Gemini Omni stellt einen bedeutenden Wandel gegenüber herkömmlichen KI-Systemen dar. Es fungiert als All-in-One-KI-Modell, das Informationen von Grund auf natürlich verarbeitet. Anstatt verschiedene Werkzeuge für unterschiedliche Medientypen miteinander zu verknüpfen, läuft es vollständig auf einer einzigen, universellen neuronalen Engine. Durch die Verarbeitung von Text, Bild, Audio und Video innerhalb eines einzigen, kreuzmodalen Vektorraums eliminiert es veraltete Datensilos und Kommunikationsengpässe vollständig.
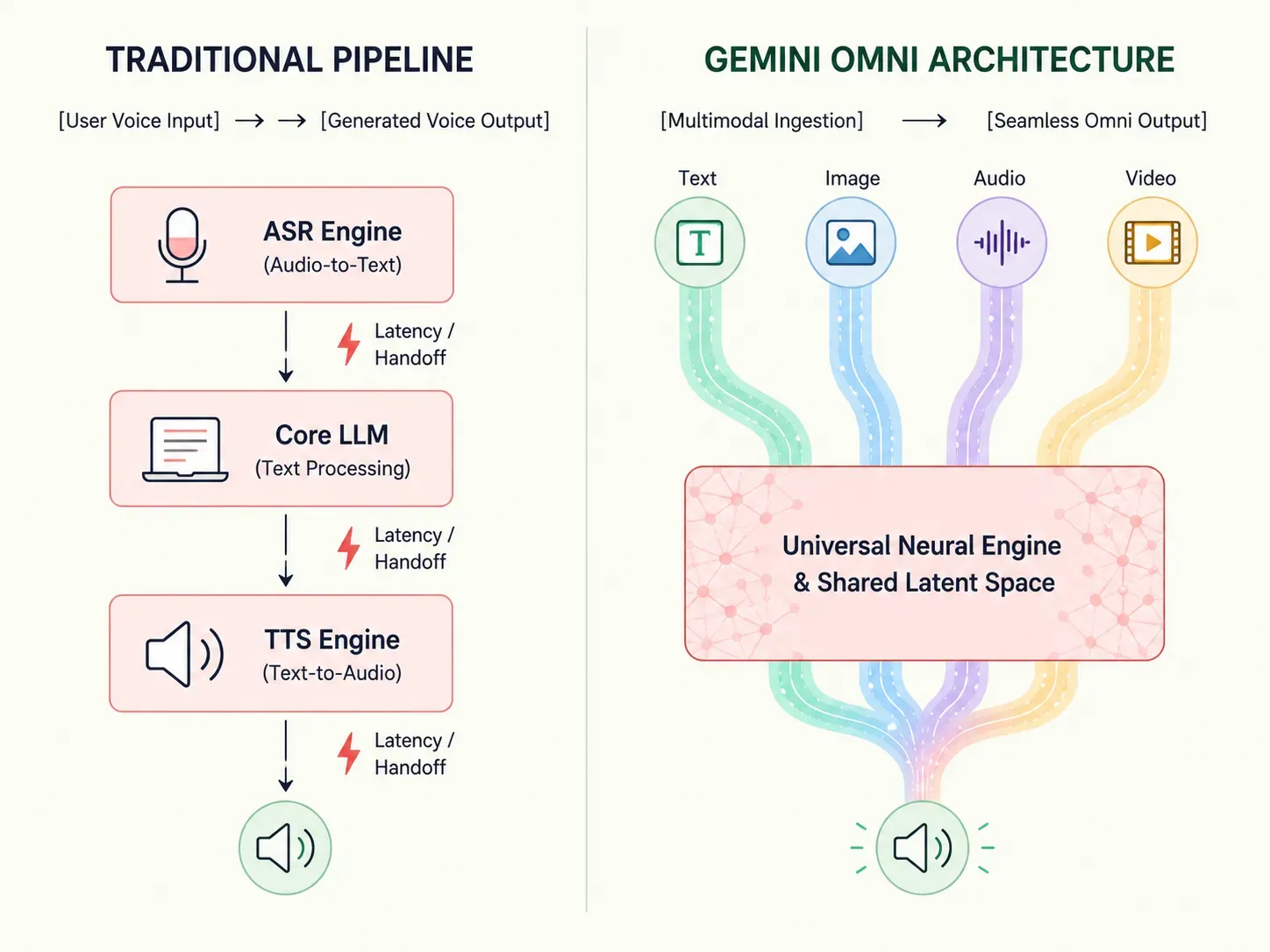
Herkömmliche künstliche Intelligenz basiert auf gestaffelten Pipelines, bei denen Sprache erst in Text umgewandelt werden muss, bevor ein Sprachmodell überhaupt mit der Verarbeitung einer Antwort beginnen kann. Gemini Omni definiert diesen Arbeitsablauf grundlegend neu.
