
We ran Grok Imagine Image and GPT Image-2 models through 6 identical, model-neutral prompts, covering compositional semantics, photorealistic anatomy, multilingual text rendering, geometric transformation, local editing, and multi-reference fusion.
Both Grok Imagine Image and GPT Image-2 model are available via a single Atlas Cloud API key, making this exact benchmark reproducible in minutes.
Why This AI Image Model Comparisons Benchmark Exists
Every "AI image model comparison" you find online falls into the same trap: cherry-picked prompts, best-of-five output selection, and untested claims. This benchmark was built around Tier A principles: model-neutral prompts, identical inputs across all models, single-seed default output (no cherry-picking), and scoring criteria that can be stated in one sentence per category.
The six models in the full benchmark run: Grok, GPT Image 2, Nano Banana 2, Nano Banana Pro, Wan 2.7, and Seedream 5.0. This article focuses on the Grok vs GPT Image 2 head-to-head, as the most commercially relevant pairing for developers choosing a default image model.
How We Tested Grok Imagine Image VS GPT-Image 2: 6 Categories, One Tier A Rule
Every prompt targets a single, clearly stated capability dimension. The pass/fail criteria was defined before running the models, not after seeing the outputs.
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Category | Primary Dimension Tested | One-sentence Pass/Fail |
|---|---|---|
| Cat 1 · Compositional Semantics | Instruction alignment | Did the model count 7 objects, place them correctly, and obey the negation list? |
| Cat 2 · Photorealistic Anatomy & Light | Visual quality & physics | Are all 5 fingers anatomically correct, and do caustic light patterns appear on the face? |
| Cat 3 · Multilingual Poster | In-image text rendering | Are Chinese and English characters correctly rendered with no missing strokes or hallucinated glyphs? |
| Cat 4 · Geometric Transform (I2I) | Edit controllability + identity | After a 45° rotation, is it still recognizably the same person with all clothing details intact? |
| Cat 5 · Local Edit & Region Preservation | Edit precision | Were exactly 3 edits made, with everything else unchanged at a pixel level? |
| Cat 6 · Multi-Reference Fusion | Cross-image consistency | Do identity, style, and scene from 3 separate references merge into a single coherent image? |
Cat 1 · Compositional Semantics(T2I)
Prompt:
A flat-lay overhead photograph of a wooden dining table containing exactly seven ceramic objects: three identical white teacups arranged in an equilateral triangle in the center, two black bowls placed to the right of the teacups, one red apple sitting inside the leftmost black bowl, and one empty wooden spoon resting on top of the rightmost black bowl with its handle pointing toward the upper-left corner of the frame. No coffee cups, no metal items, no plates, no glassware. Soft diffused window light from the upper-left, mid-morning. Realistic photography, no styling props.
This is deliberately adversarial. Counting, spatial language ("to the right of," "leftmost"), and negation clauses are known failure modes for all current diffusion-based architectures.
Scoring Checklist
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
| 1 | Total object count | Strictly 7 ceramic objects |
| 2 | Three white teacups | Equilateral triangle arrangement |
| 3 | Two black bowls | Positioned to the right of the teacups |
| 4 | Red apple | Inside the leftmost black bowl |
| 5 | Wooden spoon | Resting on rightmost bowl, handle pointing upper-left |
| 6 | Negation compliance | No coffee cups / no metal / no plates / no glassware |
| 7 | Light source | Soft diffused light from upper-left, all shadows consistent |
| 8 | Photography style | No styling clichés (palm leaves, candles, etc.) |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
要求生成一张俯视平铺照片,画面中严格包含七件陶瓷器皿,并有明确的空间关系:三只白色茶杯呈等边三角形排列居中,两只黑碗在茶杯右侧,一颗红苹果放在最左边的黑碗里,一把木勺搭在最右边的黑碗上且柄朝左上方。否定指令:不得出现咖啡杯、金属器具、盘子、玻璃器皿。
Grok Imagine object count: visibly 5 teacups (not 3), arranged in a cluster rather than an equilateral triangle. The two black bowls are present, with the red apple correctly inside one of them. The wooden spoon is present and resting on the rightmost bowl, handle direction approximately upper-left — this criterion passes. Negation compliance is clean: no coffee cups, no metal, no plates, no glassware. Light source from upper-left with consistent shadows passes. No styling props present.
