Summary
In mid-May 2026, Qwen3.7-Max and Qwen3.7-Plus quietly appeared on LM Arena. @Alibaba_Qwen set community expectations with the line "Alibaba #6 in Text, #5 in Vision." On June 2, the Alibaba Cloud Tongyi Qianwen team officially released this multimodal agent model. It is already available on Alibaba Cloud Model Studio and Qwen Chat, with API access under alibaba/qwen3.7-plus and a listed price of about $0.40 / $1.60 per million input/output tokens.
The official positioning is clear: Plus is the cost-effective multimodal model; Max is the text flagship.
We spent one afternoon running a hard test suite across Qwen3.6-plus, Qwen3.7-plus, and Qwen3.7-Max: automatic repair of 10 real bugs, 15 AIME 2025 math contest problems, plus a broader comparison of multimodality, speed, and cost.
The results are best read as 5 task-level observations, not as a general model ranking:
- BugFind-10 single run: Plus passed all external pytest checks. Under this 10-task suite, official Stirrup scaffold, and single-run setup, Plus scored 10/10 while Max and 3.6-Plus scored 9/10. This indicates task fit in this setting; it should not be extrapolated into a general coding ranking.
- Math: Plus with thinking enabled reached the same single-run score as Max. On 15 contest math problems, Plus and Max both answered 14 correctly; in this run, Qwen3.7-plus took much less time than Qwen3.7-Max (113s vs 303s per problem).
- A generational speed jump: On agent tasks, end-to-end throughput for Qwen3.7-plus reached 147.5 t/s, while Qwen3.6-plus reached only 41.5 t/s, a 3.55x improvement. Math tasks that the previous generation could not finish became easy to complete.
- Multimodality still has flaws: In our controlled multimodal tests, Qwen3.7-plus answered simple image questions correctly, but the official example image dog_and_girl.jpeg was described as "a train and a crowd."
- Some capabilities were close to Max, with a latency advantage: Across several tests in this run, Qwen3.7-plus reached results close to Qwen3.7-Max while showing lower latency. This is not a general ranking claim.
Below are the full test data, methodology, and model-selection recommendations for engineering leads. All comparisons are scoped to this small sample, single run, and fixed scaffold.
0. Model Capability and Leaderboard Context
Alibaba Qwen's product line had already settled into a pattern in the 3.6 generation: Max = text flagship, Plus = multimodal long-context model. Version 3.7 continues that logic:
| Dimension | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| Input modalities | Primarily text | Text + image |
| Typical selling point | Reasoning ceiling, long-horizon agents | 1M context, vision, hybrid thinking, lower unit price |
| Arena (2026-05) | About #13 on the overall text leaderboard | About #16 on vision |
| Gateway price (06-01) | $1.25 / $3.75 per M | $0.40 / $1.60 per M |
1.How Does the Official Story Position Plus?
Alibaba Qwen's launch post reduces the message to one sentence:
"One model. Sees, thinks, codes, acts."
The core selling points are: a multimodal interactive hybrid agent with unified GUI & CLI operation, a versatile coding agent, and cross-agent-framework generalization. Qwen core developer shuai bai_ explained it further:
Our goal is to turn multimodal AI from passive image captioning into an active problem solver: one that can see, reason, write code, operate interfaces, and verify results. It is a step toward truly agentic multimodal intelligence.
The Performance posts from the official thread give the key positioning:
- Text performance is "close to Max level" (vendor claim)
- Multimodal improvements focus on core agent capabilities: complex visual understanding, visual reasoning, tool use, and code/GUI execution
| Common claim on X | Source | Our result | Conclusion |
|---|---|---|---|
| Plus text is "close to Max" | Official | AIME with thinking: same score, 14/15; Plus was 2.68x faster | Same single-run math score; lower latency in this run |
| Max is better for coding / long-horizon work | Vercel docs | BugFind: Plus 10/10, Max 9/10; Plus 147.5 t/s | This task does not support applying that assumption blindly |
| The vision leaderboard is strong | Arena | Official sample image failed; controlled image ✓ | A high leaderboard score and a single-image failure can coexist |
2. Our Evaluation Method: Four Task Types and One Hard Rule
To keep the test fair, we maintain a small suite called BugFind-10: 10 real-world bugs covering price calculation, array bounds, path handling, concurrency, JSON, SQL, cache behavior, Unicode, configuration, and more. Each bug comes with pytest tests. The model must run inside the official Stirrup agent framework with local code-execution tools and complete the full loop by itself: "reproduce → locate → edit production code → run tests."
