Abstract: GLM-5-Turbo, developed by Zhipu AI (Z.ai), is a large language model designed for OpenClaw use cases and the company’s first closed-source release (previously tested under the codename Pony-Alpha-2), and is set to launch soon on Atlas Cloud.
The model delivers significant improvements in tool use, instruction execution, multi-step workflows, and long-horizon task handling, while supporting a context window of up to 200K tokens. Its data analysis capabilities are comparable to Claude Opus 4.6, and it outperforms GLM-5 in automation and information-processing tasks. Leveraging Atlas Cloud’s unified API and multi-model ecosystem, GLM-5-Turbo enables efficient deployment across complex business automation, long-document analysis, and software development, offering a cost-effective and easily integrable AI solution for developers and enterprises.
We are excited to announce that GLM-5-Turbo is coming to Atlas Cloud!
- What is GLM-5-Turbo: Developed by Zhipu AI (Z.ai), GLM-5-Turbo is a large language model tailored for OpenClaw use cases. It marks the team’s first closed-source release, offering higher runtime efficiency than GLM-5 at a lower cost per call. Prior to this, Zhipu AI had informally tested its next-generation model under the codename Pony-Alpha-2.
- Core features: GLM-5-Turbo delivers substantial improvements in tool use, instruction following, multi-step workflows, and persistent task execution. It supports dynamic reasoning modes across scenarios, real-time streaming output, enhanced tool integration, and long-context handling of up to 200K tokens.
- Release Date: 2026.3.24.
GLM-5 previously drew attention as the top-performing open-source model on the Artificial Analysis Intelligence Index, surpassing Gemini 3 Pro. As its successor, GLM-5-Turbo introduces a series of iterative upgrades, detailed below.
Core Positioning: A ClawBench-Optimized Model
Strong Benchmark Performance
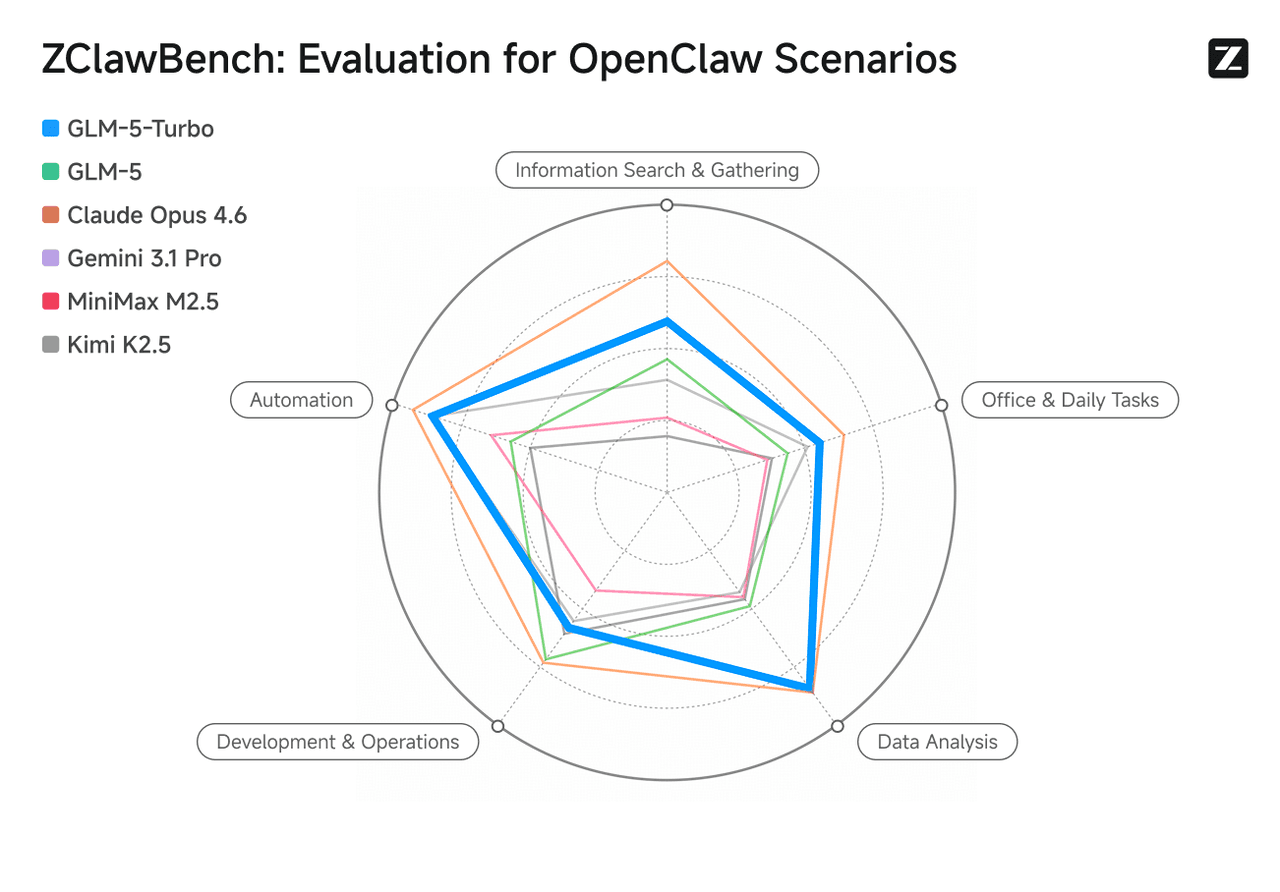
Optimized for OpenClaw scenarios, GLM-5-Turbo significantly enhances capabilities in tool invocation, instruction execution, and complex task orchestration. Its data analysis performance is on par with Claude Opus 4.6, while surpassing GLM-5 in automation, information retrieval, office productivity, and analytical tasks.
Image source: Zhipu AI (Z.ai) official website.
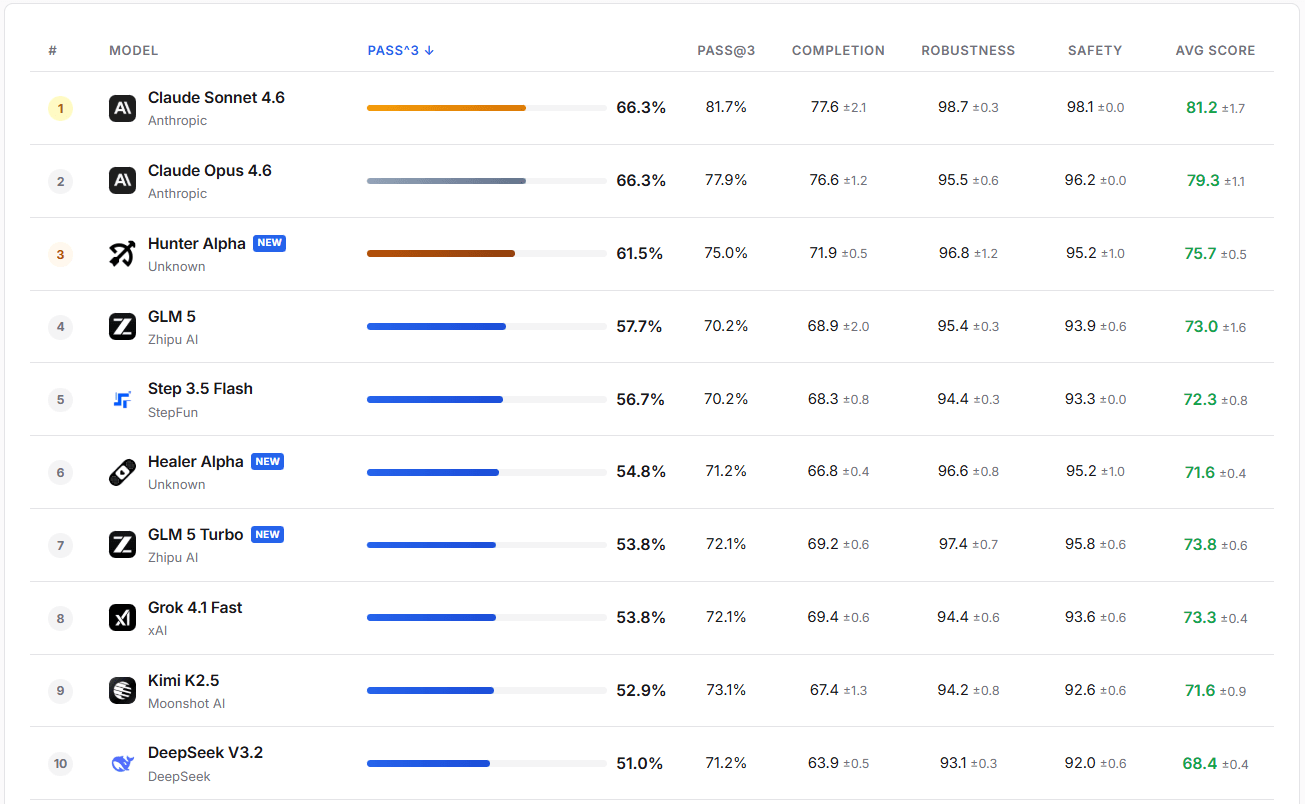
In practical evaluations, GLM-5-Turbo demonstrates high robustness and safety. Its PASS@3 success rate exceeds that of GLM-5, Step 3.5 Flash, and Kimi K2.5.
