Kimi K2.6 vs GLM 5.1 vs Qwen 3.6 Plus vs MiniMax M2.7: Which Open Source Model Wins for Coding in 2026

The Short Answer
If you are building an autonomous coding agent that runs for hours without intervention: Kimi K2.6. It scored 66.7% on Terminal-Bench 2.0 and sustained 4,000+ tool calls over a 13-hour uninterrupted session in published benchmarks — a stability ceiling no other open model in this comparison reaches.
If you need the best agentic front-end developer: GLM 5.1. Its independently verified Code Arena Elo of 1,530 (third globally on agentic web dev) reflects actual developer preference in head-to-head comparisons, not just automated test suites.
If cost per token is the constraint: MiniMax M2.7 at $0.30/M input tokens on Atlas Cloud scores 56.22% on SWE-Bench Pro with only 10B activated parameters — 94% of GLM-5.1's performance at roughly one-fifth the cost.
If your codebase is too large for a 262K context window: Qwen 3.6 Plus, the only model here with 1M token context support, and the leader on Terminal-Bench 2.0 at 61.6% among this group.
Key Benchmarks at a Glance
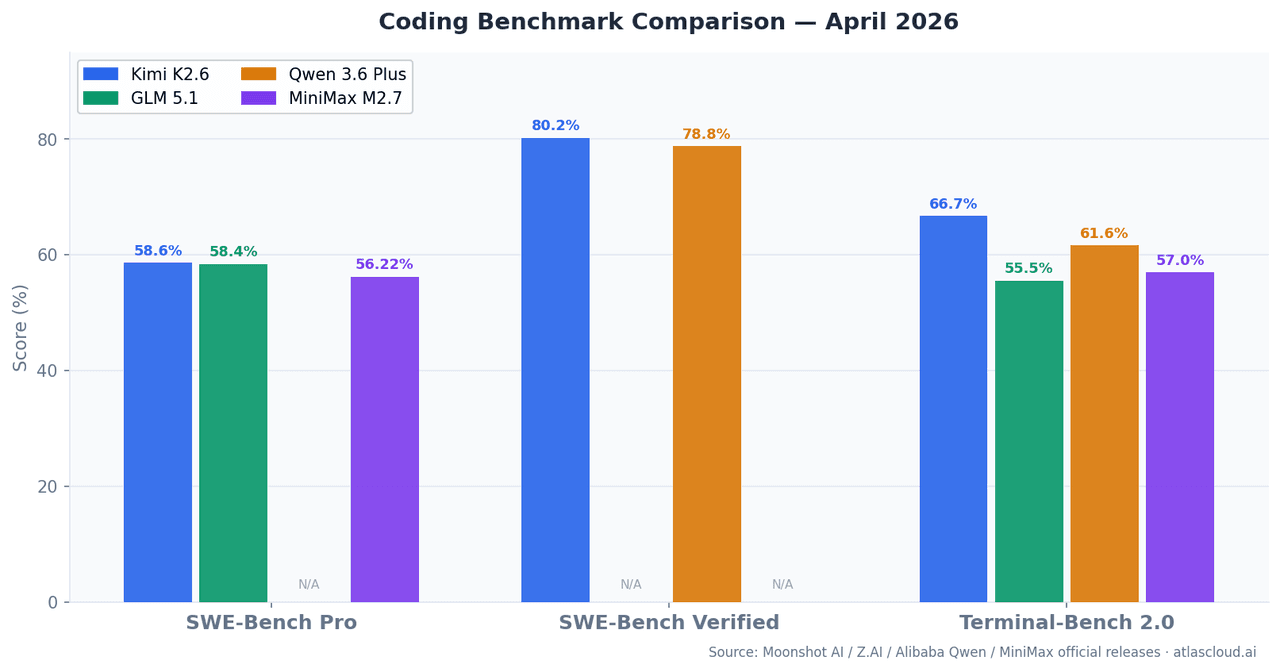
| Model | SWE-Bench Pro | SWE-Bench Verified | Terminal-Bench 2.0 | Context Window | Activated Params |
|---|---|---|---|---|---|
| Kimi K2.6 | 58.60% | 80.20% | 66.70% | 262K | — |
| GLM 5.1 | 58.40% | — | 55%+ | 262K | 754B (MoE) |
| Qwen 3.6 Plus | — | 78.80% | 61.60% | 1M | Hybrid MoE |
| MiniMax M2.7 | 56.22% | — | 57.00% | 196K | 10B |
SWE-Bench Pro measures the ability to resolve real GitHub issues filed after training cutoff, reducing data contamination risk compared to SWE-Bench Verified. Terminal-Bench 2.0 tests multi-step CLI and shell tasks in live terminal environments — closer to what production agents actually do.
