Am 19. Mai 2026 stellte Google auf der Google I/O DeepMind Gemini Omni vor. Am selben Tag ging der Gemini Omni Prompt-Leitfaden auf der Dokumentationsseite von DeepMind online – versteckt zwischen der Modellkarte für Omni Flash und den API-Hinweisen. Die meisten Leute sahen sich die Keynote-Demos an. Das Dokument blieb weitgehend ungelesen.
Zuerst die Fakten: Gemini Omni ist das neue multimodale Generierungsmodell von DeepMind. Das erste Produkt, Gemini Omni Flash, erstellt bis zu 10-sekündige Videos aus jeder beliebigen Kombination von Text-, Bild-, Audio- oder Videoeingaben. Jede Ausgabe trägt ein SynthID-Wasserzeichen. Abonnenten von AI Plus, AI Pro und AI Ultra erhielten sofortigen Zugriff; Nutzer von YouTube Shorts und der YouTube Create App erhalten ab dieser Einführungswoche kostenlosen Zugriff (laut Bericht von Gagadget). Der API-Zugriff kommt laut Google „in den nächsten Wochen“.
Zurück zum Prompt-Leitfaden. Der Leitfaden von Google DeepMind verdeutlicht den Wandel direkt im Abschnitt „World understanding“ (Weltverständnis):
Mit Veo müssen Sie präzise Anweisungen geben, um die besten Ergebnisse zu erzielen. Bei Gemini Omni müssen Sie jedoch nicht so präzise sein. Sagen Sie Omni einfach, was Sie erstellen möchten – und beobachten Sie, wie das logische Verständnis und das Weltwissen des Modells die Details zum Leben erwecken.
Die Übersetzung: Schreiben Sie weniger.
Betrachten Sie dies im Vergleich zu den Prompt-Leitfäden, die ByteDance und Kuaishou für ihre eigenen Videomodelle veröffentlichen. Die Rahmenbedingungen unterscheiden sich, deuten aber in dieselbe Richtung.