Why Build Our Own Test Suite?
Public leaderboards have three common failure modes:
- Memorization and leakage: flagship models are already saturated on older problems. We selected AIME 2025, a contest that was published after likely model training cutoffs.
- Vendor self-reporting can drift away from independent retesting: the same metric can change significantly depending on dataset version, whether thinking is enabled, and whether tools are allowed.
- Agent benchmarks depend on scaffolding: different agent frameworks can shift scores by 2-3 percentage points. We fixed the framework to official Stirrup and added external verification.
The Four Test Tasks
| Task | What it measures | Core metric |
|---|---|---|
| Gate check | Identity confirmation, thinking support, vision capability | Pass / fail |
| BugFind-10 | Automatic repair of 10 real code bugs | External pytest pass rate, model-call count, wall-clock time |
| AIME 2025 I | 15 contest math problems | Accuracy, time per problem, thinking ablation |
| Quick Eval | 8 elementary-school word problems | Speed baseline, TTFT, thinking benefit on simple tasks |
Our Hard Rule: Code Scores Only Count Under External Pytest
This is the foundation of the whole review. It also directly addresses the Hacker News concern that an agent saying "tests passed" is not enough.
Process:
- The agent edits code in the workspace, runs pytest itself, and writes a CHANGELOG.
- We copy the modified production code into an isolated environment and run pytest independently.
- We publish only the exit code and failure stack from step 2.
An analogy: the agent is the exam taker. We do not just read the answer it hands in; we take the answer into another room and grade it again, so we are not trusting its own belief that it succeeded.
3. Code and Agent Capability
Three-Model Overview
| Model | pytest result | Repair rate | LLM calls | Wall-clock time | End-to-end t/s |
|---|---|---|---|---|---|
| Qwen3.6-Plus | 1 failed, 26 passed | 9/10 | 63 | 334s | 41.5 |
| Qwen3.7-Plus | 27 passed | 10/10 | 52 | 205s | 147.5 |
| Qwen3.7-Max | 1 failed, 26 passed | 9/10 | 20 | 249s | 51.8 |
Plus getting the better single-run BugFind result was unexpected:
- Plus was the only 10/10 run in this test.
- Max used the fewest calls but did not get full marks. 3.7-Max stopped after only 20 model calls, the fewest of the three. It tended to "think for a long time and make one large change," with fewer iterations. By contrast, 3.7-Plus used 52 calls and was willing to edit, run, inspect feedback, and edit again.
- Plus had the shortest wall-clock time and highest throughput. For IDE-agent experience, that matters much more than a few Elo points on a leaderboard.
One Task, Three Repair Philosophies: Deep Dive on task05
This task tests the rule that invalid JSON must not be silently swallowed. When parsing sees bad data, it must not pretend success and return an empty object; it must report the error clearly. The original bug:
plaintext1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # Bug: swallows the exception
The tests require:
- For input like "this is not json {", the function must not return an empty dict {}.
- For invalid input without braces, like "bad", it must raise an exception.
Max's approach (external test ✗): raise a custom JSONParseError.
That looks like a clean solution, but for "this is not json {" it raised immediately, so the test failed before the first assertion could even run. Yet Max's CHANGELOG confidently said "27 passed." This is exactly why external verification is mandatory: an agent's self-assessment and an external audit often diverge.
3.6-Plus (external ✗): failed on the same first hurdle.
3.7-Plus (external ✓):
plaintext1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"Invalid JSON: {e}") from e
For malformed input containing braces, it returns an error object that is distinguishable from {}. For input with no braces at all, it raises. It hit both sides of the test contract precisely.