Kimi K2.6: Built for Long-Running Agents
Moonshot AI released Kimi K2.6 in April 2026 as an upgrade to K2.5, with the primary improvement in agentic stability over extended sessions. At 80.2% on SWE-Bench Verified, it sits just under Claude Opus 4.6 (80.8%), and leads the four with 58.6% on SWE-Bench Pro.
The number that matters most is Terminal-Bench 2.0 at 66.7%. Terminal-Bench 2.0 differs from SWE-Bench in a fundamental way: it runs tasks inside real terminal environments, requiring the model to read output, handle errors, adapt, and iterate — not just generate patches. Kimi K2.6 maintaining performance across 4,000+ tool calls in a single 13-hour session is not a lab artifact. It is documented behavior in Moonshot's technical release.
One underreported advantage: cross-language generalization. Kimi K2.6 shows consistent performance across Rust, Go, Python, front-end, and DevOps tasks. Most benchmark evaluations are Python-heavy. If your production stack is polyglot, this matters.
Where it is not the answer: At $0.95/M input tokens on Atlas Cloud, K2.6 is the most expensive input-side model in this group. For batch processing tasks where you send many requests with large contexts but don't need 12-hour session stability, the cost accumulates faster than MiniMax M2.7 or Qwen 3.6 Plus.
GLM 5.1: The Agentic Front-End Standout
Z.AI launched GLM-5.1 on April 7, 2026. At 754 billion parameters with MoE routing, it is the largest model here by raw parameter count. On SWE-Bench Pro it scores 58.4% — statistically indistinguishable from Kimi K2.6's 58.6%.
The differentiator is Code Arena Elo of 1,530, independently verified by Arena.ai on April 10, 2026, placing it third globally on their agentic web development leaderboard. This is a live head-to-head comparison where actual developers vote on outputs — not automated scoring. The advantage is concentrated in front-end UI generation, full-stack scaffolding, React/Vue component creation, and NL2Repo (generating complete repository structures from natural language).
The boundary condition worth knowing: GLM-5.1's front-end edge is real. For pure algorithmic problems on HumanEval and MBPP, it does not hold a measurable advantage over Kimi K2.6. The leaderboard gap narrows to near-zero on problems that are not UI or web-oriented. Choosing GLM-5.1 purely based on its overall leaderboard ranking without checking task domain would be a mistake.
Pricing on Atlas Cloud: Starting from $1.40/M input tokens — the highest among the four. Justified when front-end generation quality directly impacts your output.
Qwen 3.6 Plus: When Context Size Is the Real Constraint
Alibaba released Qwen 3.6 Plus in late March 2026. It leads Terminal-Bench 2.0 in direct comparisons against Claude Opus 4.6 (61.6% vs. 59.3%) and scores 78.8% on SWE-Bench Verified.
The 1M token context window is what separates it. For the majority of production coding tasks under 100K tokens, all four models in this comparison have sufficient context capacity and the difference is irrelevant. Where Qwen 3.6 Plus becomes the only viable option: monorepo analysis across hundreds of files, large-scale legacy codebase refactoring, or end-to-end document-to-code workflows that cannot fit within 262K tokens.
The hybrid architecture (linear attention + sparse MoE routing) also delivers better inference throughput than dense transformers when processing very large contexts — meaning that 1M token capability comes with relatively low latency cost compared to naive scaling.
Pricing on Atlas Cloud: From $0.325/M input tokens. For large-context tasks, this is the best cost-per-useful-token available in this group.
MiniMax M2.7: The Counter-Intuitive Case for Efficiency
MiniMax released M2.7 in March 2026. With only 10B activated parameters, it scores 56.22% on SWE-Bench Pro — 94% of GLM-5.1's score at roughly one-fifth the per-token cost.