Image source: https://claw-eval.github.io/
Enhanced Tool Use and External Integration
Z.ai has strengthened GLM-5-Turbo’s agentic capabilities during training, enabling seamless interaction with external tools. This execution-first orientation comes with trade-offs: some users report a slightly more mechanical tone compared to GLM-5 in role-playing scenarios.
To accommodate varying strengths across models, Atlas Cloud provides a unified interface that allows users to query multiple models simultaneously, enabling side-by-side comparison and selection.
Additionally, users can define custom skills or allow GLM-5-Turbo to autonomously discover and install them.
Image source: Atlas Cloud

Long-Horizon Autonomous Execution
GLM-5-Turbo is optimized for tasks requiring scheduled triggers or extended runtimes. It handles persistent, multi-stage, and cross-temporal workflows with strong task continuity.
The model proactively suggests execution strategies based on task complexity. In comparative testing on code optimization, GLM-5-Turbo produced recommendations that outperformed competing models in approximately 10% of cases.
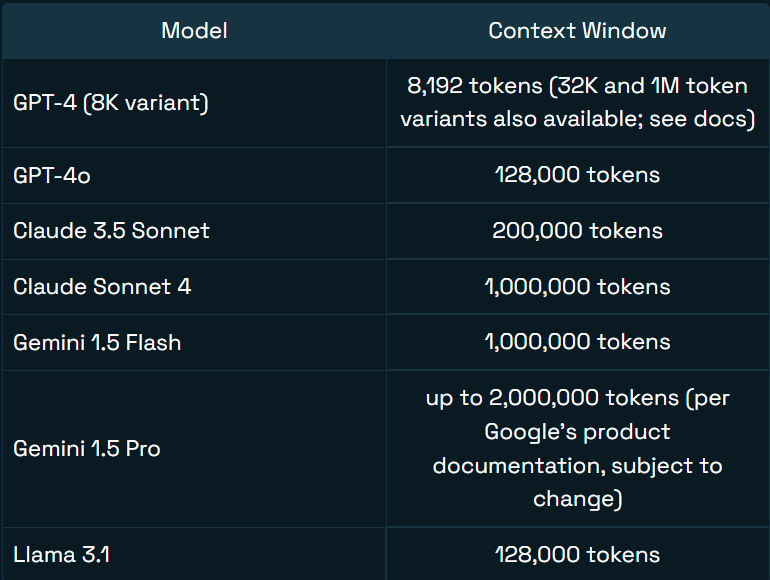
200K-Token Context Window
With support for up to 200K tokens (roughly 133,000 English words), GLM-5-Turbo can retain and utilize extensive context within a single session. This enables accurate retrieval of earlier information even in later stages of a conversation.
Image source: Jim Allen Wallace (Redis)
Use Cases
Automating Complex Workflows
With its enhanced OpenClaw capabilities, GLM-5-Turbo can decompose complex business processes, identify underlying logic, and autonomously locate or generate the necessary skills to execute tasks.
