
Google Nano Banana 2 Lite (known as the gemini-3.1-flash-lite-image API endpoint) is a small, fast AI tool made for quick app setups. It is the most affordable Google image API you can buy. It turns text into pictures in just 4 seconds, so it works perfectly for big business apps that need tons of images fast.

Waiting for hundreds of automated image generation queues to clear is an exhausting bottleneck for developers building highly concurrent applications. When your platform needs to dynamically render thousands of localized ad variations, user avatars, or quick web mockups on the fly, relying on premium creative models quickly spikes your production costs and stalls user experience. High latency and steep per-image fees often force development teams to choose between application speed and their monthly operational budget.
Google addresses this friction with its latest addition to its creative model line. By separating performance tiers based on explicit workload demands, developers can now optimize high-velocity asset pipelines without paying a premium for unnecessary rendering capabilities. The solution lies in a specialized, lightweight image generation model designed directly for rapid-fire programmatic deployment.
Meeting the Demand for the Cheapest Google Image API
For engineering teams running high-volume visual workflows, traditional image generation APIs present a major fiscal challenge. Paying several cents per image becomes unsustainable when scaling to millions of automated API calls. This economic hurdle has intensified the demand for a true cheapest Google image API capable of handling bulk requests without introducing immense infrastructure overhead.
The rollout of the gemini-3.1-flash-lite-image model changes the architecture of programmatic image generation by shifting the economic floor. Instead of treating every visual request as a premium artistic asset, this architecture treats high-velocity image generation as a raw utility. This allows software engineers to embed fluid, real-time image creation directly into multi-tenant apps, and interactive social software where cost efficiency is the leading operational metric.
Deep Dive Into Nano Banana 2 Lite Performance Benchmarks
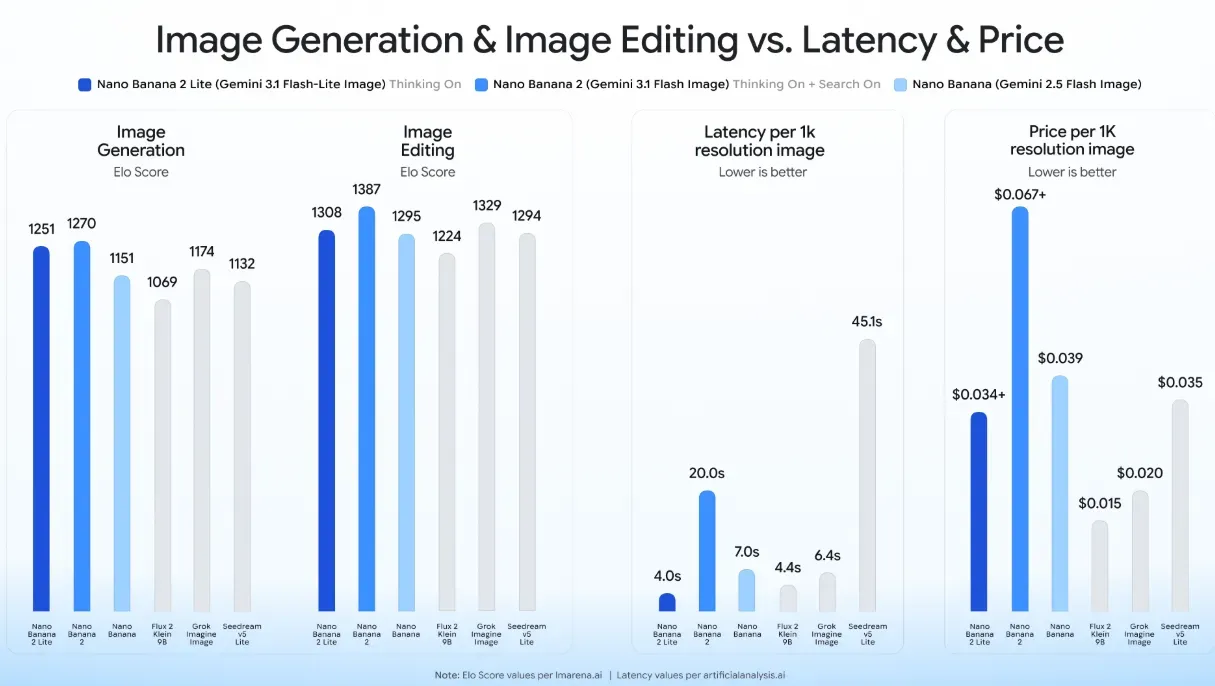
The commercial designation for this efficiency-first model tier is the Nano Banana 2 Lite. This model is engineered with a strict focus on maximizing processing throughput and minimizing response overhead. Real-world testing and official specifications verify that the model achieves text-to-image generation latency in as little as 4 seconds. This rapid turnaround represents an approximate 5x speedup over standard model tiers, transforming the developer workflow from an asynchronous, queue-based operation into a synchronous, near-real-time user experience.
