
Beyond n8n: Why Rust is the Only Answer for Zero-Crash AI Workflows
It is 2:00 AM, and an asynchronous JavaScript node in your production n8n environment silently encounters an implicit type conversion error. A third-party webhook changed an integer into a string. Because Node.js evaluates code dynamically at runtime, the execution breaks down midway. The workflow halts, leaving data half-processed and your team scrambling to fix a broken state machine.
For developers building mission-critical automation and multi-agent pipelines, runtime fragility is a ticking time bomb. The solution is moving away from the paradigm of untyped, interpretation-heavy orchestration entirely.
Enter flow-like, an open-source, enterprise-grade workflow automation engine built from the ground up in Rust. By trading the dynamic looseness of Node.js for a rigid, compile-time strong-typing ecosystem, flow-like changes the rules of production pipelines. It turns unpredictable multi-agent behaviors into reliable, deterministic tasks that can execute on a single terminal or a Kubernetes cluster without a single runtime surprise.
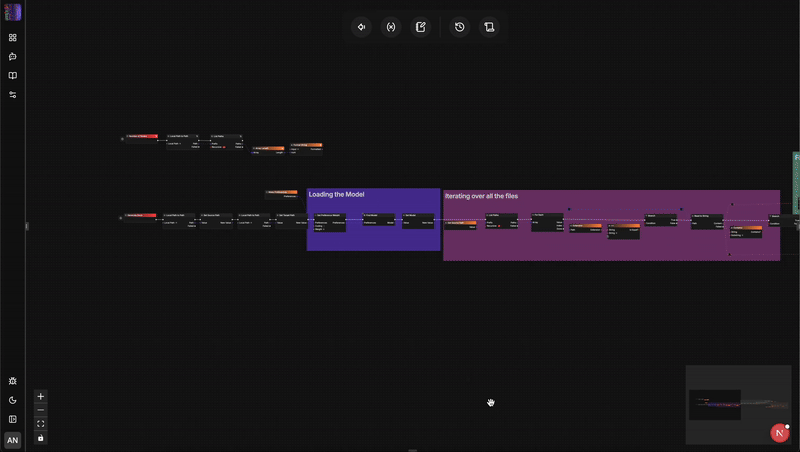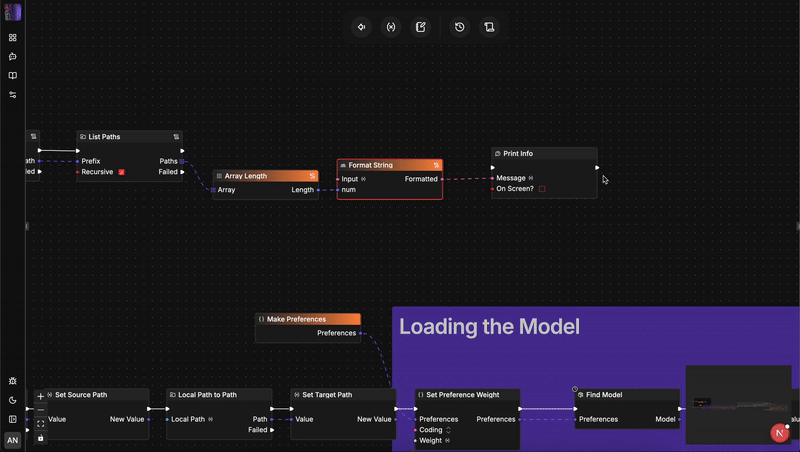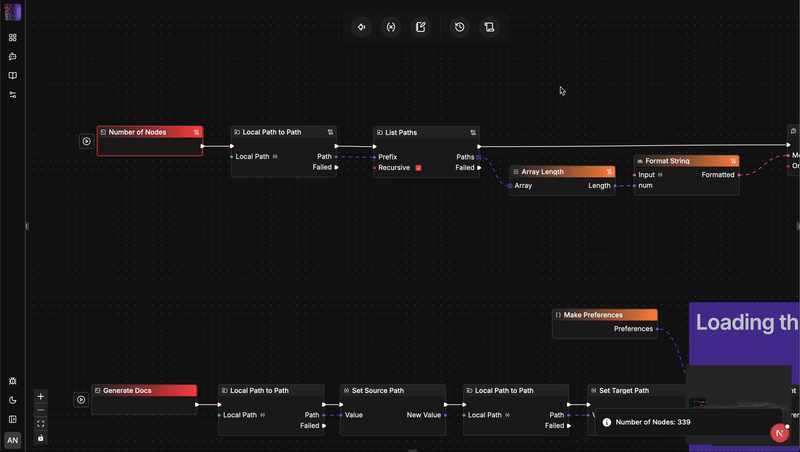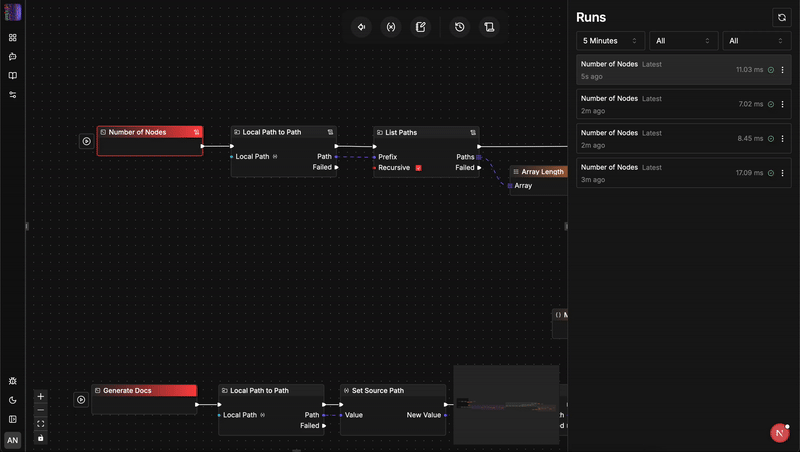
Architectural Showdown: flow-like vs. n8n
Understanding why a language shift matters requires looking closely at how these two engines manage state, safety, and scale.
Type Safety vs. Untyped Chaos
The most visible issue in n8n is its complete reliance on loose JSON payloads passed blindly between Node.js modules. If a node outputs a nested dictionary where another node expects a flat object, the engine only discovers this discrepancy when live production traffic runs through it.