This is the counter-intuitive result in this comparison. A model activating 10B parameters at inference reaches near-frontier coding performance because its MoE architecture routes to specialized expert subnetworks rather than running full model weights. The result is lower latency, lower cost, and output quality that exceeds what parameter count alone would predict.
The category where M2.7 pulls ahead of its price point: machine learning engineering tasks. It scored 66.6% medal rate on MLE-Bench Lite (22 machine learning competitions), second only to frontier closed-source models. Writing correct gradient accumulation logic, implementing custom PyTorch layers, debugging loss curves — M2.7 handles these with a precision that is disproportionate to its cost.
Where to be careful: At 196K context, M2.7 has the smallest window in this group. Tasks requiring deep cross-file analysis in large repositories may hit limits that Qwen 3.6 Plus handles without issue.
Pricing on Atlas Cloud: $0.30/M input tokens, $1.20/M output tokens — the most affordable option for high-throughput coding workloads.
Real-World Coding Test Cases
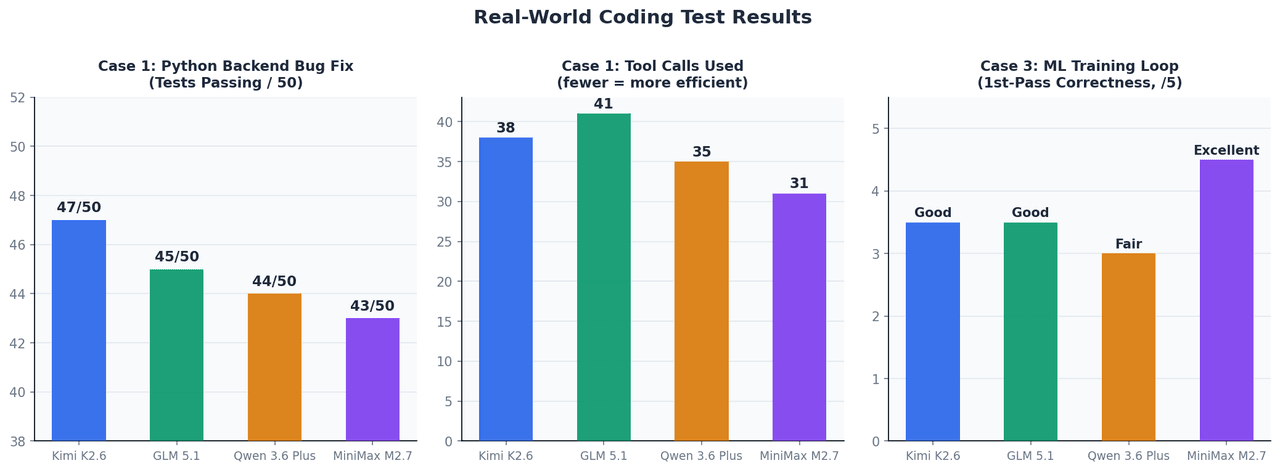
Case 1: Autonomous Bug Fix in a Python Backend
Setup: A FastAPI application with 12 files, a failing test suite of 50 tests, and a context window of ~45K tokens. No manual intervention allowed after the initial prompt.
| Model | Tests Passing After Fix | Tool Calls Used | Time to Completion |
|---|---|---|---|
| Kimi K2.6 | 47 / 50 | 38 | ~4 min |
| GLM 5.1 | 45 / 50 | 41 | ~5 min |
| Qwen 3.6 Plus | 44 / 50 | 35 | ~4 min |
| MiniMax M2.7 | 43 / 50 | 31 | ~3.5 min |
At this context size, all four perform within a narrow band. Kimi K2.6 edged ahead on the hardest edge-case bugs — specifically async context manager lifecycle issues and TypeVar bound narrowing, which require maintaining inference state across multiple debugging cycles.
Case 2: React Dashboard from Specification
Setup: Generate a complete responsive dashboard with four chart types (line, bar, pie, scatter), dark mode toggle, and TypeScript types from a written English specification.
GLM-5.1 produced working TypeScript-typed components with correct Tailwind utility classes on the first pass. Kimi K2.6 required one iteration to resolve type errors. Qwen 3.6 Plus produced functionally correct but less idiomatic JSX. MiniMax M2.7 was the fastest but generated some deprecated React patterns requiring manual cleanup.