- Native Ingestion: Das System verarbeitet Text-Token, Bildpixel, Audiofrequenzen und Videobilder zeitgleich.
- Kontexterhaltung: Die End-to-End-Datenverarbeitung verhindert, dass subtile Emotionen, visuelle Hinweise und kleine Details zwischen verschiedenen Ebenen verloren gehen.
Diese strukturelle Veränderung erhöht die Verarbeitungseffizienz und reduziert Verzögerungen auf nahezu menschliche Reaktionszeiten. Entwickler und Unternehmen können nun komplexe Multi-Modell-Setups überspringen und sich auf ein solides System verlassen, das für echtes multisensorisches Computing gebaut ist.
Wie ein Modell vier Modalitäten gleichzeitig berechnet
Um zu verstehen, wie Gemini Omni-Funktionen Text, Bilder, Audio und Video gleichzeitig verarbeiten, müssen wir einen direkten Blick auf die zentrale Datenschicht werfen. Herkömmliche Systeme leiten unterschiedliche Dateitypen durch separate, isolierte Sub-Modelle. Gemini Omni umgeht diesen fragmentierten Ansatz vollständig. Es implementiert ein einheitliches Tokenisierungs-Framework, das alle Eingaben nativ in eine einzige Sprache übersetzt, die der KI-Kern versteht.
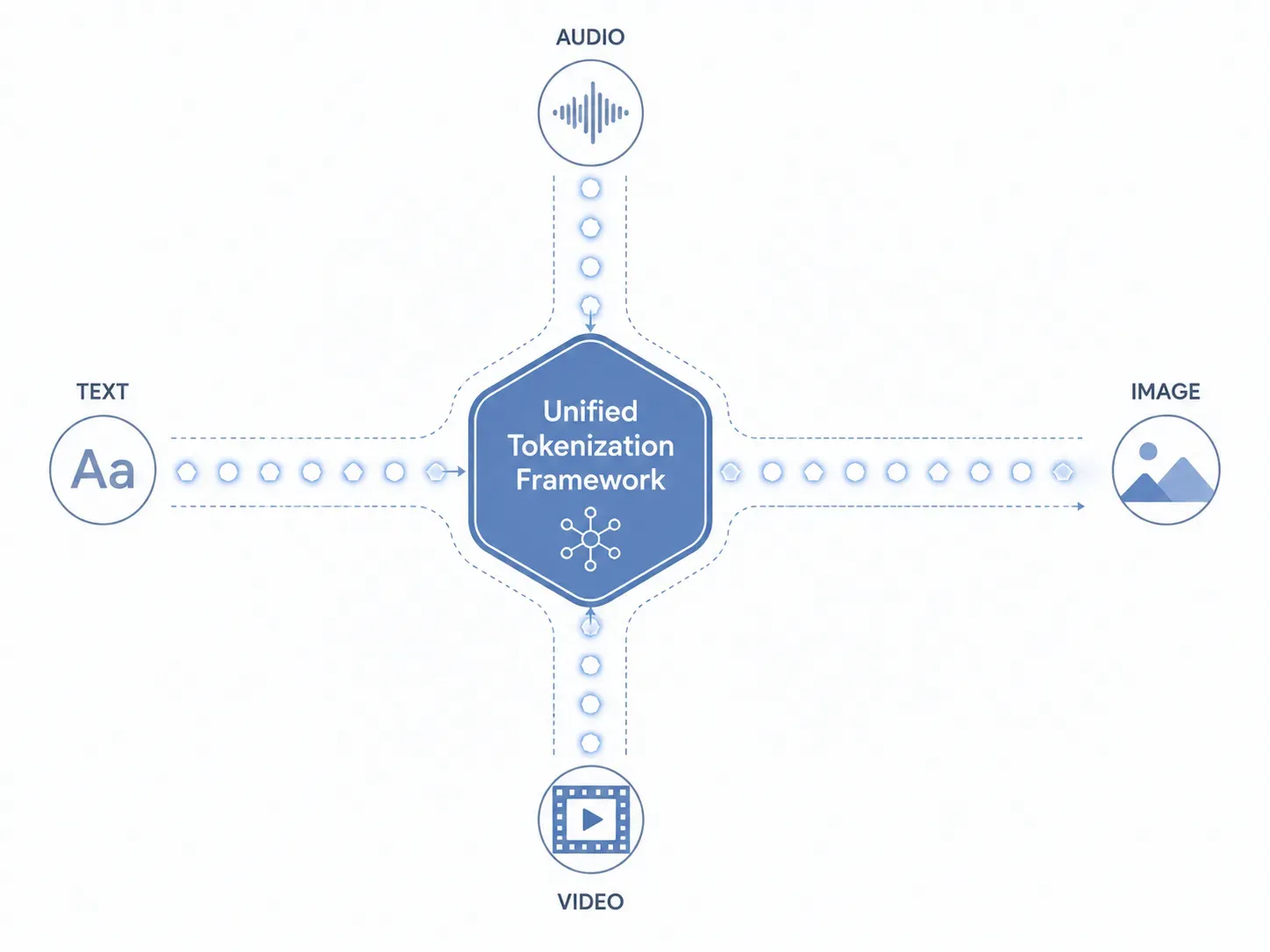
Die Mechanik der einheitlichen Tokenisierung
Wie verarbeitet Gemini Omni verschiedene Dateitypen ohne separate Sub-Modelle? Die Antwort liegt in der Art und Weise, wie die Daten aufgenommen und zerlegt werden, bevor die Inferenz beginnt:
- Text: Alphanumerische Zeichen werden in standardmäßige semantische Text-Token umgewandelt.
- Bilder: Visuelle Elemente werden in kleine Pixel-Patches unterteilt und als visuelle Token abgebildet.
- Audio: Kontinuierliche Schallwellen werden abgetastet, wobei Frequenz und Tonhöhe erfasst und in akustische Token transformiert werden.
