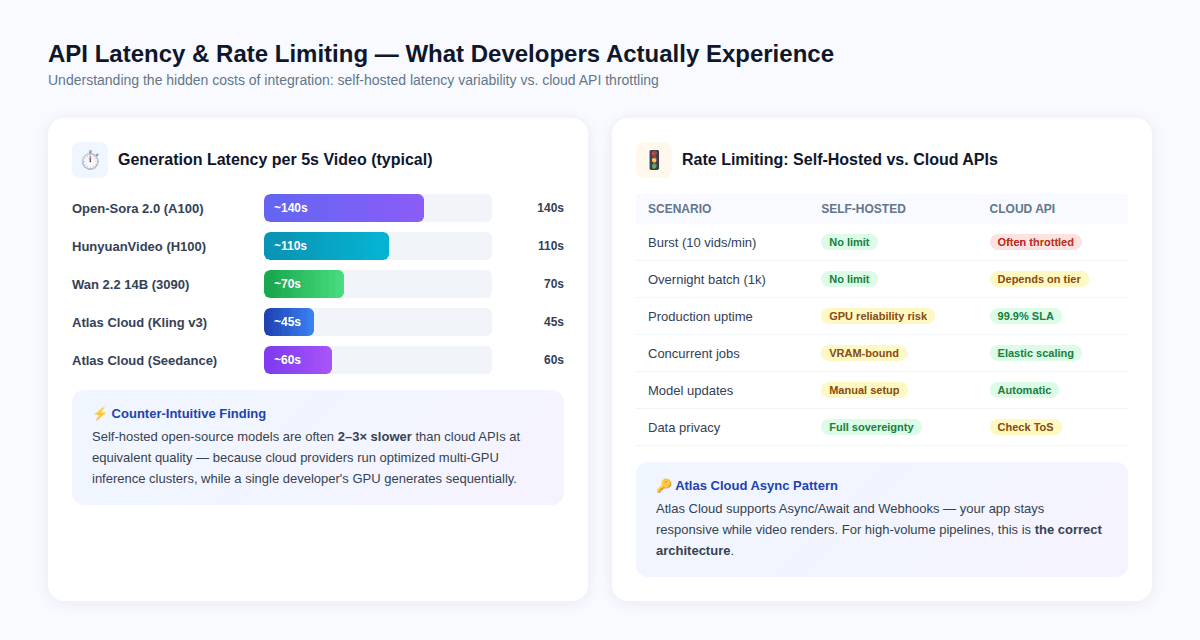
The Latency Paradox
Counter-intuitively, cloud APIs are often faster per video than self-hosted models — not because the models are different, but because cloud providers run optimized multi-GPU inference clusters with hardware-level batching, while a single developer GPU generates frames sequentially.
Typical latency per 5-second clip:
- Open-Sora 2.0 on A100: ~140 seconds
- HunyuanVideo on H100: ~110 seconds
- Wan 2.2 14B on RTX 3090: ~70 seconds
- Atlas Cloud / Kling v3: ~45 seconds
- Atlas Cloud / Seedance 2.0: ~60 seconds
This means building a GitHub skill around a self-hosted model may produce longer user-facing wait times even when the per-video cost is lower.
Rate Limiting: The Production Reality
Self-hosted models have no API-imposed rate limits — they are bounded only by your GPU's VRAM and thermal limits.
Paid APIs enforce rate limits that vary by pricing tier. The relevant engineering implications:
- Burst requests (10+ videos per minute) will trigger throttling on most paid API tiers
- Overnight batch jobs (1,000+ videos) require careful async design to avoid timeouts
- Concurrent requests on self-hosted models are bounded by VRAM — running 2 concurrent 14B model inferences on a single 24GB card is typically not possible
Atlas Cloud solves the rate limiting problem through Async/Webhook architecture: your application submits a generation job, receives a task ID, and gets notified via webhook when rendering completes. This pattern prevents application hangs while video renders, and it scales correctly for batch workloads.