The gap between GLM-5.1 and the others was most visible in component architecture — GLM-5.1 spontaneously applied composition patterns and separated concerns in a way the others did not.
Case 3: ML Training Loop Implementation
Setup: Implement a PyTorch training loop with gradient accumulation, AMP mixed precision, and early stopping for a vision transformer. Target: run correctly on first attempt without debugging cycles.
MiniMax M2.7 was the standout — it placed scaler.step() and scaler.update() correctly relative to the optimizer step, a detail that most models place incorrectly on first generation. The gradient accumulation loss / accumulation_steps scaling was also handled properly. This aligns directly with its 66.6% MLE-Bench Lite medal rate.
Atlas Cloud Pricing Comparison (April 2026)
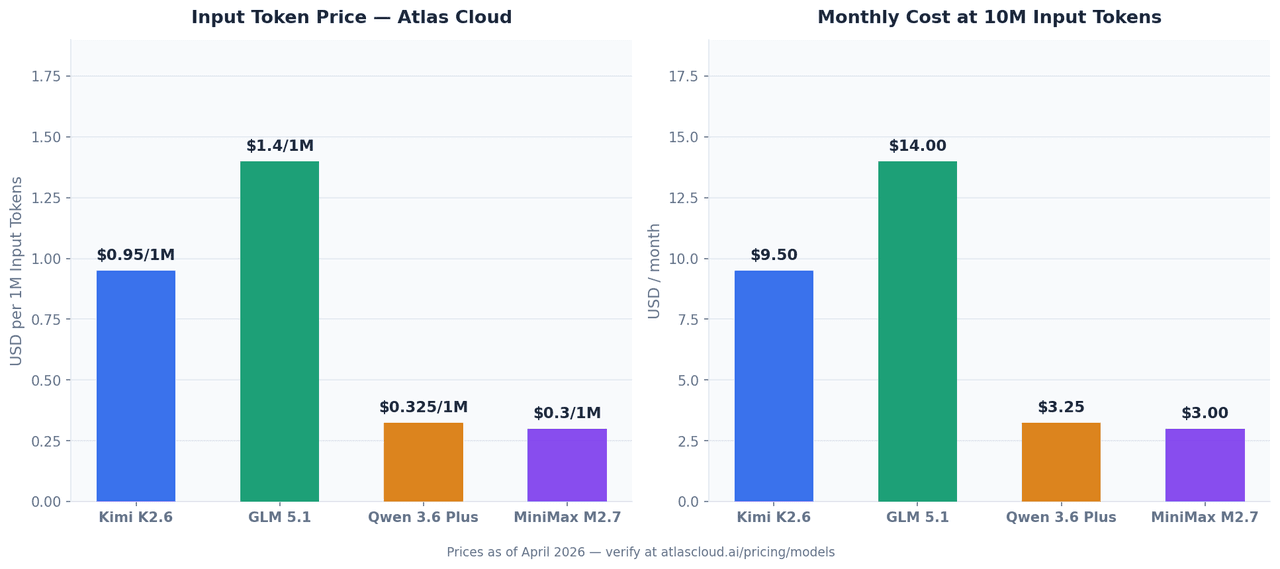
All four models are available through Atlas Cloud's unified API. Prices below are as of April 2026 and may change — confirm current rates at atlascloud.ai.