- Video: Bewegte Bilder werden als eine kontinuierliche Sequenz von zeitlichen Einzelbildern (Frames) behandelt, wodurch räumlich-zeitliche Token entstehen.
Gemeinsame Gewichtungen und native Tensor-Verarbeitung
Sobald diese vielfältige multimodale Datenaufnahme abgeschlossen ist, fließen alle Datentypen in eine Architektur mit gemeinsamen Gewichtungen (shared weight architecture) ein. Anstatt einzelne spezialisierte Encoder zu verwenden, die Daten über latenzanfällige Brücken hin und her schicken, verarbeitet ein einziger neuronaler Kern alle Token einheitlich.
Durch die Nutzung der nativen Tensor-Verarbeitung führt das Modell mathematische Berechnungen für Text-, Audio- und visuelle Token innerhalb derselben Matrix-Ebenen aus. Da sich alles im selben Rechenraum befindet, versteht das Netzwerk die Beziehung zwischen einem gesprochenen Wort, einem geschriebenen Satz, einem Bildpixel und einem Videobild direkt, ohne einen einzigen Übersetzungsschritt.
Um diese technischen Prinzipien und die native Tokenisierung in realen Szenarien im Einsatz zu sehen, schauen Sie sich die Präsentation der Forschungsvision des MIT Media Lab an. Diese Präsentation skizziert den langfristigen Wandel der Industrie hin zur direkten Verbindung von KI-Modellen mit einem breiten Spektrum an Signalen aus der physischen und multisensorischen Welt:
Die zentralen Modalitätssäulen: Cross-Media-Verarbeitungskarte
Um die volle Leistungsfähigkeit von Gemini Omni zu begreifen, muss man über die reine Datenaufnahme hinausblicken. Das Modell nutzt eine einheitliche Architektur, bei der Text, Bilder, Audio und Video innerhalb eines gemeinsamen Latent-Space-Mappings existieren. Wenn sich eine Eingabe in einer Modalität ändert, löst dies nicht nur eine isolierte Reaktion aus – es verschiebt dynamisch die mathematischen Parameter der anderen drei Formate zur exakt gleichen Zeit.