Conversely, flow-like works with a strict "Strong-Type Contract" model across all data boundaries. Variables are explicitly declared using core constructs like VariableType::String, VariableType::Execution, or customized structs. If an output payload fails to match the schema contract expected by the consumer pin, the pipeline engine catches it early. The execution pipeline throws deterministic validation blocks before processing corrupt or unexpected payloads.
High-Performance Concurrency without Garbage Collection
Node.js relies on a single-threaded event loop to handle concurrent I/O. When an n8n container parses large files or processes high-frequency webhooks, the V8 JavaScript engine incurs severe memory overhead and sudden latency spikes due to Garbage Collection (GC) pauses.
flow-like leverages Rust’s zero-cost abstractions and manual memory management. Built with asynchronous traits and low-overhead hashing utilities like blake3, flow-like scales effortlessly to an astonishing 244,000 workflows per second. It processes data arrays and complex nested loops with an average internal execution speed of just ~0.6ms per node, requiring a tiny fraction of the memory footprint of a Node.js runtime instance.
Showcase: Building a Zero-Leak, Multi-Modal AI Processing Pipeline in 3 Minutes
Let us look at how easily you can set up and run a live, type-safe multi-agent workflow that processes input data through local parameters and calls an advanced cloud model for processing.
Step 1: Local Environment Setup & Compilation
Since flow-like is a pure native application with zero external runtime dependencies, compiling it is straightforward. Clone the project and verify the workspace build structure using Cargo:
Bash
plaintext1git clone https://github.com/Rheosoph/flow-like.git 2cd flow-like 3cargo build --release
The compilation process packages everything—including underlying WASM sandboxing runtimes and type definitions—into a single executable binary.