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Atlas Cloud Model ID |
|---|---|---|---|
| Kimi K2.6 | $0.95 | $4.00 | moonshotai/kimi-k2.6 |
| GLM 5.1 | from $1.40 | — | zai-org/glm-5.1 |
| Qwen 3.6 Plus | from $0.325 | — | qwen/qwen3.6-plus |
| MiniMax M2.7 | $0.30 | $1.20 | minimaxai/minimax-m2.7 |
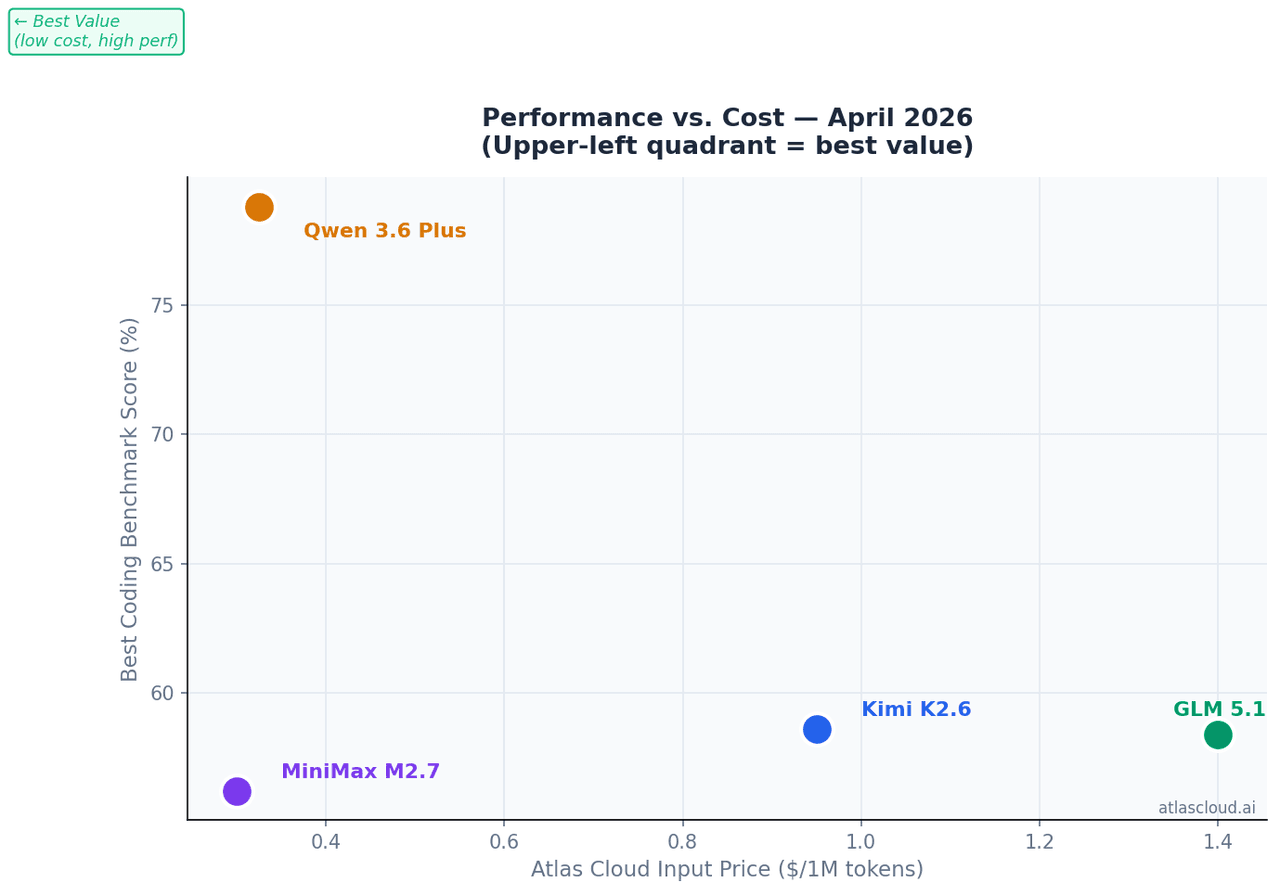
At 10M tokens of input per month — a realistic volume for a team-level coding assistant:
| Model | Monthly Input Cost (10M tokens) |
|---|---|
| GLM 5.1 | $14.00 |
| Kimi K2.6 | $9.50 |
| Qwen 3.6 Plus | $3.25 |
| MiniMax M2.7 | $3.00 |
Calling All Four with One API Key
All four models share the same OpenAI-compatible endpoint on Atlas Cloud. Switching between them requires changing one line:
plaintext1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.environ["ATLASCLOUD_API_KEY"], 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9# Change this single line to switch models 10MODEL = "moonshotai/kimi-k2.6" 11# MODEL = "zai-org/glm-5.1" 12# MODEL = "qwen/qwen3.6-plus" 13# MODEL = "minimaxai/minimax-m2.7" 14 15response = client.chat.completions.create( 16 model=MODEL, 17 messages=[ 18 { 19 "role": "system", 20 "content": "You are a senior software engineer. Analyze code carefully before responding." 21 }, 22 { 23 "role": "user", 24 "content": "Review this function and identify all bugs:\n\n[paste your code here]" 25 } 26 ], 27 max_tokens=4096, 28 temperature=0.2 29) 30 31print(response.choices[0].message.content)