Die multimodale Interdependenz-Matrix
Diese Cross-Media-Inferenz in Echtzeit beruht auf interdependenten Datenströmen. Anstatt Daten in sequenziellen Blöcken zu verarbeiten, synchronisiert das Modell kontinuierlich alle vier Säulen, um eine perfekte multimodale Ausrichtung zu erreichen.
Die folgende Verarbeitungskarte zeigt genau, wie sich diese Live-Eingaben innerhalb des universellen neuronalen Netzwerks gegenseitig beeinflussen:
| Primäre Medieneingabe | Mitverarbeitete Modalitäten | Systembetrieb | Tiefer technische Absicht |
| Akustische Wellenformen | Text + Videoframes | Verfolgt Stimmkadenz zur Indizierung zeitlicher Videosequenzen | Echtzeit-sensorische Ausrichtung |
| Statische Bilder | Rohes Audio + Text | Übersetzt visuelle Farbspektren in passende kontextuelle Akustik | Cross-modale Synthese |
| Alphanumerischer Code | Video-Arrays + Text | Modifiziert strukturelle Videovariablen direkt über Programmierlogik | Generative Code-Ausführung |
| Zeitliche Videosequenzen | Audiospuren + Code | Berechnet räumlich-zeitliche Updates über mehrschichtige Datenspuren | Einheitliches Video-Audio-Parsing |
Echtzeit-Parametersynchronisation in Aktion
Wenn Gemini Omni einen Live-Videostream verarbeitet, trennt es die Bilder nicht von der Hintergrundspur. Wenn der Audioeingang einen plötzlichen Frequenzanstieg registriert – zum Beispiel, wenn eine Person schreit –, aktualisiert das Modell sofort seine Erwartungen an die visuellen Token. Es antizipiert schnelle physische Bewegungen oder eine Verschiebung in den Videoframes, noch bevor diese eintreten.
Diese tiefe gegenseitige Beeinflussung verhindert ein Abdriften des Kontexts. Da das gesamte Netzwerk diese Variablen gleichzeitig ausbalanciert, bleibt die Ausgabe perfekt kohärent, egal ob das Modell eine synchronisierte Videozusammenfassung generiert oder einen multisensorischen Live-Stream spontan übersetzt.
Eliminierung von Latenz und Kontextdrift: Der Vorteil einheitlicher Gewichtungen
Um die Geschwindigkeit von Gemini Omni zu schätzen, hilft ein Blick auf die mathematischen Ineffizienzen traditioneller „gestitchter“ KI-Pipelines. Historisch gesehen erforderte der Aufbau eines sprach- oder videofähigen Assistenten das Hintereinanderschalten separater Softwareebenen mit jeweils eigenem Zweck.
plaintext1[Benutzer-Audioeingabe] 2 │ 3 ▼ 4 1. ASR-Engine (Audio-zu-Text-Transkription) 5 │ 6 ▼ 7 2. Kern-LLM-Ebene (Textgenerierungsverarbeitung) 8 │ 9 ▼ 10 3. TTS-Engine (Text-zu-Audio-Synthese) 11 │ 12 ▼ 13[Generierte Sprachausgabe]
Diese mehrstufige Orchestrierung zwingt Daten dazu, über kontinuierliche Softwarebrücken zu reisen, was die Ausführungsverzögerungen summiert. Die separate Text-to-Speech-Engine kann die ursprüngliche Audioaufnahme nicht „hören“. Dies führt zu einem massiven Datenverlust zwischen verschiedenen Medientypen. Wichtige vokale Hinweise, wie der sarkastische Tonfall, Zögern oder emotionaler Stress eines Benutzers, verschwinden vollständig, wenn alles in reinen Text umgewandelt wird.