Step 2: Connecting the Cloud Brain via Atlas Cloud
While flow-like executes lightning-fast on local consumer hardware, processing unstructured data or generating precise JSON schema structures requires advanced inference capabilities. Instead of writing custom API code or loading thousands of lines of model-specific wrapper libraries, flow-like includes a native BuildAtlasCloudNode node in its standard catalog.
The underlying layout registry configures the system to target the platform:
Rust
plaintext1let mut node = Node::new( 2 "ai_generative_build_atlascloud", 3 "Atlas Cloud Model", 4 "Builds a model served by Atlas Cloud, a full-modal AI inference platform exposing a single OpenAI-compatible API...", 5 "AI/Generative/Provider" 6);
💡 Developer Note: This approach eliminates the traditional friction of api keys management. I use a single API token provided by Atlas Cloud inside this node, which lets me dynamically spin up or switch between deep reasoning models like DeepSeek-V4-Pro, Qwen, or GLM on the fly without having to manually register accounts or initialize separate client packages for every model.
Here is an example setup mapping out the connection properties:
JSON
plaintext1{ 2 "node_id": "ai_generative_build_atlascloud", 3 "inputs": { 4 "endpoint": "https://api.atlascloud.ai/v1", 5 "api_key": "ac_prod_secure_token_7721", 6 "model_id": "deepseek-ai/deepseek-v4-pro" 7 } 8}
Step 3: Triggering the Pipeline & Checking Metrics
When an execution signal hits the exec_in pin, the engine activates the runner logic:
Rust
plaintext1let mut hasher = blake3::Hasher::new(); 2hasher.update(b"atlascloud"); 3// System hashes parameters and returns a unique, reusable VLM Bit structure
The engine validates the structure, wraps the authentication logic neatly inside an OpenAI-compatible runtime provider instance (custom:openai), and passes the structured Bit object to downstream visual extraction blocks via the model pin.
Production Performance Indicators Metrics:
- Engine Initialization Footprint: ~24 MB RAM
- Internal Node Pin Latency: < 0.1ms
- Type-Safety Failures: 0 (Caught at configuration step)
Deep-Dive Comparison Table: Engine Specs at a Glance
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Architectural Dimension | n8n Workflow Engine | flow-like Architecture |
| Underlying Language | Node.js (TypeScript / JavaScript) | Rust (Pure Native Core) |
| Data Interface Typing | Loose JSON (Dynamic validation at runtime) | Strongly Typed Contracts (Pins enforce structures) |
| Max Concurrent Throughput | ~220 tasks/sec (V8 event-loop bound) | ~244,000 workflows/sec (Zero-GC execution) |
| Execution Sandboxing | VM2/Isolates (Prone to prototype pollution) | WebAssembly (WASM) Isolation |
| Offline Architecture | Heavy Docker environments required | Local-First Native (Runs seamlessly on Raspberry Pi) |
| Model Ingestion Ecosystem | Separate community integrations per vendor | Unified Endpoints (via Atlas Cloud node layer) |
FAQ: Resolving the Skepticism Behind Rust-Based Automation
Does a Rust-based engine mean I have to write raw Rust code to build a node?
No, you do not need to write Rust to extend the platform. While the engine core is pure Rust, flow-like uses WebAssembly (WASM) sandboxing to support custom node generation across 15+ languages, including TypeScript, Python, and Go, without breaking the runtime safety guarantees of the engine.
How does the type-safe system handle arbitrary, dynamic API payloads?
It maps loose inputs into a well-defined Struct container at the ingestion node. By enforcing strict boundaries at input pins, any missing keys or format mutations are surfaced and handled immediately at the border node, ensuring internal logic steps never encounter undefined runtime variables.
What is the precise memory overhead when handling massive processing loops?
The platform averages less than 30 Megabytes of base memory allocation under typical heavy loads. Because Rust frees resource block registers immediately when data goes out of scope instead of queuing garbage collections, memory graphs show a flat line even when processing wide iteration matrices.