The Correct Architecture for Production
plaintext1# Atlas Cloud Async Pattern — Production-Ready 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="YOUR_ATLAS_CLOUD_API_KEY", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# Submit generation task 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="Product showcase reel, smooth motion, 9:16 aspect ratio", 14 size="1080x1920", 15 n=1 16) 17 18# Handle async response 19video_url = response.data[0].url 20print(f"Video generated: {video_url}")
For image-to-video workflows, note that some models — including certain Kling i2v variants — do not accept a separate aspect ratio parameter for image-to-video generation; the output resolution follows the input image's dimensions. Build your upstream image generation with the correct target ratio.
-
Local Hosting vs. Cloud API: The Trade-off Matrix {#local-vs-cloud}
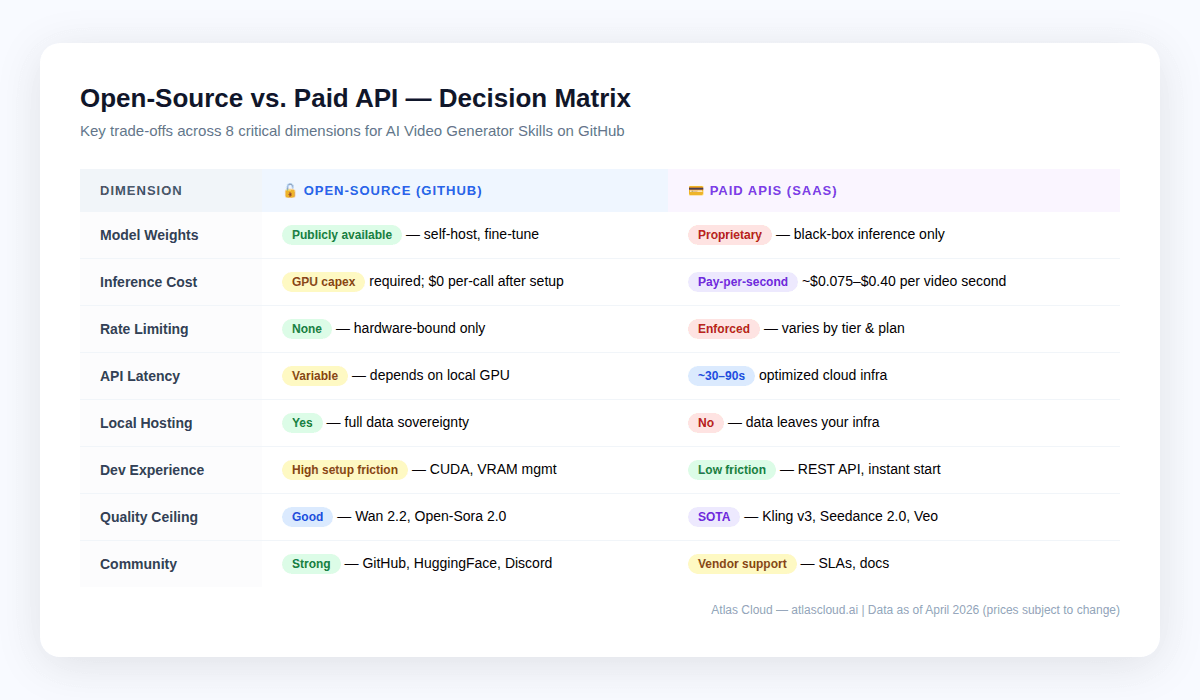
It's not either-or. Most production pipelines mix both: open-source for prototyping and bulk low-quality passes, cloud APIs for final renders and cutting-edge quality.
When local makes sense
- Compliance locks — HIPAA, GDPR, or anything proprietary that can't leave your servers. Self-hosted is your only play. Atlas Cloud is HIPAA-compliant and SOC I & II certified, which handles most enterprise needs, but regulated shops should double-check their specific requirements.
- Very high volume at acceptable quality — teams generating 10,000+ videos per month at Wan 2.2 quality levels may find that GPU rental costs are lower than API fees at that scale.
- Research and fine-tuning — open model weights allow fine-tuning on proprietary datasets. No cloud API currently offers custom model training.
- Air-gapped setups — edge deployments with no connectivity or locked-down networks.