Erzielung einer echten Reduzierung der Pipeline-Latenz
Gemini Omni umgeht diese Grenzen durch den Betrieb mit einheitlichen neuronalen Gewichtungen. Da ein einziges neuronales Netzwerk Text, Audio und Pixel nativ unter einem mathematischen Dach bewertet, skaliert es die Ausführungsgeschwindigkeiten drastisch. Dieses Layout führt zu einer tiefgreifenden Reduzierung der Pipeline-Latenz.
Laut Benchmarking-Berichten von Google DeepMind senken native multimodale Architekturen, die Live-Audio-Streams verarbeiten, die End-to-End-Reaktionszeiten auf unter 150 Millisekunden. Diese Verschiebung entspricht effektiv dem natürlichen Tempo der menschlichen Konversation in Echtzeit.
Optimierung der Kontexterhaltung
Über die reine Geschwindigkeit hinaus sorgt die einheitliche Ausführung für eine hohe Optimierung der Kontexterhaltung. Wenn Sie mit dem Modell sprechen, verarbeiten die Gewichtungen Ihre Audiofrequenzen gleichzeitig mit Ihren textuellen Definitionen.
- Intonationsverarbeitung: Das Netzwerk erfasst vokale Modulationen direkt und reagiert mit angemessener Empathie oder Dringlichkeit.
- Visuelle Synchronisation: Subtile mikromimische Gesichtsausdrücke oder räumliche Bewegungen innerhalb eines Videoframes werden ohne Parsing-Fehler direkt in die Konversationsausgabe übersetzt.
Durch das Entfernen von Zwischenübersetzungsschritten verhindert Gemini Omni, dass kleine Details verblassen. Dies schafft eine solide Grundlage für flüssige, natürliche Interaktionen zwischen Mensch und Maschine über verschiedene Sinne hinweg.
Aufbau von Unternehmens-Workflows mit Omni-Channel-KI-Systemen
Dieser Wandel hin zur nativen Multimodalität verändert die Art und Weise, wie Unternehmen digitale Tools entwickeln und skalieren. Durch den Einsatz eines einzigen All-in-One-KI-Setups können Unternehmen komplexe, separate Softwarekomponenten durch einheitliche Workflows ersetzen. Dies ermöglicht ihnen den einfachen Betrieb interaktiver Mixed-Media-Systeme in großem Maßstab.
Die Single-API-Architektur
Entwickler müssen keine disparaten Cloud-Funktionen für Spracherkennung, Textanalyse und Bildverarbeitung mehr koordinieren. Stattdessen verbindet eine einzige, einheitliche API-Integration die Anwendungsebene direkt mit dem Kernnetzwerk, wie zum Beispiel die Atlas Cloud KI-Modell-API. Dieser optimierte Pfad ermöglicht es Teams, fortschrittliche Cross-Media-Pipelines mit einem einzigen Anforderungs-Framework zu konstruieren.
plaintext1 ┌─────────────────────────────────┐ 2 │ Einheitliche Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Echtzeit-Code │ │ Mixed-Media-Daten│ │ Multisensorische │ 9│ & Asset Sync │ │ Automatisierung │ │ Dashboards │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
Beispielsweise kann eine Trainingsplattform für Unternehmen einen Live-Videostream verarbeiten, die Audiofrequenz eines Sprechers verfolgen, den Dialog übersetzen und gleichzeitig dynamisch ein visuelles Daten-Dashboard aktualisieren – alles gesteuert durch ein einziges Backend-System.
Strategische Bereitstellungsvorteile
Welche Vorteile bietet der Umstieg auf eine All-in-One-Modellarchitektur für die Bereitstellung?