For example, in short-form video production, the model can search for, install, and orchestrate writing, image generation, and video production tools—planning and executing the entire workflow end-to-end.
Long-Document QA and Deep Analysis
The model maintains full context across long documents within a single session, enabling accurate multi-turn question answering. Its high token efficiency ensures fast responses with lower computational cost.
In large-scale codebases, GLM-5-Turbo can analyze architectural design, map dependencies across components, and flag potential cascading effects from low-level code changes.
“Vibe Coding”
Within the software development lifecycle, GLM-5-Turbo functions more like a full-stack engineer embedded in complex workflows. Developers can outline high-level logic while the model incrementally builds application architecture in real time.
Combined with multimodal skills, users can upload UI images, screen recordings, or sketches, which the model can directly convert into functional frontend components.
Why Use GLM-5-Turbo on Atlas Cloud?
As an all-modal AI infrastructure platform, Atlas Cloud provides users with a unified API interface. Once connected, users can easily unlock over 300 advanced AI models including generating text, images, video, or multi-modal models.
Target Audience
- Independent Developers seeking low-cost, simplified solutions to call various AI models.
- Enterprises requiring stable, secure, and scalable infrastructure to support core business.
- Development Teams needing to efficiently integrate multiple cross-modal models into projects.
- Workflow Users who prioritize toolchain compatibility and use ComfyUI or n8n.
Product Features
- Greatly Simplified Integration: The platform provides an OpenAI-compatible API, instantly simplifying the developer's workload. No more juggling multiple vendor keys or stressing over maintenance costs across platforms.
- Cost Advantage: Compared to competitors, Atlas Cloud has lower deployment costs. Nano Banana 2 costs $0.056/image (competitor: $0.07/image); Veo 3.1 is priced at $0.09/second (competitor: $0.1/second). Additionally, the Playground interface offers full price transparency, with the "Run" button directly labeling the deduction amount per image or second of video.
- Enterprise-Grade Stability & Support: Atlas Cloud ensures data protection meets strict privacy standards and can tackle sensitive information.
- Plug-and-Play Friendly: Built to work effortlessly with tools like ComfyUI and n8n, helping businesses cut down on switching costs and hit the ground running.
Comparison with Similar Products
- Fal.ai: While they offer some models, Atlas Cloud provides a wider selection (300+), more competitive pricing, and new registered users receive a $1 trial credit.
- Wavespeed: Pricing is significantly higher. Atlas Cloud offers additional enterprise compliance support and expert technical guidance that Wavespeed does not emphasize.
- Kie.ai: Uses an opaque credit system. Atlas Cloud displays the exact cost for every run directly on the interface. The model count is also higher than Kie.ai.
- Replicate: Focuses on model hosting. Atlas Cloud’s advantages lie in API unification, the speed of model deployment, and more developer-friendly support policies.
- OpenAI or Google: These vendors only provide their own models. Users with cross-modal needs usually need to integrate multiple services. Atlas Cloud integrates proprietary and open-source models under one API, reducing system complexity.
How to Use GLM-5-Turbo on Atlas Cloud?
Method 1: Use directly on the platform
Method 2: Use via API integration
Step 1: Get your API Key. Create and paste your API key in the console:


Step 2: Consult the API Docs. Check request parameters, authentication methods, etc.
Step 3: Make your first request (Python Example)
GLM-5 as example.
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
FAQ
What is the difference between GLM-5-Turbo and GLM-5? GLM-5-Turbo is faster and more cost-efficient, with significantly improved token efficiency—reportedly up to three times that of GLM-5. It is also specifically optimized for OpenClaw scenarios.
How does GLM-5-Turbo compare to MiniMax M2.7? Both models are optimized for agentic tool use and feature higher token efficiency than GLM-5. Each supports context windows of around 200K tokens (MiniMax M2.7 supports 196,608 tokens). We are preparing a blog post for further comparative evaluation. Stay tuned!
Which GLM model is recommended for OpenClaw deployment? GLM-5-Turbo, as it is specifically optimized for OpenClaw scenarios and achieves data analysis performance comparable to Claude Opus 4.6.