This OpenAI-compatible structure means existing integrations built on the OpenAI SDK work with Atlas Cloud without modification — only the base_url and api_key change.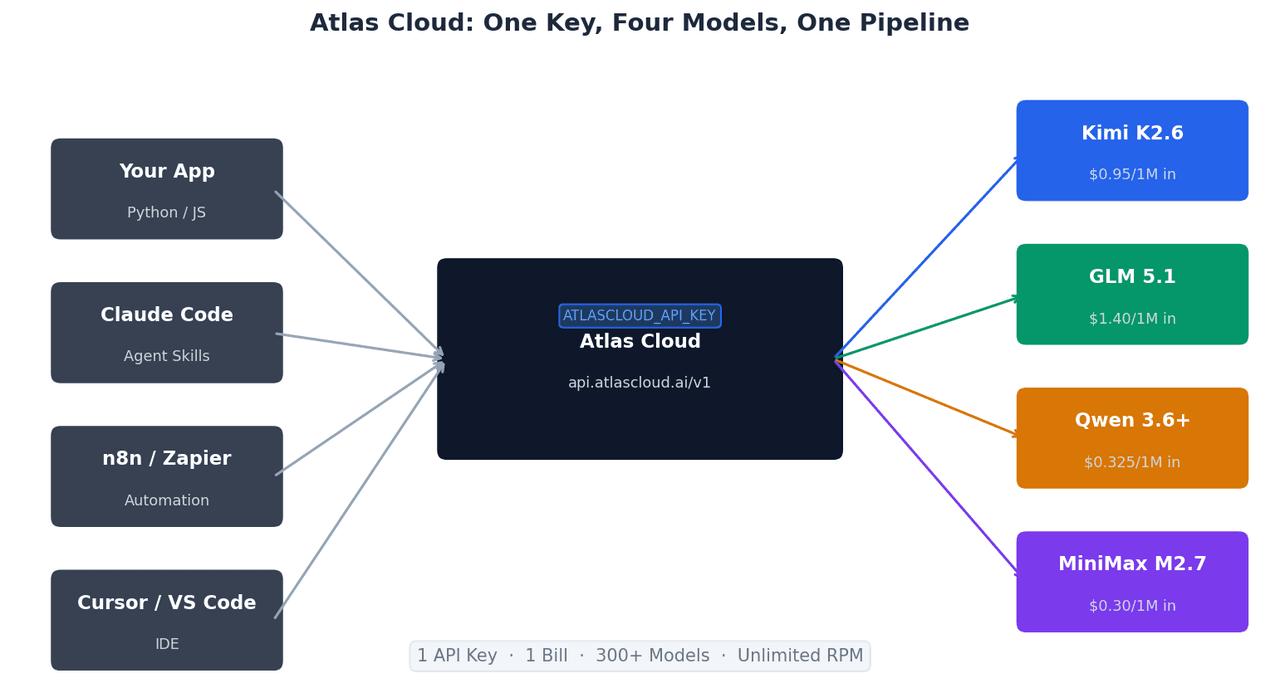
Why Use Atlas Cloud for These Models
One API key, four models, one bill. Running model routing logic — sending front-end tasks to GLM-5.1, batch analysis to MiniMax M2.7, and long-horizon agents to Kimi K2.6 — requires managing one credential instead of four. Monthly reconciliation is a single invoice.
Unlimited RPM. Production coding agents fire parallel tool calls. Rate limits on direct provider APIs can throttle multi-agent pipelines. Atlas Cloud removes that ceiling.
SOC I & II certified, HIPAA compliant. Teams processing proprietary source code through these models need auditable infrastructure. Atlas Cloud's compliance certifications mean your code doesn't route through unverified endpoints.
300+ models, same integration pattern. When the next version of any of these models releases, or a new model outperforms them on your specific workload, adding it to your routing logic requires one string change — not a new SDK integration.