Der Wechsel von alten Multi-Modell-Setups zu einem einzelnen neuronalen Netzwerk bietet unmittelbare, solide Vorteile für IT-Systeme von Unternehmen:
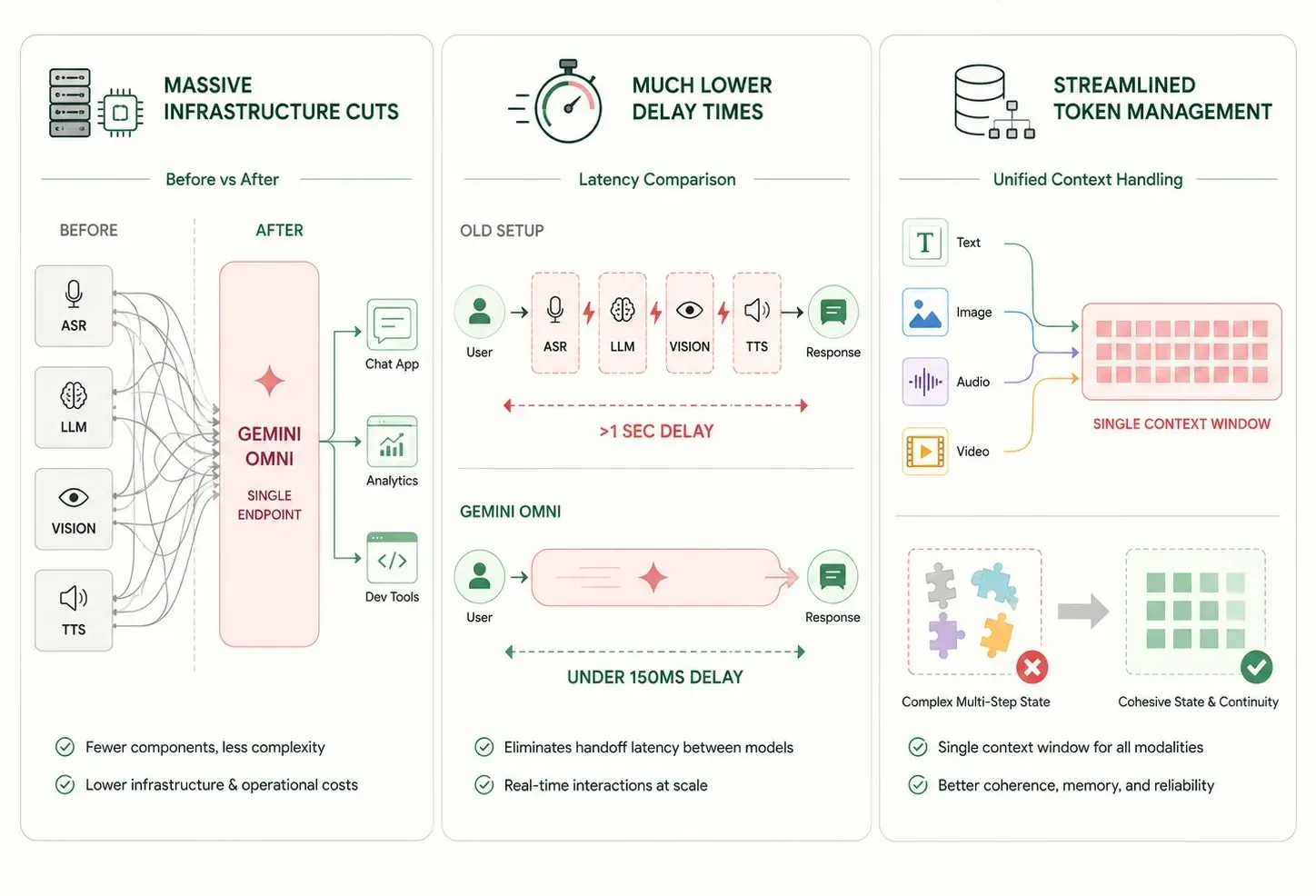
- Massive Infrastruktureinsparungen: Die Zusammenlegung von Text-, Vision- und Audioaufgaben in ein einziges Modell reduziert die Anzahl separater Software-Endpunkte. Dies macht die langfristige Wartung wesentlich einfacher.
- Deutlich geringere Verzögerungszeiten: Das Überspringen zusätzlicher Netzwerkschritte zwischen kleinen, spezialisierten Tools senkt die Reaktionszeiten auf unter eine Sekunde. Dies ermöglicht echte Echtzeit-Benutzererlebnisse.
- Optimiertes Token-Management: Ein einzelnes Kontextfenster, das alle Modalitäten einheitlich verfolgt, reduziert komplexe Probleme bei der Zustandsverwaltung über mehrstufige Prozesse hinweg.