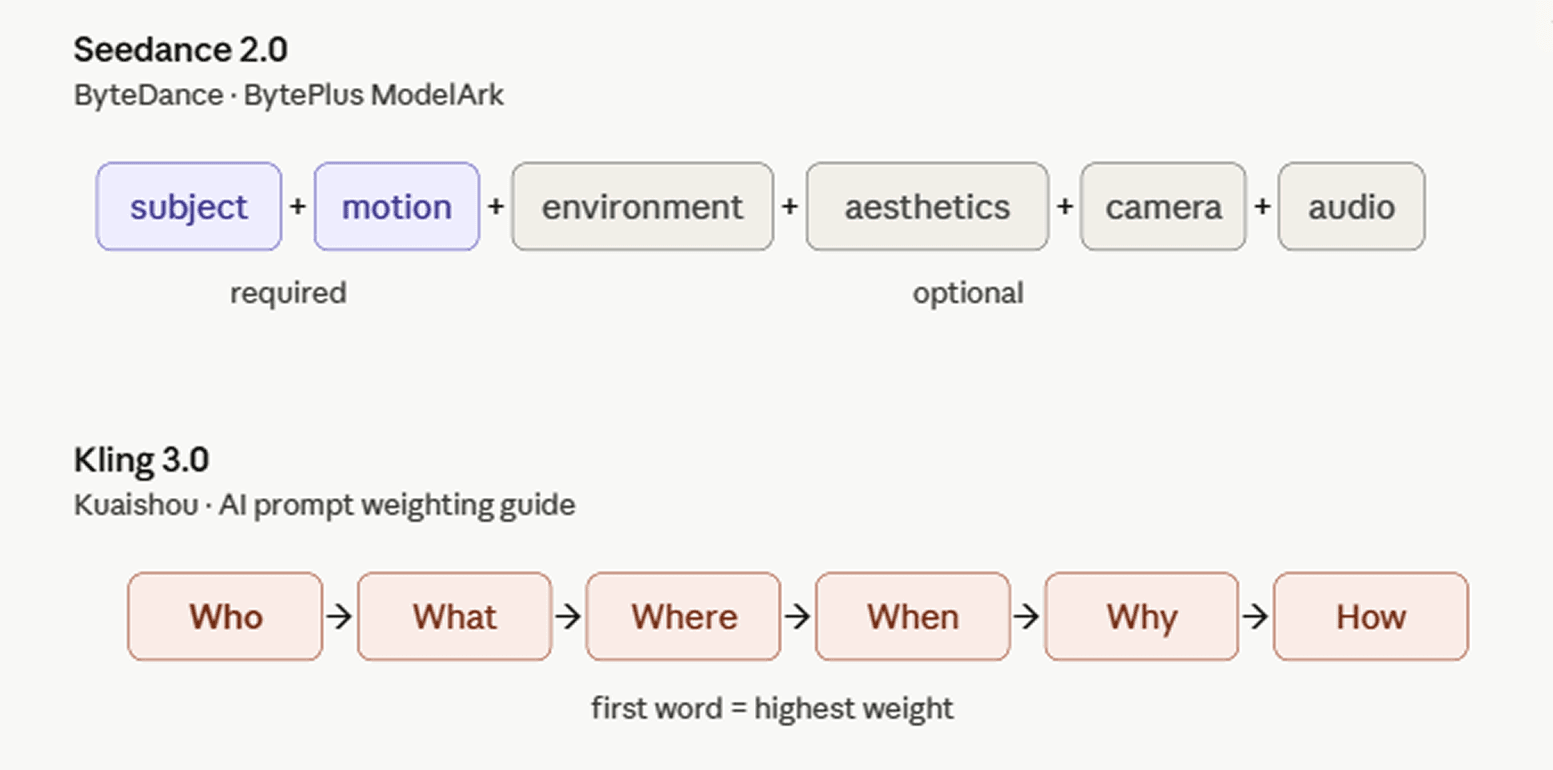
ByteDance dokumentiert Seedance 2.0 auf seiner internationalen Entwicklerplattform mit dem BytePlus ModelArk Prompt-Leitfaden. Die empfohlene Struktur: Subjekt + Bewegung (+ Umgebung + Ästhetik + Kamerabewegung/Schnitt + Audio). Nicht jede Komponente ist erforderlich; Sie wählen, was zur Aufnahme passt.
Der Kuaishou KI-Prompt-Gewichtungsleitfaden nutzt eine 5W1H-Formel: Wer + Was + Wo + Wann + Warum + Wie. Das „Wer“ – das Subjekt – hat normalerweise die höchste Priorität und steht am Anfang des Prompts, da die Wortposition in Kling 3.0 das Gewicht bestimmt: Was zuerst kommt, erhält die meiste Aufmerksamkeit bei der Berechnung. Stilistische Entscheidungen wie Medium oder Perspektive funktionieren am Ende am besten und wirken als Filter über der bereits etablierten Szene. Der Leitfaden warnt davor, Elemente blind zu stapeln; zu viele widersprüchliche Schlüsselwörter mindern die Qualität.
Drei Unternehmen kamen unabhängig voneinander zu diesem Rat, was darauf hindeutet, dass ihre Modelle etwa zur gleichen Zeit ein ähnliches Leistungsniveau erreicht haben. Google rät dazu, weniger zu schreiben, ByteDance stuft die meisten Komponenten als optional ein und Kuaishou betont die Wortreihenfolge gegenüber der reinen Menge. Die spezifische Formulierung unterscheidet sich, aber alle drei Labore führen die Ersteller zu lockeren, natürlicheren Prompts.
Kommen wir nun dazu, wie sich der Gemini Omni Prompt-Leitfaden in der Praxis auswirkt.
