DeepSeek v4: Everything We Know So Far – Features, Release Date, and How to Access on Atlas Cloud
Introduction: What is DeepSeek v4?
AtlasCloud is expanding its generative AI arsenal with the upcoming addition of DeepSeek v4.
- What it is: The latest flagship from the DeepSeek team. If DeepSeek v3.2 sets the standard for cost-effective open-source coding models, v4 pushes the boundaries of logic and memory using proprietary Manifold-Constrained Hyper-Connections (mHC) and Engram Memory technologies.
- Key Benefit: Beyond just generating code snippets, v4 acts like a senior architect, understanding entire repository structures for cross-file reasoning and complex bug fixing.
- Status: Upcoming Release (Expected mid-February 2026 — read our deep dive on what to expect from DeepSeek V4).
Why are we confident that DeepSeek v4 is the next game-changer? Because it solves the industry's biggest pain point: AI needs to remember and understand logic of a project.
📣 Update — April 24, 2026: DeepSeek-V4 has officially launched. Read our full coverage of what actually shipped, including the new sparse attention architecture, 1M token context, and Agent benchmark results — in DeepSeek-V4 Preview Launch.
Technical Deep Dive: Key features
To challenge Claude Opus 4.5, DeepSeek has rebuilt the model from the ground up. Leaked papers indicate a fundamental shift in how the model handles memory and logic stability. Let's break down the four pillars of this update.
Architecture: Superior Logical Reasoning
-
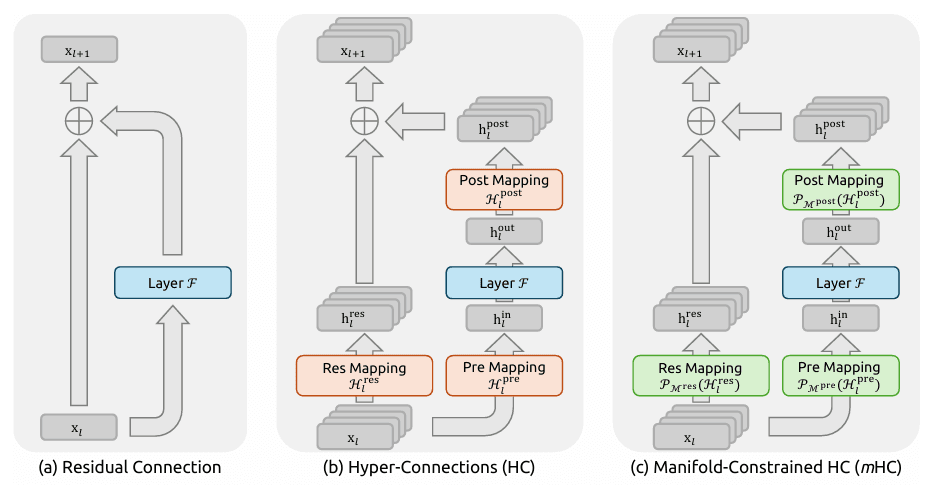
Manifold-Constrained Hyper-Connections (mHC)
- The Concept: DeepSeek v4 invents a new "neural wiring" method. Traditional connections often lose information in deep networks, but mHC acts like a "logical superhighway" for the AI's brain.
- The Result: When handling massive, complex logic (like refactoring thousands of lines of code), the model learns faster and retains logic better. This eliminates the "logic hallucinations" and inconsistencies common in long-context generation.
Efficiency: Lower Inference Costs
-
Mixture-of-Experts (MoE) 2.0
- The Concept: While v4 is a parameter giant (hundreds of billions), it uses an optimized MoE architecture to activate only the most relevant "experts" for each token.
- The Result: It strikes a perfect balance between High Capability (massive knowledge base) and Efficient Scaling (running as lightly as a smaller model).
-
Sparse Attention
- The Concept: Abandoning the brute-force method of scanning all text, the model now intelligently focuses only on key information. This drastically reduces compute costs and accelerates long-context processing.