Skalierbare multimodale Bereitstellung erreichen
Durch die Arbeit mit Frameworks wie der Gemini Enterprise Agent Platform können Unternehmen Netzwerke autonomer Sub-Agenten nahtlos koordinieren. Dieses System erleichtert den Betrieb groß angelegter Multimedia-Projekte. Es nutzt verwaltete Setups, die den Hintergrundkontext und die Benutzeridentität über Workflows hinweg verfolgen, die tagelang dauern können. Indem unterschiedliche Eingaben in einem sicheren Raum gehalten werden, können Unternehmen Aufgaben über verschiedene Medien hinweg von Anfang bis Ende automatisieren, ohne Daten zu verlieren oder den Überblick über das Hauptthema zu verlieren.
Rechenbeschränkungen und Hardwareoptimierung für globale KI-Inferenz
Während die Verarbeitung von vier separaten Datenströmen unter einer einheitlichen Netzwerkarchitektur nahtlose Cross-Media-Workflows ermöglicht, stellt sie auch beispiellose Anforderungen an die moderne Hardwareinfrastruktur. Die Navigation in dieser Umgebung erfordert ein sorgfältiges Compute-Ressourcen-Management, um die extremen physischen Auswirkungen der gleichzeitigen, multisensorischen Verarbeitung in globalem Maßstab zu überwinden.
Der Overhead der multimodalen Tokenisierung
Die größte technische Herausforderung ergibt sich aus dem multimodalen Token-Overhead. Im Gegensatz zu standardmäßigen alphanumerischen Textdatensätzen erzeugen hochauflösende Bilder, rohe Audiofrequenzen und sequenzielle Videodateien enorme Mengen an numerischen Daten.
- Textverarbeitung: Eine einzelne geschriebene Seite verwandelt sich in etwa 1.000 dichte, aussagekräftige Token.
- Visuelle Verarbeitung: Eine Minute rohes Videomaterial, in feste Bildschritte und Pixelblöcke geschnitten, zerfällt in Hunderttausende von visuellen Token.
Wenn ein einziger Modellkern diese Medientypen zusammen verarbeitet, führt dies zu einem exponentiellen Anstieg der Kontextfensterdichte. Der Aufmerksamkeits-Mechanismus des Systems muss bewerten, wie jedes einzelne Token mit jedem anderen Token in Beziehung steht, was die High Bandwidth Memory (HBM)-Kapazitäten auf dem Chip überfordern und die Verarbeitungsschichten sättigen könnte.
Beschleunigung von Workloads durch TPU-Cluster-Skalierung
Um diesem Engpass entgegenzuwirken, setzen Unternehmensinfrastrukturen auf spezialisierte Hardwareplattformen, die speziell für multisensorisches Computing entwickelt wurden. Googles neueste Architektur nutzt TPU-Cluster-Skalierung, um diese intensiven, einheitlichen Token-Workloads über mehrschichtige Rechenzentrumsumgebungen zu verteilen.
plaintext1 ┌─────────────────────────┐ 2 │ Einheitliche Gemini-Token│ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore-Array │ │ TensorCore-Array │ 9│ (Parallele Matrix-Arithmetik) │ │ (Parallele Matrix-Arithmetik) │ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Optische Verbindung │ 16 │ (Ultra-Low Latency ICI) │ 17 └─────────────────────────┘
Hardware-Setups wie die Trillium TPU v6e-Plattform liefern eine beeindruckende 4,7-fache Steigerung der Spitzen-Rechenleistung pro Chip im Vergleich zu älteren Hardware-Generationen. Diese spezialisierte Architektur bewältigt die massiven Anforderungen durch die Kombination optimierter Matrix-Ausführungseinheiten mit tiefgreifenden physischen Infrastrukturlayouts:
| Hardware-Engine-Schicht | Architektonische Spezifikationen | Hauptsystemfunktion |
| Erweiterte TensorCore-Arrays | Doppelte Matrix-Multiply-Unit (MXU)-Fläche | Führt intensive parallele Arithmetik auf dichten Video-Tensoren aus. |
| High-Bandwidth HBM | Bis zu 32 GB HBM pro Chip | Hält riesige Token-Arrays vollständig auf dem Silizium, um Speicherengpässe zu verhindern. |
| Next-Gen Inter-Chip Interconnect | 800 GBps bidirektionale Bandbreite | Synchronisiert Parametervariablen über zehntausende von Chips ohne Verzögerung. |
Durch die Nutzung kundenspezifischer optischer Netzwerk-Fabrics neben diesen tiefen Speicherkonfigurationen können Cloud-Infrastrukturen dynamisch skalieren, um Eingabeparameter mit mehreren Millionen Token zu verarbeiten. Dies ermöglicht es Unternehmen, fortschrittliche Echtzeit-KI-Agenten global bereitzustellen, ohne Speicherstaus oder Systemausfälle zu riskieren.