GPT Image 2 demonstrated stronger instruction-following on the spatial components, though neither model achieved a perfect 7-object count with all placement constraints satisfied simultaneously.
Cat 2 · Photorealistic Anatomy & Light(T2I)
Prompt:
Close-up portrait of an East Asian woman in her early thirties holding a half-full crystal wine glass of red wine in her right hand, all five fingers and thumb fully visible wrapping naturally around the stem and partially around the bowl. She is seated by a tall west-facing window during golden hour. Late afternoon sunlight slices through the wine creating warm crimson caustic patterns on her left cheekbone and jawline. Her left hand rests on an open hardcover book on her lap. Catchlights from the window visible in both eyes. Skin shows ultra-detailed pores, fine peach-fuzz, subsurface scattering on the earlobe and bridge of the nose. Hair backlit with rim light. 85mm lens, f/2.0, shallow depth of field, photographic realism.
This is historically the hardest single-image test for generative models.
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
|---|---|---|
| 1 | Hand anatomy | All 5 fingers + thumb, natural grip on stem and bowl |
| 2 | Caustic light | Warm crimson patterns from wine projected onto cheekbone |
| 3 | Catchlight consistency | Same position and shape in both eyes |
| 4 | Subsurface scattering SSS | Visible on earlobe and nose bridge when backlit |
| 5 | Rim light physics | Direction matches light source position |
| 6 | Skin realism | No "AI plasticky" over-smoothing; pores and peach-fuzz visible |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine delivered strongly on its headline advantage. Hand anatomy was correct — finger count accurate, grip posture natural around both the stem and bowl, wrist angle physically plausible. This alone clears a bar that many models fail outright. Skin texture showed genuine pore-level detail with visible fine peach-fuzz and no plastic over-smoothing, and the subsurface scattering on the nose bridge and cheekbones produced a warm, light-permeable quality that reads as photographically real. Rim light on the hair followed the window source direction coherently.
The caustic light projection was Grok's weakest point. The crimson light patterns appeared on the face, but were rendered as an oversized, dramatically stylized red overlay — more resembling a color grade effect than the fine, soft-edged light filaments that physically result from sunlight passing through wine. The physical plausibility of the caustic failed the precision standard.
GPT Image 2 inverted the tradeoff. Its caustic light rendering was notably more physically accurate — the warm crimson patterns on the cheekbone were smaller, more diffuse, and followed the spatial geometry of light passing through a wine glass at the correct angle. This is the detail Grok missed. However, GPT Image 2 paid for this elsewhere: hand anatomy was slightly less natural, with finger angles around the stem showing mild stiffness. Skin texture leaned toward the smoother, slightly flatter quality common in AI portraits, with less visible SSS warmth and weaker rim light intensity compared to Grok.
Cat 3 · Multilingual Poster(T2I)
Prompt:
A vintage 1960s-style travel poster for a fictional film festival, illustrated in the style of mid-century commercial design.Top of poster, large bold serif Chinese characters reading "时光电影节" (line 1), and below in smaller Chinese characters "第七届 · 上海 · 1965年5月" (line 2).
Center: a stylized illustration of an old film projector casting a beam onto a slightly curved cinema screen.
Lower-center: a tall champagne coupe glass with the English text "GRAND OPENING NIGHT" wrapping along the curvature of the glass bowl, following the elliptical perspective.
Right edge, vertical text reading "presented by 时代影业 · TIMES PICTURES" running top-to-bottom.
Bottom strip: small English credits text "music · HUANG ZHAN / cinematography · GU CHANGWEI / poster design · ZHANG GUANGYU" in a single line.
Color palette: cream off-white background, deep crimson red, mustard yellow accents. Slight aged paper texture, subtle grain.