Gemini Omni Prompt-Struktur: 5 Dimensionen von Google DeepMind
Der Leitfaden beginnt mit einem vollständigen Beispiel:
Eine Weitwinkel-Tracking-Aufnahme gleitet sanft über einen ruhigen See und enthüllt ein kolossales, reflektierendes, chromartiges, bohnenförmiges Objekt, das mühelos darüber schwebt und sich langsam dreht, um seine verzerrten Spiegelungen majestätischer Klippen und ein kleineres, ähnliches Objekt freizugeben, das teilweise im klaren azurblauen Wasser darunter untergetaucht ist, während eine strahlende Sonne hinter der schwebenden Anomalie untergeht und die gesamte Szene in klares, ätherisches Tageslicht mit lebendigen Blau- und Grüntönen taucht, was eine filmische und ehrfurchtgebietende Atmosphäre schafft, unterstrichen von einer majestätischen und außerweltlichen Orchestermusik, die die Weite und das Geheimnis der fremden Landschaft betont, mit schwachen, tiefen Summtönen, die vom schwebenden Objekt ausgehen.
Über 90 Wörter. Zerlegen Sie es und Sie erhalten 5 Dimensionen.
- Kameraeinstellung und Bewegung. Weitwinkel, Medium oder Nahaufnahme? Soll die Kamera sanft gleiten oder plötzlich rasen? Die beiden Verben erzeugen merklich unterschiedliche Ergebnisse, daher lohnt sich ein wenig Ausprobieren, wenn Sie nach dem richtigen Bewegungsgefühl suchen.
- Stil. Realistisch, filmisch, ätherisch, majestätisch? Diese Dimension braucht keine Details. Geben Sie dem Modell den emotionalen Ton vor, das reicht.
- Beleuchtung. Woher kommt das Licht? Die Sonne, eine Straßenlaterne, auf oder außerhalb der Kamera? Soll es sich klar, warm oder ätherisch anfühlen?
- Szene. Ein Satz im Leitfaden ist besonders hervorzuheben: „Sie müssen nicht jedes kleinste Detail beschreiben, da Omni mit Ihrer allgemeinen Absicht arbeitet.“ Das deckt sich mit dem, was Seedance und Kling in ihren offiziellen Dokumenten sagen.
- Aktion und Interaktion. Wer und was ist in der Szene, wie bewegen sie sich, wie interagieren sie?
Gemini Omni Konversationelle Bearbeitung vs. Veo Prompt-Rewriting
Omni und Veo erzeugen eine vergleichbare Generierungsqualität. Der eigentliche Unterschied liegt darin, was Sie tun können, nachdem das Video generiert wurde.
Früher bedeutete die Änderung eines Details, den gesamten Prompt neu zu schreiben, neu zu generieren und darauf zu hoffen, dass die Konsistenz zwischen den Frames erhalten blieb. Omni ersetzt diesen Schritt durch ein Gespräch.
Der offizielle Leitfaden bietet einige Beispiele.
Ein Stop-Motion-Video eines kleinen Jungen. Erste Bearbeitung: „Ändere den Schmetterling in eine Biene.“ Als Nächstes: „Ändere die Biene in einen kleinen Schwarm Glühwürmchen.“ Ein Element ändert sich pro Schritt; andere Frames bleiben automatisch erhalten.
Bei der Kamera funktioniert es genauso. Ein Video eines Geigers erhält drei Befehle hintereinander: „Transportiere den Geiger in die Bildumgebung“, „mache die Geige unsichtbar“, „ändere den Kamerawinkel so, dass er über die Schulter des Geigers blickt.“ Umgebungswechsel, Objektentfernung, Kamerapositionierung – alles durch natürliche Sprache.
Es gibt einen Haken: Externe Tester merken an, dass Omni dazu neigt, zu stark zu bearbeiten, wenn die Anweisung zu vage ist, und Elemente verändert, die man behalten wollte. Googles Empfehlung: Ändern Sie eine Variable pro Schritt und geben Sie explizit an, was gleich bleiben soll.
Das Beispiel zur kanalübergreifenden Synchronisierung ist interessanter. Nehmen Sie ein nächtliches Video eines Wohnhauses und fügen Sie die Anweisung hinzu: „Die Lichter der Wohnungen beginnen sich im Takt zur Musik einzuschalten.“ Das Modell analysiert die Beats im Soundtrack und richtet die Fensterlichter danach aus. Dies in After Effects zu tun, erfordert eine Zeitleiste, ein Metronom und manuelles Keyframing Frame für Frame.