Why did Max miss full marks on this task? Start with call counts:

3.7-Max stopped after only 20 model calls, the fewest of the three. It tended to "think for a long time and make one large change," with less iteration. 3.7-Plus used 52 calls and was willing to edit, run, inspect feedback, and edit again. In agent coding tasks that require repeated interaction with the environment, more iteration may help cover edge cases that Max missed in this run. This points to an often-overlooked fact: in agent tasks, "deeper reasoning" does not necessarily mean more stable delivery. Using tool feedback well is just as important.
On repair quality, all three models did well on task03. This task directly concatenates user_id into a file path, so ".." can create path traversal and "user;rm -rf" can carry shell metacharacters. The repair added a whitelist sanitizer, identifying a real security defect instead of blindly patching for green tests:
plaintext1user_id = re.sub(r'[^a-zA-Z0-9_-]', '', user_id) or "unknown"
Engineering takeaways:
- For agent tasks, willingness to wrestle with the environment (Plus had 52 dialogue turns and 98 code executions) matters more than minimal iteration.
- Max stopped after 20 turns and prematurely believed task05 was solved.
- In interactive bug fixing, a clean "raise an exception" solution is not always more useful than returning dirty data in a distinguishable form.
4. Reasoning and Math: Thinking Mode Is a Cost Decision
The Qwen3.7 series emphasizes "hybrid thinking," controlled through the enable_thinking switch. Is this switch worth enabling? We ran an ablation across two task groups with very different difficulty. The hard set was AIME 2025 I, a contest published after likely model training cutoffs and therefore more resistant to contamination. We checked each problem and answer against two independent sources, AoPS and Areteem, then graded automatically.
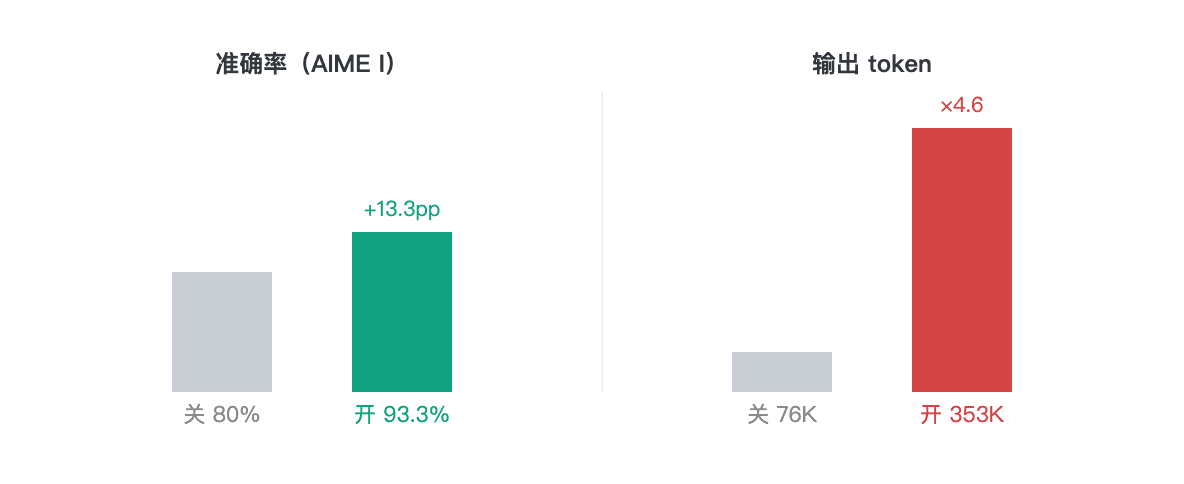
| Model / mode | Accuracy | Average time/problem | Output tokens |
|---|---|---|---|
| 3.7-Plus · thinking off | 12/15 (80%) | 24.7s | 76,502 |
| 3.7-Plus · thinking on | 14/15 (93.3%) | 113.4s | 353,424 |
| 3.7-Max · thinking on | 14/15 (93.3%) | 303.1s | 307,801 |
| 3.6-Plus · thinking | First 6 problems: 6/6 (see below) | 464s | 25.7K/problem |
Cost comparison:
| Configuration | Correct | Accuracy | Avg time/problem | Total output tokens | Avg tps | Placeholder cost |
|---|---|---|---|---|---|---|
| Plus thinking off | 12/15 | 80.0% | 24.7s | 76,502 | 204.0 | $0.15 |
| Plus thinking on | 14/15 | 93.3% | 113.4s | 353,424 | 205.4 | $0.69 |
| Max thinking on | 14/15 | 93.3% | 303.1s | 307,801 | 68.3 | $0.60 |
Note: placeholder pricing was estimated with 3.6-Plus at $0.325/$1.95 per M. The official Gateway price of $0.40/$1.60 is closer to production pricing.