Nano Banana 2 Lite Performance Metrics
| Parameter Dimension | Official Specification / Metric | Notes & Operational Paradigm |
| Supported Modalities | Input: Text, Image, Video; Output: Text, Image | Audio is not supported; Video is input-only. |
| Context Window Limits | Max Input: 65,536 tokens; Max Output: 4,096 tokens | Optimized for high-frequency, rapid-fire application logic. |
| Core Capabilities | Image generation, Interleaved images/text, Edit images, Multi-turn image editing | Image generation from video input is not supported. |
| Output Resolution | Strictly 1K (Roughly 1 Megapixel) | Consumes exactly 1,120 output image tokens per 1K generation. |
| Supported Aspect Ratios | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | Perfectly covers standard e-commerce, social media, and banner layouts. |
| Per-Prompt Constraints | Max Input Images: 14 images per prompt;Max Output Images: Limited to 32,768 output tokens | File count is ultimately bounded by the 65,536 token context window. |
| Multimodal Token Cost | Input Image: 1,120 tokens/image; Input Video: 70 tokens/second (sampled at 1 fps) | Additional charges apply for text input and output modalities. |
| Concurrency Safeguards | Provisioned Throughput is Supported | Crucial for enterprise platforms to guarantee 4-second latency under peak loads. |
The performance gains of the Nano Banana 2 Lite over legacy models are rooted in substantial architectural updates. When compared to the older, legacy gemini-2.5-flash-image model, the new Lite variant offers specific technical advancements:
- World Knowledge Integration: The model displays a highly accurate contextual understanding of locations, physical structures, and abstract spatial layouts, making it highly effective for rapid UI/UX wireframing.
- Character Consistency: It maintains stable character identities and structural object details across sequential generations. This allows engineers to build iterative storyboarding software or programmatic virtual try-on features for e-commerce platforms.
- Inline Typography and Localization: The system renders legible, clean text directly into generated graphics. This allows developers to construct automated ad variants tailored to different geographic markets instantly.
Decoding Nano Banana 2 Lite API Pricing and Token Mechanics
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Standard Price ( (/1M tokens) <= 200K input tokens) |
| Input (text, image, video) | $0.25 |
| Text output (response and reasoning) | $1.50 |
| Image Output | $30 |
Understanding your operational costs requires looking closely at the underlying token structure rather than relying on broad marketing averages. While standard industry promotion lists a flat rate of approximately $0.034 per 1,000 images, Google's actual billing structure relies on a precise multimodal token infrastructure. The specific paid-tier developer rates for Nano Banana 2 Lite API pricing are split across distinct transaction mechanics.
Under standard paid-tier usage via Google AI Studio or the Gemini Enterprise Agent Platform, text, image, or video inputs cost exactly $0.25 per 1 million tokens. Output text and structural reasoning tokens are billed at $1.50 per 1 million tokens. When generating a standard 1K-resolution image (~1 megapixel), the system processes a fixed output payload equivalent to $30.00 per 1 million image output tokens. This maps directly to an exact per-image cost of $0.0336.
Furthermore, engineers can implement massive budget optimizations by utilizing asynchronous batch execution. Google offers a flat 50% discount for non-urgent, batched requests processed within a 24-hour window. This drops the cost of a 1K-resolution image down to a remarkable $0.0168, making it the definitive choice for background asset generation.