Die 4 fortgeschrittenen Fähigkeiten von Gemini Omni: Weltwissen, Text-Rendering, Aktionsreferenz, Multi-Input
Die zweite Hälfte des Leitfadens gliedert 4 Fähigkeiten auf.
Angewandtes Weltwissen
Der Beispiel-Prompt: Erkläre den Unterschied zwischen regulärem Computing und Quantencomputing. Visualisiere diesen Satz in einem zeitgenössischen Flat-Media-Stil, der minimalistische Vektorformen mit satten organischen Texturen verbindet. Die Ästhetik wird durch eine kontrastreiche, „elektrische“ Farbpalette aus Neonpink, Cyan und Limettengrün vor einem tiefseeblauen Hintergrund definiert. Ein Markenzeichen dieses Stils ist die Verwendung von Punktierungsschattierungen und körnigen Verläufen, die den ansonsten einfachen geometrischen Formen eine taktile, Risograph-artige Qualität verleihen. Durch die Kombination scharfer Kanten mit diesen weicheren, gesprenkelten Übergängen erhält die Illustration eine verspielte, editorische Anmutung.
Das Modell weiß bereits, was Quantensuperposition ist und wie man sie durch eine Reihe vergleichbarer Aufnahmen vermittelt. Der Nutzer muss keine Quantenmechanik erklären, nur den visuellen Ton.
Das funktioniert, weil Omni auf einem hochmodernen Reasoning-Modell läuft, was reine Video-Generierungsmodelle nicht leisten können. Demis Hassabis bezeichnete Omni in einem Semafor-Interview nach der I/O als einen Schritt im Projekt, eine KI zu bauen, die die reale Welt besser versteht. Er wies darauf hin, dass Waymo, Alphabets Abteilung für autonomes Fahren, bereits ähnliche Weltmodelle testet, um autonomen Autos eine Art „Vorstellungsvermögen“ für den Umgang mit unvorhersehbaren Situationen zu geben. Die Videogenerierung ist nur die sichtbarste Anwendung dieser Architektur.
Text-Rendering
Der Beispiel-Prompt: Wort für Wort, jeweils ein Wort auf dem Bildschirm, jedes Wort in einem anderen animierten Stil, perfektes Tempo im Rhythmus, Sizzle-Reel.
Komplexe Aktionsreferenz
Beispiel-Prompt: Bearbeite dies, wobei alles gleich bleibt, füge animierte Bewegungseffekte hinzu, die vom Skateboard ausgehen.
Multi-Input-Referenz
Beispiel-Prompt: Die Vögel aus dem Video bilden lose die unvollkommene Form eines Vogels basierend auf dem Bild. Sie bewegen sich zur Musik aus dem Audio und lösen sich auf, während sie davonfliegen.
Stilübertragung (Style Transfer)
Beispiel-Prompt: Erstelle eine vierteilige stilistische Progression der Videoreferenz, die mit einer lebendigen, wachsartigen Buntstift-Ästhetik beginnt, mit satten, texturierten Strichen und verspielten, handgezeichneten Charakterdesigns vor einem Hintergrund aus stark granuliertem Papier. Übergang nahtlos zu einer Graphitstift-Skizze auf strukturiertem Papier unter Verwendung von Kreuzschraffuren, variierenden Linienstärken und einem 12-fps „Line Boiling“-Effekt, um ein handgezeichnetes Gefühl zu betonen. Gehe dann in einen hyperrealistischen, durchscheinenden 3D-Glasstil über, charakterisiert durch komplexe Lichtbrechungen, kaustische Muster und weiches internes Leuchten in einer minimalistischen Studio-Umgebung. Schließe die Sequenz mit einem taktilen Risograph-Druck-Look ab, unter Verwendung einer begrenzten Dreifarben-Palette, körnigen Halbton-Texturen und bewussten Register-Überlagerungen für ein Retro-Finish.
Storyboard-Referenz
Prompt: Zeig mir diese Story. Folge der Story exakt in der Reihenfolge, beginnend oben links. Die gesamte Story in 10 Sekunden. Filmisch.