Marginal Benefit of the Thinking Switch
With reasoning enabled, Plus reached the same single-run AIME score as Max. 3.7-Plus with thinking on and 3.7-Max both scored 14/15, but Plus took 113 seconds per problem while Max took 303 seconds. In this run, Max's longer latency did not produce a higher score; that single run still does not prove Max has no advantage on other math tasks.
On 8 elementary-school word problems, both modes were 100% correct. Enabling thinking only burned 24% more tokens. Put the two sets together and the conclusion is clear:
Turn thinking off for simple tasks to save money; turn it on for hard tasks to buy accuracy. Leaving reasoning globally enabled means continuously paying more than 4x on simple requests with no accuracy gain. The value of the switch is that it lets you route dynamically by task difficulty.
Max vs Plus: Where the Latency Came From in This Run
Max also scored 14/15 and also failed I-14 (predicted 69, correct answer 60). Same test, same missed problem, same failure pattern, not "Max was smarter and failed a different hard case." Max did solve I-15 while Plus missed it, so there is variance on very hard problems, and one run cannot declare one model globally stronger.
But the speed gap was striking. On problem I-2, Max took 261 seconds; Plus took only 108 seconds. Across the full set, Max averaged 68.3 tps while Plus averaged 205.4, roughly 3x faster.
Conclusion: once thinking is enabled, Plus reached the same single-run score as Max on this contest-math set while keeping a clear latency and cost advantage. For real-time interactive scenarios, that difference matters.
Simple-Task Control
We used 8 elementary-school word problems as a simple-load test:
| Mode | Accuracy | Avg time | Total output tokens |
|---|---|---|---|
| thinking off | 8/8 | 2.17s | 2,314 |
| thinking on | 8/8 | 2.48s | 2,881 |
Turning thinking on burned 24% more tokens with zero accuracy gain. Difficulty is the only sensible criterion for enabling thinking mode.
5. Speed, the Generational Gap, and One Task We Had to Kill
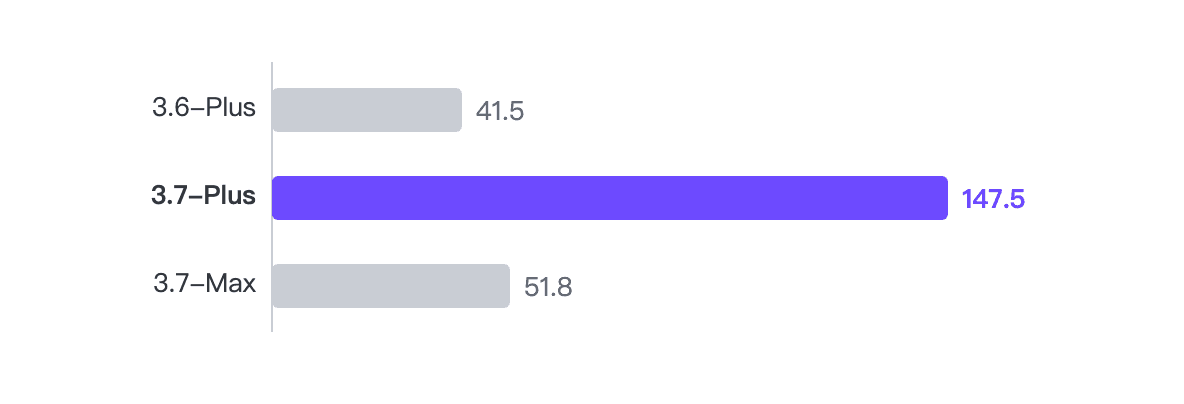
Agent Throughput Comparison
Real end-to-end speed extracted from BugFind runner_summary.json:
- 3.7-Plus: 147.5 t/s (52 calls, 204.8s)
- 3.7-Max: 51.8 t/s (20 calls, 249.0s)
- 3.6-Plus: 41.5 t/s (63 calls, 334.5s)
Generational improvement (3.6 → 3.7 Plus) was about 3.55x. Same-generation Plus vs Max was about 2.85x.