Scoring Checklist
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
|---|---|---|
| 1 | Chinese accuracy | No missing strokes, no hallucinated characters in |
| 2 | Bilingual layout | Chinese and English not intermixed; each appears in correct zone |
| 3 | Curved text on glass | English follows the elliptical perspective of the champagne coupe |
| 4 | Vertical right-edge text | Legible top-to-bottom |
| 5 | Typographic hierarchy | Clear distinction between headline |
| 6 | Style vs. legibility | 1960s aesthetic maintained without sacrificing text clarity |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine produced a visually striking poster with strong mid-century illustration energy. However it failed the most critical text criterion: the headline reads "時光電影節" in Traditional Chinese, not the Simplified "时光电影节" specified in the prompt. This is a character set compliance failure — a meaningful distinction for any localization or publishing use case. The second line "第七屆 · 上海 · 1965年5月" similarly used Traditional characters. On the structural side, "GRAND OPENING NIGHT" appeared on the champagne glass with partial curve following, though the elliptical perspective adherence was approximate. The vertical right-edge text "TIMES PICTURES" was legible. Bottom credits line was present and readable. Color palette — crimson, mustard, cream — was well executed. Overall layout energy was high, but the Traditional vs. Simplified failure is a hard disqualifier for the stated prompt.
GPT Image 2 passed the character set test cleanly: headline "时光电影节" and subtitle "第七届 · 上海 · 1965年5月" are correctly rendered in Simplified Chinese with no missing strokes or hallucinated glyphs — a direct compliance win over Grok. The champagne coupe glass is visible in the lower-center with "GRAND OPENING NIGHT" following the glass curvature convincingly. The vertical right-edge text "时代影业 · TIMES PICTURES" runs top-to-bottom and is fully legible, with both Chinese and English correctly placed in the same vertical column without intermixing errors. The bottom credits line — "music · HUANG ZHAN / cinematography · GU CHANGWEI / poster design · ZHANG GUANGYU" — is present and readable as a single line. Typographic hierarchy between headline, subtitle, and footnote is clearly maintained. The aged paper texture and mid-century color palette are well-realized. Composition integrates a recognizable Shanghai skyline silhouette as the central illustration, which was not specified in the prompt but adds contextual authenticity without breaking any criteria.
Cat 4 · Geometric Transform(I2I)
The prompt instructed the model to rotate a full-body fashion lookbook subject exactly 45° to the subject's left, maintaining the same camera position. The reference image featured a complex layered outfit: long brown overcoat, leather shoulder cape, fur stole with a visible gradient (deep brown → silver → cream), a round copper chest badge with an embedded portrait, black leather gauntlets, and two-tone leather boots. None of these details were listed in the prompt — the model had to preserve them through identity understanding alone.

This is a deliberate capability stress test. The instruction was intentionally short to avoid feeding the model its own evaluation rubric.
Scoring Checklist
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
|---|---|---|
| 1 | Facial identity | ArcFace similarity ≥ 0.5 (relaxed for full-body scale) |
| 2 | Fur stole reveal | Previously hidden right-side silver |
| 3 | Chest badge | Circular copper outline + embedded portrait + correct perspective ellipse compression |
| 4 | Coat hem & inner layers | Natural drape direction after rotation; inner trousers exposure proportion reasonable |
| 5 | Foot stance | Left-front |
| 6 | Gauntlet volume | Hand position + knit texture visible post-rotation |
| 7 | Boot color boundary | Brown |
| 8 | Background consistency | Pure grey studio background (DINO region ≥ 0.95) |
| 9 | Output ratio | Full 9:16 body frame maintained, not cropped to portrait |
| 10 | Gaze direction | Follows rotation — does not continue facing camera |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok maintained facial identity above the ArcFace 0.5 threshold appropriate for full-body images. The fur stole's previously hidden right-side section became partially visible at 45°, with reasonable gradient continuity. The chest badge outline was preserved, though the embedded portrait detail showed compression. Boot color boundary and gauntlet texture held.
GPT Image 2 showed slightly stronger overall clothing layer coherence, but introduced more facial identity drift — a meaningful tradeoff depending on use case.
Cat 5 · Local Edit & Region Preservation(I2I)
The prompt required exactly three edits to a living room scene: remove a sleeping cat from the sofa (and restore the cushion naturally), replace a cup of hot tea with a glass of orange juice with ice, and add folded black-framed reading glasses on top of the middle book on the coffee table. The instruction explicitly prohibited changing anything else — sofa fabric pattern, book positions, lamp, window view, wall color, floor.