Konsistenz über Aufnahmen hinweg
Warum die Prompt-Ratschläge von Gemini Omni, ByteDance Seedance und Kuaishou Kling konvergieren
Zurück zur früheren Beobachtung: Die Ähnlichkeit der Prompt-Ratschläge von Seedance, Kling und Omni ist kein Ergebnis gegenseitiger Kopien. Es ist plausibler, dass diese Generation von Modellen von sich aus ein ähnliches Leistungsniveau erreicht hat.
Sobald ein Modell natürliche Sprache auf Szenenebene verarbeiten, Details durch Weltwissen ergänzen und daraus ableiten kann, was der Nutzer tatsächlich meint, wird eine zu starke Vorgabe zum Engpass. Die drei Labore sind sich zwar uneinig darüber, wie viel Struktur man wieder hinzufügen sollte, sind sich aber einig, dass die Lösung nicht darin besteht, immer mehr zu schreiben.
Dies ist das Ergebnis von zwei Jahren Diffusionsmodellen, die gemeinsam mit großen Sprachmodellen trainiert wurden. Omni bringt das Ergebnis in einen relativ vollständigen Zustand.
Gemini Omni via Atlas Cloud nutzen: Vereinheitlichte API für Seedance, Kling, Veo
Gemini Omni kommt zu Atlas Cloud. Atlas Cloud aggregiert über 300 KI-Modelle für Text, Bild, Video und Audio. Die wichtigsten Videomodelle laufen bereits auf der Plattform: Seedance 2.0, Kling 3.0, Wan 2.7, Veo und andere. Für einen direkten Vergleich siehe den Wan 2.7 vs. Seedance 2.0 vs. Kling 3.0 Deep Dive von Atlas Cloud.
Ein Konto reicht für die gesamte Pipeline. Es ist nicht nötig, sich auf mehreren regionalen Plattformen zu registrieren, zu bezahlen oder API-Schlüssel zu verwalten. Der Playground unterstützt interaktives Debugging. Eine vereinheitlichte, OpenAI-kompatible API lässt sich in bestehende Workflows integrieren.
Die Prompt-Bibliothek von Atlas Cloud bietet über zwanzig Kategorien von sofort einsatzbereiten Prompts, die Anime, Sci-Fi, Mystery, Food und Vlog-Formate abdecken. Jeder Prompt enthält ein Beispielvideo und Parameterhinweise. Kopieren, ein paar Wörter austauschen, ausführen.
Eine vereinheitlichte API für die Videogenerierung in der Produktion
Während Google Gemini Omni Flash in der Gemini App und Google Flow für Endnutzer ausrollt, benötigen Entwickler und Produktteams, die dieselbe multimodale Video-Engine in ihre eigenen Workflows einbetten möchten, eine stabile, vorhersehbare API-Schicht.
Atlas Cloud stellt Gemini Omni Flash über eine vereinheitlichte, OpenAI-kompatible API bereit, zusammen mit über 300 weiteren Bild-, Video- und LLM-Modellen – sodass Sie Googles natives multimodales Modell integrieren können, ohne separate Anbieterkonten, Abrechnungsportale oder SDKs jonglieren zu müssen.
Beide Gemini Omni Flash-Varianten sind live auf Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Am besten geeignet für | Eingaben | Auflösung | Dauer | Startpreis |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | Reine prompt-gesteuerte filmische Generierung | Text (bis 20.000 Zeichen) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/Sek. |
| Gemini Omni Flash Image-to-Video (Developer) | Subjekt-konsistentes Video aus realen Referenzen | Text + bis zu 7 Referenzbilder | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/Sek. |
Schnellstart – Generieren Sie ein Gemini Omni Flash-Video in 5 Zeilen:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Ein nebliger Wald zur goldenen Stunde, filmische Dolly-Aufnahme", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
Die API liefert sofort eine Vorhersage-ID – pollen Sie /api/v1/model/prediction/{id} für die gerenderte MP4-URL. Vollständiges Schema, Code-Beispiele in 7 Sprachen und ein No-Code-Playground sind auf den oben verlinkten Modellseiten verfügbar.