Side-by-Side Architectural Comparison: Google's Creative Model Family
To select the most efficient model for your production stack, it is helpful to contrast the performance and cost structures across Google's entire creative image lineup. Each model variant targets a different operational threshold, requiring developers to match their specific application requirements to the proper API endpoint.
| Metric / Feature | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
| API Model ID | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| Input Token Price | $0.25 / 1M tokens | $0.50 / 1M tokens | $2.00 / 1M tokens |
| Output Image Token Price | $30.00 / 1M tokens | $60.00 / 1M tokens | $120.00 / 1M tokens |
| Standard 1K Image Cost | $0.03 | $0.07 | $0.13 |
| Batch 1K Image Cost | $0.02 | Not Available | Not Available |
| Average Latency | ~4 seconds | ~6–8 seconds | ~10–12 seconds |
| Biggest Downside | Hard 1K resolution cap; struggles with highly complex, dense paragraphs of text. | Lacks native batch pricing discounts for heavy background operations. | High transaction latency and steep output costs limit its use in high-concurrency loops. |
| Best Production Use Case | High-volume pipelines, real-time app interactions, localized banners. | Mid-tier applications requiring deep conversational image editing. | Cinematic asset creation, complex graphic design, maximum text fidelity. |
SDK Quick-Integration Script for gemini-3.1-flash-lite-image
Integrating Google AI Studio image generation into an existing application pipeline can be done directly through the native Google GenAI SDK. The code block below demonstrates how to initialize the client, configure programmatic parameters, and safely execute an asynchronous text-to-image request targeting the gemini-3.1-flash-lite-image endpoint.
Python
plaintext1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str):""" 6 Initializes the Google GenAI client and executes a low-latency text-to-image 7 generation request using the cost-optimized gemini-3.1-flash-lite-image model. 8 """# Initialize the client; expects GEMINI_API_KEY environment variable to be set 9 client = genai.Client() 10 11 print(f"Sending generation request for model: gemini-3.1-flash-lite-image") 12 13 try: 14 response = client.models.generate_images( 15 model='gemini-3.1-flash-lite-image', 16 prompt=prompt_text, 17 config=types.GenerateImagesConfig( 18 number_of_images=1, 19 output_mime_type="image/jpeg", 20 aspect_ratio="1:1", # Accepts standard aspect ratios like 1:1, 16:9, 4:3 21 person_generation="ALLOW_ADULT" 22 ) 23 ) 24 25 # Process and save the generated image payloadfor i, generated_image in enumerate(response.generated_images): 26 image_bytes = generated_image.image.image_bytes 27 full_path = f"{output_path}_asset_{i}.jpg"with open(full_path, "wb") as f: 28 f.write(image_bytes) 29 print(f"Successfully saved 1K image asset to {full_path}") 30 31 except Exception as e: 32 print(f"API Execution failed: {str(e)}") 33 34if __name__ == "__main__": 35 prompt = "A professional product mockup of a sleek desktop companion robot on an office desk, clean lighting" 36 generate_bulk_asset(prompt, "output_production")
When deploying this script at scale, security and compliance layers are handled automatically by the infrastructure. Google embeds imperceptible SynthID watermarks and structural C2PA content credentials directly into the metadata of every output image by default. This ensures that all programmatic assets generated through your pipeline remain completely traceable and enterprise-compliant without requiring any custom post-processing scripts.
Future-Proofing Your Production Stack with Unified API Layers
While calling Google's native SDK works perfectly for isolated environments, scaling this text-to-image workflow across multi-tenant enterprise applications often requires a unified API management layer.
Infrastructure and orchestration platforms like Atlas Cloud have officially decentralized this pipeline by providing production-ready integration pathways for this specific model variant. Through the dedicated Atlas Cloud Nano Banana 2 Lite text to image/edit model hub, developers can now route their high-velocity visual workflows directly through a unified API infrastructure.
Connecting through a hub like Atlas Cloud lets your dev team mix this model's fast 4-second video tool with backup options from other models. It also gives you one central place for usage stats and simple billing. This means you do not have to add extra messy code to your main servers.
Troubleshooting Common API Error Codes and Rate Limit
You will definitely run into server or client limitations if you expand your app to handle tens of thousands of image hits at once. Handling these traffic jams smoothly stops your app from crashing. It also keeps things running fast and easy for users.
Handling 429 Too Many Requests
The most frequent error during busy app runs is the 429 Too Many Requests message. This means your app went over the shared speed limits given to regular Google AI Studio dev accounts. To resolve this, developers should build an exponential backoff algorithm with jitter into their request loops, delaying subsequent API calls when a 429 status is caught. For enterprise operations requiring guaranteed capacity, engineers can transition to provisioned throughput (PT) arrangements within the Gemini Enterprise Agent Platform, which reserves dedicated hardware allocation to guarantee consistent throughput.