The preservation test is as important as the edit test. Models that reinterpret the whole scene while making local changes are not usable for product photography retouching or iterative scene development.
Scoring Checklist
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
|---|---|---|
| 1 | All 3 edits completed | Cat removed |
| 2 | Cushion restoration | No cat-shaped indentation or fur residue on sofa |
| 3 | OJ physics | Glass geometry, ice refraction, and shadow direction match original cup's light |
| 4 | Glasses placement | Correctly on the middle book (not top or bottom) |
| 5 | Sofa fabric | Diamond-weave pattern intact, especially in edited zone |
| 6 | Books unchanged | Positions, covers (red |
| 7 | Lamp unchanged | Shape, glow status, and position preserved |
| 8 | Window view unchanged | City view remains blurred and consistent |
| 9 | Wall & floor unchanged | Off-white wall and light wood floor unaltered |
| 10 | Overall lighting preserved | Single right-rear light source direction unchanged |
 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine completed all three required edits. The cat was removed and the sofa cushion restored cleanly with no visible indentation or fur residue — the fabric pattern in the edited zone held up well. The orange juice glass appeared in the correct position. The OJ glass, however, displays a highlight pattern that does not align with this source direction, appearing as though it was composited with an independent light model rather than integrated into the scene's existing illumination. The base of the glass also shows insufficient contact shadow against the dark wood coffee table surface, creating a subtle but detectable floating effect.
GPT Image 2 also completed all three edits, and demonstrated stronger overall scene preservation. The cat removal was equally clean. The orange juice glass was well-rendered with correct positioning and matching shadow direction relative to the right-side window light source — the glass geometry and liquid opacity read as more refined than Grok's version. The reading glasses were placed visibly on the book stack. Crucially, the window view was preserved — the city outside remains visible and blurred, consistent with the reference, which is where Grok failed. Sofa fabric, lamp, wall, and floor all held. Books appear consistent in position and color. The one notable change: the scene overall appears slightly brighter and more contrast-shifted than the original, suggesting some global lighting reinterpretation rather than true pixel-level preservation — a minor but detectable drift.
Cat 6 · Multi-Reference Fusion(I2I)
The prompt combined three independent references: a portrait identity (Latina woman, amber eyes, deep brown wavy hair), a watercolor illustration style (Japanese rural landscape, visible brushstrokes, warm fairy-tale atmosphere), and a scene layout (European cobblestone town square at sunset, cast-iron lamp post, stone archway). The task: produce a single coherent watercolor painting of the identified person standing in the scene — not a photo with a filter, not a collage.