The most dramatic example of the generational gap came from running math on 3.6-Plus. We wanted to add an AIME result for it too, but it was too slow to finish: reasoning ran all the way to the limit on each problem, single-problem output reached 16K-52K tokens, and each problem took 297-932 seconds. The first 6 problems alone took 46 minutes. A full 15-problem run was not feasible within any reasonable time budget, so we stopped it.
We tried "time limiting" by cutting max_tokens from 16000 to 4096. It did not work. This is an engineering trap worth recording:
- In thinking mode, reasoning tokens are not constrained by max_tokens; the model can still emit tens of thousands of reasoning tokens.
- Request timeout is not enough either. OpenAI/httpx timeout is a "read timeout" between data chunks. As long as the streaming response keeps emitting tokens, that timeout never fires.
Both timeout routes were blocked, so we killed the process and reported the recovered first 6 problems: 6/6 correct. That means 3.6-Plus's math capability itself was not the issue. It could solve the problems. But "can solve" and "can finish within a time users will tolerate" are different claims. For a production model that must respond to users, the latter is often more important. This is exactly the dimension that leaderboards often hide but user experience exposes.
Advice for engineering teams: for thinking models, traditional timeout and max_tokens strategies can fail. You need a total token budget, total wall-time cap, or reasoning-token cap.
6. Core Finding Four: Multimodality - Controlled Image Passed, Official Sample Failed
| Test sample | Input | Model output | Judgment |
|---|---|---|---|
| Controlled image | Red/blue block PNG (local) | "blue, orange" | ✓ correct |
| Official sample | dog_and_girl.jpeg (OSS) | "a group of people standing beside a train..." | ✗ completely wrong |
Arena Vision ranks Plus around #16 (preview). That benchmark measures image-text dialogue under human preference. Our test shows that a high leaderboard score and a single-image failure can coexist.
Advice for model selectors: we did not run standardized vision benchmarks such as MMMU or ChartQA, so we are not making a broad claim about whether Plus vision is production-ready. But the finding is clear: running 20-50 images from your own business domain (OCR, charts, UI screenshots, receipts) is far more reliable than reading a leaderboard.
Some Hacker News users also tested the model and concluded that "Qwen vision is stronger than Gemma." That user feedback is not contradictory; those were private tasks. The official sample-image failure is a reminder that private success and official failure can coexist. Model selection must be driven by your own data.
7. Cost: What This Whole Round Cost
This article itself is a cost sample. After running three models across four task types, real Qwen API usage was about 2 million tokens (the stopped 3.6-Plus portion was not fully counted), with a placeholder cost of about $2-3.
Bill for This Test Round
| Item | Token scale | Placeholder cost |
|---|---|---|
| AIME Plus on | 353K out | ~$0.69 |
| AIME Plus off | 76K out | ~$0.15 |
| AIME Max on | 308K out | ~$0.60 |
| BugFind × three models | Very high cumulative input | Included in total |
| Total | ~2 million | $2-3 |
Insight 1: a serious evaluation round costs about as much as a meal. Teams should spend that money on rerunning their own tasks, not on marketing copy.