Resolving 400 Invalid Argument and 403 Forbidden Errors
A 400 Invalid Argument error usually means your video settings have wrong sizes or bad aspect ratios. The Lite plan is very strict and only allows 1K video outputs. Make sure your aspect ratio matches regular sizes like 1:1 or 16:9.
In contrast, a 403 Forbidden error means there is an API key issue or a safety block. Google uses automatic filters to check all text. If your prompt breaks these safety rules, the system will block the video. You will need to rewrite the text to follow the platform guidelines.
Developer Realities: Integrating Budget Image Workflows Natively
Deploying a budget-optimized model means acknowledging its practical limitations. Because the architecture of the model is tuned for exceptional speed and low cost, it makes explicit trade-offs:
- The hard 1K resolution ceiling means it cannot produce native 4K print-ready graphics.
- Additionally, when tasked with highly intricate prompts containing dense structural layers, the model can occasionally experience character-consistency wobbles across widely different scene transitions.
To mitigate these drawbacks without inflating your operational costs, you can chain your generation pipeline into a multi-turn editing workflow.
Instead of attempting to generate a flawless, highly complex scene on your very first try, write your application logic to generate a rapid 4-second base draft. From there, use conversational image editing requests to programmatically modify, relight, or swap specific objects within the asset.
For advanced multi-media applications, this 1K image output can be fed directly into video generation pipelines like Gemini Omni Flash, which processes video editing tasks at an affordable rate of $0.10 per second.
Is Nano Banana 2 Lite Right for Your Stack?
To streamline your architectural evaluation, here is a breakdown of which development teams will gain the highest ROI from the Nano Banana 2 Lite (gemini-3.1-flash-lite-image), and who should look toward standard premium tiers.
Who Is This Model Ideal For?
- High-Concurrency Application Developers: If your software handles thousands of automated API requests per minute, such as real-time user avatar creators, instant dynamic ad generators, or bulk e-commerce product placement systems—this model is built specifically for your load requirements.
- Cost-Sensitive Software Engineers: Teams targeting micro-budget workflows where keeping operational expenses low is a leading survival metric. Leveraging its $0.0168 batch tier effectively eliminates the standard premium fiscal bottleneck.
- Interactive App Architects: Products requiring a strict synchronous loop where users demand a near-real-time feedback loop will benefit immensely from its sub-4-second generation speed.
Who Should Avoid This Model?
- High-Fidelity Graphic Designers: If your application relies on rendering large-scale print graphics, native 4K resolution banners, or complex cinematic marketing materials, the hard 1K resolution cap will limit your creative output.
- Text-Heavy Visual Marketers: While the model supports inline typography, applications requiring dense, hyper-complex paragraphs of layout text embedded natively inside images should utilize the Gemini 3 Pro Image tier instead to maintain absolute text fidelity.
- Audio-Centric Multimedia Builders: Teams building advanced multi-modal loops that rely heavily on audio synchronization or generating images directly from continuous live audio streams should look elsewhere, as audio is strictly unsupported by this specific Lite tier.
FAQ
How does gemini-3.1-flash-lite-image lower developer costs compared to standard tiers?
The model slashes standard developer costs by exactly 50% compared to the standard gemini-3.1-flash-image model. By optimizing the token footprint down to $0.25 per 1 million input tokens and $30.00 per 1 million image output tokens, the price for a standard 1K-resolution image drops to $0.0336 under standard paid tiers. For non-urgent background tasks, utilizing the batch API drops this rate down to $0.0168 per image.
Can Nano Banana 2 Lite handle high-concurrency enterprise application loads?
Yes, the model is built specifically to handle high-concurrency enterprise demands. While standard developer tiers share a common infrastructure pool, enterprise teams can secure dedicated, highly reliable performance by deploying provisioned throughput via the Gemini Enterprise Agent Platform. This completely bypasses standard shared rate limits and ensures a steady 4-second generation speed during peak traffic windows.
Does the cheapest Google image API compromise on safety or content tracking?
Cost optimization does not remove enterprise safety features or compliance mechanisms. Every image generated by the model automatically includes a native SynthID watermark embedded directly into the pixel array, alongside standard C2PA content credentials. This metadata allows enterprise platforms to maintain transparent tracking and completely verify the authenticity of all AI-generated assets before they face public-facing applications.