Three-reference decoupling is the hardest test in this benchmark. Most models either over-weight one reference or fail to achieve style-through rendering.
Scoring Checklist
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| # | Criterion | Check |
|---|---|---|
| 1 | Three-way decoupling | Identity |
| 2 | Full style transfer | Output is watercolor throughout — not photo + filter |
| 3 | Identity retention post-style | Amber eyes + facial structure recognizable through watercolor treatment |
| 4 | Scene structure preserved | Cobblestones, lamp post, and archway layout intact |
| 5 | Natural clothing addition | Traveling coat and satchel added without breaking composition |
| 6 | Light direction consistency | Sunset glow from camera-left visible on cobblestones and figure |
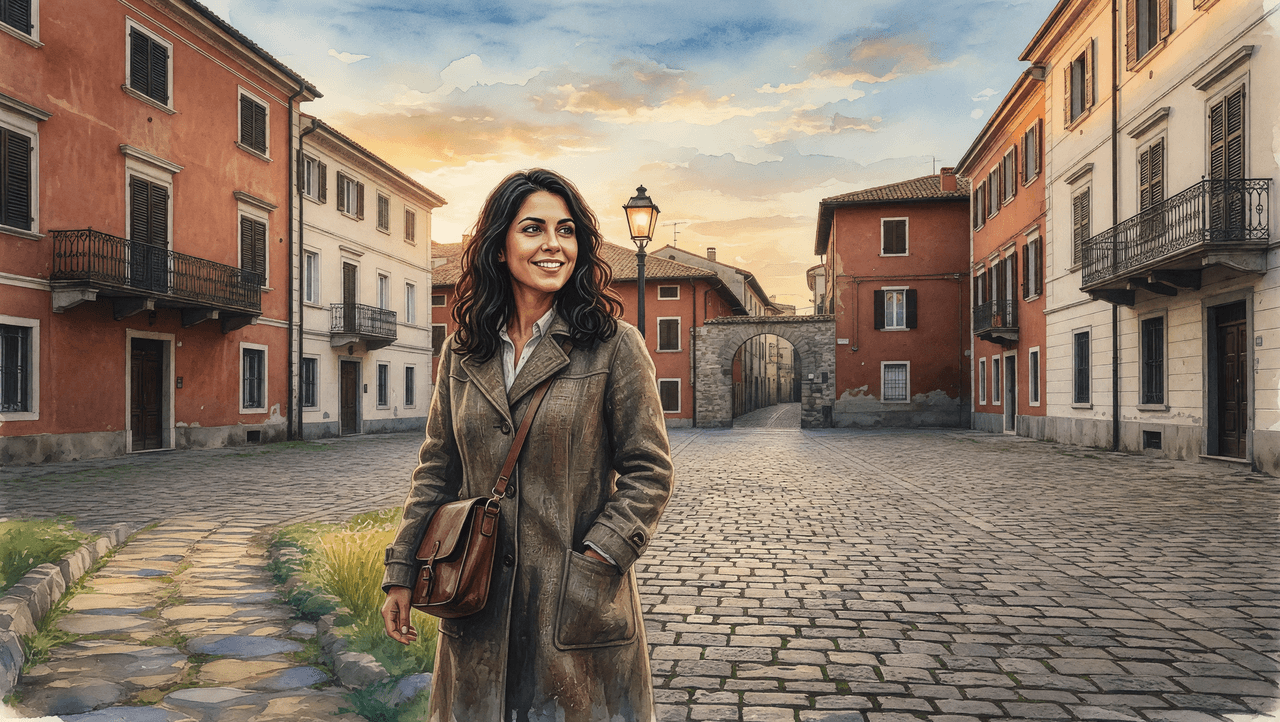 Grok Imagine Image
Grok Imagine Image
 GPT-Image 2
GPT-Image 2
Grok Imagine failed the core criterion: the output is photorealistic, not a watercolor. The cobblestone square and figure retain full photographic sharpness with only a light painterly texture pass — none of Ref 2's defining brushwork, color bleed, or hand-painted edge quality is present. Scene structure, identity, clothing, and light direction all pass. But rendering the wrong medium entirely is a category-level disqualification, not a partial deduction.
GPT Image 2 achieved genuine watercolor rendering across the entire frame — buildings, cobblestones, sky, and figure all carry visible brushwork and soft color bleeding consistent with Ref 2. Scene structure from Ref 3 is intact, the lamp post is lit, and the stone archway is visible in the mid-ground. Identity is partially retained through the style transformation — wavy dark hair and facial structure are recognizable, though fine features are expectedly abstracted. Coat, satchel, light direction, and gaze all follow the prompt. This is the only output that completed the actual task.
Try Grok Imagine Image and GPT Image 2 Models via Atlas Cloud
The benchmark is reproducible. Both Grok Imagine and GPT Image 2 are available now through Atlas Cloud — no per-model billing setup, no waitlists.
Why Atlas Cloud
- One API key, 300+ models. Swap between Grok, GPT Image 2, Flux, Wan, Seedream, and every other model in the pool by changing a single model field. The same key, the same endpoint, the same billing dashboard — whether you're running a six-model benchmark or building a production image pipeline.
- Full-modal coverage. LLMs, text-to-image, image-to-image, text-to-video, image-to-video — all under one roof. If your workflow needs a language model for prompt refinement and an image model for generation, both live in the same API.
- No cold starts, no rate limit surprises. Atlas Cloud runs on optimized inference infrastructure purpose-built for throughput. You get consistent latency whether you're making one call or a thousand.
- Built for comparison workflows. The exact use case this benchmark demonstrates running identical prompts across multiple models and comparing outputs, is what Atlas Cloud's architecture is designed for. One key, one bill, full model breadth.