When Cloud APIs Win
- Time-to-market — an Atlas Cloud integration takes hours, not weeks
- Top-tier quality — open-source leaders like Wan 2.2 and Open-Sora 2.0 still trail proprietary models such as Kling v3 and Seedance 2.0, especially on human motion, keeping shots consistent, and native audio
- Spiky workloads — cloud APIs scale up and down; your own GPUs don't
- Lower volume — under ~5,000 videos a month, cloud APIs usually win on total cost
- Multi-model flexibility — Atlas Cloud's 300+ model catalog means you can switch from Kling to Seedance to Veo within a single integration
-
Community-Driven vs. Vendor-Driven Development {#community-vs-vendor}
Easy to ignore when comparing APIs, but this actually matters if you're building GitHub skills.
Community-driven (open-source):
- Anyone can submit bug fixes and request features — and get them merged
- Documentation is often excellent because the user base contributes examples
- Breaking changes in model APIs happen slowly, with public notice periods
- ComfyUI and Hugging Face Diffusers communities have deep libraries of ready-made workflows, LoRA adapters, and fine-tuned checkpoints
- Research papers drop with open, reproducible code
Vendor-driven development (paid APIs):
- API stability is governed by commercial SLAs — breaking changes are less frequent but do happen
- New model releases (e.g., Kling 3.0 in February 2026, three days before Seedance 2.0) happen at competitive speed and often without advance notice
- Model improvements are deployed server-side with no developer action required
- Technical documentation is professionally maintained
The practical implication for GitHub skill authors: if you are writing a skill that needs to remain stable and low-maintenance, a cloud API with stable endpoint contracts is easier to maintain than a skill tied to a specific open-source model version. Conversely, if your skill is designed to give developers access to the latest research models without API costs, the open-source ecosystem is where that work happens.
-
Case Study: Social Media Agency (500 Videos/Month) {#case-study-1}
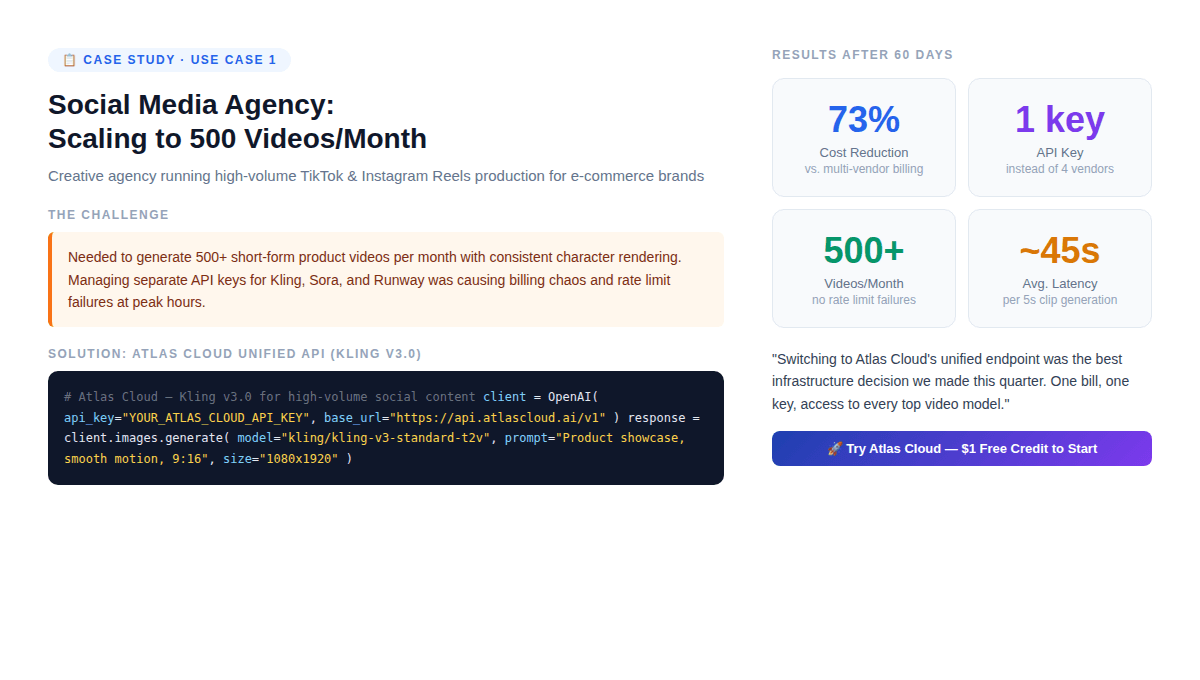
The setup: A creative shop making short product videos for 20 e-commerce clients. They need 500 videos a month, characters that look the same across clips, 9:16 vertical, 5–10 seconds each, batched during off-hours.