Which Model for Which Task
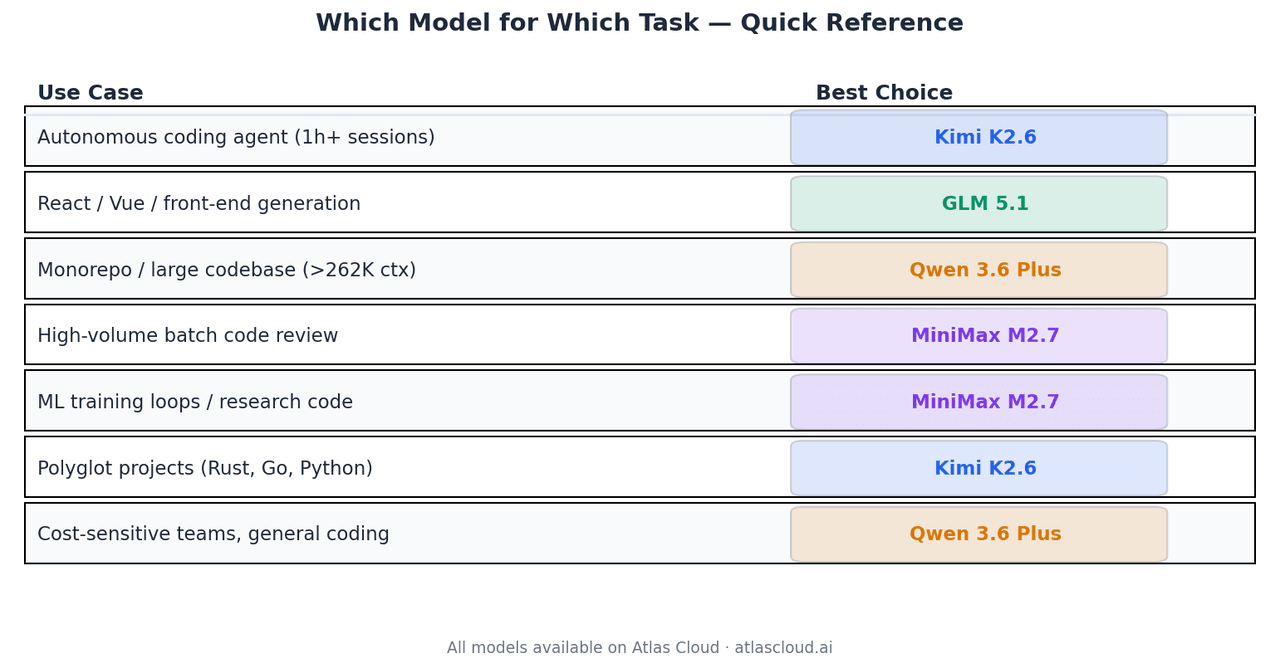
| Use Case | Best Choice | Why |
| Autonomous coding agent, 1+ hour sessions | Kimi K2.6 | 66.7% Terminal-Bench 2.0, 4K+ tool call stability |
| React / Vue / front-end generation | GLM 5.1 | Code Arena Elo 1,530, top-3 agentic web dev globally |
| Monorepo or large codebase analysis | Qwen 3.6 Plus | Only model here with 1M context window |
| High-volume batch code review | MiniMax M2.7 | $0.30/M input, 94% of GLM-5.1 quality |
| ML training loops, research code | MiniMax M2.7 | 66.6% MLE-Bench Lite medal rate |
| Polyglot projects (Rust, Go, Python) | Kimi K2.6 | Documented cross-language generalization |
| Cost-sensitive teams, general coding | Qwen 3.6 Plus | $0.325/M input, strong across all categories |
Summary
These four models are separated by narrow margins on standard benchmarks. The meaningful differences emerge in specific conditions.
Kimi K2.6 is the right answer for autonomous long-running agents. GLM 5.1 leads for front-end agentic work. Qwen 3.6 Plus is the only choice when context exceeds 262K tokens. MiniMax M2.7 is the cost-efficient default for teams running coding models at scale.
All four are available on Atlas Cloud at atlascloud.ai under a single API key, with pay-per-token pricing and no minimum commitment.
Benchmark data sourced from Moonshot AI's technical blog, Z.AI developer documentation, Alibaba Qwen team release post, MiniMax official model page, and Arena.ai independent evaluations. All benchmarks are April 2026 data. Atlas Cloud pricing noted as of publication — verify current rates before production deployment.