Memory: Intelligent Context Management
-
Engram Memory (Selective Storage & Recall)
- The Concept: The AI stops rote memorizing and starts "understanding." It recognizes project structures, follows naming conventions (snake_case vs. camelCase), and identifies coding patterns (mimicking your team's specific factory patterns).
- The Result: It codes like a tenured employee.
-
Multi-Head Latent Attention (MLA)
- The Concept: Think of this as "super shorthand." Where other models need 100 tokens to store information, MLA compresses it into 10 key symbols.
- The Result: When recall is needed, the model mathematically reconstructs the original meaning without loss. This maintains incredible detail retention with significantly lower VRAM usage.
Application: Real-World Engineering
- Repo-Level Understanding & Bug Fixing
- The goal isn't just to write a function, but to control the codebase. In SWE-bench testing, DeepSeek v4 aims to resolve over 80.9% of real-world, complex issues by understanding cross-file dependencies.
Use Cases: Cutting Costs & Boosting Efficiency
DeepSeek v4 is built for hardcore engineering. Here is how it compares to the competition:
Refactoring Legacy Code
For undocumented, chaotic legacy systems, the mHC architecture is a lifesaver. It traces long-distance logical dependencies for safe refactoring.
- VS GPT-4o: GPT-4o often suffers from "logic hallucinations" (inventing non-existent function calls) when context exceeds 10k tokens. DeepSeek v4 maintains 100% logical consistency across long contexts.
- VS Claude 3.5 Sonnet: While Sonnet is high-quality, it is slow and expensive for massive refactoring jobs. DeepSeek v4’s MoE architecture offers ~40% faster inference speeds at a lower cost on Atlas Cloud.
Repo-Level Feature Development
When adding a new API to a mature project, v4 uses "Engram Memory" to instantly grasp the context.
- VS Traditional Autocomplete: Standard tools often ignore project-specific norms, introducing style inconsistencies. DeepSeek v4 mimics your existing codebase so well it feels like a copy-paste from your best developer.
Full-Link Bug Tracking
Targeting an 80.9% success rate on SWE-bench means handling bugs that span frontend, backend, and databases.
- VS Claude Opus 4.5 (Expected): Opus 4.5 will likely be powerful but priced at a premium. DeepSeek v4 offers near-SOTA performance at a price point that allows for iterative "reflection and correction" loops without breaking the bank.
📉 The Takeaway: ROI for Teams
For startups and dev teams, the DeepSeek v4 + AtlasCloud combo delivers tangible ROI:
- Productivity: Reduce coding time for senior devs by 30-50%.
- Cost: Compared to renting dual RTX 4090 servers or paying for closed-source APIs, AtlasCloud's integrated API can save teams over 60% in comprehensive compute costs.
The Hardware Red Line: Hosting Locally? Think Twice.
By now, you might be tempted to run this "Coding God" on your local machine. But we have to give you a reality check: Performance comes at a price.
- Minimum Entry:Dual RTX 4090s
- Translation: You are buying two of the most expensive consumer GPUs on the market and linking them. The cost of the GPUs alone is roughly equivalent to 3x iPhone 17 Pro Max devices (or a decent used car).
- Recommended:Single RTX 5090 (2026 Flagship)
- Translation: This is the "Ferrari" of GPUs. Not only will the price be sky-high due to scalpers, but availability will be scarce.
With GPU prices remaining high, ask yourself: Is it worth spending thousands of dollars and dealing with fan noise, heat, and environment configuration just to run one model?
The Smart Solution: Atlas Cloud Day 0 Access
You don't need to be rich to use DeepSeek v4; you just need to be smart. Instead of buying "electronic bricks" that depreciate, choose the cloud.
AtlasCloud is ready for the launch:
-
Our Promise: Enjoy your holiday. Leave the dirty work of deployment to us. We are monitoring the official release channels 24/7.
-
Core Advantages:
- Instant Access: As soon as the open-source weights drop, our API integration goes live.
- Zero Barrier: No expensive hardware, no CUDA dependency hell. Just bring your Prompt.
- Uncompromised Experience: We provide full context support, ensuring the "Engram" memory mechanism works at 100% capacity without quantization loss.