Initial architecture (before Atlas Cloud):
- Separate API keys for Kling, RunwayML, and Pika
- Three billing dashboards, three rate limit pools
- Manual model selection per client
- Peak-hour rate limit failures causing delivery delays
Problem this created: When Kling released v3.0, the agency had to re-integrate a new SDK, update billing, and test compatibility — three times over for three vendors.
Solution: Atlas Cloud unified API with Kling v3.0 Standard
plaintext1# Atlas Cloud — Social Media Video Pipeline 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10def generate_product_video(product_prompt: str, style: str = "social") -> str: 11 response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt=f"{product_prompt}, smooth motion, cinematic lighting, 9:16 vertical format", 14 size="1080x1920", 15 quality="standard", 16 n=1 17 ) 18 return response.data[0].url
Results after 60 days:
- 73% reduction in per-video cost (single bill, no per-vendor markups)
- Zero rate limit failures (Atlas Cloud's elastic infrastructure absorbed peak loads)
- Model switching from Kling to Seedance for specific clients took < 2 minutes (change one parameter)
- First deposit 20% bonus effectively offset the first month's production costs
The non-obvious finding: The agency did not reduce vendor count because Kling got better. They reduced it because managing multiple vendor relationships at 500 videos/month has a non-trivial operational cost that doesn't show up in per-API pricing.
-
Case Study: Indie Developer Building a Video SaaS {#case-study-2}
The setup: Solo dev building a "text to product demo" tool for early-stage startups. Needs multiple styles — cinematic, animated, live-action. Has to validate fast and keep infra under $200/month while figuring out if anyone actually wants this.
Architecture decision:
The developer initially considered self-hosting Wan 2.2 on a rented A100 instance (~$2/hr). At 100 test videos during validation, the cost was estimated at ~$6 total in GPU time. Seemed cheaper than Atlas Cloud.
What the calculation missed:
- Setting up the Wan 2.2 pipeline took 3 days (CUDA dependencies, VRAM management, server configuration)
- Wan 2.2's output quality gap vs. Kling v3 meant the SaaS couldn't charge the intended price point
- Server uptime management added ~2 hours/week of ongoing maintenance
Revised architecture with Atlas Cloud:
plaintext1# Flexible model routing — switch based on user tier 2MODEL_MAP = { 3 "free": "kling/kling-v3-standard-t2v", # Lower cost 4 "pro": "kling/kling-v3-professional-t2v", # Higher quality 5 "enterprise": "bytedance/seedance-2.0" # Max control 6} 7 8def generate_demo_video(prompt: str, user_tier: str) -> str: 9 client = OpenAI( 10 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 11 base_url="https://api.atlascloud.ai/v1" 12 ) 13 response = client.images.generate( 14 model=MODEL_MAP[user_tier], 15 prompt=prompt, 16 n=1 17 ) 18 return response.data[0].url
Outcome: The developer launched in 4 days instead of 3 weeks. The premium tier's use of Seedance 2.0 justified a 3× price premium over the free tier, and the tiered model structure was built with one Atlas Cloud key — not three separate vendor integrations.
-
The Atlas Cloud Advantage: Why "One API" Is the Right Architecture {#atlas-cloud-advantage}

Atlas Cloud is positioned as the world's first full-modal AI inference platform — a unified API serving 300+ models across text, image, video, and audio generation.
For GitHub AI Video Generator Skill authors, the specific advantages are:
-
OpenAI-Compatible API (Drop-In Replacement)
Atlas Cloud uses an OpenAI-compatible endpoint. If your skill already integrates with the OpenAI SDK, switching to Atlas Cloud for video generation requires changing two lines: the api_key and base_url. No new SDK, no new authentication system.