Eine einheitliche API für die Produktion von Videogenerierung
Während Google Gemini Omni Flash innerhalb der Gemini-App und Google Flow für Endbenutzer ausrollt, benötigen Entwickler und Produktteams, die dieselbe multimodale Video-Engine in ihre eigenen Workflows einbetten möchten, eine stabile, vorhersehbare API-Ebene.
Atlas Cloud stellt Gemini Omni Flash über eine einheitliche, OpenAI-kompatible API bereit, zusammen mit über 300 anderen Bild-, Video- und LLM-Modellen – sodass Sie Googles natives multimodales Modell integrieren können, ohne separate Anbieterkonten, Abrechnungsportale oder SDKs jonglieren zu müssen.
Beide Gemini Omni Flash-Varianten sind live auf Atlas Cloud:
| Variante | Am besten für | Eingaben | Auflösung | Dauer | Startpreis |
| Gemini Omni Flash Text-to-Video (Developer) | Reine prompt-gesteuerte filmische Generierung | Text (bis zu 20.000 Zeichen) | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
| Gemini Omni Flash Image-to-Video (Developer) | Subjekt-konsistente Videos aus echten Referenzen | Text + bis zu 7 Referenzbilder | 720p / 1080p / 4K | 4, 6, 8, 10 s | $0.2 + $0.1/sec |
Quick Start — Generieren Sie ein Gemini Omni Flash-Video in 5 Zeilen:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
Die API gibt sofort eine Vorhersage-ID zurück — rufen Sie /api/v1/model/prediction/{id} ab, um die gerenderte MP4-URL zu erhalten. Das vollständige Schema, Code-Beispiele in 7 Sprachen und ein No-Code-Playground sind auf den oben verlinkten Modellseiten verfügbar.
Fazit: Zukunftssicherung für einheitliche maschinelle Intelligenz
Die Ankunft von Gemini Omni verändert die Paradigmen des Entwicklerdesigns grundlegend und verlagert die Industrie weg vom Zusammenfügen separater Werkzeuge hin zur Bereitstellung einheitlicher Ein-Schicht-Lösungen. Anstatt komplexe Integrationsbrücken zwischen isolierten APIs zu verwalten, können sich Ingenieure nun auf Maschine-Learning-Frameworks der nächsten Generation verlassen, die interdependente Datenströme unter einem mathematischen Dach verarbeiten.
plaintext1[Legacy Software Pipeline] 2Separate Text-API ──┐ 3Separate Audio-API ─┼──► Manuelle Pipeline-Blöcke ──► Fragile Produktion 4Separate Video-API ──┘ 5 6[Einheitliche Omni-Architektur] 7Universelle Token ──► Natives Ein-Schicht-Modell ──► Nahtlose Automatisierung
Dieser strukturelle Wandel erfordert eine vollständige Überarbeitung der Art und Weise, wie wir digitale Produkte entwickeln. Um wettbewerbsfähig zu bleiben, müssen technische Teams sich von statischen Datensilos abwenden und Standard-Software-Ökosysteme auf native multisensorische Systeme vorbereiten.
Durch den direkten Betrieb auf einem hochoptimierten Cloud-Backbone wie der Google Cloud KI-Infrastruktur können Unternehmen diese intensiven Token-Workloads skalieren, ohne das Risiko eines systemischen Kontextdrifts oder Latenzeinbußen einzugehen. Letztendlich bedeutet die Zukunftssicherung Ihrer Entwicklungspipeline, Lösungen um eine einzelne, zusammenhängende Engine herum zu konzipieren, die darauf ausgelegt ist, die physische Welt ganzheitlich zu verstehen.