How to use on Atlas Cloud
Atlas Cloud lets you use models side by side — first in a playground, then via a single API.
Method 1: Use directly in the Atlas Cloud playground
Method 2: Access via API
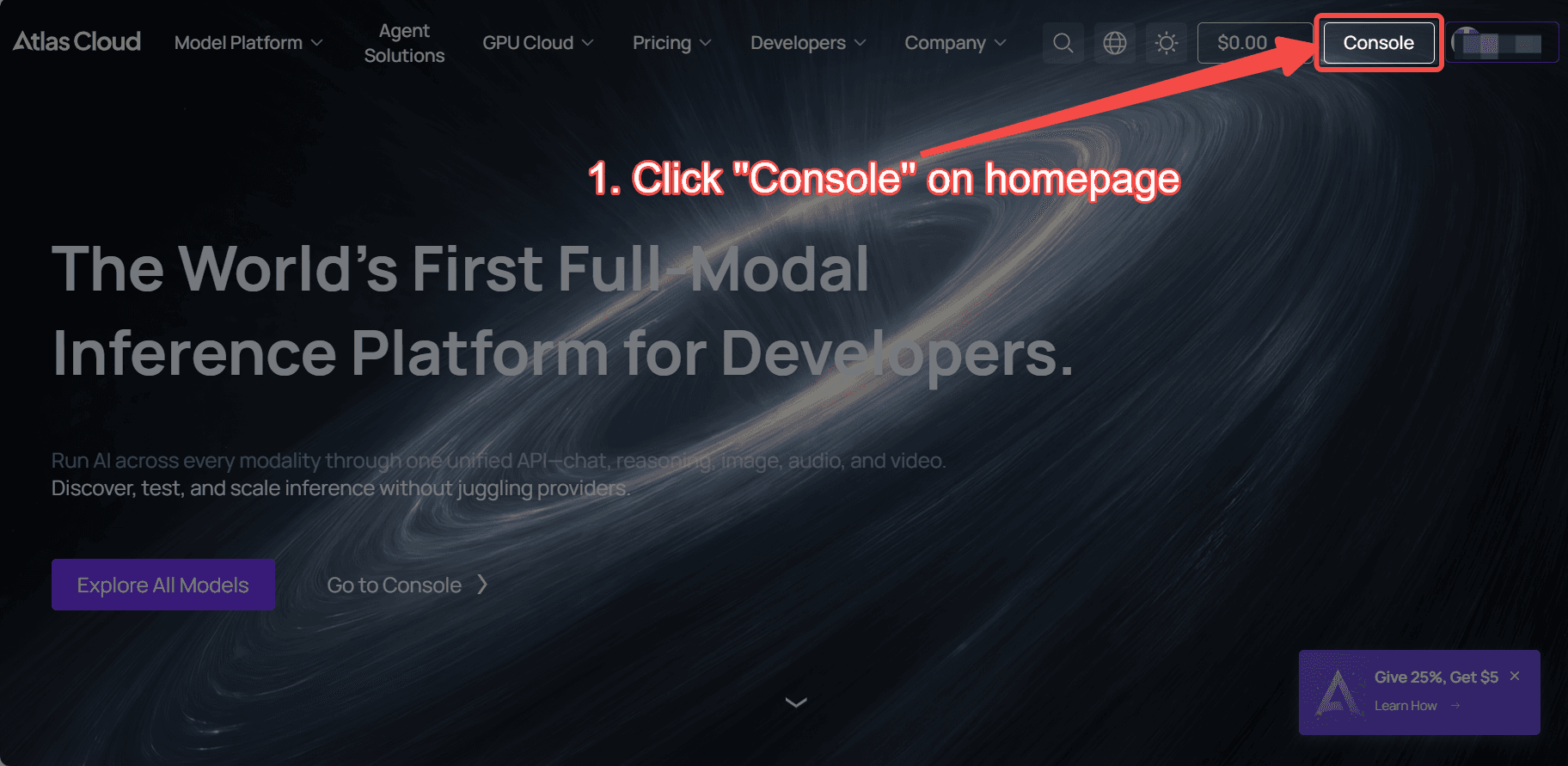
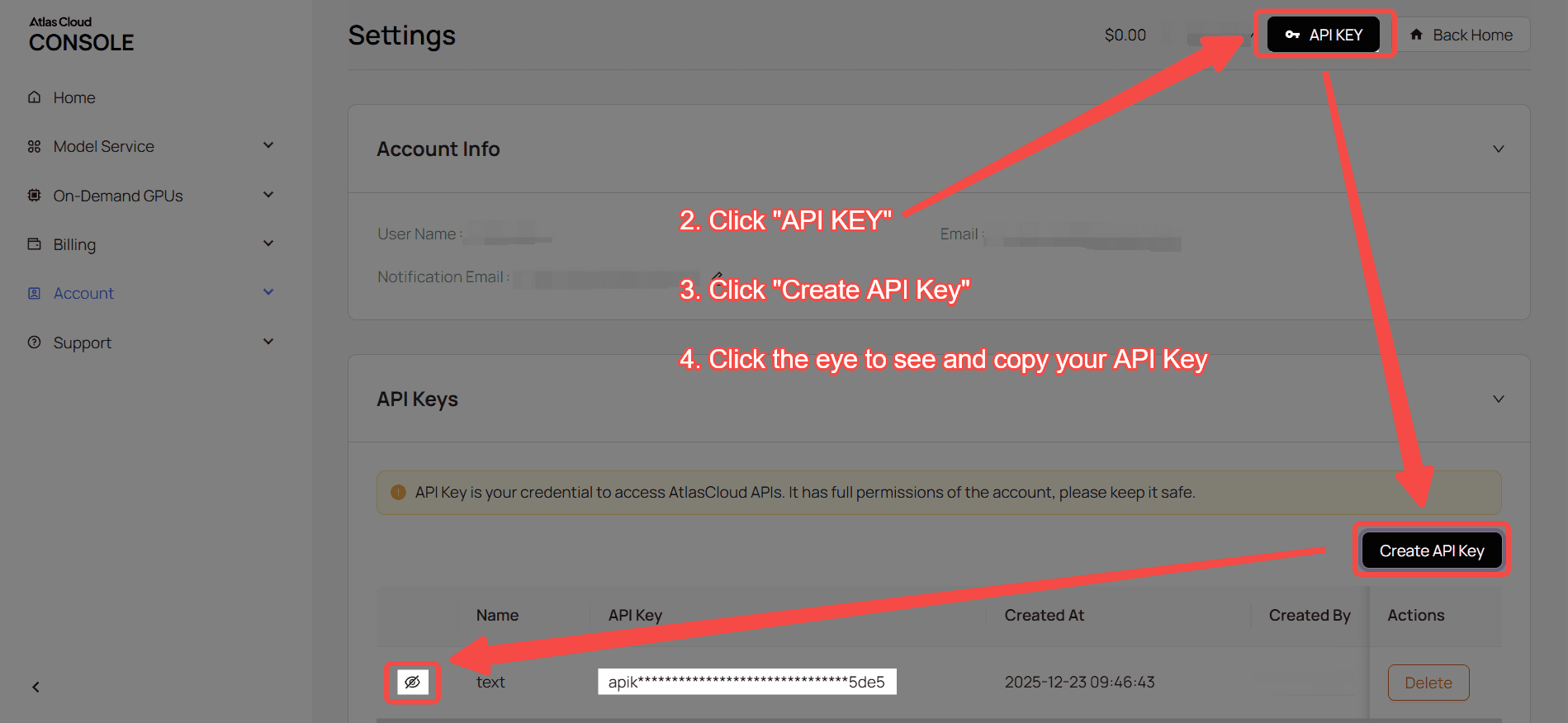
Step 1: Get your API key
Create an API key in your console and copy it for later use.
Step 2: Check the API documentation
Review the endpoint, request parameters, and authentication method in our API docs.
Step 3: Make your first request (Python example)
Example: generate a video with DeepSeek v3.2:
plaintext1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