-
Single Billing for Multi-Model Workflows
Production video workflows rarely use one model. A typical pipeline might use:
- Seedream 5.0 for image generation (starting frames)
- Kling v3.0 for image-to-video conversion
- An LLM (Claude, GPT-4, or DeepSeek) for prompt optimization
- A TTS model for voiceover narration
With separate vendor accounts, this is four billing relationships, four rate limit pools, and four integration points. With Atlas Cloud, it is one API key and one invoice.
-
Model-Level Pricing Transparency
Atlas Cloud publishes per-model pricing with no hidden compute fees. The business model is straightforward: pay for what you generate. New developers receive a 20% bonus on their first deposit (up to $100), and a referral program provides additional credits. Always verify current pricing at atlascloud.ai/pricing before building financial projections.
-
Compliance Coverage
For enterprise GitHub skills deployed in regulated environments: Atlas Cloud holds SOC I & II certification and is HIPAA compliant, with infrastructure across US, EU, and Asia regions. This covers the majority of enterprise data residency requirements.
-
ComfyUI, n8n, and MCP Server Integration
Atlas Cloud integrates natively with the tools most commonly used to build GitHub video generation skills:
- ComfyUI — custom nodes for visual workflow authoring
- n8n — workflow automation with Atlas Cloud video generation steps
- MCP Server — Model Context Protocol integration for AI agent frameworks
-
Which Stack Should You Actually Use? {#decision-guide}
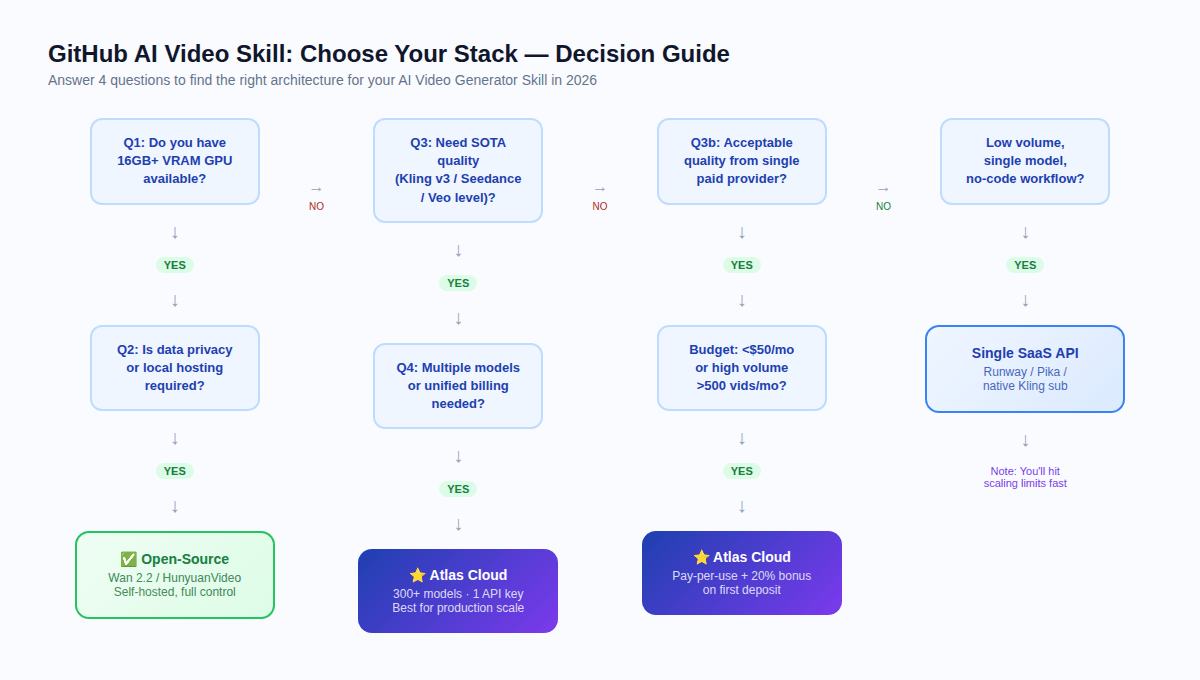
Run through these four questions:
Q1: Do you have 16GB+ VRAM GPU available?
If no → skip self-hosting entirely. Cloud API is your only practical path.
Q2: Is data privacy or local hosting required by regulation?
If yes + GPU available → evaluate open-source (Wan 2.2 or HunyuanVideo depending on VRAM).