Insight 2: agent cost is not mainly the unit price. It is turn count × history length per turn. BugFind used 52-63 calls per model, and a single-turn input could exceed 11K tokens. Optimization should target history compression, sub-agent decomposition, and caching, not just cheaper model pricing.
Marginal Cost of Thinking (AIME I Example)
- Thinking off: $0.15 / 15 problems ≈ $0.01/problem
- Thinking on: $0.69 / 15 problems ≈ $0.046/problem
Two additional correct answers (I-9 and I-14) cost +$0.54. If your business runs 10,000 medium-difficulty problems per day, the gap can easily reach thousands of dollars per day. Routing strategy (start without thinking, then enable thinking when confidence is low) is mandatory in production.
Gateway Price Comparison (2026-06-01)
| Model | Input / output per M |
|---|---|
| qwen3.7-plus | $0.40 / $1.60 |
| qwen3.7-max | $1.25 / $3.75 |
Max is about 3x more expensive than Plus (about 2.3x on output), while this run showed the same AIME score and a one-point lower BugFind score. Time cost is usually more expensive than token cost: engineer waiting time and occupied agent slots are money too.
8. Model-Selection Advice for Developers
| Scenario | Recommendation |
|---|---|
| Building agents / coding / bug fixing | Put 3.7-Plus into the default candidate set. This single run was 10/10, with high throughput and more iteration; keep Max as the text-flagship / high-difficulty fallback, and do not choose by the flagship label alone. |
| Medium-difficulty reasoning or math, with latency sensitivity | 3.7-Plus with thinking on. In this run it matched Max accuracy with lower latency. |
| Simple Q&A / classification / extraction | 3.7-Plus with thinking off. Save the extra reasoning cost. |
| Still using 3.6-Plus | Upgrade. The main generational gap is speed, and 3.5x throughput changes the user experience. |
9. Limitations and Honest Disclosures
This article is a deep snapshot from one afternoon, not an academic paper. The following limitations matter:
- Single run: neither BugFind nor AIME used pass@k. High-variance cases such as task05 and I-15 need repeated validation.
- No horizontal competitor comparison: Claude, GPT, Gemini, and DeepSeek were not tested. This only describes internal differences within the Qwen family.
- 3.6-Plus completed only 6 AIME problems: its accuracy cannot be directly compared with the 15-problem Plus/Max runs.
- Pricing used placeholder estimates: check the latest Gateway pricing for official numbers; domestic DashScope pricing may have separate discounts.
- Only one agent framework was used (Stirrup): switching to SWE-agent could change the ranking.
- Multimodal sample size was n=2: it cannot represent broad vision capability.
- The tested model was an invite beta: the official SKU may have minor behavior changes.
- X data was a one-day snapshot: it captured community sentiment at the time of writing and may have changed after publication.
Final Note
In the official June 2026 narrative, Qwen3.7-Plus is the Chinese flagship tier on the vision leaderboard, the cost-effective choice on Gateway, and the new Qwen family member that the community describes as moving at a frightening iteration speed.
In our reproducible one-afternoon universe, it is:
- The model that was the only one to score 10/10 in this single real-code bug-fixing run.
- The model that reached the same score as Max on this contest-math run with thinking enabled, while showing lower latency.
- The model that delivered a 3.55x throughput improvement over the previous generation, making "unable to finish" a thing of the past.
- The model that still hallucinated on the official sample image while passing our controlled image test, reminding you not to choose a vision model from one screenshot.
These conclusions are scoped to this small sample, single run, and fixed scaffold. They support putting Plus in the engineering default-candidate set; they do not support a general model ranking.
For engineers, the official narrative is responsible for the vision; the outputs/ directory is responsible for the evidence. If you are choosing a model for production, read this review together with the companion data-visualization version ([13_Qwen3.7-Plus_Eval.html](13_Qwen3.7-Plus_Eval.html)): trust the numbers first, then read why we are willing to call this an "evaluation" instead of a repost.
In the 2026 AI model flood, only reproducible audit-grade evidence is hard currency for technical decisions.