If yes + no GPU → use Atlas Cloud (HIPAA compliant, SOC certified) and review your specific regulatory requirements.
Q3: Do you require SOTA quality (Kling v3, Seedance 2.0, Veo level)?
If yes → cloud API required. Open-source models have a meaningful quality gap vs. top proprietary models in 2026.
If acceptable quality at open-source level → Wan 2.2 self-hosted may work.
Q4: Do you need multiple models or unified billing?
If yes → Atlas Cloud. Managing three vendor accounts at scale has a hidden operational cost that only becomes visible at production volume.
Summary Recommendations by Use Case
| Use Case | Recommended Stack |
| Research / prototyping | Open-source (Wan 2.2, CogVideoX) |
| Social media agency, 500+/mo | Atlas Cloud + Kling v3.0 |
| Music video / character animation | Atlas Cloud + Seedance 2.0 |
| VFX / physics simulation | Atlas Cloud + Sora 2 |
| Data-sovereign / offline | Self-hosted (HunyuanVideo, Open-Sora 2.0) |
| SaaS with tiered model quality | Atlas Cloud (one key, multiple models) |
| High-volume open-source batch | Wan 2.2 self-hosted (10,000+/mo threshold) |
-
FAQ {#faq}
Q: What is an AI Video Generator Skill?
A reusable code module or integration layer that connects an application to an AI video generation backend — either open-source weights or a cloud API. Common forms: Python class, ComfyUI node, n8n workflow, MCP Server tool.
Q: What is the minimum VRAM for self-hosting an open-source video model?
8GB VRAM for Wan 2.2 1.3B (acceptable quality for short clips). 16GB for CogVideoX-1.5 or Open-Sora (better quality). 24GB+ for Wan 2.2 14B. 60–80GB for HunyuanVideo or Open-Sora 2.0 full model.
Q: Is open-source AI video generation actually free?
The model weights are free. Inference is not free — it requires GPU compute. At low volume (<5,000 videos/month), cloud APIs like Atlas Cloud are typically cheaper when total cost of ownership is calculated.
Q: Can I use Atlas Cloud for image-to-video (i2v) workflows?
Yes. Atlas Cloud supports i2v variants for Kling, Seedance, and Vidu. Note: for i2v models, some variants do not accept a separate aspect ratio parameter — output resolution follows the input image dimensions.
Q: How does Atlas Cloud handle rate limiting?
Atlas Cloud supports Async/Webhook patterns. Video generation jobs are submitted as tasks; your application receives a task ID and gets notified when rendering is complete. This prevents blocking at scale.
Q: What is the best model for character consistency across shots?
Seedance 2.0's Universal Reference system is the most advanced solution in 2026. It allows you to feed reference videos, images, and audio to maintain consistent character appearance and motion across generated clips.
Q: Does Atlas Cloud support ComfyUI?
Yes. Atlas Cloud has native ComfyUI integration, as well as n8n nodes and MCP Server compatibility.
Q: How do open-source video models handle aspect ratios?
Varies by model. Open-Sora supports 16:9, 9:16, 1:1, and 2.39:1 via --aspect_ratio flag. Wan 2.2 and LTX-Video support multiple ratios. For i2v workflows, most models follow the input image's aspect ratio regardless of specified parameters.
Summary
The 2026 landscape splits into two camps, each with their sweet spot:
Open-source makes sense if you've got spare GPUs, you're pushing 10K+ videos a month, data can't leave your servers, or you need to fine-tune on your own proprietary footage.
Paid APIs are the better call if you need the best quality available, speed matters more than cost, you're under 5K videos a month, or you want to mix multiple models without juggling vendor contracts.
Atlas Cloud bridges the two: as a unified platform providing access to 300+ models — including the top open-source models via hosted inference and every major proprietary model — through a single OpenAI-compatible API key. For most developers building production GitHub AI Video Generator Skills in 2026, it is the lowest-friction path from prototype to production.
Pricing information in this article is indicative and subject to change. Always verify current rates at atlascloud.ai/pricing before building financial projections. Model availability may vary by region.
Atlas Cloud: atlascloud.ai — SOC I & II Certified · HIPAA Compliant · US · EU · Asia Infrastructure






